SQL Server-聚焦NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL性能分析(十八)
前言
本节我们来综合比较NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL的性能,简短的内容,深入的理解,Always to review the basics。
NOT IN、NOT EXISTS、LEFT JOIN...IS NULL性能分析
我们首先创建测试表
USE TSQL2012
GO CREATE SCHEMA [compare]
CREATE TABLE [compare].t_left (
id INT NOT NULL PRIMARY KEY,
value INT NOT NULL,
stuffing VARCHAR() NOT NULL
)
CREATE TABLE [compare].t_right (
id INT NOT NULL PRIMARY KEY,
value INT NOT NULL,
stuffing VARCHAR() NOT NULL
)
GO
接着我们在两个表中的列value上创建索引
USE TSQL2012
GO CREATE INDEX idx_left_value ON [compare].t_left (value)
CREATE INDEX idx_right_value ON [compare].t_right (value)
我们在t_left和t_right表中插入如下测试数据
USE TSQL2012
GO BEGIN TRANSACTION
DECLARE @cnt INT
SET @cnt =
WHILE @cnt <=
BEGIN
INSERT
INTO [compare].t_left
VALUES (
@cnt,
@cnt % ,
LEFT('Left ' + CAST(@cnt AS VARCHAR) + ' ' + REPLICATE('*', ), )
)
SET @cnt = @cnt +
END;
WITH rows AS
(
SELECT AS row
UNION ALL
SELECT row +
FROM rows
WHERE row <
)
INSERT
INTO [compare].t_right
SELECT (id - ) * + row + ,
value + ,
LEFT('Right ' + CAST(id AS VARCHAR) + ' ' + REPLICATE('*', ), )
FROM [compare].t_left
CROSS JOIN
rows
COMMIT
我们稍微解释下上述插入的测试数据:
(1)t_left表中插入10万条数据,其中包含1万条重复数据。
(2)t_right表中插入100万条数据,其中包含1万条重复数据。
(3)t_left表中插入10条t_right表中没有的数据。
接下来我们一个个来看看其查询执行计划。
NOT IN性能分析
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT l.id, l.value
FROM [compare].t_left l
WHERE l.value NOT IN
(
SELECT value
FROM [compare].t_right r
)
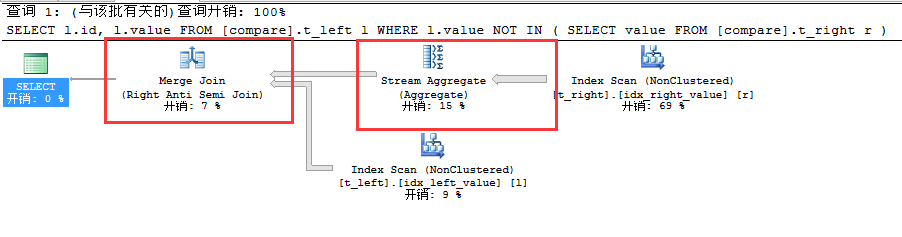

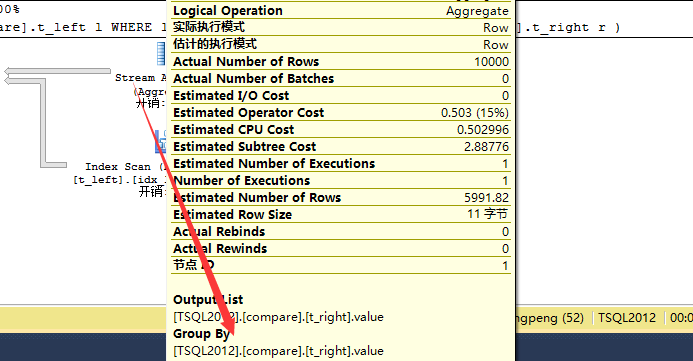
我们重点看看上述图做了标记的两个重要的地方,最后返回结果集时使用了Merge Anti Semi Join也就是说是上述Merge Join和Right Anti Semi Join的结合,可以说这是一种非常高效的方式,事先通过索引来排序然会获取两个表的结果集。数据库通过Merge Join来迭代两个表的结果集从小值到大值,当然也是通过指针指向二者结果集的当前值然后接着指向下一个值。而Anti Semi Join主要是干什么的呢?前面我们讲过它是半联接,此时数据库引擎只要匹配到t_right表中的值就跳过所有t_left和t_right表其他也同样匹配的同一个值,为什么会跳过呢? 因为此时Stream Aggregate起到了决定性作用(【关于Stream Aggregate前面简单了解了下,感觉理解的还是不够透,写这篇文章时才算是灰常了解了,后续会专门写写Stream Aggregate和Hash Aggregate】)我们知道Stream Aggregate首先需要排序,然后进行分组接着就是聚合,因为我们建立了索引所以就有了排序,接着执行Stream Aggregate进行分组,通过查看Stream Aggregate如下具体信息知道。因为对t_right表中的值进行了分组,所以当进行合并右半联接时,只取组中第一个,其余的自然而然就进行跳过,所以这种方式非常高效,通过索引来进行排序,再通过Stream Aggregate进行分组,最后执行Merge Join(Right Anti Semi Join)。最后我们看到查询仅仅只耗费了0.315秒。
NOT EXISTS性能分析
我们运行如下查询
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT l.id, l.value
FROM [compare].t_left l
WHERE NOT EXISTS
(
SELECT NULL
FROM [compare].t_right r
WHERE r.value = l.value
)
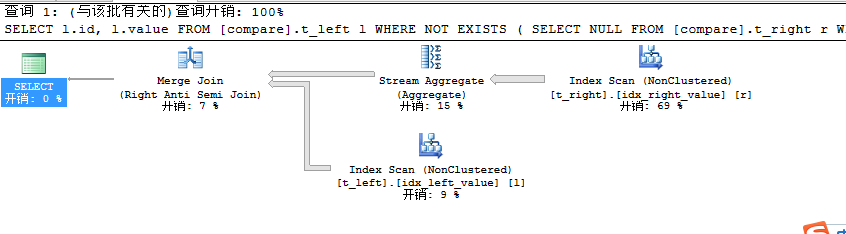
关于其查询耗费时间就不再给出了,其实NOT EXISTS和NOT查询计划和查询时间都是一样的,并没有任何区别,我们之前在单独讨论NOT EXISTS和NOT IN时就已经明确说过,二者在查询列不为NULL的前提下,二者的查询开销是一样的,而将查询列设置为可NULL时,NOT EXISTS的性能远高于NOT IN,这里我们就不过多的讨论了,不明白的童鞋可以看看前面关于二者比较的文章。
LEFT JOIN....IS NULL性能分析
USE TSQL2012
GO SET STATISTICS IO ON
SET STATISTICS TIME ON SELECT l.id, l.value
FROM [compare].t_left l
LEFT JOIN
[compare].t_right r
ON r.value = l.value
WHERE r.value IS NULL
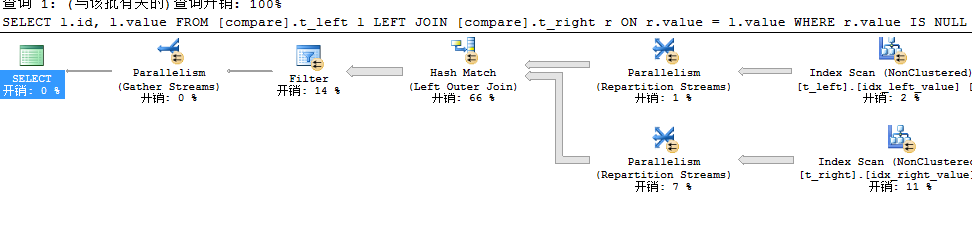

到这里我们知道很显然结果集肯定是一样的,但是查询计划和上述NOT EXISTS、NOT IN有很大的差异,LEFT JOIN...IS NULL首先是使用LEFT JOIN返回所有数据,其中包括重复的,然后再进行过滤,为什么会先进行LEFT JOIN然后再进行Filter呢?因为SQL Server根本无法很智能的识别LEFT JOIN上紧跟着的IS NULL,所以需要两步操作来完成。此时我们需要过滤100万条数据,这是一个非常耗时的工作,所以此时利用非常高效的Hash Match并且是并行的,但是过滤这些值还是要花费很长时间。整个时间花费了0.989秒,其查询耗费时间是NOT EXISTS或者NOT IN的3倍。所以到这里,关于此三者我们可以定下如下这样一个结论。
NOT IN VS NOT EXISTS VS LEFT JOIN..IS NULL结论:当查询缺省值时利用NOT EXISTS和NOT IN是最佳方式,但是前提是二者查询列都不能为NULL,否则使用NOT EXISTS。而LEFT JOIN...IS NULL因其总是不会跳过已经匹配过的值而是利用先返回所有结果集然后过滤的方式,其低效性可想而知。
总结
本节我们比较了NOT EXISTS和NOT IN和LEFT JOIN..IS NULL的性能,最终得出了三者性能分析结论,下一节我们已经确定是最后一篇终极篇比较EXISTS VS IN VS JOIN的性能,简短的内容,深入的理解,我们下节再会。
SQL Server-聚焦NOT IN VS NOT EXISTS VS LEFT JOIN...IS NULL性能分析(十八)的更多相关文章
- SQL Server ->> Memory Allocation Mechanism and Performance Analysis(内存分配机制与性能分析)之 -- Minimum server memory与Maximum server memory
Minimum server memory与Maximum server memory是SQL Server下配置实例级别最大和最小可用内存(注意不等于物理内存)的服务器配置选项.它们是管理SQL S ...
- (4.20)SQL Server数据库启动过程,以及启动不起来的各种问题的分析及解决技巧
转自:指尖流淌 https://www.cnblogs.com/zhijianliutang/p/4085546.html SQL Server数据库启动过程,以及启动不起来的各种问题的分析及解决技巧 ...
- SQL Server的唯一键和唯一索引会将空值(NULL)也算作重复值
我们先在SQL Server数据库中,建立一张Students表: CREATE TABLE [dbo].[Students]( ,) NOT NULL, ) NULL, ) NULL, [Age] ...
- SQL Server-索引故事的遥远由来,原来是这样的?(二十八)
前言 前段时间工作比较忙,每天回来也时不时去写有关ASP.NET Core的文章,无论是项目当中遇到的也好还是自学的也好都比较严谨的去叙述,喜欢分享,乐于分享这是我一直以来的态度,当然从中也会有些许错 ...
- SQL Server-聚焦INNER JOIN AND IN性能分析(十四)
前言 本节我们来讲讲联接综合知识,我们在大多教程或理论书上都在讲用哪好,哪个性能不如哪个的性能,但是真正讲到问题的实质却不是太多,所以才有了本系列每一篇的篇幅不是太多,但是肯定是我用心去查找许多资料而 ...
- SQL Server判断对象是否存在 (if exists (select * from sysobjects )(转)
1 判断数据库是否存在Sql代码 if exists (select * from sys.databases where name = ’数据库名’) drop database [数据库名] ...
- SQL Server 存储过程中处理多个查询条件的几种常见写法分析,我们该用那种写法
本文出处: http://www.cnblogs.com/wy123/p/5958047.html 最近发现还有不少做开发的小伙伴,在写存储过程的时候,在参考已有的不同的写法时,往往很迷茫,不知道各种 ...
- 强制SQL Server执行计划使用并行提升在复杂查询语句下的性能
最近在给一个客户做调优的时候发现一个很有意思的现象,对于一个复杂查询(涉及12个表)建立必要的索引后,语句使用的IO急剧下降,但执行时间不降反升,由原来的8秒升到20秒. 通过观察执行 ...
- 你所不知道的SQL Server数据库启动过程,以及启动不起来的各种问题的分析及解决技巧
目前SQL Server数据库作为微软一款优秀的RDBMS,其本身启动的时候是很少出问题的,我们在平时用的时候,很少关注起启动过程,或者很少了解其底层运行过程,大部分的过程只关注其内部的表.存储过程. ...
随机推荐
- 《Web 前端面试指南》1、JavaScript 闭包深入浅出
闭包是什么? 闭包是内部函数可以访问外部函数的变量.它可以访问三个作用域:首先可以访问自己的作用域(也就是定义在大括号内的变量),它也能访问外部函数的变量,和它能访问全局变量. 内部函数不仅可以访问外 ...
- Jquery 搭配 css 使用,简单有效
前几篇博客中讲了Jquery的基础和点击实际,下面来说一下和css搭配着来怎么做 还是和往常一样,举个例子 好几个方块,然后设置颜色 <!DOCTYPE html PUBLIC "-/ ...
- 使用技术手段限制DBA的危险操作—Oracle Database Vault
概述 众所周知,在业务高峰期,某些针对Oracle数据库的操作具有很高的风险,比如修改表结构.修改实例参数等等,如果没有充分评估和了解这些操作所带来的影响,这些操作很可能会导致故障,轻则导致应用错误, ...
- 关于Layer弹出框初探
layer至今仍作为layui的代表作,她的受众广泛并非偶然,而是这五年多的坚持,不断完善和维护.不断建设和提升社区服务,使得猿们纷纷自发传播,乃至于成为今天的Layui最强劲的源动力.目前,laye ...
- 从零开始编写自己的C#框架(27)——什么是开发框架
前言 做为一个程序员,在开发的过程中会发现,有框架同无框架,做起事来是完全不同的概念,关系到开发的效率.程序的健壮.性能.团队协作.后续功能维护.扩展......等方方面面的事情.很多朋友在学习搭建自 ...
- 算法与数据结构(十七) 基数排序(Swift 3.0版)
前面几篇博客我们已经陆陆续续的为大家介绍了7种排序方式,今天博客的主题依然与排序算法相关.今天这篇博客就来聊聊基数排序,基数排序算法是不稳定的排序算法,在排序数字较小的情况下,基数排序算法的效率还是比 ...
- Python自然语言处理工具小结
Python自然语言处理工具小结 作者:白宁超 2016年11月21日21:45:26 目录 [Python NLP]干货!详述Python NLTK下如何使用stanford NLP工具包(1) [ ...
- .NET CoreCLR开发人员指南(上)
1.为什么每一个CLR开发人员都需要读这篇文章 和所有的其他的大型代码库相比,CLR代码库有很多而且比较成熟的代码调试工具去检测BUG.对于程序员来说,理解这些规则和习惯写法非常的重要. 这篇文章让所 ...
- C# 对象实例化 用json保存 泛型类 可以很方便的保存程序设置
用于永久化对象,什么程序都行,依赖NewtonSoft.用于json序列化和反序列化. using Newtonsoft.Json; using System; using System.Collec ...
- bzoj1079--记忆化搜索
题目大意:有n个木块排成一行,从左到右依次编号为1~n.你有k种颜色的油漆,其中第i种颜色的油漆足够涂ci个木块.所有油漆刚好足够涂满所有木块,即c1+c2+...+ck=n.相邻两个木块涂相同色显得 ...