【论文阅读】GRI: General Reinforced Imitation and its Application to Vision-Based Autonomous Driving
Column: December 30, 2021 11:01 PM
Last edited time: January 10, 2022 4:45 PM
Sensor/组织: 3 RGB; 曾经短暂的第一名
Status: 正在套娃
Summary: RL; carla leaderboard
Type: arXiv
Year: 2021
参考与前言
模块化思想有点意思,但是好像和看过的某一篇特别相似 关于先相机出seg部分 再到下一层,类似于一个中途检查效果 想起来了 和 MaRLn 一个部分很像 → 原文在3.2部分引用说了参考于那边
后面有外链MaRLn,温馨链接:End-to-End Model-Free Reinforcement Learning for Urban Driving Using Implicit Affordances
1. Motivation
DRL [7, 16, 17 22] 慢慢被证实 能处理复杂决策,但是因为DRL同时也具有极高的复杂度和低稳定性。而一般专家数据(模仿学习)能帮忙缓解一下这个问题。所以本文就是融合这两者之间 DRL和 IL 来进行训练。
- low stability 需要套娃看一下是什么样的低稳定性
Contribution
主要就是针对上面的问题而来的,总结一句就是融合了两者之间的关系,提出一个框架来训练,做了很多实验证明这样效果很好

发现learning方向的文章 消融实验做的特别多 为了证明自己这一块加入的重要性
2. Method
整体框架,从下图可以基本看出整体的融合就是先训练其中一个然后反向传播后再联合进入第二阶段
- 第一阶段的对比都由输出的结果对比而不是动作进行loss判断
- 第二阶段由第一阶段结果add 然后进到DRL框架对输出动作和专家动作进行loss判断
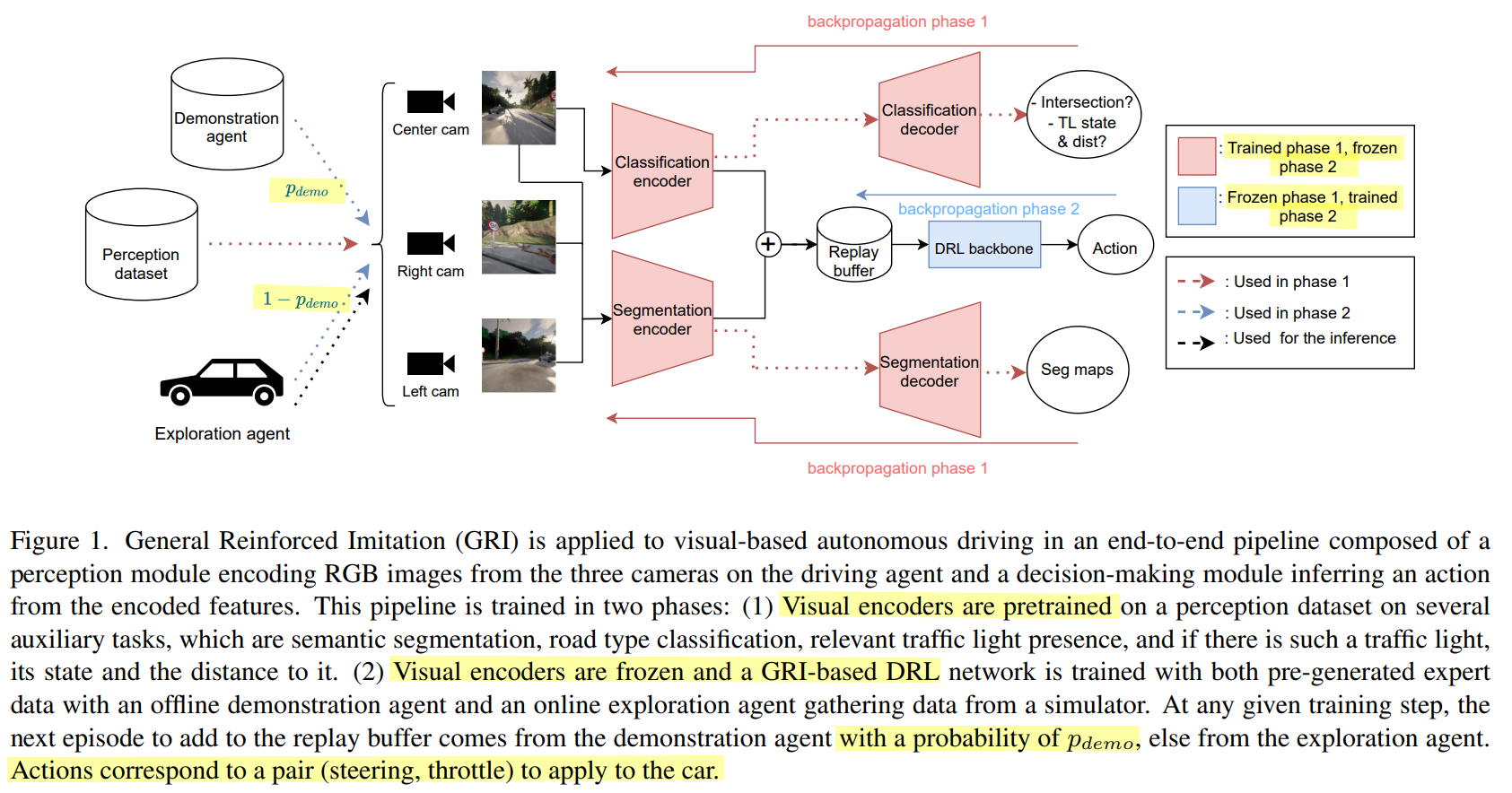
具体这个add操作看一下论文有讲吗 不然只能等代码开出来 虽然好像也没说要开
直接一个输出是224,一个是3x448 然后直接flatten 拉到了1568
2.1 输入
首先是传感器配置位置 三个相机,以车为中心放置于:\(x=2.5m,z=1.2m \text{ and } y \in \{-0.8,0,0.8\}\) 也就是left center right分布,两边的相机有 70度的转角偏置,所有相机都是100度FOV。这样看来相机之间有共同部分 也较为合理 感觉更好激活一点
这一层输入应该说需要分阶段去考虑
- 首先整体的action数据根据不同的 \(p_{\text{demo}}=0.25\),然后还有 专家数据的reward=1,得到后的reward进行归一化后,再靠近这个专家reward也就是1
- 看相机输入的话,是232x352x3然后放到分类和分割器里 两层均参考于 [23]
- 关于动作进行了离散化 27个 steering values 和 4个油门或者刹车值,所以在RL那层动作离散空间就是 \(27\times4=108\) 个
看输出发现问题了,首先是关于两个阶段的loss function都没给
因为直接用的EfficientNet 那一套?所以
reward判定也没给,只说要靠近专家数据的reward 但是你专家数据reward也是从一个评判中获取的,原来还有比MaRLn更简略的 人家只是简略不开那块代码 这个倒好 直接不介绍了 emmm
话说太早了,看到后面有了 直接参考MaRLn hhhh 所以才没啥介绍 -> 温馨链接:End-to-End Model-Free Reinforcement Learning for Urban Driving Using Implicit Affordances
以下RL全部摘自上文参考中:
RL 设置
首先选的是value-based method,当然这样的设置就导致我们看的动作都是离散的,文中并没有做policy-based的对比(挖坑 后面做),借鉴开源的Rainbow-IQN Ape-X 但是去掉了dueling network
温馨链接:RL policy-based method和value-based method区别
Reward Shaping
原来这个shaping是指... reward setting
计算的方法主要是 Carla提供了waypoint的API来进行判断,当遇到路口的时候,随机选择(左、右、直走),reward主要由以下三个决定
desired speed:reward range [0,1]
如果在期望速度给最大1,然后线性打分当速度高了或者是低了,本文中期望速度为40km/h
展开可见图片示意
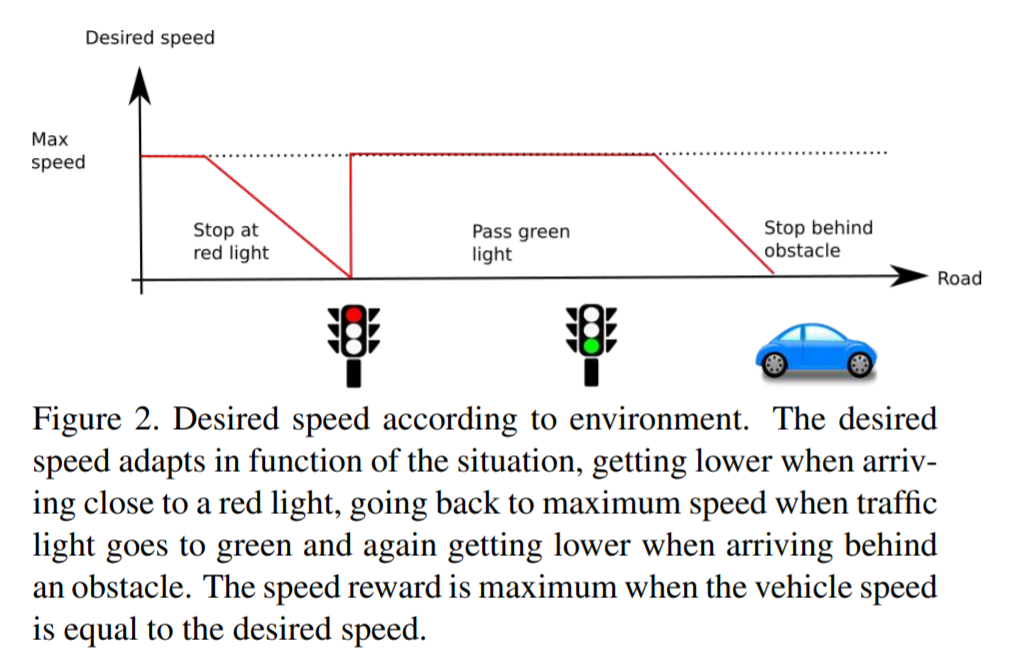
desired position:reward range [-1,0]
如果刚好在道路中心的路径点给0,然后和相距距离成反比的给负reward,以下两种情况episode直接停止,并设reward为-1,本文设置\(D_{max}=2\text{m}\) 也正是中心线到路边缘的距离
- 与中心路径点相距超过\(D_{max}\)
- 与其他东西相撞,闯红绿灯,前无障碍物/红灯时 车辆停下来
desired rotation
这一个设置的是因为 作者发现只有前两个的时候,车子会在有障碍物的时候直接停下,而不是绕行,因为绕行会让他的第二个reward下降,直行的话又会使他撞上去 → 有做消融实验证明
reward 和 optimal trajectory的angle差距值成反比
- 但是看到这点的时候,我本来打算看看rotation的reward范围,然后发现这个作者... 是假开源,他并没有开源RL expert的代码 emmm,也没有给出RL跑的数据集 → 按道理不给代码 给数据集应该不难?代码里只有load他的model,连Dataloader都没有 emmm
- 还有一点是在换道的时候 reward还是会偏离原路径点的angle呀,如果是optimal trajectory的角度的话,并没有定义清楚optimal trajectory是由谁给出的
噢 是不是 他在开头嫌弃的那个carla的expert?→ 不对啊 他不会换道呀
2.2 框架
大框架已经在上面给出,小部分主要是关于reward设置和分类器、分割器的网络分别细节部分
首先reward设置引用至:CVPR2020: End-to-End Model-Free Reinforcement Learning for Urban Driving Using Implicit Affordances
两个部分的框图(建议放大看):
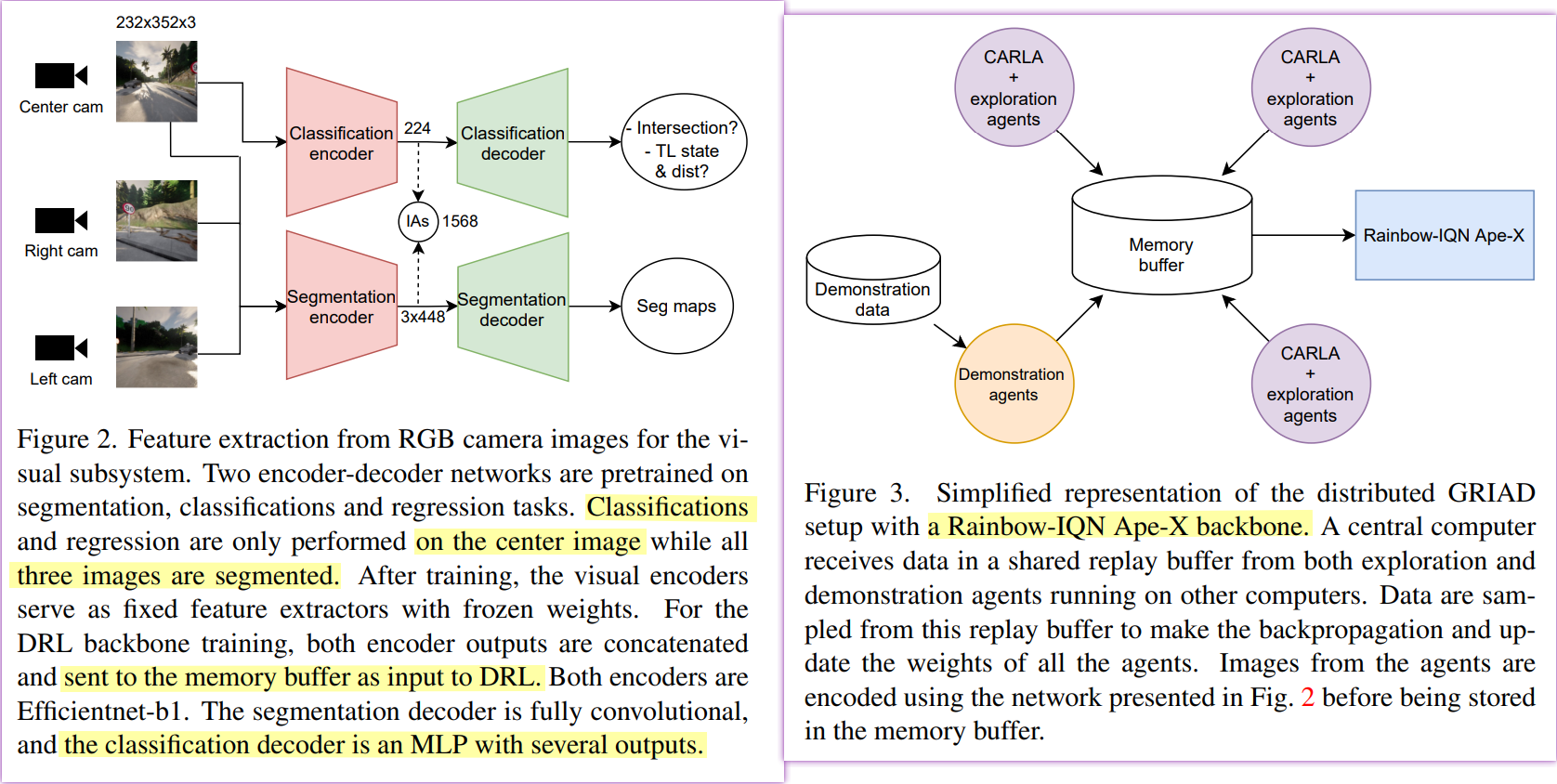
摘自原文中
然后基本就没啥然后了 因为直接参考的Efficientnet-b1 [23]和Rainbow-IQN Ape-X [25] backbone,看来又是一层套娃之旅
Figure 2也就是说的 视觉子系统,Figure 3就是决策子系统。
2.3 输出
首先在训练时 各自层的输出都是基于参考的backbone来的,还没开始套娃。最后的model输出当然就直接是动作,其中包括steering vale, throttle or brake value
3. Conclusion
基本没啥好说的了,重复了一遍contribution:

摘自原文
整体emmm 大框架值得参考,小细节需要套娃看一下,特别是add操作没有解释清楚 也没代码 无法对着看吧。 不过 \(p_{\text{demo}}\) 是否也可以当做一个学习参数来进行,选取最好的?但是关于RL那块似懂非懂的 再瞅瞅
【论文阅读】GRI: General Reinforced Imitation and its Application to Vision-Based Autonomous Driving的更多相关文章
- 【论文阅读】Learning Dual Convolutional Neural Networks for Low-Level Vision
论文阅读([CVPR2018]Jinshan Pan - Learning Dual Convolutional Neural Networks for Low-Level Vision) 本文针对低 ...
- 论文阅读笔记六十四: Architectures for deep neural network based acoustic models defined over windowed speech waveforms(INTERSPEECH 2015)
论文原址:https://pdfs.semanticscholar.org/eeb7/c037e6685923c76cafc0a14c5e4b00bcf475.pdf 摘要 本文研究了利用深度神经网络 ...
- 【论文阅读】An Anchor-Free Region Proposal Network for Faster R-CNN based Text Detection Approaches
懒得转成文字再写一遍了,直接把做过的PPT放出来吧. 论文连接:https://link.zhihu.com/?target=https%3A//arxiv.org/pdf/1804.09003v1. ...
- 论文阅读之:Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space
Deep Meta Learning for Real-Time Visual Tracking based on Target-Specific Feature Space 2018-01-04 ...
- 论文阅读-Temporal Phenotyping from Longitudinal Electronic Health Records: A Graph Based Framework
- BERT 论文阅读笔记
BERT 论文阅读 BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding 由 @快刀切草莓君 ...
- Learning under Concept Drift: A Review 概念漂移综述论文阅读
首先这是2018年一篇关于概念漂移综述的论文[1]. 最新的研究内容包括 (1)在非结构化和噪声数据集中怎么准确的检测概念漂移.how to accurately detect concept dri ...
- 论文阅读(Xiang Bai——【PAMI2017】An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition)
白翔的CRNN论文阅读 1. 论文题目 Xiang Bai--[PAMI2017]An End-to-End Trainable Neural Network for Image-based Seq ...
- BITED数学建模七日谈之三:怎样进行论文阅读
前两天,我和大家谈了如何阅读教材和备战数模比赛应该积累的内容,本文进入到数学建模七日谈第三天:怎样进行论文阅读. 大家也许看过大量的数学模型的书籍,学过很多相关的课程,但是若没有真刀真枪地看过论文,进 ...
- 论文阅读笔记 - YARN : Architecture of Next Generation Apache Hadoop MapReduceFramework
作者:刘旭晖 Raymond 转载请注明出处 Email:colorant at 163.com BLOG:http://blog.csdn.net/colorant/ 更多论文阅读笔记 http:/ ...
随机推荐
- 使用亚马逊AWS云服务器进行深度学习——免环境配置/GPU支持/Keras/TensorFlow/OpenCV
前言 吐槽:由于科研任务,需要在云端运行一个基于神经网络的目标识别库,需要用到GPU加速.亚马逊有很多自带GPU的机器,但是环境的配置可折腾坏了,尤其是opencv,每次总会出各种各样的问题! 无奈中 ...
- ansible系列(1)--ansible基础
目录 1. ansible概述 1.1 ansible的功能 1.2 ansible的特性 1.3 ansible的架构 1.4 ansible注意事项 1. ansible概述 Ansible 是一 ...
- PostgreSQL世界上最先进的开源关系型数据库
PostgreSQL 的 Slogan 是 "世界上最先进的开源关系型数据库". PostgreSQL是一个功能非常强大.源代码开放的对象关系数据库系统(ORDBMS),在灵活的B ...
- addEventListener添加事件监听
removeEventListener移除事件监听 window.addEventListener('mousedown', e => this.closeMenu(e)) window.add ...
- 基于webapi的websocket聊天室(二)
上一篇 - 基于webapi的websocket聊天室(一) 消息超传缓冲区的问题 在上一篇中我们定义了一个聊天室WebSocketChatRoom.但是每个游客只分配了400个字节的发言缓冲区,大概 ...
- Docker批量删除容器/镜像
1.删除所有的容器 docker rm `docker ps -a -q` 2.删除所有的镜像 docker rmi `docker images -q` 提示: -q参数:只显示容器ID
- Uni-app极速入门(一) - 第一个小程序
Uni-app 介绍 官网:https://www.dcloud.io/index.html uni-app是为js开发者提供的一个全端开发框架,可以开发一次编译为web.App.小程序(微信/阿里/ ...
- Jenkins获取gitlab源代码
Jenkins获取gitlab源代码 Jenkins权限获取 在日常工作做由于Jenkins启动用户是Jenkins,在执行脚本时系统命令是无法让Jenkins执行的,如果需要Jenkins权限有两种 ...
- 8.24考试总结(NOIP模拟47)[Prime·Sequence·Omeed]
时间带着明显的恶意,缓缓在我的头顶流逝. T1 Prime 解题思路 成功没有签上到... 一看数据范围 \(R-L+1\le 10^7,R\le 10^{14}\) ,这肯定是判断范围内的数字是否可 ...
- 【论文笔记】轻量级网络MobileNet
[深度学习]总目录 MobileNet V1:<MobileNets: Efficient Convolutional Neural Networks for MobileVision Appl ...