Grafana监控java应用以及vCenter的方法
Grafana监控java应用以及vCenter的方法
背景
最开始弄过vCenter的监控.但是发现很多地方已经不合适了.今天看了下jmx监控 java的应用. 顺便监控了下vCenter.这里简单记录一下, 以便备忘.需要注意的是 这里其实并不优秀 因为使用了agent 可能对产品有负面影响.
jmx监控
思路:利用 javaagent的方式暴露一个端口出来.然后通过prometheus 收集暴露出来的数据通过grafana进行展示.需要下载的文件主要有:jmx_prometheus_javaagent-0.17.2.jarprometheus-2.39.0-rc.0.linux-amd64.tar.gzgrafana-enterprise-9.1.6-1.x86_64.rpm
jmx监控准备
- 添加一个配置文件:
cat >simple-config.yml <<-EOFlowercaseOutputLabelNames: truelowercaseOutputName: truewhitelistObjectNames: ["java.lang:type=OperatingSystem"]blacklistObjectNames: []rules:- pattern: 'java.lang<type=OperatingSystem><>(committed_virtual_memory|free_physical_memory|free_swap_space|total_physical_memory|total_swap_space)_size:'name: os_$1_bytestype: GAUGEattrNameSnakeCase: true- pattern: 'java.lang<type=OperatingSystem><>((?!process_cpu_time)\w+):'name: os_$1type: GAUGEattrNameSnakeCase: trueEOF
启动脚本修改
在启动脚本的地方增加如下配置.-javaagent:./jmx_prometheus_javaagent-0.17.2.jar=8080:simple-config.yml添加之后启动服务就可以了.
修改prometheus
安装prometheus. 然后进行相应的配置tar包安装非常简单, 建议直接在 /prometheus 目录下进行解压缩.然后修改 prometheus.yaml 文件, 添加对应就可以了.我这边的配置文件如下:注意1: 需要记住 job_name. grafana里面需要进行设置.注意2: instance: grafana里面可以进行区分.scrape_configs:- job_name: jmxstatic_configs:- targets: ['localhost:8080']labels:instance: xxx-server- targets: ['10.110.83.113:8080']labels:instance: xxx-dm
安装Grafana
rpm包安装grafana就可以了.安装成功后:systemctl enable grafana-server.servicesystemctl restart grafana-server.service注意需要设置一下密码默认密码是 admin/admin
配置Grafana
第一步: 增加数据源点击左下角的齿轮状配置按钮.add data source选择prometheus就可以了.注意可以讲本地IP地址设为白名单.然后将本地IP地址添加进去.第二步: 导入dashboard点击左上角 四个正方形的按钮.browse 然后点击new 的下拉列表. 选择import输入: 8563就可以导入 JVM dashboard
效果图
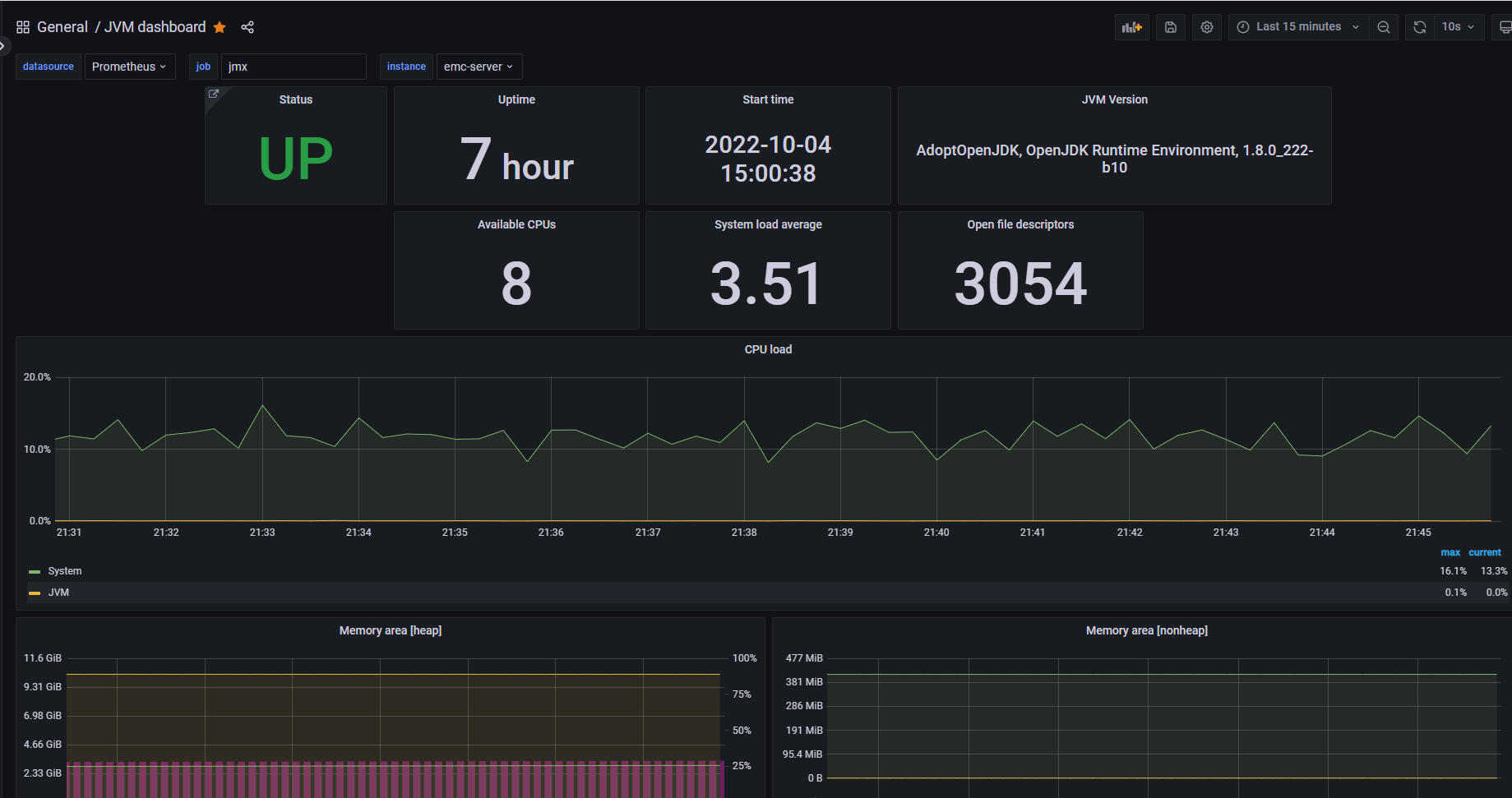
vCenter的展示
跟之前写的一样, 这里面用到了influxdb以及telegraf需要的文件主要有:influxdb-1.8.9.x86_64.rpmtelegraf-1.19.2-1.x86_64.rpm注意安装方式有是本地安装就可以.这里吐槽一下OpenEuler:第一: ESXi使用 6.7 More的兼容配置,无法读取安装介质.无法安装第二: influxdb 安装完没有形成 influxdb 的配置文件的步骤.
influxdb的设置.
这里还是用的1.x本着够用就好的方针..安装完成之后 命令行输入 influx 就可以登录数据库需要注意的是 需要先启动服务systemctl restart influxdb添加用户以及修改密码的命令:CREATE USER "influxdb" WITH PASSWORD 'Test@xxxxxxx'GRANT ALL PRIVILEGES TO influxdb
Telegraf 的设置
注意 Telegraf里面添加了配置之后会自动创建数据库.另外需要注意的是 要监控vCenter 可能需要两个Telegraf来运行但是可以导入到一个influxdb的数据库里面.配置文件举例为:/etc/telegraf/{telegraf01.conf,telegraf02.conf}注意两个配置文件唯一不同的可能就是 vcenter的用户以及密码.需要注意 主要有input和output 两处设置.模板就是如下:
Telegraf模板配置文件
[global_tags][agent]interval = "10s"round_interval = truemetric_batch_size = 1000metric_buffer_limit = 10000collection_jitter = "0s"flush_interval = "10s"flush_jitter = "0s"precision = ""hostname = ""omit_hostname = false[[outputs.influxdb]]#这里需要修改。urls = ["http://127.0.0.1:8086"]database = "vm187"timeout = "0s"username = "zhaobsh"password = "Test@xxxx"[[inputs.vsphere]]# 这里需要设置为密码vcenters = [ "https://10.110.xx.xx/sdk" ]username = "administrator@vsphere.local"password = "somepassword"vm_metric_include = ["cpu.demand.average","cpu.idle.summation","cpu.latency.average","cpu.readiness.average","cpu.ready.summation","cpu.run.summation","cpu.usagemhz.average","cpu.used.summation","cpu.wait.summation","mem.active.average","mem.granted.average","mem.latency.average","mem.swapin.average","mem.swapinRate.average","mem.swapout.average","mem.swapoutRate.average","mem.usage.average","mem.vmmemctl.average","net.bytesRx.average","net.bytesTx.average","net.droppedRx.summation","net.droppedTx.summation","net.usage.average","power.power.average","virtualDisk.numberReadAveraged.average","virtualDisk.numberWriteAveraged.average","virtualDisk.read.average","virtualDisk.readOIO.latest","virtualDisk.throughput.usage.average","virtualDisk.totalReadLatency.average","virtualDisk.totalWriteLatency.average","virtualDisk.write.average","virtualDisk.writeOIO.latest","sys.uptime.latest",]host_metric_include = ["cpu.coreUtilization.average","cpu.costop.summation","cpu.demand.average","cpu.idle.summation","cpu.latency.average","cpu.readiness.average","cpu.ready.summation","cpu.swapwait.summation","cpu.usage.average","cpu.usagemhz.average","cpu.used.summation","cpu.utilization.average","cpu.wait.summation","disk.deviceReadLatency.average","disk.deviceWriteLatency.average","disk.kernelReadLatency.average","disk.kernelWriteLatency.average","disk.numberReadAveraged.average","disk.numberWriteAveraged.average","disk.read.average","disk.totalReadLatency.average","disk.totalWriteLatency.average","disk.write.average","mem.active.average","mem.latency.average","mem.state.latest","mem.swapin.average","mem.swapinRate.average","mem.swapout.average","mem.swapoutRate.average","mem.totalCapacity.average","mem.usage.average","mem.vmmemctl.average","net.bytesRx.average","net.bytesTx.average","net.droppedRx.summation","net.droppedTx.summation","net.errorsRx.summation","net.errorsTx.summation","net.usage.average","power.power.average","storageAdapter.numberReadAveraged.average","storageAdapter.numberWriteAveraged.average","storageAdapter.read.average","storageAdapter.write.average","sys.uptime.latest",]cluster_metric_include = []datastore_metric_include = []datacenter_metric_include = []datacenter_metric_exclude = [ "*" ]insecure_skip_verify = true
手动启动telegraf
nohup telegraf -config /etc/telegraf/telegraf01.conf >/dev/null 2>1.txt &nohup telegraf -config /etc/telegraf/telegraf02.conf >/dev/null 2>2.txt &注意 手动启动就可以. 重启机器后需要重新启动.
Grafana监控vCenter
第一步: 添加数据源:注意选择influxdb地址可以输入ip地址比如我这个:http://10.110.136.70:8086influxdb数据库选择 telegraf里面定义的那个用户密码输入 创建的有权限的用户和密码就可以了.
Grafana监控vCenter
导入grafana的配置项目主要有如下三个:其他的好像需要更高的版本名称 编号vSphere - Overview 12786vSphere - Host details 12852vSphere - VM details 12874
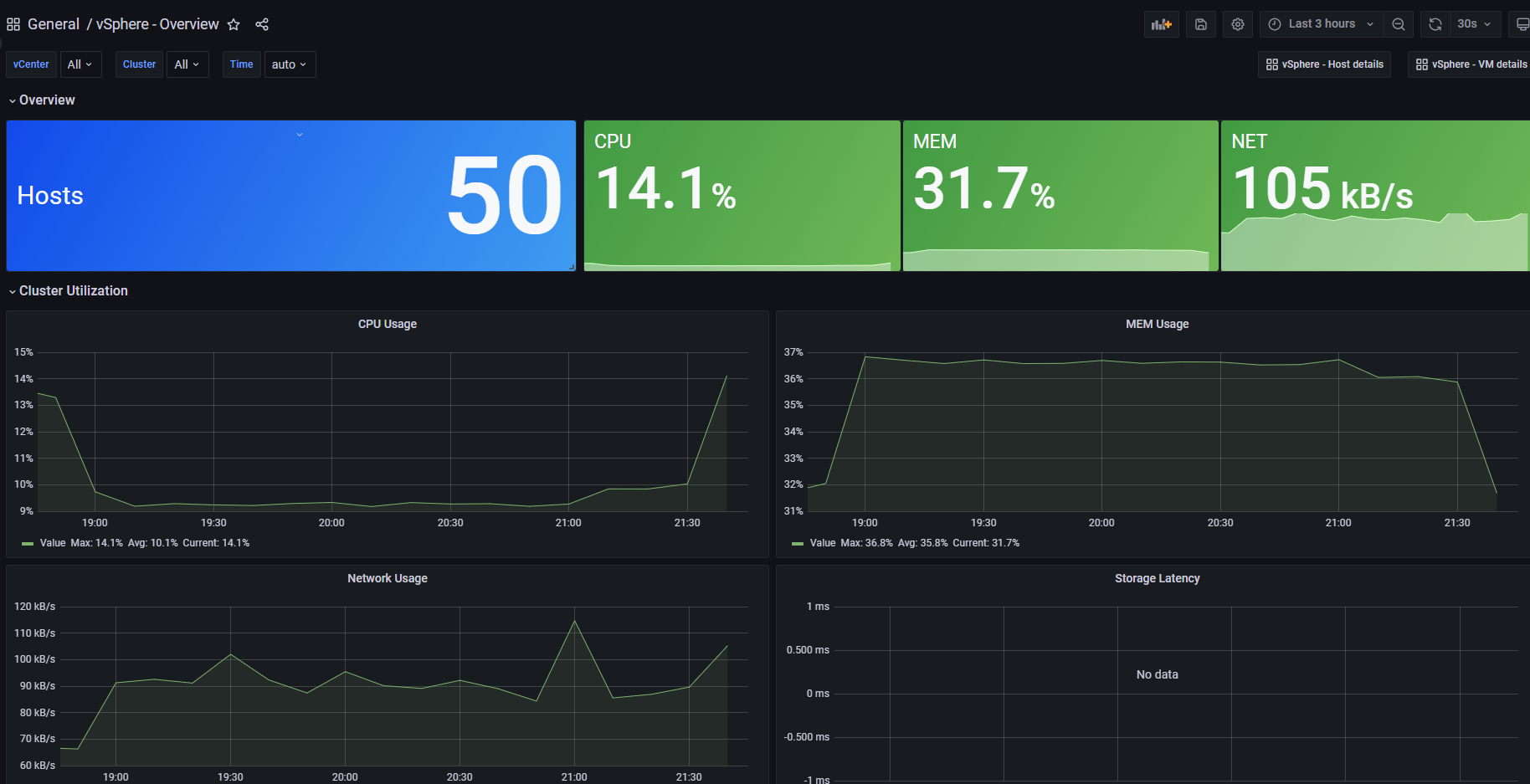
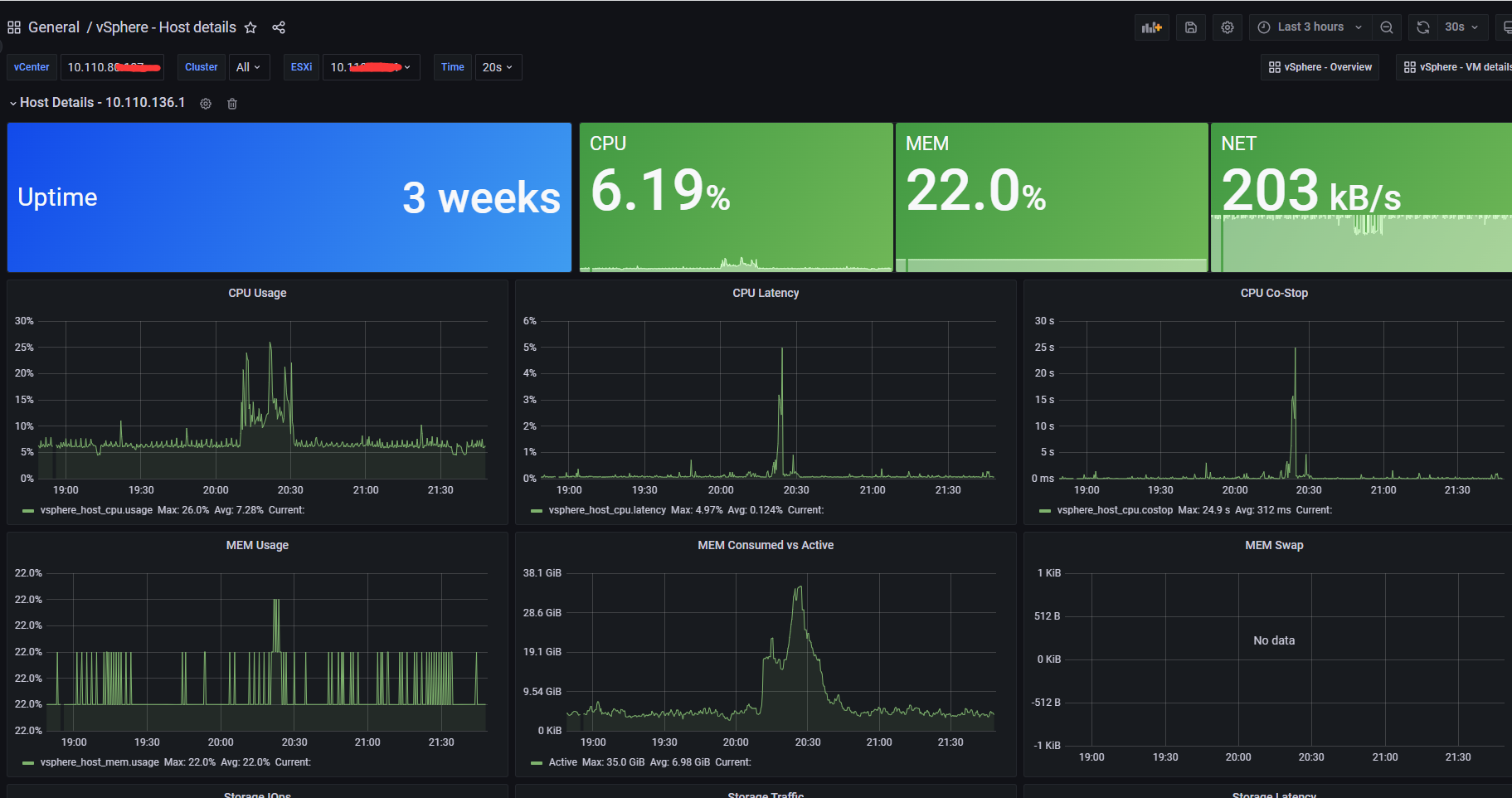
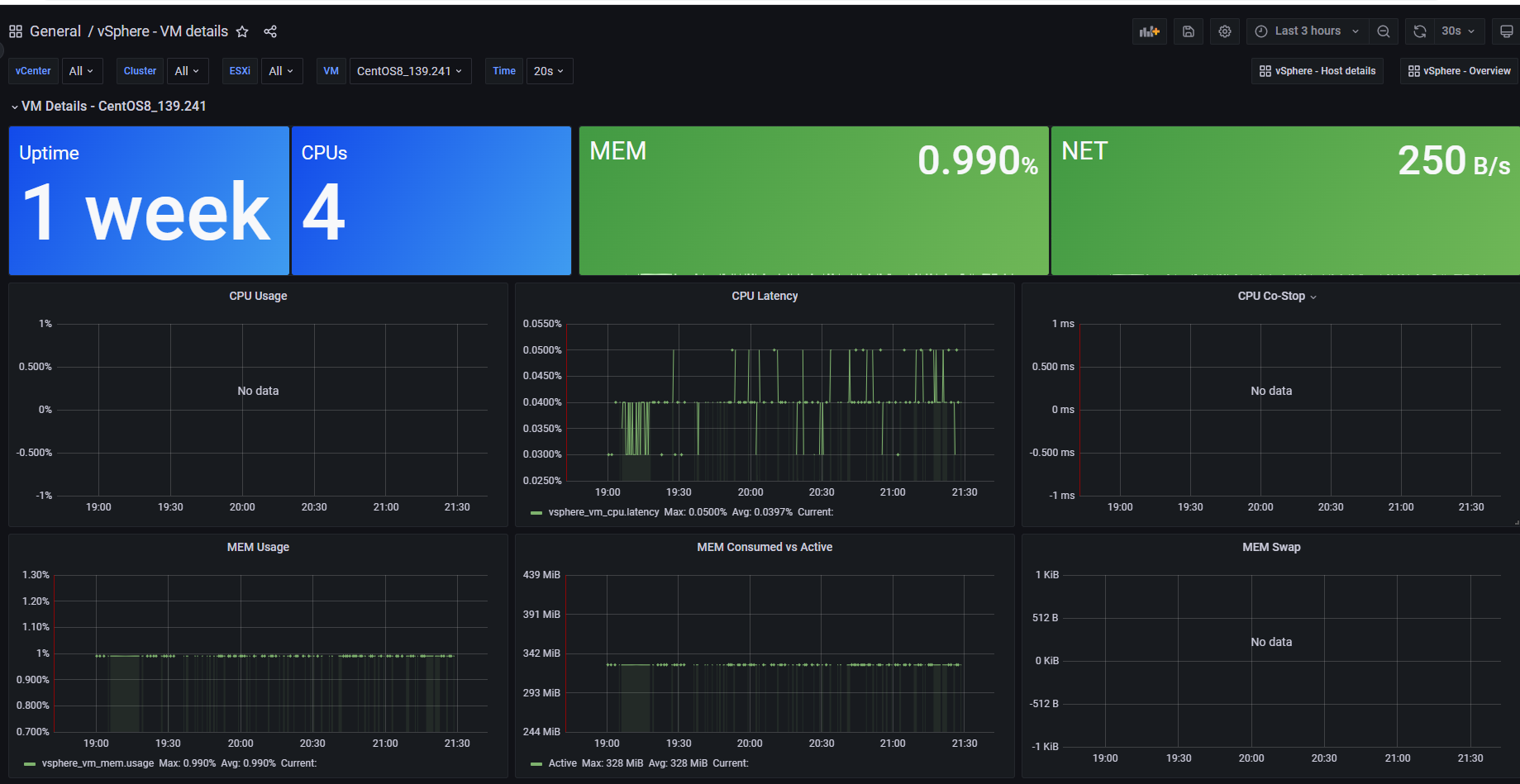
Grafana监控vCenter的简要效果
- 概览信息
- 宿主机的信息
- 虚拟机的信息
Grafana监控java应用以及vCenter的方法的更多相关文章
- 在Docker中监控Java应用程序的5个方法
译者注:Docker是一个开源的应用容器引擎,让开发者可以打包他们的应用以及依赖包到一个可移植的容器中,然后发布到任何流行的Linux机器上,也可以实现虚拟化.通常情况下,监控的主要目的在于:减少宕机 ...
- 快速接入业务监控体系,grafana监控的艺术
做一个系统,如果不做监控,是不完善的. 如果为做一个快速系统,花力气去做监控,是不值得的. 因为,我们有必要具备一个能够快速建立监控体系的能力.即使你只是一个普通开发人员! 个人觉得,做监控有三个核心 ...
- [转帖]使用Grafana和Telegraf监视VMware ESXi的方法
使用Grafana和Telegraf监视VMware ESXi的方法 2019-04-03 15:28:30作者:曾秀珠稿源:云网牛站 https://ywnz.com/linuxyffq/4660. ...
- Prometheus+Grafana监控SpringBoot
Prometheus+Grafana监控SpringBoot 一.Prometheus监控SpringBoot 1.1 pom.xml添加依赖 1.2 修改application.yml配置文件 1. ...
- Spark-StructuredStreaming 下的checkpointLocation分析以及对接 Grafana 监控和提交Kafka Lag 监控
一.Spark-StructuredStreaming checkpointLocation 介绍 Structured Streaming 在 Spark 2.0 版本于 2016 年引入, 是基于 ...
- Spring Boot 使用 Micrometer 集成 Prometheus 监控 Java 应用性能
转载自:https://cloud.tencent.com/developer/article/1508319 文章目录1.Micrometer 介绍2.环境.软件准备3.Spring Boot 工程 ...
- 利用JConsole工具监控java程序内存和JVM
一.找到java应用程序对应的进程PI 性能测试应用程序访问地址:http://192.168.29.218:7070/training/ 部署的应用服务器为tomcat6.028 启动tomcat服 ...
- 编写高质量代码:改善Java程序的151个建议(第一章:JAVA开发中通用的方法和准则)
编写高质量代码:改善Java程序的151个建议(第一章:JAVA开发中通用的方法和准则) 目录 建议1: 不要在常量和变量中出现易混淆的字母 建议2: 莫让常量蜕变成变量 建议3: 三元操作符的类型务 ...
- (转)利用JConsole工具监控java程序内存和JVM
转自:http://www.cnblogs.com/luihengk/p/5446279.html 一.找到java应用程序对应的进程PI 性能测试应用程序访问地址:http://192.168.29 ...
- 利用VisualVm和JMX远程监控Java进程
自Java 6开始,Java程序启动时都会在JVM内部启动一个JMX agent,JMX agent会启动一个MBean server组件,把MBeans(Java平台标准的MBean + 你自己创建 ...
随机推荐
- 理论+实例,带你掌握Linux的页目录和页表
摘要:操作系统在加载用户程序的时候,不仅仅需要分配物理内存,来存放程序的内容:而且还需要分配物理内存,用来保存程序的页目录和页表. 本文分享自华为云社区<Linux从头学15:[页目录和页表]- ...
- 看FusionInsight Spark如何支持JDBCServer的多实例特性
摘要:采用多主实例模式的HA方案,不仅可以规避主备切换服务中断的问题,实现服务不中断或少中断,还可以通过横向扩展集群来提高并发能力. 本文分享自华为云社区<FusionInsight Spark ...
- DataLeap的全链路智能监控报警实践(一):常见问题
随着字节跳动业务的快速发展,大数据开发场景下需要运维管理的任务越来越多,然而普通的监控系统只支持配置相应任务的监控规则,已经不能完全满足当前需求,在日常运维中开发者经常会面临以下几个问题: 任务多,依 ...
- SQL Server 项目中 SQL 脚本更新、升级方式,防止多次重复执行
MySQL 项目中 SQL 脚本更新.升级方式,防止多次重复执行 Oracle 项目中 SQL 脚本更新方式 一套代码,多家部署时,在SQL脚本升级时,通过一个SQL文件给运维,避免出现SQL执行序顺 ...
- Appium介绍及第一个例子
Appium介绍 appium是开源的移动端自动化测试框架 appium可以测试原生的,混合的,以及移动端的项目 appium可以测试ios,android应用 appium是跨平台的,可以用在osx ...
- Spring Cloud 和 Dubbo 哪个会被淘汰?
今天在知乎上看到了这样一个问题:Spring Cloud 和 Dubbo哪个会被淘汰?看了几个回答,都觉得不在点子上,所以要么就干脆写篇小文瞎逼叨一下. 简单说说个人观点 我认为这两个框架大概率会长期 ...
- vi / vim 键盘图(清晰打印版,桌面背景好图)
PDF File https://files.cnblogs.com/files/RioTian/vivim-graphical.zip?t=1704439837&download=true ...
- 如何使用阿里云 CDN 对部署在函数计算上的静态网站进行缓存
前言 为了进一步提升网站的访问速度,我们会使用 CDN 对网站进行加速,但是最近在调试阿里云的函数计算和 CDN 的配合使用时发现了一个需要额外注意的地方,下面带大家一起看一下. 如何使用 CDN 对 ...
- kafka集群六、java操作kafka(没有密码验证)
系列导航 一.kafka搭建-单机版 二.kafka搭建-集群搭建 三.kafka集群增加密码验证 四.kafka集群权限增加ACL 五.kafka集群__consumer_offsets副本数修改 ...
- freeswitch设置最大呼叫时长
概述 freeswitch 作为开源VOIP软交换,对经过fs的每一通电话都要有足够的控制. 在一通电话呼叫中,通话时长是一个重要的数据,客户在实际使用过程中,会有各种针对呼叫时长的场景需求. 本篇文 ...