Hive----基本概念
Hive 基本概念
1、 Hive:由 Facebook 开源用于解决海量结构化日志的数据统计。
2、 Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,并提供类 SQL 查询功能。
3、 本质是:将 HQL 转化成 MapReduce 程序
1) Hive 处理的数据存储在 HDFS
2) Hive 分析数据底层的实现是 MapReduce
3) 执行程序运行在 Yarn 上
4.Hive 的优缺点
优点
1) 操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
2) 避免了去写 MapReduce,减少开发人员的学习成本。
3) Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
4) Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较
高。
5) Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点
1.Hive 的 HQL 表达能力有限
(1) 迭代式算法无法表达
(2) 数据挖掘方面不擅长,由于 MapReduce 数据处理流程的限制,效率更高的算法却无法实现。
2.Hive 的效率比较低
(1) Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2) Hive 调优比较困难,粒度较粗
Hive 架构原理
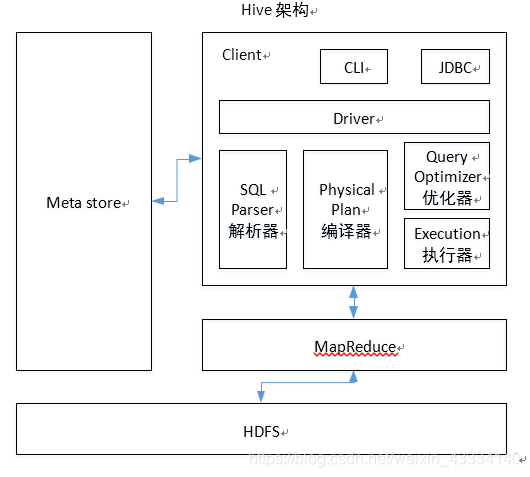
1.用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive)
2.元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore
3.Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。
4.驱动器:Driver
(1) 解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
(2) 编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
(3) 优化器(Query Optimizer):对逻辑执行计划进行优化。
(4) 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是 MR/Spark。
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver,结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将执行返回的结果输出到用户交互接口。
Hive 和数据库比较
由于 Hive 采用了类似 SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是 Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
查询语言
由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
数据更新
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修改数据。
执行
Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
可扩展性
由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009 年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
数据规模
由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive----基本概念的更多相关文章
- hive学习1(hive基本概念)
hive基本概念 hive简介 hive是什么 Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能. 为什么使用hive 1)简单易上手.提 ...
- Hive从概念到安装使用总结
一.Hive的基本概念 1.1 hive是什么? (1)Hive是建立在hadoop数据仓库基础之上的一个基础架构: (2)相当于hadoop之上的一个客户端,可以用来存储.查询和分析存储在hadoo ...
- 【Hive】概念、安装、数据类型、DDL、DML操作、查询操作、函数、压缩存储、分区分桶、实战Top-N、调优(fetch抓取)、执行计划
一.概念 1.介绍 基于Hadoop的数据仓库工具,将结构化数据映射为一张表,可以通过类SQL方式查询 本质:将HQL转换成MapReduce程序 Hive中具有HQL对应的MapReduce模板 存 ...
- Hive基础概念、安装部署与基本使用
1. Hive简介 1.1 什么是Hive Hives是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供类SQL查询功能. 1.2 为什么使用Hive ① 直接使用 ...
- [Hive_1] Hive 基本概念
Hive 系列01 Hive 简介 & Hive 应用场景 & Hive 与 Hadoop 的关系 & Hive 与传统数据库对比 1. Hive 简介 [ 官方介绍 ] Ap ...
- Hive基本概念
Hive Hive的相关概念 Hive的架构图 用户接口:包括 CLI.JDBC/ODBC.WebGUI.其中,CLI(command line interface)为shell命令行:Hive中的T ...
- 大数据开发实战:离线大数据处理的主要技术--Hive,概念,SQL,Hive数据库
1.Hive出现背景 Hive是Facebook开发并贡献给Hadoop开源社区的.它是建立在Hadoop体系架构上的一层SQL抽象,使得数据相关人员使用他们最为熟悉的SQL语言就可以进行海量数据的处 ...
- Hive(一)【基本概念、安装】
目录 一. Hive基本概念 1.1 Hive是什么 1.2 Hive的优缺点 1.3 Hive的架构 1.4 Hive和数据库的区别 二. Hive安装 2.1 安装地址 2.2 Mysql的安装 ...
- Hive Tutorial(上)(Hive 入门指导)
用户指导 Hive 指导 Hive指导 概念 Hive是什么 Hive不是什么 获得和开始 数据单元 类型系统 内置操作符和方法 语言性能 用法和例子(在<下>里面) 概念 Hive是什么 ...
- 《OD学hive》第四周0717
一.Hive基本概念.安装部署与初步使用 1. 后续课程 Hive 项目:hadoop hive sqoop flume hbase 电商离线数据分析 CDH Storm:分布式实时计算框架 Spar ...
随机推荐
- Python 基于lxml.etree实现xpath查找HTML元素
基于lxml.etree实现xpath查找HTML元素 By:授客 QQ:1033553122 #实践环境 WIN 10 Python 3.6.5 lxml-4.6.2-cp36-cp36m-win_ ...
- 图灵课堂netty 仿微信开发
通信的图文示例 以下是需要实现的前端界面, 准备工作:开始实现前需要技术关健字解释 第一步,这儿直接建一个maven 项目 就好,只要是可能用maven 管理包的环境就行,课程使用的版本是 java ...
- springsecurity使用:登录与校验
首先是引入依赖 <dependency> <groupId>org.springframework.boot</groupId> <artifactId> ...
- 【H5】02 <head>头标签介绍
摘自: https://developer.mozilla.org/zh-CN/docs/Learn/HTML/Introduction_to_HTML/The_head_metadata_in_HT ...
- 【Project】原生JavaWeb工程 03 单表的业务功能
年级表效果图样例: 可以看到主要分为以下这些功能: 功能一:展示年级列表 功能二:每个年级都具备修改和删除 功能三:添加一个年级 功能四:对多个年级选中删除,也可以全选删除,或者反选删除 功能五:根据 ...
- 深度学习需要float64精度吗 —— 为什么各大深度学习框架均不支持float64的深度学习运算呢 —— 商用NVIDIA显卡的float64性能是否多余呢
首先要知道这么几个事实,也是交代一下本文要讨论的问题的背景: 各大深度学习框架均支持float64类型的简单运算,但是均不支持float64的深度学习的运算操作: 作为深度学习运行的加速设备,各种GP ...
- openAI的仿真环境Gym Retro的Game Integration——新游戏融合(2)( 示例 demo )
内容接前文: openAI的仿真环境Gym Retro的Game Integration--新游戏融合(将retro中没有融合的ROM游戏加入其中) 前文大致简单的介绍了gym retro 库对新游戏 ...
- Win32 拆分窗口
前两天学习了MFC的拆分窗口,今天来学习Win32 SDK下如何拆分窗口. win32是没有像MFC那样直接有函数方法拆分窗口,只能自己处理了. 1.在WM_CREATE消息中创建两个控件,TreeV ...
- 在 Ubuntu 环境下 Qt Creator 无法使用搜狗输入法
在 Ubuntu 环境下 Qt Creator 无法使用搜狗输入法 在 Ubuntu 中安装 Qt Creator 后,发现无法使用搜狗输入法.切换输入法也没有效果. 最初以为是搜狗输入法出了问题,后 ...
- LaTeX cleveref 宏包用法
介绍 cleveref 宏包是 LaTeX 中用于增强交叉引用功能的一个强大工具.它的主要特点是能够自动地按照不同元素的类型(如章节.图表等)生成格式化的引用,同时还支持定制引用格式,提供了比 LaT ...