机器学习(四)——Lasso线性回归预测构建分类模型(matlab)
Lasso线性回归(Least Absolute Shrinkage and Selection Operator)是一种能够进行特征选择和正则化的线性回归方法。其重要的思想是L1正则化:其基本原理为在损失函数中加上模型权重系数的绝对值,要想让模型的拟合效果比较好,就要使损失函数尽可能的小,因此这样会使很多权重变为0或者权重值变得尽可能小,这样通过减少权重、降低权重值的方法能够防止模型过拟合,增加模型的泛化能力。其中还有另外一种类似的方法叫做岭回归,其基本原理是在损失函数中加上含有模型权重系数的平方的惩罚项,其他原理基本相同。
Lasso线性回归的目标是最小化以下损失函数:
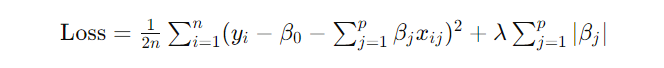
其中:

理论上来说当模型的损失函数越小时,构建的模型越接近真实分布,但是当模型的参数远远大于用来训练模型的数量的时候,很容易造成过拟合(模型学到的特征不是样本之间的共同特征,而是样本自身的特异性特征)。
通过L1正则化,可以约束线性模型中的权重系数,而且会减少特征量,保留权重系数有效的特征,同时能够减少系数之间的差距,让模型更具有泛化性。
当模型的损失函数达到最小的时候,惩罚项λ达到最优,模型的性能达到最优。
本文同样使用留一交叉验证的方法验证模型的分类性能,具体应用场景可以参考:机器学习(一)——递归特征消除法实现SVM(matlab)。
本文还提供了均方误差与特征数量的变化关系曲线、λ与均方误差的变化关系曲线以及分类结果的ROC曲线画法,如有需要请选择对应模块进行调整作图。
matlab实现代码如下:
labels = res(:, 1); % 第一列是标签
features = res(:, 2:end); % 后面的列是特征
features = zscore(features); %归一化处理
%% 使用留一法交叉验证选择最优的 Lambda 值及其对应的特征
numSamples = size(features, 1);
lambda_values = logspace(-2, 2, 60); % 选择一系列 Lambda 值
mse_values = zeros(size(lambda_values)); % 存储每个 Lambda 值的均方误差
selected_features_all = cell(length(lambda_values), 1); % 存储每个 Lambda 值选择的特征
for i = 1:length(lambda_values)
mse_fold = zeros(numSamples, 1);
selected_feature = []; % 重置选择的特征
for j = 1:numSamples
% 划分训练集和验证集
X_train = features([1:j-1, j+1:end], :); % 使用除了当前样本之外的所有样本作为训练集
y_train = labels([1:j-1, j+1:end]); % 训练集标签
X_valid = features(j, :); % 当前样本作为验证集
y_valid = labels(j); % 验证集标签
% 训练 LASSO 模型
B = lasso(X_train, y_train, 'Lambda', lambda_values(i));
% 在验证集上进行预测
y_pred = X_valid * B;
% 计算均方误差
mse_fold(j) = mean((y_pred - y_valid).^2);
% 将选择的特征添加到列表中
selected_feature = [selected_feature; find(B ~= 0)]; % 使用分号进行垂直串联
end
% 计算当前 Lambda 值的平均均方误差
mse_values(i) = mean(mse_fold);
selected_feature= unique(selected_feature);%消除重复的特征
% 保存每个 Lambda 值选择的特征
selected_features_all{i} = selected_feature;
end
% 找到使均方误差最小的 Lambda 值
[min_mse, min_idx] = min(mse_values);
min_idx=min_idx-2; %相当于当λ达到最优时,特征数量为0,所以要找最靠近最优λ的λ值来构建模型,此处可调
min_mse=mse_values(min_idx);
optimal_lambda = lambda_values(min_idx);
% 找到最优 Lambda 值对应的特征
selected_features_optimal = selected_features_all{min_idx};
selected_features_optimal = unique(selected_features_optimal); %%%%%%%保留不同的特征,防止特征重复出现
% 显示最优的 Lambda 值及其对应的特征
disp(['最优的 Lambda 值:', num2str(optimal_lambda)]);
%% 对挑选出来的向量构建模型,并使用留一交叉验证计算其平均准确率
% 初始化变量来存储准确率
num_samples = size(features, 1);
accuracies = zeros(num_samples, 1);
Prediction_probability=zeros(num_samples, 1);%声明一个空数组用于储存预测的概率
% 遍历每个样本
for i = 1:num_samples
% 留出第 i 个样本作为验证集,其余样本作为训练集
X_train = features([1:i-1, i+1:end], selected_features_optimal); % 选择选出来的特征
y_train = labels([1:i-1, i+1:end]);
X_valid = features(i, selected_features_optimal);
y_valid = labels(i);
% 训练逻辑回归模型
mdl = fitglm(X_train, y_train, 'Distribution', 'binomial', 'Link', 'logit');
% 在验证集上进行预测
y_pred = predict(mdl, X_valid);
% 将预测概率转换为类别标签
y_pred_label = round(y_pred);
Prediction_probability(i)=y_pred;
% 计算准确率
accuracies(i) = (y_pred_label == y_valid);
end
% 计算平均准确率
average_accuracy = mean(accuracies);
% 显示平均准确率
disp(['平均准确率:', num2str(average_accuracy)]);
% 计算选取的特征个数
num_selected_features = cellfun(@length, selected_features_all);
% 绘制三维图像
figure;
plot3(lambda_values, mse_values, num_selected_features, 'b-', 'LineWidth', 2);
xlabel('λ值');
ylabel('均方误差');
zlabel('特征数量');
title('λ值与均方误差以及特征数量的变化关系');
grid on;
% 绘制 λ 和平均误差曲线
figure;
semilogx(lambda_values, mse_values, 'b-', 'LineWidth', 2);
xlabel('λ值');
ylabel('均方误差');
title('λ值与均方误差的变化关系');
grid on;
%计算ROC模型的相关参数
[fpr, tpr, thresholds] = perfcurve(labels, Prediction_probability, 1);
% 绘制 ROC 曲线
figure;
plot(fpr, tpr);
xlabel('假阳性率 (FPR)');
ylabel('真阳性率 (TPR)');
title('Lasso回归模型下ROC 曲线');
% 计算曲线下面积(AUC)
auc = trapz(fpr, tpr);
legend(['AUC = ' num2str(auc)]);
%% 统计每次迭代后选择的特征的,然后出一个排名,迭代过程中出现最多次的特征认为是可靠的特征
% 初始化一个空的结构数组
unique_elements_struct = struct('value', {}, 'count', {});
% 遍历每个单元格中的数组,统计每个元素出现的次数
for i = 1:numel(selected_features_all)
current_array = selected_features_all{i};
unique_elements = unique(current_array);
for j = 1:numel(unique_elements)
element = unique_elements(j);
idx = find([unique_elements_struct.value] == element);
if isempty(idx)
% 如果元素不在结构数组中,则添加它
unique_elements_struct(end+1).value = element;
unique_elements_struct(end).count = sum(current_array == element);
else
% 否则更新该元素的计数
unique_elements_struct(idx).count = unique_elements_struct(idx).count + sum(current_array == element);
end
end
end
% 按照出现次数进行降序排序
[~, sorted_indices] = sort([unique_elements_struct.count], 'descend');
unique_elements_struct = unique_elements_struct(sorted_indices);
% 显示结果
for i = 1:numel(unique_elements_struct)
disp(['Element ', num2str(unique_elements_struct(i).value), ' appeared ', num2str(unique_elements_struct(i).count), ' times.']);
end
机器学习(四)——Lasso线性回归预测构建分类模型(matlab)的更多相关文章
- Spark学习笔记——构建分类模型
Spark中常见的三种分类模型:线性模型.决策树和朴素贝叶斯模型. 线性模型,简单而且相对容易扩展到非常大的数据集:线性模型又可以分成:1.逻辑回归:2.线性支持向量机 决策树是一个强大的非线性技术, ...
- 吴裕雄 python 机器学习——集成学习随机森林RandomForestClassifier分类模型
import numpy as np import matplotlib.pyplot as plt from sklearn import datasets,ensemble from sklear ...
- 【机器学习实验】学习Python来分类现实世界的数据
引入 一个机器能够依据照片来辨别鲜花的品种吗?在机器学习角度,这事实上是一个分类问题.即机器依据不同品种鲜花的数据进行学习.使其能够对未标记的測试图片数据进行分类. 这一小节.我们还是从scikit- ...
- 机器学习01:使用scikit-learn的线性回归预测Google股票
这是机器学习系列的第一篇文章. 本文将使用Python及scikit-learn的线性回归预测Google的股票走势.请千万别期望这个示例能够让你成为股票高手.下面按逐步介绍如何进行实践. 准备数据 ...
- weka实际操作--构建分类、回归模型
weka提供了几种处理数据的方式,其中分类和回归是平时用到最多的,也是非常容易理解的,分类就是在已有的数据基础上学习出一个分类函数或者构造出一个分类模型.这个函数或模型能够把数据集中地映射到某个给定的 ...
- Spark机器学习4·分类模型(spark-shell)
线性模型 逻辑回归--逻辑损失(logistic loss) 线性支持向量机(Support Vector Machine, SVM)--合页损失(hinge loss) 朴素贝叶斯(Naive Ba ...
- 机器学习04-(决策树、集合算法:AdaBoost模型、BBDT、随机森林、分类模型:逻辑回归)
机器学习04 机器学习-04 集合算法 AdaBoost模型(正向激励) 特征重要性 GBDT 自助聚合 随机森林 分类模型 什么问题属于分类问题? 逻辑回归 代码总结 波士顿房屋价格数据分析与房价预 ...
- 机器学习入门-文本特征-使用LDA主题模型构造标签 1.LatentDirichletAllocation(LDA用于构建主题模型) 2.LDA.components(输出各个词向量的权重值)
函数说明 1.LDA(n_topics, max_iters, random_state) 用于构建LDA主题模型,将文本分成不同的主题 参数说明:n_topics 表示分为多少个主题, max_i ...
- 模型构建<1>:模型评估-分类问题
对模型的评估是指对模型泛化能力的评估,主要通过具体的性能度量指标来完成.在对比不同模型的能力时,使用不同的性能度量指标可能会导致不同的评判结果,因此也就意味着,模型的好坏只是相对的,什么样的模型是较好 ...
- python实现感知机线性分类模型
前言 感知器是分类的线性分类模型,其中输入为实例的特征向量,输出为实例的类别,取+1或-1的值作为正类或负类.感知器对应于输入空间中对输入特征进行分类的超平面,属于判别模型. 通过梯度下降使误分类的损 ...
随机推荐
- 算法~利用zset实现滑动窗口限流
滑动窗口限流 滑动窗口限流是一种常用的限流算法,通过维护一个固定大小的窗口,在单位时间内允许通过的请求次数不超过设定的阈值.具体来说,滑动窗口限流算法通常包括以下几个步骤: 初始化:设置窗口大小.请求 ...
- Gem离线包安装
Gem离线包安装 项目环境 以 rest-client 为例 本地如果是rails项目环境: ruby '2.7.0' gem 'rails', '~> 6.0.3', '>= 6.0.3 ...
- PageOffice 在线编辑 office文件,回调父页面
一.子页面调用父页面的方法 var value=window.external.CallParentFunc("ParentFunName(Arguments);");//父页面的 ...
- 可视化学习:使用极坐标参数方程和SDF绘制有趣的图案
前言 本文将介绍如何使用极坐标参数方程和上一篇文章提到的距离场SDF来绘制有趣的图案. 说到曲线和几何图形的绘制,我们知道图形系统默认支持的是通过直角坐标绘制,但是有些曲线呢,不太容易使用直角坐标系来 ...
- Ceph配置与认证授权
目录 Ceph配置与认证授权 1. 为什么现在不采用修改配置文件的方式了呢? 2. Ceph元变量 3. 使用命令行修改配置 3.1 全部修改(使用服务名) 3.2 部分修改(修改进程) 3.3 临时 ...
- mit 6.824 lab1 思路贴
前言 为遵守 mit 的约定,这个帖子不贴太多具体的代码,主要聊聊自己在码代码时的一些想法和遇到的问题. 这个实验需要我们去实现一个 map-reduce 的功能.实质上,这个实验分为两个大的板块,m ...
- 一个与 WSL2 建立远程的简单方法
前言 众所周知,windows 会通过虚拟交换机给本机和 wsl2(Linux 子系统)分别分配 ip.于是本机重启或重启 wsl 服务的时候会重新分配 ip.之前所作的端口转发,监听之类的都会失效. ...
- MKV与MatroskaExtractor
mkv封装格式相关内容可以参考:MKV 文件格式解析_Martyn哥的博客-CSDN博客_mkv 格式解析 本篇主要是用来记录MatroskaExtractor是如何解析EBML的,如何解析EBML ...
- WPF插件之 - PropertyChanged.Fody使用详解
总目录文章目录总目录一.PropertyChanged.Fody是什么?二.PropertyChanged.Fody的安装三.PropertyChanged.Fody的功能1. 特性1 实现属性通知的 ...
- LLM 大模型学习必知必会系列(三):LLM和多模态模型高效推理实践
LLM 大模型学习必知必会系列(三):LLM和多模态模型高效推理实践 1.多模态大模型推理 LLM 的推理流程: 多模态的 LLM 的原理: 代码演示:使用 ModelScope NoteBook 完 ...