开发必会系列:《深入理解JVM(第二版)》读书笔记
- http://www.cnblogs.com/sunilsun/p/6078171.html ubuntu 编译OPENJDK8
- 运行时内存
- 运行时数据区:
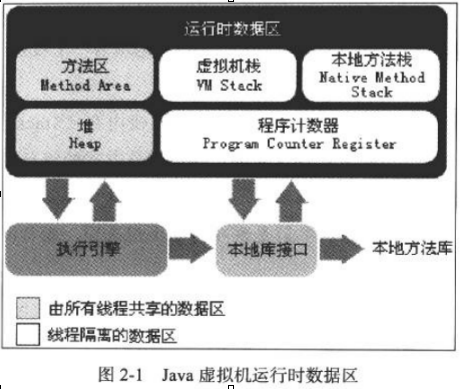
- 线程请求的栈深度大于虚拟机所允许的深度——StackOverflowError
- 当前大部分虚拟机可动态扩展,虚拟机栈在动态扩展时无法申请到足够的内存——OutOfMemoryError
- 本地方法栈:
- Java堆:
- 方法区:
- 检查完类加载,虚拟机就为新生对象分配内存。大小在类加载完后就能确定了。分配内存会触发java堆中指针碰撞(Bump the Pointer)或空闲列表(Free List)——遇到并发,可以采用CAS保证原子性或TLAB本地线程分配缓冲。
- 对对象进行设置,把类元数据信息、对象哈希码、对象GC分代年龄存到对象头(Object Header)
- 这时虚拟机的活干完了,但java程序还需要执行<init>方法
- 在Debug/Run的VM arguments写
- 在代码中做文档注释写:
- 虚拟机栈和本地方法栈溢出
- 方法区和运行时常量池溢出
- 垃圾收集器和内存分配策略
- 判断堆里实例对象死了没
- 引用,JDK1.2后,引用分四类:
- 方法区回收
- 垃圾收集算法
- hotspot的算法实现
- 具体咋收垃圾?垃圾收集器

- 虚拟机性能监控与故障处理工具
- jdk命令行工具
- jps,虚拟机进程状况工具。进程的本地虚拟机唯一ID(Local Virtual Machine Identifier, LVMID),它与操作系统进程(Process Identifier, PID)一致。
- 可视化工具
- 调优实战
- 高性能硬件上的程序部署策略
- 通过64位JDK来使用大内存
- 使用若干个32位虚拟机建立逻辑集群来利用硬件资源

- 集群间同步导致的内存溢出:避免过于频繁的写操作。
- 堆外内存导致的溢出错误:直接内存的问题

- 类文件结构
- 魔数
- 常量池
- 常量池后面,是访问标志,用于识别类或接口的访问信息。比如:这个Class是类还是接口,它是不是public类型……
- 后面是类索引、父类索引和接口索引,这三项数据确定这个类的继承关系。
- 后面是字段表集合,字段表用于描述接口或者类中声明的变量。此外还有方法表和属性表。
- 虚拟机类加载机制
- 类加载过程
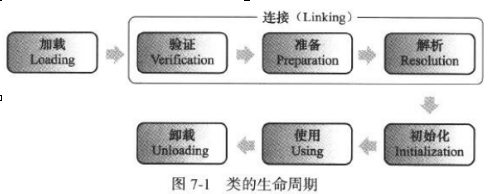
- 类加载器:
- 虚拟机如何执行定义在Class文件里的字节码
- 运行时栈针结构
- 局部变量表:其容量以变量槽(Variable Slot)为最小单位。
- 运行期优化
- 虚拟机刚开始用解释器解释执行,省编译时间,但渐渐发现某个代码很常用,就通过即时编译器JIT把它编译成与本地平台相关的机器码,提高运行效率。如何发现热点代码——方法调用计数器,计数器超过一定阈值,就触发JIT编译。
- 线程安全和锁优化
- 线程安全实现:
- 互斥同步:属于悲观,重量级锁。
- 非阻塞同步:乐观。
- 无同步
- 锁优化
- 自旋锁与自适应自旋:
- 锁消除:
- 锁粗化:
- 轻量级锁:
- 偏向锁:
开发必会系列:《深入理解JVM(第二版)》读书笔记的更多相关文章
- Spring 实战 第4版 读书笔记
第一部分:Spring的核心 1.第一章:Spring之旅 1.1.简化Java开发 创建Spring的主要目的是用来替代更加重量级的企业级Java技术,尤其是EJB.相对EJB来说,Spring提供 ...
- 深入浅出MySQL 数据库开发、优化与管理维护(第2版) -- 读书笔记 -- 基础篇
1.切换数据库 use blog; 2.显示当前数据库 所有的表. show tables; +----------------+ | Tables_in_blog | +------------ ...
- Spring实战第4版PDF下载含源码
下载链接 扫描右侧公告中二维码,回复[spring实战]即可获取所有链接. 读者评价 看了一半后在做评论,物流速度挺快,正版行货,只是运输过程有点印记,但是想必大家和你关注内容,spring 4必之3 ...
- Spring实战(第4版).pdf - 百度云资源
http://www.supan.vip/spring%E5%AE%9E%E6%88%98 Spring实战(第4版).pdf 关于本书 Spring框架是以简化Java EE应用程序的开发为目标而创 ...
- Spring实战第六章学习笔记————渲染Web视图
Spring实战第六章学习笔记----渲染Web视图 理解视图解析 在之前所编写的控制器方法都没有直接产生浏览器所需的HTML.这些方法只是将一些数据传入到模型中然后再将模型传递给一个用来渲染的视图. ...
- Spring实战第五章学习笔记————构建Spring Web应用程序
Spring实战第五章学习笔记----构建Spring Web应用程序 Spring MVC基于模型-视图-控制器(Model-View-Controller)模式实现,它能够构建像Spring框架那 ...
- Spring实战第四章学习笔记————面向切面的Spring
Spring实战第四章学习笔记----面向切面的Spring 什么是面向切面的编程 我们把影响应用多处的功能描述为横切关注点.比如安全就是一个横切关注点,应用中许多方法都会涉及安全规则.而切面可以帮我 ...
- 将Spring实战第5版中Spring HATEOAS部分代码迁移到Spring HATEOAS 1.0
最近在阅读Spring实战第五版中文版,书中第6章关于Spring HATEOAS部分代码使用的是Spring HATEOAS 0.25的版本,而最新的Spring HATEOAS 1.0对旧版的AP ...
- ASP.NET MVC开发必看系列
一.关于HTTP协议的那些事 这可以说我们开发WEB程序的空气,推荐不断温故知新! HTTP协议 (一) HTTP协议详解 HTTP协议 (二) 基本认证 HTTP协议 (三) 压缩 HTTP协议 ( ...
- Spring实战 (第3版)——AOP
在软件开发中,分布于应用中多处的功能被称为横切关注点.通常,这些横切关注点从概念上是与应用的 业务逻辑相分离的(但是往往直接嵌入到应用的业务逻辑之中).将这些横切关注点与业务逻辑相分离正是 面向切面编 ...
随机推荐
- dotnet-cnblog tool 测试案例
这是测试donet-cnblog工具是否能将正常的Typora图片转换为博客园格式 测试1:本地图片导入 测试2:QQ截图 测试3:url https://pics3.baidu.com/feed/9 ...
- NC16742 [NOIP2002]字串变换
题目链接 题目 题目描述 已知有两个字串 A, B及一组字串变换的规则(至多6个规则): A1 -> B1 A2 -> B2 规则的含义为:在A中的子串 A1可以变换为 B1.A2可以变换 ...
- 统一日志输出打印POST请求参数
众所周知,request.getInputStream()只能调一次.如果希望在请求进入Controller之前统一打印请求参数(拦截器或过滤器),又不影响业务,我们只能将获取到的输入流缓存起来,后续 ...
- php+bootstrap+jquery+mysql实现购物车项目案例
获取源码 一键三连后,评论区留下邮箱安排发送:) 介绍 使用php,bootstrap,jquery,mysql实现的简易购物车案例. 通过本案例,你将学习到以下知识点: php 操作 mysql 实 ...
- gitlab+jenkins+docker持续集成环境搭建实战
介绍 什么是持续集成? 持续集成(CI)是在源代码变更后自动检测.拉取.构建和(在大多数情况下)进行单元测试的过程.持续集成是启动管道的环节(尽管某些预验证 -- 通常称为 上线前检查(pre-fli ...
- 美团面试:Kafka如何处理百万级消息队列?
美团面试:Kafka如何处理百万级消息队列? 在今天的大数据时代,处理海量数据已成为各行各业的标配.特别是在消息队列领域,Apache Kafka 作为一个分布式流处理平台,因其高吞吐量.可扩展性.容 ...
- C++ 多线程的错误和如何避免(2)
试图 join 一个已经 detach 的线程 如果你已经在某个地方分离了线程,那你不可以在主线程再次 join,这是一个明显的错误 比如: #include <iostream> #in ...
- Java常用编程类库
Java语言已经有许多非常成熟的开源基础类库,封装了日常开发中的各种常用操作,如:对象判空,字符串编码,本地缓存等等. 可以直接在项目中引入对应类库使用即可,或者参与完善相应类库的方法. 现将常用的基 ...
- 启动HDFS伪分布式环境时报权限错误
问题描述 操作系统:Ubuntu18.04 LTS HDFS版本:hadoop-3.2.3 普通用户登录,参照官方文档在单机上安装伪分布式环境时,启动HDFS报权限错误. 具体报错信息如下: $ ./ ...
- Android加载PDF方案(pdf.js,支持缩放)
都知道,Android本身的webview是不支持pdf加载的(比不上iOS的webview,谁让人家NB呢),因此通过连接Google的一个服务器转换成功后返回给WebView显示.但是,但是,但是 ...