ViT:拉开Trasnformer在图像领域正式挑战CNN的序幕 | ICLR 2021
论文直接将纯Trasnformer应用于图像识别,是Trasnformer在图像领域正式挑战CNN的开山之作。这种简单的可扩展结构在与大型数据集的预训练相结合时,效果出奇的好。在许多图像分类数据集上都符合或超过了SOTA,同时预训练的成本也相对较低
来源:晓飞的算法工程笔记 公众号
论文: An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale

Introduction
基于自注意力的架构,尤其是Transformers,已成为NLP任务的首选模型。通常的用法是先在大型文本语料库上进行预训练,然后在较小的特定任务数据集上fine-tuning。得益于Transformers的计算效率和可扩展性,训练超过100B参数的模型成为了可能。而且随着模型和数据集的继续增长,模型仍然没有性能饱和的迹象。
在计算机视觉中,卷积网络仍然占主导地位。受NLP的启发,多项工作尝试将CNN的结构与self-attention进行结合(比如DETR:Facebook提出基于Transformer的目标检测新范式 | ECCV 2020 Oral),其中一些则尝试完全替换卷积(比如实战级Stand-Alone Self-Attention in CV,快加入到你的trick包吧 | NeurIPS 2019)。 完全替换卷积的模型虽然理论上有效,但由于使用了特殊的注意力结构,尚未能在现代硬件加速器上有效地使用。因此,在大规模图像识别中,经典的ResNet类型仍然是最主流的。
为此,论文打算不绕弯子,直接将标准Transformer应用于图像。先将图像拆分为图像块,块等同于NLP中的token,然后将图像块映射为embedding序列作为Transformer的输入,最后以有监督的方式训练模型进行图像分类。
但论文通过实验发现,不加强正则化策略在ImageNet等中型数据集上进行训练时,这些模型的准确率比同等大小的ResNet低几个百分点。这个结果是意料之中的,因为Transformers缺乏CNN固有的归纳偏置能力,例如平移不变性和局部性。在数据量不足的情况下,训练难以很好地泛化。但如果模型在更大的数据集(14M-300M图像)上训练时,情况则发生了反转,大规模训练要好于归纳偏置。为此,论文将在规模足够的数据集上预训练的Vision Transformer(ViT)迁移到数据较少的任务,得到很不错的结果。
在公开的ImageNet-21k数据集或内部的JFT-300M数据集上进行预训练后,ViT在多个图像识别任务上接近或超过了SOTA。其中,最好的模型在ImageNet上达到88.55%,在ImageNet-ReaL上达到90.72%,在CIFAR-100上达到94.55%,在包含19个视觉任务的VTAB标准上达到77.63%。
Method
在模型设计中,论文尽可能地遵循原生的Transformer结构。这样做的好处在于原生的Transformer结构已经被高效地实现,可以开箱即用的。
Vision Transformer(ViT)
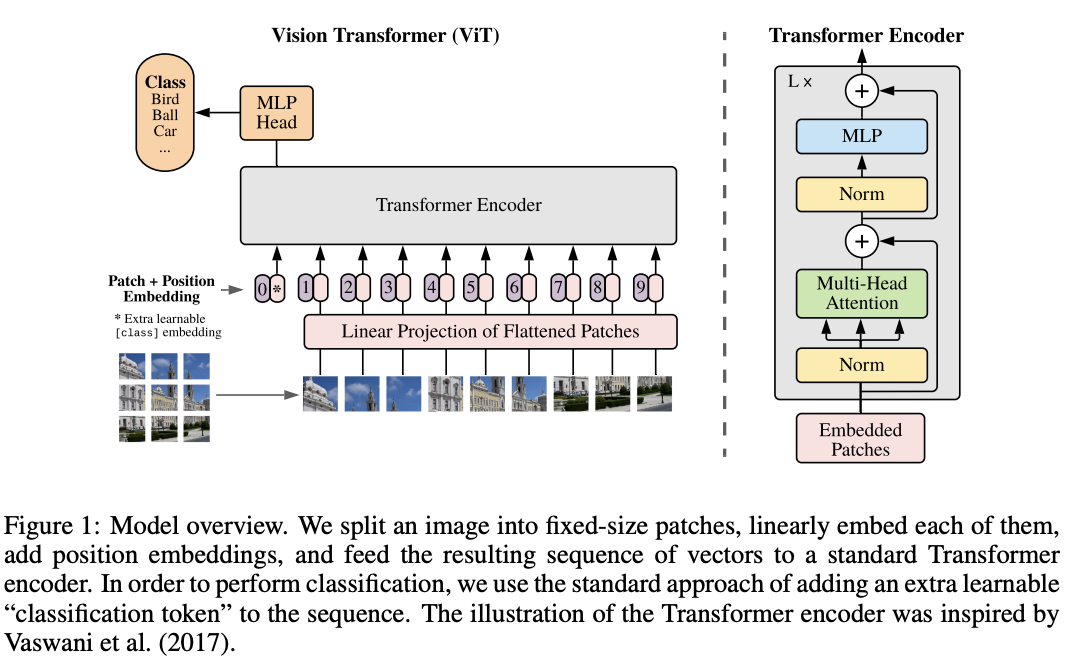
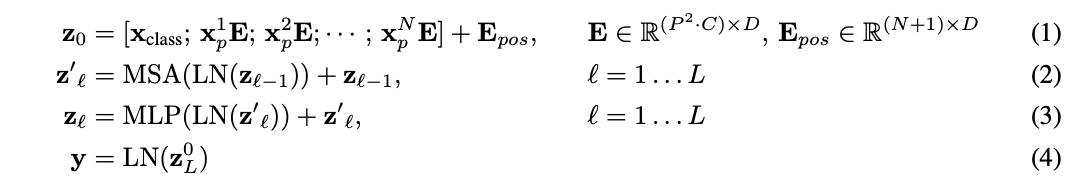
模型的整体结构如图1所示,计算流程如公式1-4所示,主要有以下几个要点:
- 输入处理:标准Transformer接收一维embedding序列作为输入,为了处理二维图像,先将图像\(x\in R^{H\times W\times C}\)重排为二维块序列\(x_p\in R^{N\times (P^2\times C)}\),其中\((H, W)\)为原图像的分辨率,\(C\)是通道数,\((P, P)\)是每个图像块的分辨率,\(N=HW/P^2\)是生成的块数量,也是Transformer的有效输入序列长度。Transformer所有层使用向量的维度均为\(D\),需要先使用可训练的公式1将二维图像块线性映射到\(D\)维,映射的输出称为图像块embedding。
- class token:类似于BERT在输入序列开头插入[class]token,论文同样在图像块embedding序列中预先添加一个可学习的class token(\(z^0_0=x_{class}\)),并将其在Transformer encoder中的对应输出(\(z^0_L\))经公式4转换为图像特征\(y\)。在预训练和fine-tuning期间,分类head都接到\(z^0_L\)上。分类head在预训练时由仅有单隐藏层的MLP实现,而在fine-tuning时由单线性层实现。
- position embedding:添加position embedding到图像块embedding中可以增加位置信息,用合并的embedding序列用作encoder的输入。论文使用标准的可学习1D position embedding,使用更复杂的2D-aware position embedding并没有带来的显着性能提升。
- Transformer encoder:Transformer encoder是主要的特征提取模块,由multiheaded self-attention模块和MLP模块组成,每个模块前面都添加Layernorm(LN)层以及应用残差连接。MLP包含两个具有GELU非线性激活的全连接层,这是point-wise的,不是对整个token输出。self-attention的介绍可以看看附录A或公众号的实战级Stand-Alone Self-Attention in CV,快加入到你的trick包吧 | NeurIPS 2019)文章。
Inductive bias
论文注意到,在Vision Transformer中,图像特定的归纳偏置比CNN要少得多。在CNN中,局部特性、二维邻域结构信息(位置信息)和平移不变性贯彻了模型的每一层。而在ViT中,自注意力层是全局的,只有MLP层是局部和平移不变的。
ViT使用的二维邻域结构信息非常少,只有在模型开头将图像切割成图像块序列时以及在fine-tuning时根据图像的分辨率调整对应的position embedding有涉及。此外,初始的position embedding仅有图像块的一维顺序信息,不包含二维空间信息,所有图像块间的空间关系必须从头开始学习。
Hybrid Architecture
作为图像块的替代方案,输入序列可以由CNN的特征图映射产生,构成混合模型中。将公式1中映射得到图像块embedding \(E\)替换为从CNN提取的特征图中映射得到的特征块embedding,然后跟前面一样添加插入[class] token和position embedding进行后续计算。
有一种特殊情况,特征块为\(1\times 1\)的空间大小。这意味着输入embedding序列通过简单地将特征图按空间维度展开,然后映射到Transformer维度得到。
Fine-Tuning and Higher Resolution
通常,ViT需要先在大型数据集上预训练,然后在(较小的)下游任务fine-tuning。为此,在fine-tuning时需要将预训练的预测头替换为零初始化的\(D\times K\)前向层,\(K\)为下游任务的类数量。
根据已有的研究,fine-tuning时使用比预训练高的分辨率通常可以有更好的效果。但使用更高分辨率的图像时,如果保持图像块大小相同,产生的embedding序列会更长。虽然Vision Transformer可以处理任意长度的序列,但预训练得到的position embedding将会失去意义。因此,论文提出根据原始图像中的位置对预训练的position embedding进行2D插值,然后进行fine-tuning训练。
值得注意的是,这种分辨率相关的调整以及模型开头的图像块的提取是Vision Transformer中少有的手动引入图像二维结构相关的归纳偏置的点。
Experiment
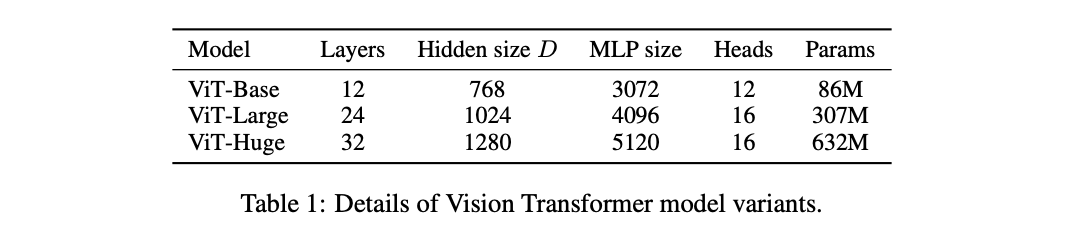
论文设计了三种不同大小的ViT,结构参数如上。

分类性能对比,不同模型、不同预训练数据集在不同分类训练集上的表现。
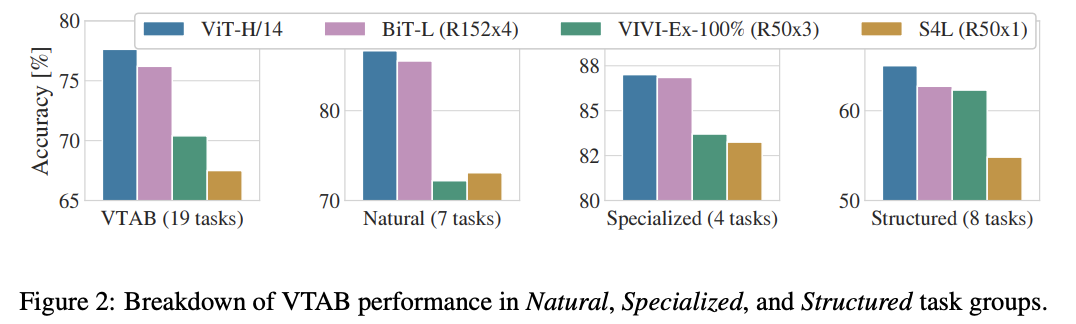
将VTAB任务拆分与SOTA模型进行对比,其中VIVI是在ImageNet和Youtube数据集上训练的ResNet类模型。
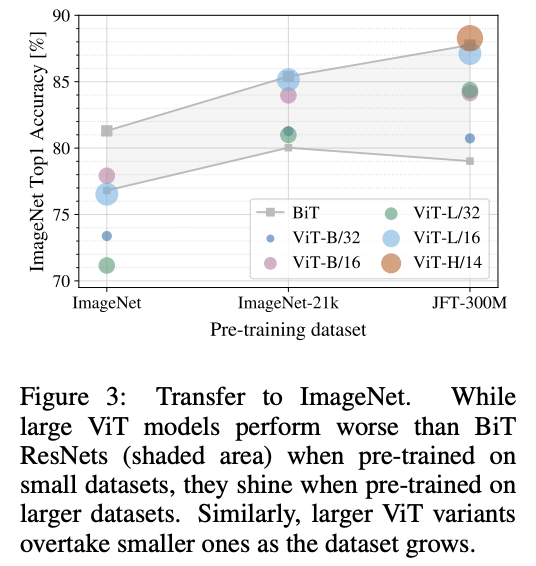
预训练数据集与迁移数据集上的性能关系对比,预训练数据集小更适合使用ResNet类模型。
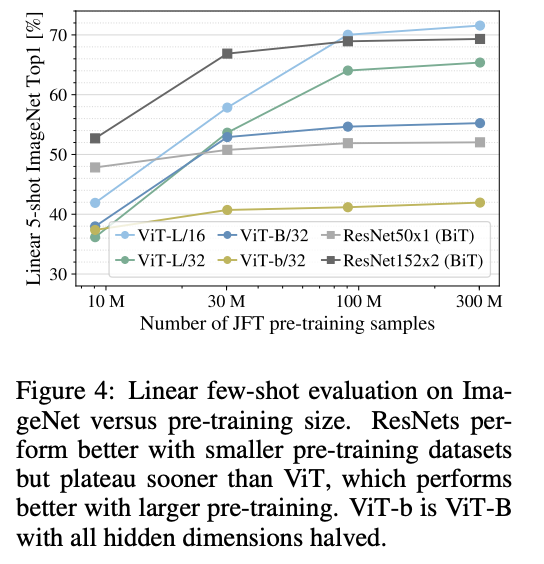
预训练数据集与few-shot性能对比,直接取输出特征进行逻辑回归。
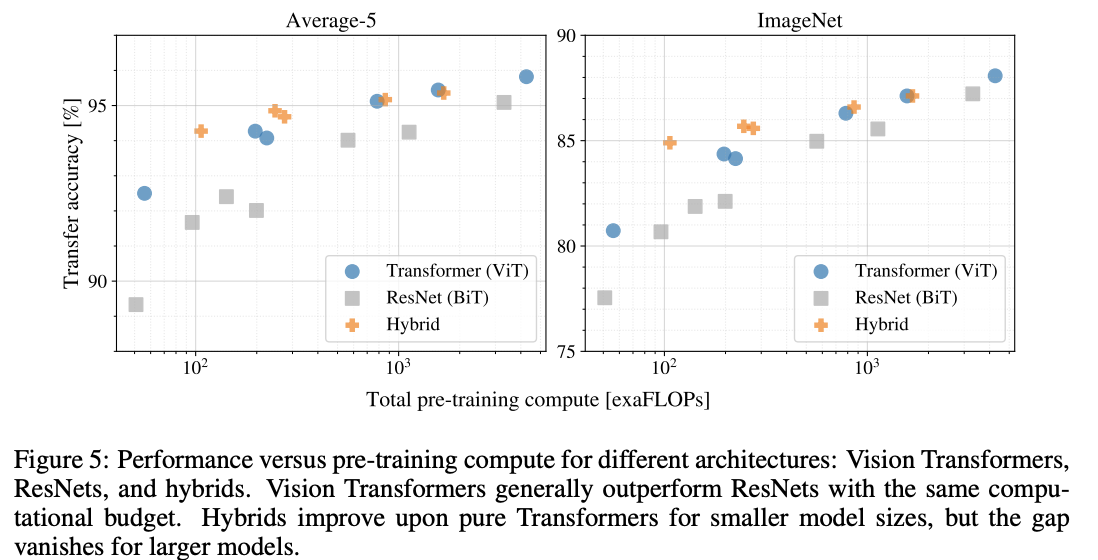
预训练消耗与迁移后性能的对比。
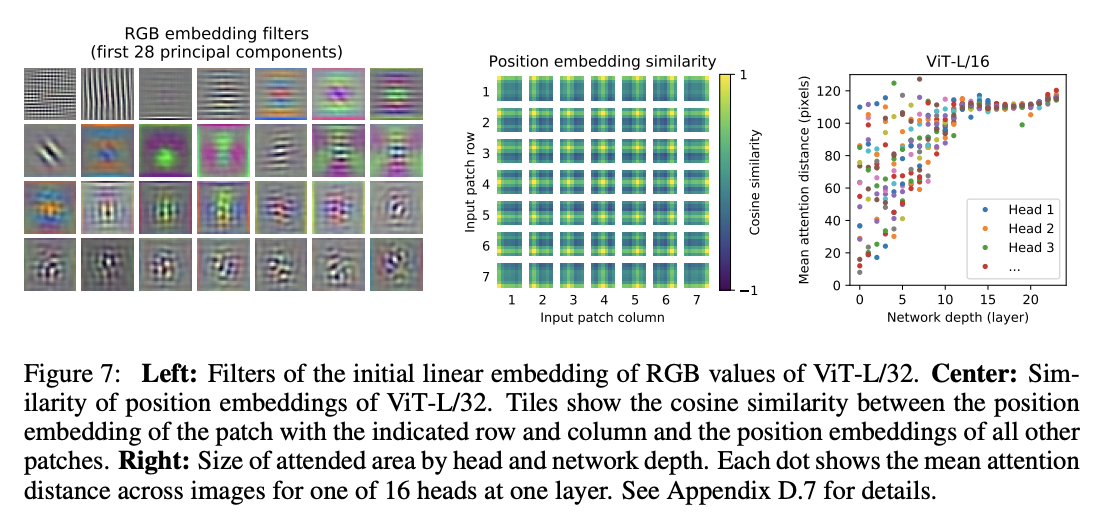
可视化ViT:
- 公式1的前28个线性映射参数的权值主成分分析,主成分差异代表提取的特征较丰富。
- position embedding之间的相关性,约近的一般相关性越高。
- 每层的self-attention中每个head的平均注意力距离(类似于卷积的感受域大小),越靠前的关注的距离更远,往后则越近。
Conclusion
论文直接将纯Trasnformer应用于图像识别,是Trasnformer在图像领域正式挑战CNN的开山之作。这种简单的可扩展结构在与大型数据集的预训练相结合时,效果出奇的好。在许多图像分类数据集上都符合或超过了SOTA,同时预训练的成本也相对较低。
如果本文对你有帮助,麻烦点个赞或在看呗~
更多内容请关注 微信公众号【晓飞的算法工程笔记】

ViT:拉开Trasnformer在图像领域正式挑战CNN的序幕 | ICLR 2021的更多相关文章
- GCN: Graph Convolutional Network
从CNN到GCN的联系与区别: https://www.zhihu.com/question/54504471/answer/332657604 更加详解Laplacian矩阵: https://ww ...
- 【转】贾扬清:希望Caffe成为深度学习领域的Hadoop
[转:http://www.csdn.net/article/2015-07-07/2825150] 在深度学习(Deep Learning)的热潮下,Caffe作为一个高效.实用的深度学习框架受到了 ...
- 利用神经网络进行网络流量识别——特征提取的方法是(1)直接原始报文提取前24字节,24个报文组成596像素图像CNN识别;或者直接去掉header后payload的前1024字节(2)传输报文的大小分布特征;也有加入时序结合LSTM后的CNN综合模型
国外的文献汇总: <Network Traffic Classification via Neural Networks>使用的是全连接网络,传统机器学习特征工程的技术.top10特征如下 ...
- 大尺寸卫星图像目标检测:yoloT
大尺寸卫星图像目标检测:yoloT 1. 前言 YOLT论文全称「You Only Look Twice: Rapid Multi-Scale Object Detection In Satellit ...
- 挑战App Store,微信通过“跳一跳”秀了一下“小程序”的肌肉
2017年即将结束的时候,微信放了一个大招.随着最新的微信v6.6.1版本更新,基于小程序的"小游戏"板块正式上线.微信上首发的这款"小游戏"叫"跳一 ...
- Behance 大神推荐2019 年所有设计领域的最新趋势!
昨天国内设计界发生了一则重大新闻! 相信大家应该都听说了吧 Behance挂了··· 继续Pinteres之后 在一个设计师不用上班的周六 我的电脑默默打不开Behance了 也就是说大陆地区的ip地 ...
- Python下opencv使用笔记(一)(图像简单读取、显示与储存)
写在之前 从去年開始关注python这个软件,途中间间断断看与学过一些关于python的东西.感觉python确实是一个简单优美.easy上手的脚本编程语言,众多的第三方库使得python异常的强大. ...
- 在CV尤其是CNN领域的一些想法
现在的CNN还差很多,未来满是变数. 你看,现在的应用领域也无非merely就这么几类----分类识别,目标检测(定位+识别),对象分割......,但是人的视觉可不仅仅这么几个功能啊!是吧. 先说说 ...
- 14、OpenCV实现图像的空间滤波——图像锐化及边缘检测
1.图像锐化理论基础 1.锐化的概念 图像锐化的目的是使模糊的图像变得清晰起来,主要用于增强图像的灰度跳变部分,这一点与图像平滑对灰度跳变的抑制正好相反.而且从算子可以看出来,平滑是基于对图像领域的加 ...
- 使用LabVIEW实现基于pytorch的DeepLabv3图像语义分割
前言 今天我们一起来看一下如何使用LabVIEW实现语义分割. 一.什么是语义分割 图像语义分割(semantic segmentation),从字面意思上理解就是让计算机根据图像的语义来进行分割,例 ...
随机推荐
- linux网络编程基础知识汇总(更新中)
阿帕网 arpanet 阿帕网为美国国防部高级研究计划署开发的世界上第一个运营的封包交换网络,它是全球互联网的始祖. 局域网 LAN(Local Area Network ):通过路由器和交换机把计算 ...
- 以Servlet来解释 抽象实现类
在 Java Servlet API 中: Servlet 接口定义了一个 Servlet 的基本行为.这个接口是抽象的,因为它包含抽象方法,比如 service(), init(), 和 destr ...
- Centos8 ssh配置三台虚拟机免密登录 root 及 非root 稍有差异;SSH的免密登录详细步骤
为了保证一台Linux主机的安全,所以我们每个主机登录的时候一般我们都设置账号密码登录.但是很多时候为了操作方便,我们都通过设置SSH免密码登录. 一.配置SSH 基本语法:假设要用用户名root登录 ...
- Advanced .Net Debugging 3:基本调试任务(对象检查:内存、值类型、引用类型、数组和异常的转储)
一.介绍 这是我的<Advanced .Net Debugging>这个系列的第四篇文章.今天这篇文章的标题虽然叫做"基本调试任务",但是这章的内容还是挺多的.由于内容 ...
- Django 初步使用
Django 框架系列 目录 Django 框架系列 一. 安装启用 1.1 主流web框架概述 1.2 安装版本 1.3 启动的两种方式 1)命令行创建 2)pycharm创建 3)两种方式的区别 ...
- Ubuntu 与Windows 之间搭建共享文件夹
工作中经常需要搭建Linux环境用于测试以及其他开发需求,办公电脑通常是Windows 系统,为便于让文件在两个系统之间传输,可以采取共享文件的方式实现: 1.安装samba 服务: sudo apt ...
- aardio 嵌入 其他应用程序
aardio 嵌入 其他应用程序 需求 这个chrome壳不能进行拖拽和缩放,所以再套一个壳,可以再分屏的时候用 import win.ui; /*DSG{{*/ winform = win.form ...
- git 删除本地创建的仓库常用方法
基本方法 清除本地文件夹下的git文件,然后在重新初始化新建的git仓库 具体实施 //删除文件夹下的所有 .git 文件 find . -name ".git" | xarg ...
- PLC与上位机传递数据
1.我这里使用的是HslCommunication 假如传递的是word类型,PLC以16进制封装数组,它有预留,我扩充 PLC博图上是 word[5] 上位机接收 ushort[] Data1=ne ...
- HTML/ CSS 入门
前言 我们在之前的学习中,对于网络有了一定的了解.现在我们来学习一些基础的 HTML/ CSS 知识.希望阅读完这篇文章能达到编写简单页面的程度. 目录: HTML/ CSS 的发明: HTML 基础 ...