Levenshtein distance 编辑距离算法
这几天再看 virtrual-dom,关于两个列表的对比,讲到了 Levenshtein distance 距离,周末抽空做一下总结。
Levenshtein Distance 介绍
在信息理论和计算机科学中,Levenshtein 距离是用于测量两个序列之间的差异量(即编辑距离)的度量。两个字符串之间的 Levenshtein 距离定义为将一个字符串转换为另一个字符串所需的最小编辑数,允许的编辑操作是单个字符的插入,删除或替换。
例子
‘kitten’和’sitten’之间的 Levenshtein 距离是 3,因为一下三个编辑将一个更改为另一个,并且没有办法用少于三个编辑来执行操作。
kittensitten => 用’s’代替’k’- sitt
en sitti=> 用’i’代替’e’ - sittin sittin
g在结尾插入’g’
Levenshtein Distance (编辑距离) 算法详解
为了得到编辑距离,我们用 beauty 和 batyu 为例:
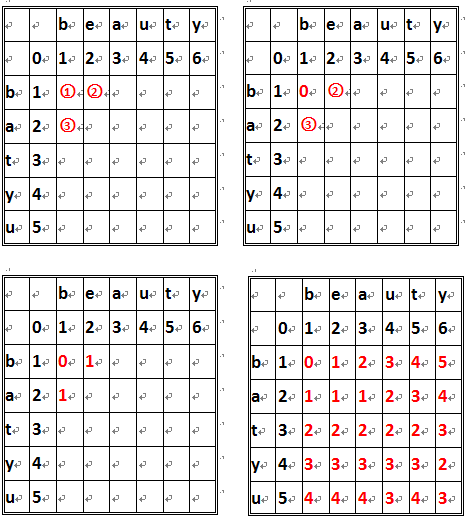
图示如 ① 单元位置是两个单词的第一个字符 [b] 比较得到的值,其的值有它的上方的值 (1)、它左方的值 (1) 和它左上角的值 (0) 来决定。当单元格所在的行和列所对应的字符相等时,单元格的值为左上方的值。
否则,单元格左上角的值与其上方和左方的值进行比较,它们之间的最小值 + 1 即是单元格的值。
图中 ① 的值由于单元格行和列相等,所以取左上角值 0。
图中 ② 的值由于单元格行列不相等,(1, 2, 0) 取最小为 0, 结果 + 1, 所以 ② 值为 1。
图示 ③ 的值由于单元格行列不相等,(1, 0, 2) 取最小 0, 结果 + 1, 所以 ③ 值为 1。
算法证明
这个算法计算的是将 s [1…i] 转换为 t [1…j](例如将 beauty 转换为 batyu)所需最少的操作数(也就是所谓的编辑距离),这个操作数被保存在 d [i,j](d 代表的就是上图所示的二维数组)中。
- 在第一行与第一列肯定是正确的,这也很好理解,例如我们将 beauty 转换为空字符串,我们需要进行的操作数为 beauty 的长度(所进行的操作为将 beauty 所有的字符丢弃)。
- 我们对字符的可能操作有三种:
- 将 s [1…n] 转换为 t [1…m] 当然需要将所有的 s 转换为所有的 t,所以,d [n,m](表格的右下角)就是我们所需的结果。
- 如果我们可以使用 k 个操作数把 s [1…i] 转换为 t [1…j-1],我们只需要把 t [j] 加在最后面就能将 s [1…i] 转换为 t [1…j],操作数为 k+1
- 如果我们可以使用 k 个操作数把 s [1…i-1] 转换为 t [1…j],我们只需要把 s [i] 从最后删除就可以完成转换,操作数为 k+1
- 如果我们可以使用 k 个操作数把 s [1…i-1] 转换为 t [1…j-1],我们只需要在需要的情况下(s [i] != t [j])把 s [i] 替换为 t [j],所需的操作数为 k+cost(cost 代表是否需要转换,如果 s [i]==t [j],则 cost 为 0,否则为 1)。
可能的改进
- 现在的算法复杂度为 O (m*n),可以将其改进为 O (m)。因为这个算法只需要上一行和当前行被存储下来就可以了。
- 如果需要重现转换步骤,我们可以把每一步的位置和所进行的操作保存下来,进行重现。
- 如果我们只需要比较转换步骤是否小于一个特定常数 k,那么只计算高宽宽为 2k+1 的矩形就可以了,这样的话,算法复杂度可简化为 O (kl),l 代表参加对比的最短 string 的长度。
- 我们可以对三种操作(添加,删除,替换)给予不同的权值(当前算法均假设为 1,我们可以设添加为 1,删除为 0,替换为 2 之类的),来细化我们的对比。
- 如果我们将第一行的所有 cell 初始化为 0,则此算法可以用作模糊字符查询。我们可以得到最匹配此字符串的字符串的最后一个字符的位置(index number),如果我们需要此字符串的起始位置,我们则需要存储各个操作的步骤,然后通过算法计算出字符串的起始位置。
- 这个算法不支持并行计算,在处理超大字符串的时候会无法利用到并行计算的好处。但我们也可以并行的计算 cost values(两个相同位置的字符是否相等),然后通过此算法来进行整体计算。
- 如果只检查对角线而不是检查整行,并且使用延迟验证(lazy evaluation),此算法的时间复杂度可优化为 O (m (1+d))(d 代表结果)。这在两个字符串非常相似的情况下可以使对比速度速度大为增加。
字符串比较代码
这一部分的代码,参考了 https://rosettacode.org/wiki/Levenshtein_distance#ES5
1 |
const ld = (a, b) => {
|
还原字符串
上面总结了传统的计算字符串之间的差距,那么当我们怎么能在计算的过程中,记录需要转换的步骤,并且进行还原呢。
这里我们需要对比较的每一位的步骤有一个了解。
为了得到编辑距离,我们用 beauty 和 batyu 为例:
从上面一节的图中可以看到,'beauty' 转换为 '' ,对一个的第一行的 [1,2,3,4,5,6],每一个步骤都相对与上一个元素新建一个元素,同理 '' 转换为 'batyu',每一个值都是相对一上一个元素的删除步骤。
那么对角线也显而易见就是先相对于替换操作。那么我们现在需要做的就是,记录下相对应的索引和元素以及需要进行的操作,并将其保存为一个对象,每次新增的对象用数组来保存就可以了。
![]()
1 |
const actionType = {
|
下面是 compare 方法:
1 |
/** |
上面需要注意的是,我们一组保存了多个数组对象,不要对原数组进行操作,每一次操作我们都需要拷贝一个新的数组对象。
具体的的 diff 代码参考 diff 代码
得到了,patches 对象,剩下的我们就需要 patch 了
1 |
const patch = (a, diffs) => {
|
具体代码参考代码地址
参考资料
- http://www.cnblogs.com/zhoug2020/p/4224866.html
- https://rosettacode.org/wiki/Levenshtein_distance#ES5
Levenshtein distance 编辑距离算法的更多相关文章
- Levenshtein Distance (编辑距离) 算法详解
编辑距离即从一个字符串变换到另一个字符串所需要的最少变化操作步骤(以字符为单位,如son到sun,s不用变,将o->s,n不用变,故操作步骤为1). 为了得到编辑距离,我们画一张二维表来理解,以 ...
- 扒一扒编辑距离(Levenshtein Distance)算法
最近由于工作需要,接触了编辑距离(Levenshtein Distance)算法.赶脚很有意思.最初百度了一些文章,但讲的都不是很好,读起来感觉似懂非懂.最后还是用google找到了一些资料才慢慢理解 ...
- 自然语言处理(5)之Levenshtein最小编辑距离算法
自然语言处理(5)之Levenshtein最小编辑距离算法 题记:之前在公司使用Levenshtein最小编辑距离算法来实现相似车牌的计算的特性开发,正好本节来总结下Levenshtein最小编辑距离 ...
- Lucene的FuzzyQuery中用到的Levenshtein Distance(LD)算法
2019独角兽企业重金招聘Python工程师标准>>> Lucene的FuzzyQuery中用到的Levenshtein Distance(LD)算法 博客分类: java 搜索引擎 ...
- 利用Levenshtein Distance (编辑距离)实现文档相似度计算
1.首先将word文档解压缩为zip /** * 修改后缀名 */ public static String reName(String path){ File file=new File(path) ...
- Levenshtein distance 编辑距离
编辑距离,又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数.许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符 实现方案: 1. 找出最长 ...
- Levenshtein Distance + LCS 算法计算两个字符串的相似度
//LD最短编辑路径算法 public static int LevenshteinDistance(string source, string target) { int cell = source ...
- C#实现Levenshtein distance最小编辑距离算法
Levenshtein distance,中文名为最小编辑距离,其目的是找出两个字符串之间需要改动多少个字符后变成一致.该算法使用了动态规划的算法策略,该问题具备最优子结构,最小编辑距离包含子最小编辑 ...
- Levenshtein Distance算法(编辑距离算法)
编辑距离 编辑距离(Edit Distance),又称Levenshtein距离,是指两个字串之间,由一个转成另一个所需的最少编辑操作次数.许可的编辑操作包括将一个字符替换成另一个字符,插入一个字符, ...
随机推荐
- Mysql 5.7.17安装后登录mysql的教程方法
在运行 ./bin/mysqld Cinitialize 初始化数据库时,会生成随机密码,示例: [Note] A temporary password is generated for root@l ...
- QT_获取正在运行程序的进程id(判断程序是否正在运行)
bool checkProcessRunning(const QString &processName, QList<quint64> &listProcessId) { ...
- plotroc.m
function out1 = plotroc(varargin) %PLOTROC Plot receiver operating characteristic. % % <a href=&q ...
- AndroidStudio离线打包MUI
1.下载5+SKD http://ask.dcloud.net.cn/article/103 2.解压到任意目录 3.导入HBuilder-Hello项目 4.在AndroidManifest.xml ...
- 最短路径问题 HDU - 3790 (Dijkstra算法 + 双重权值)
参考:https://www.cnblogs.com/qiufeihai/archive/2012/03/15/2398455.html 最短路径问题 Time Limit: 2000/1000 MS ...
- vuehomework1
红黄蓝三个按钮,点击不同的按钮可以切换一个200*200的矩形框对应的颜色 <!DOCTYPE html> <html lang="en"> <hea ...
- Vue 实现展开折叠效果
Vue 实现展开折叠效果 效果参见:https://segmentfault.com/q/1010000011359250/a-1020000011360185 上述链接中,大佬给除了解决方法,再次进 ...
- MySQL用户管理+MySQL权限管理
我们现在默认使用的都是root用户,超级管理员,拥有全部的权限! 但是,一个公司里面的数据库服务器上面可能同时运行着很多个项目的数据库! 所以,我们应该可以根据不同的项目建立不同的用户,分配不同的权限 ...
- 【JZOJ4791】【NOIP2016提高A组模拟9.21】矩阵
题目描述 在麦克雷的面前出现了一个有n*m个格子的矩阵,每个格子用"."或"#"表示,"."表示这个格子可以放东西,"#" ...
- Django1.11使用命令makemigrations提示No Changes
在项目中,遇到models模型变动,变动后合并发生问题,故当时做了删除应用文件夹下migrations文件,由于数据库里无较多新数据,故删除后重建,但重建后执行模型合并操作结果为No Changes, ...