GaussDB(for MySQL)如何快速创建索引?华为云数据库资深架构师为您揭秘
摘要:云服务环境下,如何解决客户基于大量数据创建索引的性能问题,成为云服务厂商的一个挑战。华为云GaussDB(for MySQL)通过引入并行创建索引技术,很好地解决了批量索引创建和临时添加索引等性能瓶颈问题,帮助用户更快建立好索引。想要进一步了解快速创建索引的秘诀,请不要错过本文。
本文分享自华为云社区《GaussDB(for MySQL)如何快速创建索引?华为云数据库资深架构师为您揭秘》,作者:华为云数据库资深架构师苏斌。

苏斌,华为云数据库资深架构师,拥有16年数据库内核研发经验,之前作为MySQL官方InnoDB团队主要研发人员,参与和主导了多个重要特性的开发和发布。目前在华为公司负责和参与华为云RDS主要产品RDS for MySQL和GaussDB(for MySQL)内核功能的设计和研发。
导读
云服务环境下,如何解决客户基于大量数据创建索引的性能问题,成为云服务厂商的一个挑战。华为云GaussDB(for MySQL)通过引入并行创建索引技术,很好地解决了批量索引创建和临时添加索引等性能瓶颈问题,帮助用户更快建立好索引。想要进一步了解快速创建索引的秘诀,请不要错过本文。
关于MySQL索引
我们都知道,数据库使用索引技术加快数据的查询。MySQL数据库也支持若干种索引结构提高查询的性能(参见MySQL文档:https://dev.mysql.com/doc/refman/8.0/en/create-index.html),其中使用最广泛的是B+tree索引,因为B+tree索引在查询和修改的性能之间有很好的平衡,同时其存储和维护的代价也是比较优的。
MySQL的表本身由聚簇索引(必须是B+tree索引)表示,再加上若干个二级索引,包括B+tree索引,共同组成一个MySQL的独立表,可以说MySQL的表是由一组索引共同组成的。我们都知道索引是一把双刃剑,充分的索引可以更好地提升可以适配的查询的性能,但是需要维护这些索引使得其和数据同步,所以在数据修改操作阶段,更多的索引也会带来更高的开销。索引创建与否的权衡通常是动态的,用户不一定能做到在表定义之初就知道需要建立哪些索引,需要随着业务的发展变化而调整索引,这也带来了动态索引创建的一些问题。
MySQL的索引创建逻辑
我们先看一下MySQL索引创建的逻辑。首先,MySQL索引的创建可以使用两种不同的DDL(Data Definition Language: 数据定义语言)算法来实现。第一种是COPY算法,它非常低效,就是在两个表之间进行数据拷贝,来完成表结构相关的修改,尤其是它要求加表锁,现在基本不使用了。第二种是INPLACE算法,该算法不要求加锁,因此很多DDL操作是不阻塞DML(Data Manipulation Language: 数据操纵语句)操作的,比如创建索引。该算法具体的实现在存储引擎层面完成,可以进行更多的优化。实际上DDL语句还有一种INSTANT算法,但是它无法支持创建索引操作,这里不展开介绍。
对于INPLACE算法,在5.7版本之前,是采用索引记录不断地向建好的空索引插入的方式。由于插入的数据的无序性,该方法导致了明显的性能问题和潜在的空间浪费。在5.7版本以后,MySQL优化了建索引步骤,将其改进为对已排序的索引记录进行自底向上批量插入并且紧凑拼装的创建方式,如果有多个索引要创建,会单独对每个索引执行相同的算法。新的算法会经历读取数据、排序数据和创建索引这几个主要步骤。
总体而言,创建索引这类DDL操作,会比普通的DML等操作要费时,而该类DDL耗时会导致用户在继续动态添加索引加速查询的时候,需要等待很长的时间,极大影响业务;而且用户的MySQL实例开启了Binlog复制,耗时的DDL操作容易引起备库的长时间落后。
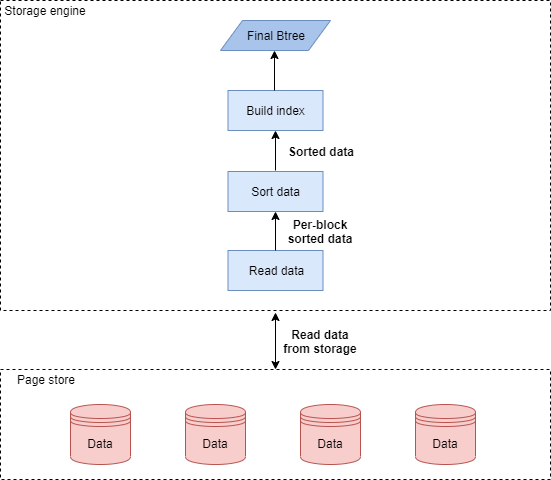
MySQL的创建索引流程图
云化场景下索引创建的问题
随着越来越多用户把数据托管在云服务上,以及用户数据量的不断增长,前述的动态添加索引导致的问题非常影响用户体验。同时客户的单表数据逐渐达到几TB甚至几十TB,客户对创建索引太慢所带来的性能问题的抱怨越来越多,尤其是创建索引周期如果太长,我们可能很难找到一段合适的业务低峰期来动态创建索引,避免业务的波动。因此,如何在云服务环境下,解决客户基于大量数据创建索引的性能问题,成为云服务厂商的一个挑战。
在云化场景下,还有一个主要场景对客户的体验非常重要。我们知道客户的业务要迁移上云,需要对数据进行大规模的迁移(华为云提供了数据复制服务DRS工具支持各类数据迁移场景),数据迁移比较高效的方式为:
- 逻辑导出源端数据
- 在目标端建表(注意,表不含二级索引)
- 将源端导出的数据插入到目标端
- 对目标端的表建立二级索引
如果涉及动态数据同步,相关步骤会更复杂一些,由于和该主题无关,这里不展开。以上步骤中,需要重点注意的是步骤2和4,在目标端创建表的时候先不创建二级索引。这个优化对性能影响很大,尤其是一个表有很多二级索引的场景。我们知道Btree索引的插入如果是有序的,对插入性能和结果的空间利用率是最好的,因为Btree索引的分裂会在插入区域的尾部产生,同时由于分裂算法的优化,分裂产生的页面填充率会比较高;相反地,如果是随机插入,尤其是并发地随机插入,很容易导致Btree索引在不同的节点进行分裂,并且分裂后的页面填充率都处于一个半满的状态,导致Btree最终的一个膨胀。
有了这个背景之后,我们就容易理解上面的问题,插入表数据的时候,我们屏蔽了二级索引,等所有数据都准备好了,再采用批量建立索引的方式创建二级索引,这对于二级索引创建效率是最高的。如果不这么做,每插入一条记录,就要去插入相应的二级索引,那么二级索引就是一个无序的随机插入,并发起来性能会变差很多。
虽然在数据同步准备好后,批量创建二级索引是一个有效的方案,但是如果数据量很大,这么创建二级索引还是非常耗时,导致客户在数据迁移完之后需要等待很长时间才能开展业务,这个等待周期可能是小时甚至天级别的。虽然可以考虑表级别的并发创建索引,但是这个方法也有明显的缺点:应用场景有限,要求有多表;以及表和表之间的并发其实不是一个最有效的并发形式,相互影响比较大。
GaussDB(for MySQL)如何快速创建索引?
综上所述,在创建索引这个点上存在两个性能瓶颈点:一个是用户迁移数据之后的批量索引创建;第二个是用户临时需要添加一个二级索引。无论哪个点,我们都需要更快的建立好索引,提升用户的使用体验。
华为云GaussDB(for MySQL)引入了并行创建索引的技术,它改进了社区版MySQL创建索引只用单线程的问题,以此提高创建索引的效率,并一起解决了前述两个痛点。前面提到的社区版创建索引逻辑是单线程的,首先存在资源利用率不够饱满的问题;其次创建索引过程是CPU和IO开销交替进行的过程,在做一个操作的时候,即使不是资源竞争的操作也只有等待。多线程创建索引可以充分利用CPU和IO资源,同时有的线程在做CPU计算时,别的线程可以并发的做IO操作。
GaussDB(for MySQL)使用的并行创建索引,是一个全链路的并行技术。前面提到,创建索引包含了若干个阶段,我们的并行创建算法,对这里的每个阶段都做并行处理,从读取数据、排序、到创建索引,都是并行操作,每一步都由指定的N个线程并发处理。它的逻辑如下图所示:
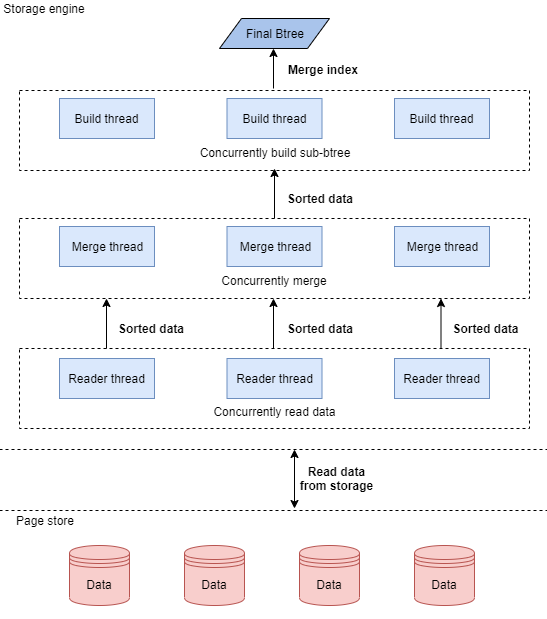
GaussDB(for MySQL)尤其对数据的归并排序做了多种优化,使得我们常规的归并排序能够充分的并行,充分利用CPU、内存和IO的资源。在并行创建索引之后的合并步骤,也使用了一套简化的算法,正确处理各种索引结构的场景。
支持的索引和场景
GaussDB(for MySQL)的并行创建索引功能,目前支持的索引为Btree二级索引。对于virtual index二级索引,将会在不久的将来提供全面的支持,而MySQL的spatial index和fulltext index不在该并行创建索引覆盖范围内。
特别要注意的是,主键索引的创建目前也是不支持并行的,因此如果一个并行创建索引的SQL语句包含创建主键索引,或者前面提及的spatial index与fulltext index,那么客户端将会收到一个告警,提示该操作不支持并行创建索引,同时该语句会采用单线程创建索引的方式执行完成。
从SQL语句的角度,如前所述,创建索引可以采用不同的算法,由于COPY算法(ALGORITHM=COPY)不是采用批量插入的方式,因此不会受益于该并行创建索引优化。而对于INPLACE算法,如果创建索引用的是非rebuild的方式,都可以受益于该优化;一旦需要使用rebuild的方式创建索引,因为涉及到主键索引的建立,将无法使用并行创建索引的算法。
示例
下面我们通过几个实例来了解一下如何使用并行创建索引算法加快创建速度,以及我们的条件约束是如何生效的。
1、我们使用sysbench的表,表内有1亿条数据
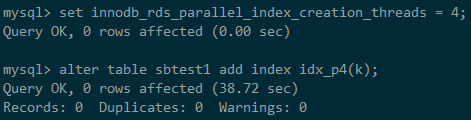
2、在该表的k字段建索引,采用社区默认单线程,耗时146.82s

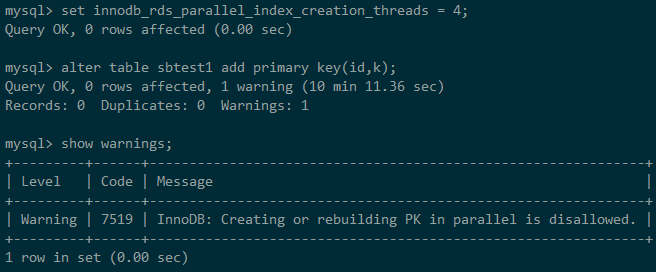
3、通过设置innodb_rds_parallel_index_creation_threads = 4启用4个线程建索引,可以看到建索引耗时38.72s,速度提升3.79倍。
4、假设我们要修改主键索引,虽然指定了多线程,但是会收到一个warning,实际上只能通过单线程建索引
注意事项
首先对innodb_rds_parallel_index_creation_threads这个参数进行一下说明,它控制了系统中所有并行DDL可以使用的总线程数,取值范围是[1-128]。该参数取值为1表示使用原始的单线程创建索引,取值为N,表示接下来的DDL使用N个线程创建。如果一个DDL使用了100个线程在执行,那么另外一个也要使用并行的DDL且最多只能使用剩下的28个线程;而如果128个线程都被并行DDL语句占用了,新来的DDL只能走原始的单线程创建的逻辑。
虽然该并行创建索引加快了索引的创建速度,但是在具体使用场景下,还是需要有审慎的评估。我们知道在并行算法应用之后,该DDL对硬件资源的使用会尽可能的充分,这也意味着其它操作就得不到太多的资源了。因此,针对不同的场景需要具体地分析,它决定了我们如何创建索引。
对于迁移场景,由于这时候还没有任何业务接入,用户希望尽快完成所有索引的创建,因此可以尽量设置多线程数,比如我们是16核规格的实例,那么我们就可以把并行线程的数量指定为16,加速完成操作。
如果是用户业务运行阶段要创建索引,我们还是不希望DDL操作,对正在运行的业务如DML操作等有太多的影响。因此,这时候创建索引可以指定相对少一些的线程数量,比如2-4(或者根据CPU规格以及负载决定,同时不鼓励并发地执行多个DDL操作)。这样既能相对地加速创建索引的进程,也能保证DML的正常进行。
综上所述,GaussDB(for MySQL)支持了并行创建索引,通过缩短创建索引使用的时间,很好地解决了客户关切的两类问题,提升了客户的体验。但技术无止境,在创建索引领域,还有其它的问题需要我们优化解决,例如如何减少创建索引步骤对IO的影响等等。我们后续会针对这些点进行优化,给客户带来更多的惊喜。
目前,华为云GaussDB(for MySQL) 并行创建索引优化功能已上线,欢迎大家前往华为云官网体验:https://www.huaweicloud.com/product/gaussdb_mysql.html
附:华为云GaussDB(for MySQL)内核专家系列文章
华为海外女科学家为您揭秘:GaussDB(for MySQL)云栈垂直集成的力量有多大?
华为云数据库内核专家为您揭秘:GaussDB(for MySQL)并行查询有多快?
GaussDB(for MySQL)如何快速创建索引?华为云数据库资深架构师为您揭秘的更多相关文章
- 华为云Stack首席架构师:打造“称手”的数字化工具,答好政企IT数字化转型这道必选题
摘要:数字化转型是一号位工程,数字化的工具本身就是企业的核心竞争力. 本文分享自华为云社区<华为云Stack首席架构师:打造"称手"的数字化工具,答好政企IT数字化转型这道必 ...
- 华为云数据库GaussDB(for Cassandra)揭秘第二期:内存异常增长的排查经历
摘要:华为云数据库GaussDB(for Cassandra) 是一款基于计算存储分离架构,兼容Cassandra生态的云原生NoSQL数据库:它依靠共享存储池实现了强一致,保证数据的安全可靠. 本文 ...
- 【云享专刊】开源遇上华为云,OCP架构变身“云原生框架”
摘要:华为云DTSE团队出品云原生改造指南,助力轻松实践OCP上云. 本文分享自华为云社区<[云享专刊]开源遇上华为云,OCP架构变身"云原生框架">,作者:华为云社区 ...
- mysql百万的数据快速创建索引
测试数据本机一张表users有100百万条记录.在创建此表前没有未相应字段添加索引,所以此时需要为表添加索引.但是因为数据量大的原因,索引添加可能不成功,想了很多办法,终于挖坑成功. 开始准备工作, ...
- mysql如何快速创建相同结构的表
[1]. 快速创建相同结构的表,包括索引: mysql> SHOW CREATE TABLE a; CREATE TABLE `a` ( `name` varchar(50) default N ...
- MySql分区后创建索引加速单表查询和连表查询
版权声明:本文为博主原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接和本声明.本文链接:https://blog.csdn.net/konkon2012/article/de ...
- Mysql建表+创建索引
创建表时可以直接创建索引,这种方式最简单.方便.其基本形式如下: CREATE TABLE 表名( 属性名 数据类型[完整性约束条件], 属性名 数据类型[完整性约束条件], ...... 属性名 数 ...
- 资深架构师Sum的故事:(Mysql)InnoDB下,存储过程中事务的处理
| 故事背景 话说有一回,X市X公司的产品经理Douni兴致冲冲的跑来和Sum(Sum,X市X公司资历8年程序猿,技能:深思.熟虑.心细.深究.技术过敏.口头禅:嗯,容我想想.坚信:只要赚钱的业务,我 ...
- MySQL 快速创建索引
用SELECT INTO OUTFILE导出记录,TRUNCATE 此TABLE,建立索引,用LOAD DATA INIFILE再导入 缺点:不支持热操作
- 通过哪吒动漫豆瓣影评,带你分析python爬虫与BeautifulSoup快速入门【华为云技术分享】
久旱逢甘霖 西安连着几天温度排行全国三甲,也许是<哪吒之魔童降世>的剧组买通了老天,从踩着风火轮的小朋友首映开始,就全国性的持续高温,还好今天凌晨的一场暴雨,算是将大家从中暑边缘拯救回来了 ...
随机推荐
- 栈溢出-GOT表劫持测试
1.目标程序源代码 char name[64]; int main(){ int unsigned long long addr; setvbuf(stdin,0,2,0); setvbuf(stdo ...
- 前端JavaScript编码规范 和react编码规范
JavaScript编码规范 点击链接查看:https://github.com/ecomfe/spec/blob/master/javascript-style-guide.md 前端React编码 ...
- 🔥🔥你以为你了解TCP协议?这些你可能不知道的细节才是关键!
引言 在之前的内容中,我们已经详细讲解了TCP面试中最常见的问题,如三次握手和四次挥手等.而今天,我们将继续深入探讨TCP协议的其他方面,比如序列号和TCP Fast Open(TFO)等重要细节问题 ...
- 快速教程|如何在 AWS EC2上使用 Walrus 部署 GitLab
Walrus 是一款基于平台工程理念的开源应用管理平台,致力于解决应用交付领域的深切痛点.借助 Walrus 将云原生的能力和最佳实践扩展到非容器化环境,并支持任意应用形态统一编排部署,降低使用基础设 ...
- win10安装WSL2
什么是WSL2 首先我们理解一下什么是WSL Windows Subsystem for Linux(简称WSL)是一个在Windows 10\11上能够运行原生Linux二进制可执行文件(ELF格式 ...
- 在vue中如何使用echart
1.在前面基础上搭建好vue环境,初始化webpack后,在终端使用npm i echarts -s 下载echart 2.下载完成后全局使用echart 在main.js文件中导入 import e ...
- Keepalived+Nginx高可用案例(抢占式与非抢占式)
(1)下载安装Keepalived源码包 Keepalived官网源码包下载地址 在服务器上解压 tar -xf keepalived-2.2.8.tar.gz 安装相关前置依赖 yum -y ins ...
- 深入了解Rabbit加密技术:原理、实现与应用
一.引言 在信息时代,数据安全愈发受到重视,加密技术作为保障信息安全的核心手段,得到了广泛的研究与应用.Rabbit加密技术作为一种新型加密方法,具有较高的安全性和便捷性.本文将对Rabbit加密技术 ...
- 🔥🔥Java开发者的Python快速进修指南:面向对象--高级篇
首先,让我来介绍一下今天的主题.今天我们将讨论封装.反射以及单例模式.除此之外,我们不再深入其他内容.关于封装功能,Python与Java大致相同,但写法略有不同,因为Python没有修饰符.而对于反 ...
- 解密Prompt系列20. LLM Agent之再谈RAG的召回多样性优化
几个月前我们就聊过RAG的经典方案解密Prompt系列14. LLM Agent之搜索应用设计.前几天刚看完openAI在DevDay闭门会议上介绍的RAG相关的经验,有些新的感悟,借此机会再梳理下R ...