【笔记】机器学习 - 李宏毅 - 10 - Tips for Training DNN
神经网络的表现
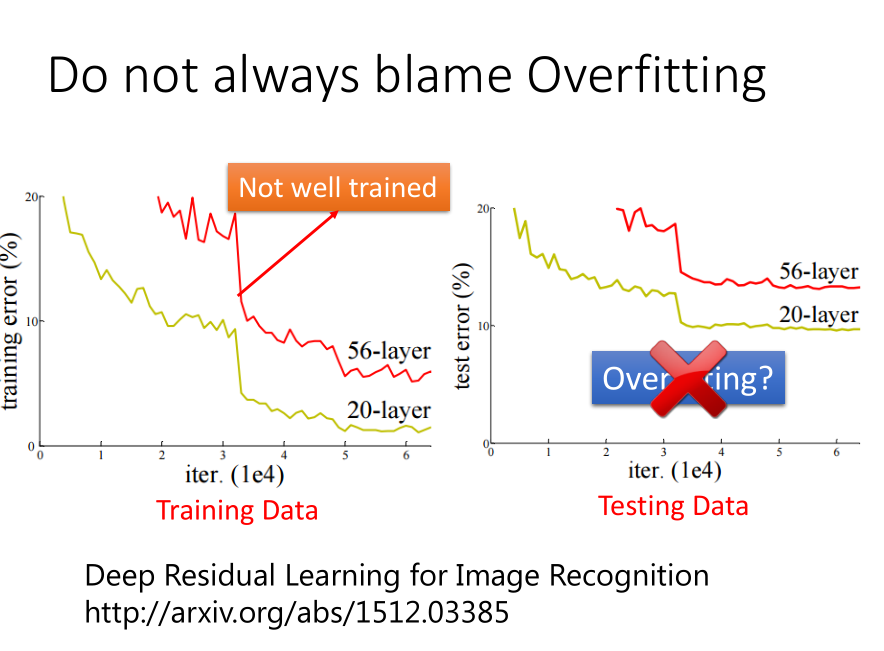
在Training Set上表现不好 ----> 可能陷入局部最优
在Testing Set上表现不好 -----> Overfitting 过拟合
虽然在机器学习中,很容易通过SVM等方法在Training Set上得出好的结果,但DL不是,所以得先看Training Set上的表现。
要注意方法适用的阶段:
比如:dropout方法只适合于:在Training Data上表现好,在Testing Data上表现不好的。
如果在Training Data上就表现不好了,那么这个方法不适用。
神经网络的改进

1. New Activation Function
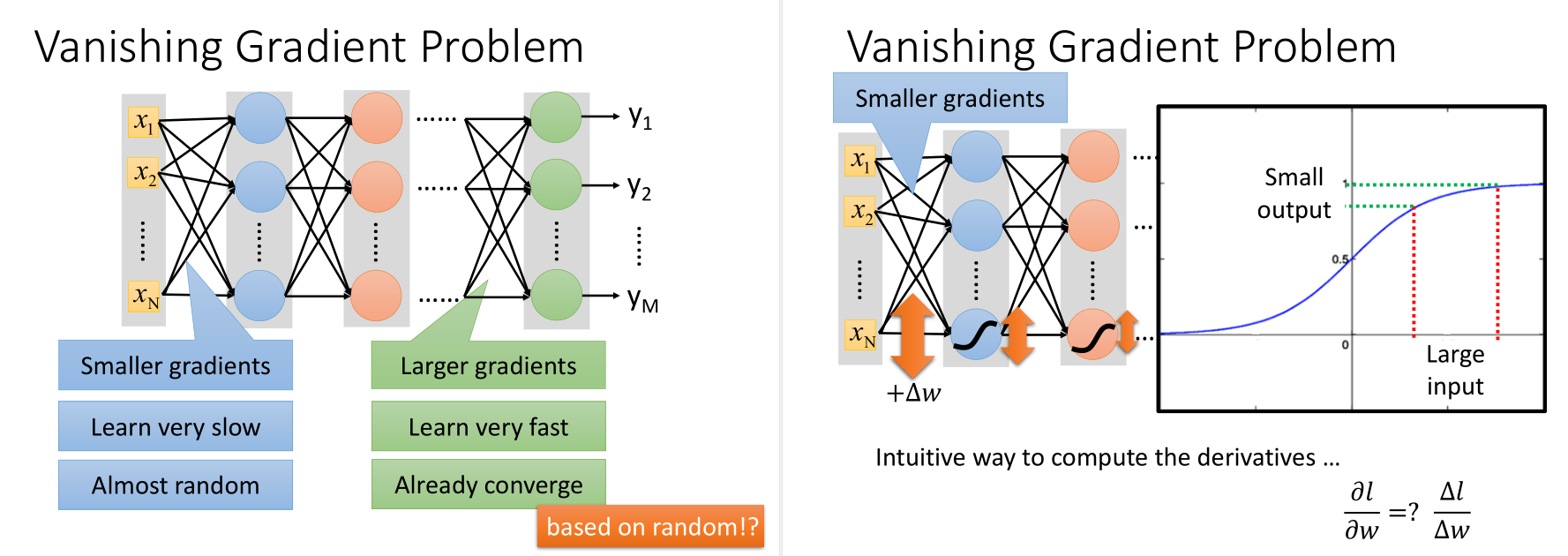
梯度消失:在输入层附近梯度小,在输出层梯度大,当参数还没有更新多少时,在输出层已经收敛了,这是激活函数\(sigmoid\)对值压缩的问题。
也就是一个比较大的input进去,出来的output比较小,所以最后对total loss的影响比较小,趋于收敛。
1.1 ReLU
如何解决梯度消失?
修改activation function为ReLU(Rectified Linear Unit),
ReLU input 大于0时,input 等于 output,input小于0时,output等于0。

其中,output为0的neural可以去掉,得到一个thinner linear network。
虽然局部是线性的,但这个network从总体上来说还是非线性的。

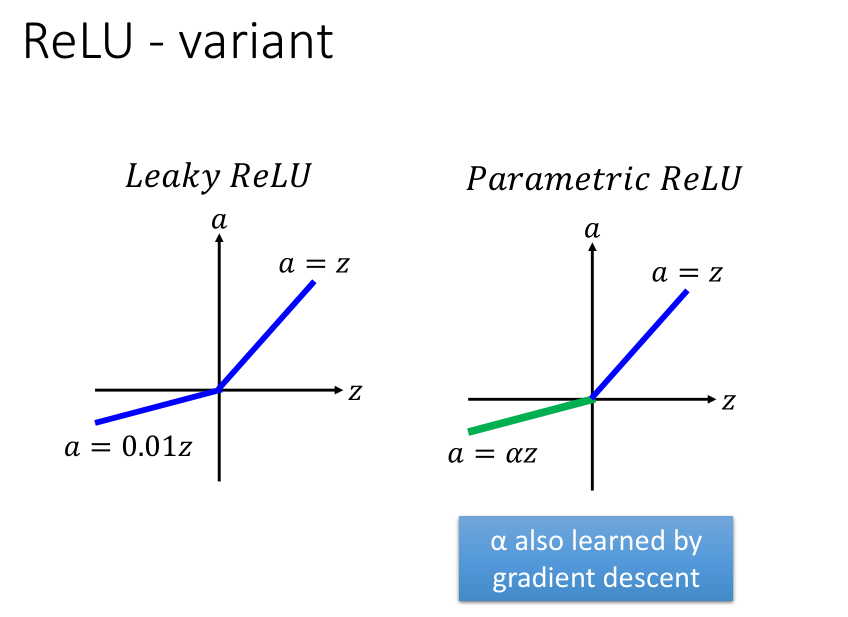
input小于0的部分,微分为0,这样就没法很好地更新参数了,所以有以下两种方法改进。
leaky ReLU,Parametric ReLU。
1.2 Maxout
此外,还可以通过Maxout自动学习activation function。ReLU是一种特殊的Maxout。
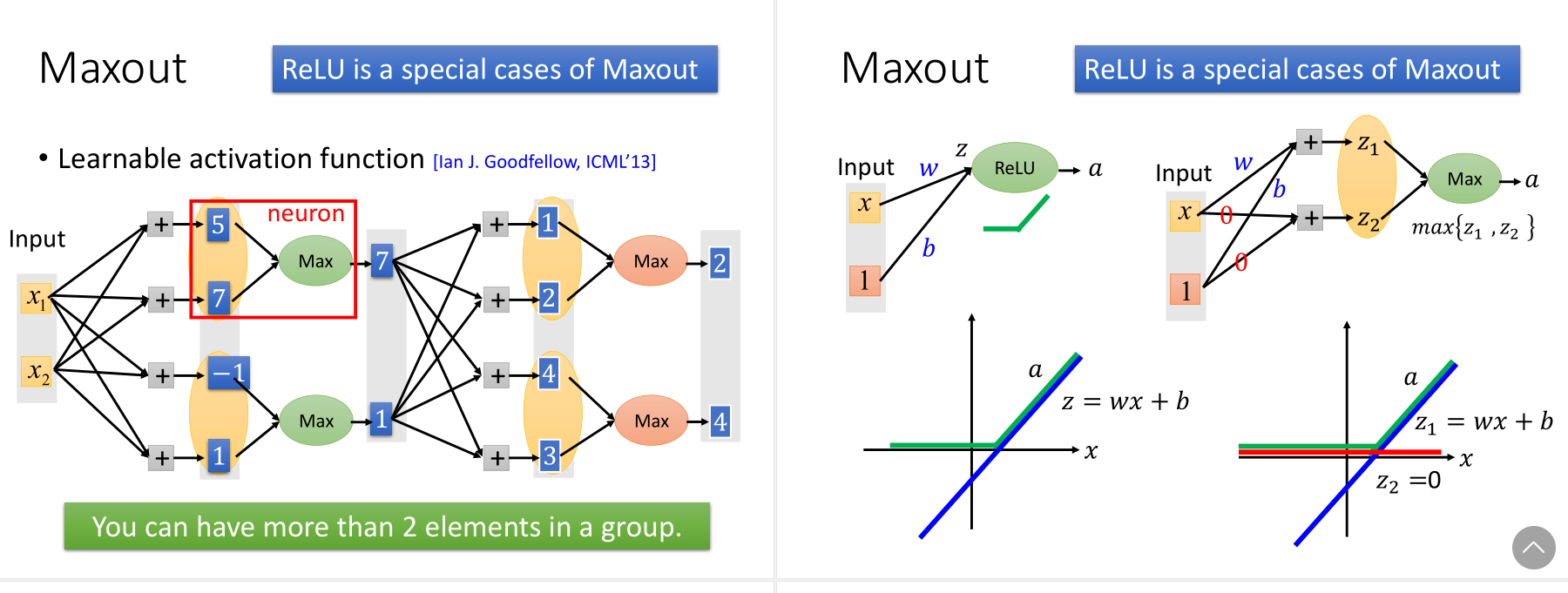
此外maxout可以与ReLU不同,如下图所示,可以有更灵活的形状,更多的piece(即更多的element)。

因为不是max的部分可以先去掉,所以可以不用train那些w,先train线性的局部。
当然,因为训练数据很多,最后都会被train到。

2. Adaptive Learning Rate
在Adagrad的基础上,Hinton提出了RMSProp方法。

对于local minimum的问题,因为每一个dimension都在谷底的情况很少,所以local minimum并没有那么多。
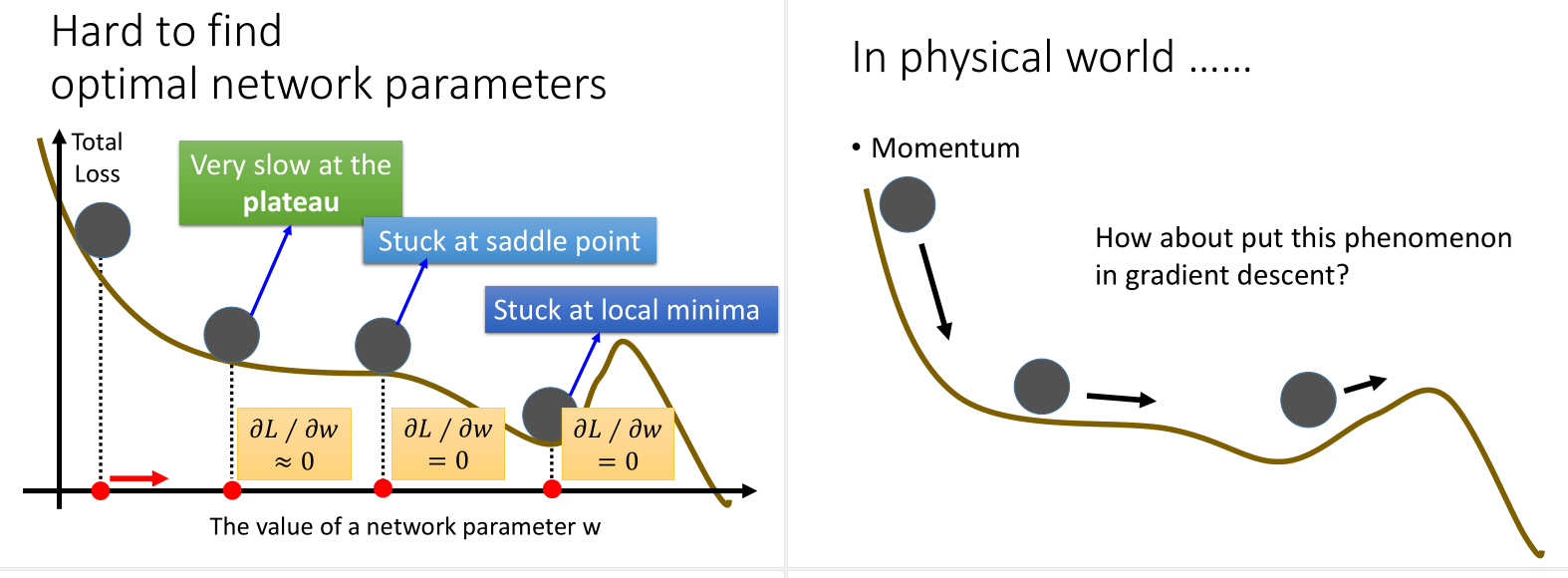
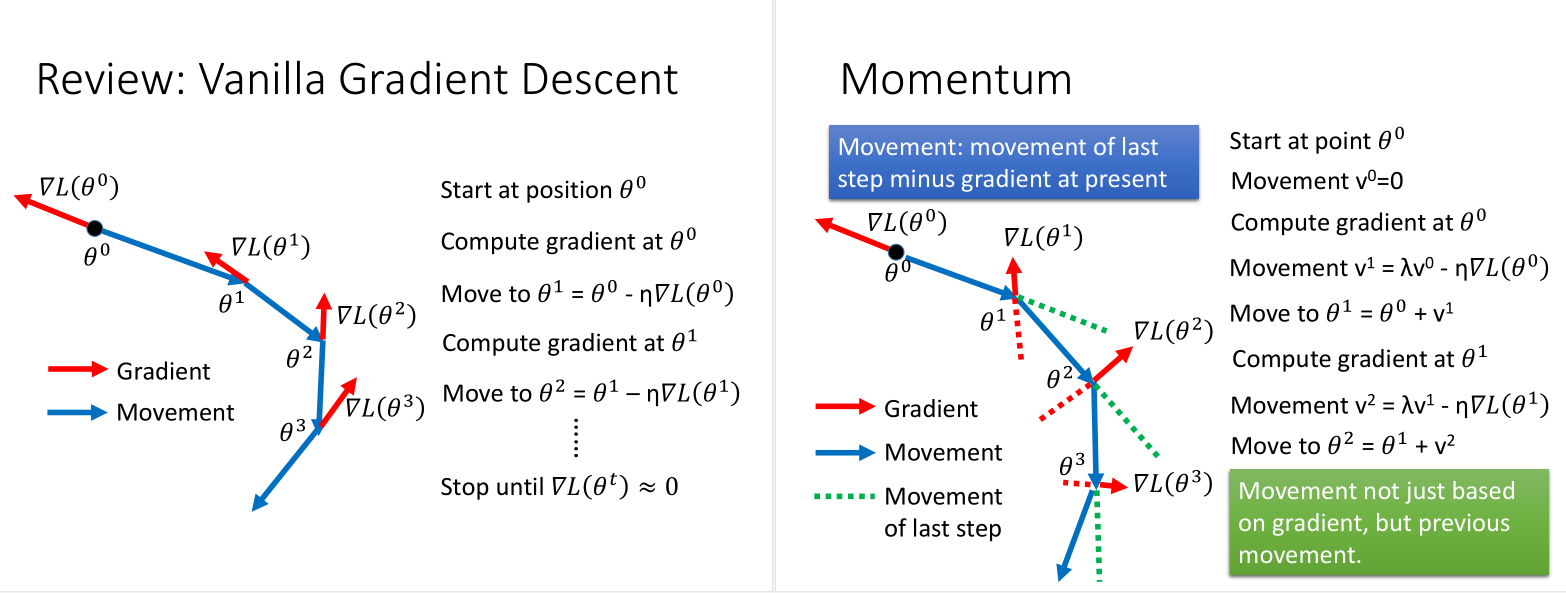
当然解决这个问题,有个Momentum的方法,模拟滚动的物理现象,加上惯性。
Adam方法,RMSProp + Momentum。

如果说在Testing Data上表现不好,可以用以下三种方法。
3. Early Stopping
用验证集去模拟测试集,在Testing Set表现开始变得不好的时候,停止Training。

4. Regularization
打个比方:小孩从出生到六岁,神经网络越来越多,但六岁以后开始变少。

在原来的Loss Function(minimize square error, cross entropy)的基础上加Regularization这一项(L2),不会加bias这一项,加Regularization的目的是让曲线更加平滑。
L2 Regularization 也叫 Weight Decay,这样每次都会让weight小一点。最后会慢慢变小趋近于0,但是会与后一项梯度的值达到平衡,使得最后的值不等于0。

用L1 Regularization也是可以的。
L2下降的很快,很快就会变得很小,在接近0时,下降的很慢,会保留一些接近01的值;
L1的话,减去一个固定的值(比较小的值),所以下降的很慢。
所以,通过L1-Norm training 出来的model,参数会有很大的值。

5. Dropout
对network里面的每个neural(包括input),做sampling(抽样)。 每个neural会有p%会被丢掉,跟着的weight也会被丢掉。
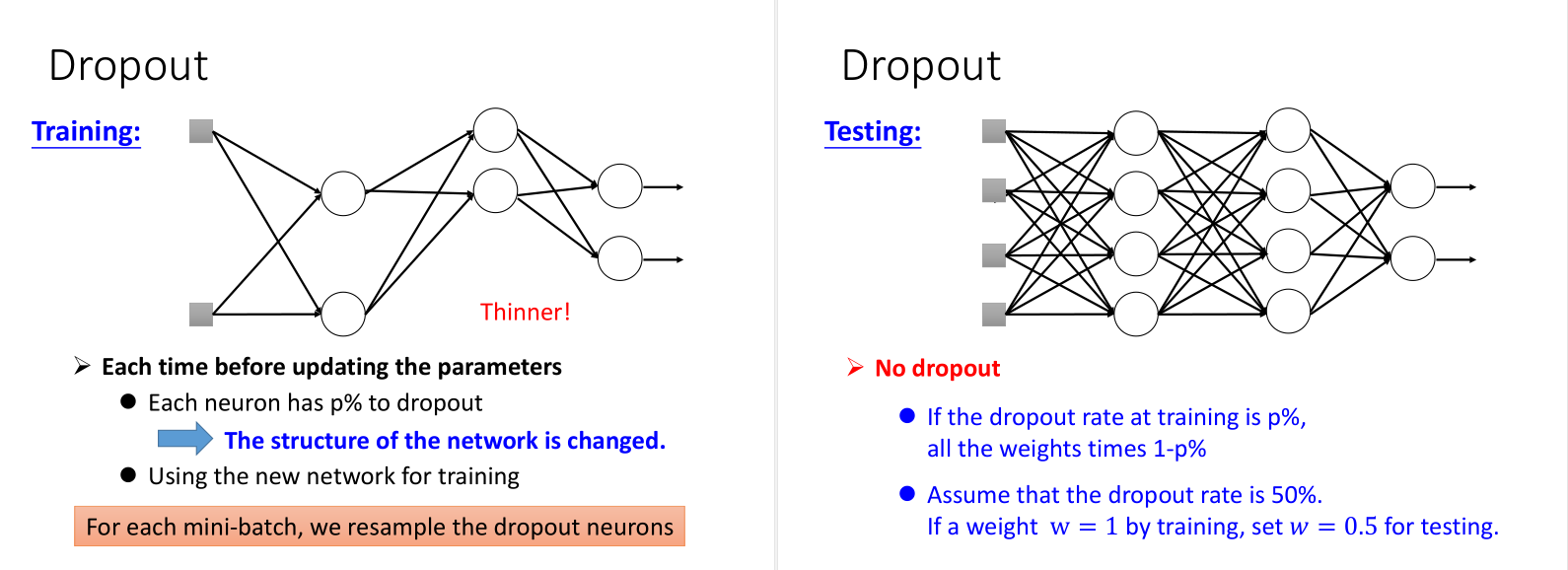
形象理解:(练武功&团队合作)

Dropout就是一种终极的集成学习 Ensemble。
可以理解为,因为有很多的model,Structure都不一样,
虽然每个model可能variance很大,但是如果它们都是很复杂的model时,平均起来时bias就很小,所以就比较准了。

如果直接将weight乘以 (1-p%),结果之前做average的结果跟output y是approximated。

【笔记】机器学习 - 李宏毅 - 10 - Tips for Training DNN的更多相关文章
- DNN训练技巧(Tips for Training DNN)
本博客是针对李宏毅教授在Youtube上上传的课程视频<ML Lecture 9-1:Tips for Training DNN>的学习笔记. 课程链接 Recipe of Deep Le ...
- 重构(Refactoring)技巧读书笔记(General Refactoring Tips)
重构(Refactoring)技巧读书笔记 之一 General Refactoring Tips, Part 1 本文简要整理重构方法的读书笔记及个人在做Code Review过程中,对程序代码常用 ...
- Andrew Ng机器学习课程10补充
Andrew Ng机器学习课程10补充 VC dimension 讲到了如果通过最小化训练误差,使用一个具有d个参数的hypothesis class进行学习,为了学习好,一般需要参数d的线性关系个训 ...
- Andrew Ng机器学习课程10
Andrew Ng机器学习课程10 a example 如果hypothesis set中的hypothesis是由d个real number决定的,那么用64位的计算机数据表示的话,那么模型的个数一 ...
- 写出完美论文的十个技巧10 Tips for Writing the Perfect Paper
10 Tips for Writing the Perfect Paper Like a gourmet meal or an old master painting, the perfect col ...
- 10 Tips for Writing Better Code (阅读理解)
出发点 http://www.tuicool.com/articles/A7VrE33 阅读中文版本<编写质优代码的十个技巧>,对于我编码十年的经验,也有相同感受, 太多的坑趟过,太多的经 ...
- 笔记-python-standard library-8.10 copy
笔记-python-standard library-8.10 copy 1. copy source code:Lib/copy.py python中的赋值语句不复制对象,它创建了对象和目 ...
- SQL Server2012 T-SQL基础教程--读书笔记(8 - 10章)
SQL Server2012 T-SQL基础教程--读书笔记(8 - 10章) 示例数据库:点我 CHAPTER 08 数据修改 8.1 插入数据 8.1.1 INSERT VALUES 语句 8.1 ...
- 机器学习笔记P1(李宏毅2019)
该博客将介绍机器学习课程by李宏毅的前两个章节:概述和回归. 视屏链接1-Introduction 视屏链接2-Regression 该课程将要介绍的内容如下所示: 从最左上角开始看: Regress ...
随机推荐
- 如何优雅的将Mybatis日志中的Preparing与Parameters转换为可执行SQL
原文链接 疫情期间大家宅在家里是不是已经快憋出“病”了~~ 公司给开了VPN,手机电脑都能连,手机装上APP测试包,就能干活了,所以walking从2020.02.01入京以来,已经窝在家里11天 ...
- Codeforces_841
A.统计每个字母数量,比较是否超过k. #include<bits/stdc++.h> using namespace std; ] = {}; string s; int main() ...
- socket实现文件上传(客户端向服务器端上传照片示例)
本示例在对socket有了基本了解之后,可以实现基本的文件上传.首先先介绍一下目录结构,server_data文件夹是用来存放客户端上传的文件,client_data是模拟客户端文件夹(目的是为了测试 ...
- 实现理论上无tps上限的分布式压测(基于Jmeter+InfluxDB+Grafana+Spring Boot)
JMeter自身带有Master-Slave压测框架,对于并发量不是很高的压力情况下(比如tps低于5000),该方案是可行的,并且使用起来非常方便,只要在配置文件或者命令行工具的参数做一些补充,即可 ...
- spark sql 执行计划生成案例
前言 一个SQL从词法解析.语法解析.逻辑执行计划.物理执行计划最终转换为可以执行的RDD,中间经历了很多的步骤和流程.其中词法分析和语法分析均有ANTLR4完成,可以进一步学习ANTLR4的相关知识 ...
- centos 7安装reids
一.reids下载 下载地址: https://redis.io/ 二.解压安装 ① 解压:tar -zxvf redis-5.0.5.tar.gz ② 安装环境:yum install gcc-c ...
- 曹工说Spring Boot源码(19)-- Spring 带给我们的工具利器,创建代理不用愁(ProxyFactory)
写在前面的话 相关背景及资源: 曹工说Spring Boot源码(1)-- Bean Definition到底是什么,附spring思维导图分享 曹工说Spring Boot源码(2)-- Bean ...
- nrm安装与配置(nrm管理npm源)
1.nrm nrm(npm registry manager )是npm的镜像源管理工具,有时候国外资源太慢,使用这个就可以快速地在 npm 源间切换 2.安装nrm 在命令行执行命令,npm ins ...
- Leetcode:110. 平衡二叉树
Leetcode:110. 平衡二叉树 Leetcode:110. 平衡二叉树 点链接就能看到原题啦~ 关于AVL的判断函数写法,请跳转:平衡二叉树的判断 废话不说直接上代码吧~主要的解析的都在上面的 ...
- SQL Server 2019 表无法修改问题
SQL Server 2019 表无法修改问题 问题描述: 解决方法: 1.在菜单栏中,点击工具->选项,示例: 2.在选项中单击设计器->表设计器和数据库设计器->取消勾选阻止保存 ...