深入理解Linux进程调度(下)
一、SMP管理
在继续讲解之前,我们先来说一下多CPU管理(这里的CPU是指逻辑CPU,在很多语境中CPU都是默认指的逻辑CPU,物理CPU要特别强调是物理CPU)。最开始的时候计算机都是单CPU的,叫做UP(Uni-Processor),操作系统也只支持UP。后来计算机慢慢发展成了多CPU(包括多物理CPU和多核技术),于是操作系统也要开始支持多CPU。支持多CPU的方式有两种:一种是AMP(Aymmetrical Multi-Processing)非对称多处理器,是指操作系统给每个CPU分配的工作任务不同,比如有的CPU专门运行中断,有的CPU专门运行普通进程,有的CPU专门运行实时进程;另一种是SMP(Symmetrical Multi-Processing),操作系统对待每个CPU的方式都是一样的,并不会把某个CPU拿来专门做啥任务,每个CPU都有可能处理任何类型的任务。由于AMP的性能和适应性都不太好,所以现在流行的操作系统基本都是SMP的。对于SMP这个词来说,在很长的一段时间内,它既是指CPU在逻辑上是对称的(操作系统对待所有CPU的方式是一样的),也指CPU在物理上是对称的(CPU在性能等所有方面都是一样的),因为当时的多CPU技术实现上每个逻辑CPU的性能等各方面都是相同的。但是后来多CPU技术的实现出现了HMP(Heterogeneous Multi-Processing)异构多处理器,也就是大小核技术,不同的逻辑CPU它们的性能并不相同。现在内核同时支持SMP和HMP,因为两者并不矛盾,SMP指的是所有的CPU在逻辑上都是一样的,每个CPU都有可能执行任何类型的任务,HMP指的是不同的CPU它的能力大小不同,能力大的多干活,能力小的少干活。内核选项CONFIG_SMP控制是否开启SMP,如果不开启的话就是UP,系统就只能在一个CPU上运行。内核选项CONFIG_ENERGY_MODEL控制是否开启HMP,开启了之后就可以为不同的设备建立不同的能耗模型,系统在分配任务就会以此为参考决定如何分配任务,达到效率更高或者更省电的目的。
1 CPU拓扑结构
我们先从发展的角度来看一看CPU的拓扑结构。最早的时候一个物理CPU就是一个逻辑CPU,一个逻辑CPU包含一个控制器、一个运算器和一些寄存器,一个物理CPU包含一个裸芯片(Die)和外面的封装(Package)。然后出现了多物理CPU,也就是一个主板上有多个CPU插槽,这样计算机中就有多个CPU了。后来发现,没必要做多个物理CPU啊,一个物理CPU(Package)包含多个裸芯片(Die)不也是多CPU嘛,省事又方便。后来又发现,多个裸芯片封装在一起也很麻烦啊,直接在一个裸芯片上做多个逻辑CPU不是也可以嘛,更省事。从这之后x86和ARM的CPU做法就不一样了。在x86上是一个裸芯片(Die)包含多个核(Core),一个核(Core)上包含多个SMT(Simultaneous Multithreading),SMT在Intel的文档里叫做HT(Hyper-Threading),SMT是最终的逻辑CPU。在ARM上是一个裸芯片(Die)包含多个核簇(Cluster),一个核簇(Cluster)包含多个核(Core)。
2 CPUMASK
不同架构的CPU,其逻辑CPU都有一个硬件ID,此ID一般是多个字段的组合。Linux为了方便管理CPU,提出了逻辑CPU的概念,此逻辑CPU的概念是指CPU的ID是逻辑的,从0来编号一直增长的。内核会把第一个启动的CPU作为CPU0,其它CPU的编号依次为CPU1,CPU2,……。内核定义了结构体cpumask来表示各个CPU编号的集合,cpumask是个bitmap,每一个bit可以代表一个CPU的某种状态。内核中定义了五个cpumask变量,用来表示不同状态下的CPU集合。下面我们来看一下:
linux-src/include/linux/cpumask.h
typedef struct cpumask { DECLARE_BITMAP(bits, NR_CPUS); } cpumask_t;
extern struct cpumask __cpu_possible_mask;
extern struct cpumask __cpu_online_mask;
extern struct cpumask __cpu_present_mask;
extern struct cpumask __cpu_active_mask;
extern struct cpumask __cpu_dying_mask;
#define cpu_possible_mask ((const struct cpumask *)&__cpu_possible_mask)
#define cpu_online_mask ((const struct cpumask *)&__cpu_online_mask)
#define cpu_present_mask ((const struct cpumask *)&__cpu_present_mask)
#define cpu_active_mask ((const struct cpumask *)&__cpu_active_mask)
#define cpu_dying_mask ((const struct cpumask *)&__cpu_dying_mask)
linux-src/kernel/cpu.c
struct cpumask __cpu_possible_mask __read_mostly;
EXPORT_SYMBOL(__cpu_possible_mask);
struct cpumask __cpu_online_mask __read_mostly;
EXPORT_SYMBOL(__cpu_online_mask);
struct cpumask __cpu_present_mask __read_mostly;
EXPORT_SYMBOL(__cpu_present_mask);
struct cpumask __cpu_active_mask __read_mostly;
EXPORT_SYMBOL(__cpu_active_mask);
struct cpumask __cpu_dying_mask __read_mostly;
EXPORT_SYMBOL(__cpu_dying_mask);
cpu_possible_mask代表的是操作系统最多能支持的CPU,cpu_present_mask代表的是计算机上存在的CPU,cpu_online_mask代表的是已经上线的CPU,cpu_active_mask代表的是未被隔离可以参与调度的CPU,cpu_dying_mask代表的是处于热下线过程中的CPU。
二、基本分时调度
Linux上的分时调度算法叫CFS(Completely Fair Scheduler)完全公平调度。它是内核核心开发者Ingo Molnar基于SD调度器和RSDL调度器的公平调度思想而开发的一款调度器,在版本2.6.23中合入内核。CFS只负责调度普通进程,包括三个调度策略NORMAL、BATCH、IDLE。
我们这章只讲单个CPU上的调度,多CPU之间的调度均衡在下一章讲。
1 CFS调度模型
内核文档对CFS的定义是:CFS在真实的硬件上基本模拟了完全理想的多任务处理器。完全理想的多任务处理器是指,如果把CPU的执行能力看成是100%,则N个进程可以同时并行执行,每个进程获得了1/N的CPU执行能力。例如有2个进程在2GHz的CPU上执行了20ms,则每个进程都以1GHz的速度执行了20ms。
通过CFS的定义很难理解CFS的操作逻辑是什么。我看了很多CFS的博客,也认真看了很多遍CFS的代码,虽然自己心里明白了其中的意思,但是想要给别人说清楚CFS的操作逻辑还是很难。后来我灵光乍现,突然想到了一个很好的类比场景,把这个场景稍微改造一下,就可以打造一个非常完美的CFS调度模型,可以让任何人都能理解CFS的操作逻辑。大家有没有这种生活体验,夏天的时候三四个好友一起去撸串,吃完准备走的时候发现有一瓶啤酒打开了还没喝。此时我们会把这瓶啤酒平分了,具体怎么分呢,比如三个人分,你不可能一次分完,每个杯子正好倒三分之一。我们一般会每个杯子先倒个差不多,然后再把剩余的啤酒来回往各个杯子里面倒,这样啤酒就会分的比较均匀了。也许你没经历过这样的场景,或者认为啤酒随便分就可以了,没必要分那么细。接下来还有一个场景更生动。你有没有经历过或者见过长辈们喝白酒划拳的,此时一般都会拿出5到10个小酒盅,先把每个酒盅都倒个差不多,然后再来回地往各个酒盅里面倒一点,还会去比较酒盅液面的高低,优先往液面低的杯子里面倒。如果你见过或者经历过这种场景,那么接下来的模型就很好理解了。
我们对倒白酒的这个场景进行改造,把它变成一个实验台。首先把酒盅变成细长(而且非常长)的玻璃杯,再把倒白酒的瓶子变成水龙头,能无限出水的水龙头,有一个桌子可以用来摆放所有的玻璃杯。我们一次只能拿着一个玻璃杯放到水龙头下接水。然后向你提出了第一个要求,在任意时刻所有的玻璃杯的水位高度都要相同或者尽量相同,越接近越好。此时你会怎么办,肯定是不停地切换玻璃杯啊,越快越好,一个玻璃杯接一滴水就立马换下一个。但是这立马会迎来第二个问题,切换玻璃杯的过程水龙头的水会流到地上,过于频繁的切换玻璃杯会浪费大量的水。向你提出的第二个要求就是要尽量地少浪费水,你该怎么办,那肯定是减少玻璃杯的切换啊。但是减少玻璃杯的切换又会使得不同玻璃杯的水位差变大,这真是一个两难的选择。对此我们只能进行折中,切换玻璃杯的频率不能太大也不能太小,太大浪费水,太小容易水位不均。
我们继续对这个模型进行完善。为了减少水位差我们每次都要去拿水位最低的,怎么能最快的时间拿到最低的玻璃杯呢,肯定是把水杯按照从高到底的顺序排列好,我们直接去拿第一个就好了。玻璃杯代表的是进程,不同进程的优先级不同,分到的CPU时间片也不同,为此我们让不同的玻璃杯有不同的粗细,这样比较粗的玻璃杯就能分到更多的水,因为我们在尽量保证它们的水位相同,横截面积大的玻璃杯就会占优势。进程有就绪、阻塞、运行等状态,为此我们在玻璃杯上面加个盖子,盖子有时候是打开的,有时候是关闭的。盖子关闭的时候玻璃杯是没法接水的,因此我们把它放到一边,直到有人把它的盖子打开我们再把它放到桌子上。
说到这里,大家在脑海里对这个模型应该已经有个大概的轮廓了,下面我们画图来看一下:
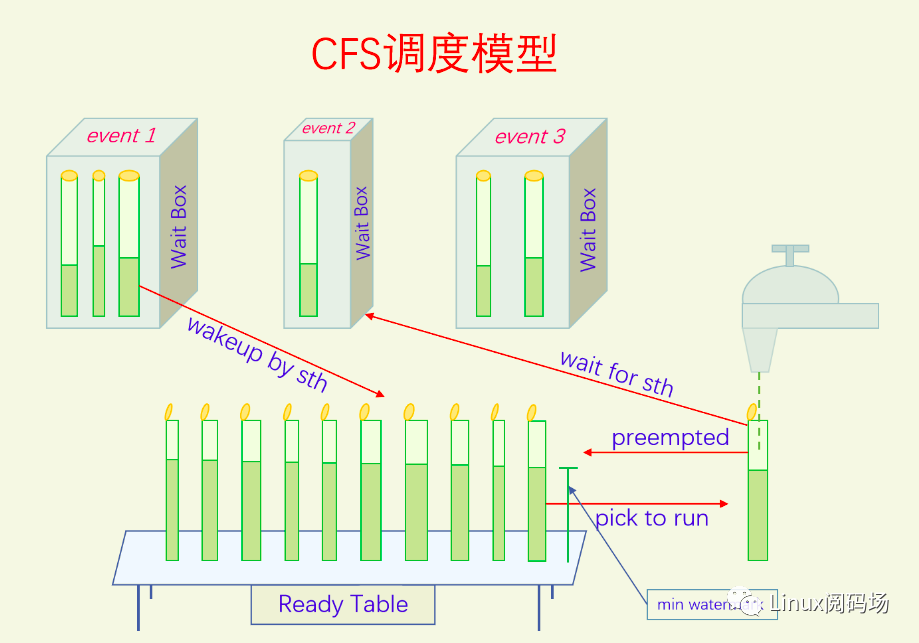
我们继续讲解这个图。我们每次都是从队首拿过来一个玻璃杯开始接水。在接水的过程中有两种情况可能会发生:一是一直接水直到此次接水的份额已经满了,我们把这个玻璃杯再放回到队列中去,由于此时玻璃杯刚接了不少水,水位比较高,所以会排的比较靠后;二是接水的过程中,瓶盖突然关闭了,这时就没法再接水了,我们把玻璃杯送到某个Wait Box中去,等待某个事件的发生。
某个事件发生之后会把对应的Wait Box中的一个或者多个玻璃杯的瓶盖打开,然后此玻璃杯就会被送到Ready Table上。玻璃杯被送到Ready Table并不是随便一放就行了,也是要参与排序的。大家从图中可以看到,Wait Box中的玻璃杯的水位都比较低,这是因为Ready Table上的玻璃杯一直在接水,水位肯定会涨的很高,相应的Wait Box中的水位就低了。因此WaitBox中的玻璃杯被唤醒放到ReadyTable上基本都能排第一,这也是好事,让休眠时间长的进程能迅速得到执行。但是这里面也存在一个问题,就是刚开盖的玻璃杯水位太低了,它就能一直得到执行,这对其它玻璃杯来说是不公平的。因此ReadyTable上放了一个最低水位记录,刚开盖的玻璃瓶如果水位比这个值低,我们就往这个玻璃瓶中填充泡沫,使得它的水位看起来和这个最低水位记录一样高。这样新开盖的玻璃杯既能优先接水,又不能过分占便宜,非常好。最低水位记录的值也会一直更新的,正在接水的玻璃杯每次离开的时候都会更新一下这个最低水位记录。
现在我们对这个玻璃杯接水模型的逻辑已经非常清楚了,下面我们一步一步把它和CFS的代码对应起来,你会发现契合度非常高。
2.CFS运行队列
所有的就绪进程都要在ReadyTable上按照水位高低排成一排,那么这个队列用什么数据结构来实现呢?先想一下这个队列都有什么需求,首先这个队列是排序的,其次我们经常对这个队列进程插入和删除操作。因此我们可以想到用红黑树来实现,因为红黑树首先是一颗二叉搜索树,是排序的,其次红黑树是平衡的,其插入和删除操作的效率都是O(logn),非常高效。所以CFS的运行队列就是用红黑树来实现的。
下面我们来看一下CFS运行队列的代码:
linux-src/kernel/sched/sched.h
struct cfs_rq {
struct load_weight load;
unsigned int nr_running;
unsigned int h_nr_running; /* SCHED_{NORMAL,BATCH,IDLE} */
unsigned int idle_h_nr_running; /* SCHED_IDLE */
u64 exec_clock;
u64 min_vruntime;
struct rb_root_cached tasks_timeline;
struct sched_entity *curr;
struct sched_entity *next;
struct sched_entity *last;
struct sched_entity *skip;
#ifdef CONFIG_SMP
struct sched_avg avg;
struct {
raw_spinlock_t lock ____cacheline_aligned;
int nr;
unsigned long load_avg;
unsigned long util_avg;
unsigned long runnable_avg;
} removed;
#endif /* CONFIG_SMP */
};
字段tasks_timeline就是所有分时进程所排队的队列,类型rb_root_cached就是内核中红黑树的实现,curr就是当前正在CPU上运行的进程。还有一些其它字段我们在讲到时再进行解说。进程在红黑树中排队的键值是虚拟运行时间vruntime,这个在4.5节中讲解。
3 进程状态表示
我们知道进程在运行的时候一直是在阻塞、就绪、执行三个状态来回转换,如下图所示:

但是Linux中对进程运行状态的定义却和标准的操作系统理论不同。
Linux中的定义如下(删减了一些状态):
linux-src/include/linux/sched.h
/* Used in tsk->state: */
#define TASK_RUNNING 0x0000
#define TASK_INTERRUPTIBLE 0x0001
#define TASK_UNINTERRUPTIBLE 0x0002
#define TASK_DEAD 0x0080
#define TASK_NEW 0x0800
在Linux中就绪和执行都用TASK_RUNNING来表示,这让人很疑惑。但是用我们的模型图来看,这一点却很好理解,因为就绪和执行它们都是开盖的,状态一样,区别它们的方法是玻璃杯有没有放在水龙头下接水,而Linux中也是利用这一点来判断的。如下代码所示:
linux-src/kernel/sched/sched.h
static inline int task_current(struct rq *rq, struct task_struct *p)
{
return rq->curr == p;
}
static inline int task_running(struct rq *rq, struct task_struct *p)
{
#ifdef CONFIG_SMP
return p->on_cpu;
#else
return task_current(rq, p);
#endif
}
linux-src/include/linux/sched.h
#define task_is_running(task) (READ_ONCE((task)->__state) == TASK_RUNNING)
注意task_is_running和task_running两者之间的不同,前者判断的是状态字段,代表进程处于就绪或者执行态,后者判断的是进程是否处于执行态。
表示进程处于阻塞态的状态有两个:TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE。TASK_UNINTERRUPTIBLE表示只有WaitBox对应的事件能把玻璃杯的盖子打开,其它人谁也打不开。TASK_INTERRUPTIBLE表示除了WaitBox对应的事件之外,信号(signal)也能把盖子打开。关于信号请参看《深入理解Linux信号机制》。
4 优先级与权重
我们在前面讲过进程的优先级,这里只讲分时进程的优先级。优先级是如何影响进程获得CPU时间的多少呢?优先级会转化为进程的权重,进程的权重也就是玻璃杯的粗细。横截面积大的玻璃杯,接收同样容积的水,它的水位增加就比较小,就容易排到队列的前面去,就比较容易获得调度。在一段时间后,所有玻璃杯的水位高度都比较接近,同样的水位高度,横截面积大的玻璃杯装的水就多,也就是进程获得的CPU时间比较多。
进程(线程)的相关信息是记录在task_struct中的,内核又把和分时调度相关的一些信息抽出来组成了结构体sched_entity,然后把sched_entity内嵌到task_struct当中,sched_entity中包含有权重信息的记录。下面我们来看一下。
linux-src/include/linux/sched.h
struct task_struct {
struct sched_entity se;
}
struct sched_entity {
/* For load-balancing: */
struct load_weight load;
struct rb_node run_node;
struct list_head group_node;
unsigned int on_rq;
u64 exec_start;
u64 sum_exec_runtime;
u64 vruntime;
u64 prev_sum_exec_runtime;
u64 nr_migrations;
struct sched_statistics statistics;
#ifdef CONFIG_FAIR_GROUP_SCHED
int depth;
struct sched_entity *parent;
/* rq on which this entity is (to be) queued: */
struct cfs_rq *cfs_rq;
/* rq "owned" by this entity/group: */
struct cfs_rq *my_q;
/* cached value of my_q->h_nr_running */
unsigned long runnable_weight;
#endif
#ifdef CONFIG_SMP
/*
* Per entity load average tracking.
*
* Put into separate cache line so it does not
* collide with read-mostly values above.
*/
struct sched_avg avg;
#endif
};
struct load_weight {
unsigned long weight;
u32 inv_weight;
};
可以看到load_weight中有两个字段:weight和inv_weight。weight代表的是权重,inv_weight是为了方便weight参与除法运算时而添加的,它可以把对weight的除法运算转化为对inv_weight的乘法运算。inv_weight = 232/weight,当需要除以weight的时候,你只需要乘以inv_weight然后再右移32就可以了。inv_weight的值可以提前算出来保存在数组里,右移操作是个效率很高的操作,这样就提高了权重相关的运算效率。下面我们先来看一下weight的值是怎么来的。
nice值的范围是-20到19,是等差数列,转化之后的权重是等比数列,以nice 0作为权重1024,公比为0.8。之前的调度算法都是把nice值转化为等差数列的时间片或者多段等差数列的时间片,为何CFS要把这个转换变为等比数列呢?这是因为人们天然地对相对值比较敏感而不是对绝对值比较敏感,比如你工资两千的时候涨薪200和工资两万的时候涨薪200,心情绝对是不一样的。如果系统中只有两个进程,nice值分别为0和1,时间片分别为200ms和195ms,几乎没啥区别,但是当nice值分为18和19的时候,时间片分别为10ms和5ms,两者的时间差达到了一倍,同样是nice值相差1,它们的时间差的比例却如此之大,是让人无法接受的。因此把nice值转化为等比数列的权重,再按照权重去分配CPU时间是比较合理的。那么公比为何是0.8呢?这是为了让两个nice值只相差1的进程获得的CPU时间比例差为10%。我们用等式来计算一下,假设x、y是权重,y对应的nice值比x大1,我们希望 x/(x+y) - y/(x+y) = 10%,我们做一下运算,看看y与x的比值是多少。
x/(x+y) - y/(x+y) = 10%
(x-y)/(x+y) = 0.1
x-y = 0.1x + 0.1y
0.9x = 1.1y
y/x = 0.9/1.1
y/x = 0.818181
y/x ≈ 0.8
那么为什么把nice 0 作为权重1024来进行转换呢?这是为了二进制运算方便。内核里并不是每次优先级转权重都进行运算,而是提前运算好了放在数组,每次用的时候查一下就可以了。反权重的值也提前计算好了放在了数组里。下面我们来看一下:
linux-src/kernel/sched/core.c
const int sched_prio_to_weight[40] = {
/* -20 */ 88761, 71755, 56483, 46273, 36291,
/* -15 */ 29154, 23254, 18705, 14949, 11916,
/* -10 */ 9548, 7620, 6100, 4904, 3906,
/* -5 */ 3121, 2501, 1991, 1586, 1277,
/* 0 */ 1024, 820, 655, 526, 423,
/* 5 */ 335, 272, 215, 172, 137,
/* 10 */ 110, 87, 70, 56, 45,
/* 15 */ 36, 29, 23, 18, 15,
};
const u32 sched_prio_to_wmult[40] = {
/* -20 */ 48388, 59856, 76040, 92818, 118348,
/* -15 */ 147320, 184698, 229616, 287308, 360437,
/* -10 */ 449829, 563644, 704093, 875809, 1099582,
/* -5 */ 1376151, 1717300, 2157191, 2708050, 3363326,
/* 0 */ 4194304, 5237765, 6557202, 8165337, 10153587,
/* 5 */ 12820798, 15790321, 19976592, 24970740, 31350126,
/* 10 */ 39045157, 49367440, 61356676, 76695844, 95443717,
/* 15 */ 119304647, 148102320, 186737708, 238609294, 286331153,
};
Nice值从-20到19一共40个数,一排5个权重值,五八四十正好40个权重值。可以看到权重数列的公比并不是标准的0.8,而是作者以0.8为基准从nice 0开始计算,之后又进行了一些调整,主要是为了方便计算。
下面我们再来看一下设置进程权重的函数:
linux-src/kernel/sched/core.c
static void set_load_weight(struct task_struct *p, bool update_load)
{
int prio = p->static_prio - MAX_RT_PRIO;
struct load_weight *load = &p->se.load;
/*
* SCHED_IDLE tasks get minimal weight:
*/
if (task_has_idle_policy(p)) {
load->weight = scale_load(WEIGHT_IDLEPRIO);
load->inv_weight = WMULT_IDLEPRIO;
return;
}
/*
* SCHED_OTHER tasks have to update their load when changing their
* weight
*/
if (update_load && p->sched_class == &fair_sched_class) {
reweight_task(p, prio);
} else {
load->weight = scale_load(sched_prio_to_weight[prio]);
load->inv_weight = sched_prio_to_wmult[prio];
}
}
我们先看第一行,prio = p->static_prio - MAX_RT_PRIO,由于static_prio = nice + 120,所以prio = nice + 20,nice的范围是 -20 - 19,所以prio的范围是 0 - 39,正好可以作为sched_prio_to_weight数组的下标。然后代码对SCHED_IDLE调度策略的进程进行了特殊处理,直接设置其权重为3,相当于是nice 26,反权重值也直接进行了设置。SCHED_IDLE进程的权重特别小意味其分到的CPU时间会相当的少,正好符合这个调度策略的本意。
scale_load和scale_load_down是对权重进行缩放,在32位系统上它们是空操作,在64位系统上它们是放大1024倍和缩小1024倍,主要是为了在运算时提高精度,不影响权重的逻辑。所以在后文中为了叙述方便,我们直接忽略scale_load和scale_load_down。接着往下看,update_load参数会影响代码的流程,当进程是新fork时update_load为false,会走下面的流程直接设置权重和反权重,当用户空间修改进程优先级时update_load为true,会走上面的流程调用reweight_task,reweight_task也会设置进程的权重,同时也会修改运行队列的权重。
运行队列的权重等于其上所有进程的权重之和。进程在入队出队时也会相应地从运行队列中加上减去其自身的权重。
下面我们来看一下代码(经过高度删减):
linux-src/kernel/sched/fair.c
static void enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
enqueue_entity(cfs_rq, se, flags);
}
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
account_entity_enqueue(cfs_rq, se);
}
static void
account_entity_enqueue(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
update_load_add(&cfs_rq->load, se->load.weight);
cfs_rq->nr_running++;
}
static void dequeue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
dequeue_entity(cfs_rq, se, flags);
}
static void
dequeue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
account_entity_dequeue(cfs_rq, se);
}
static void
account_entity_dequeue(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
update_load_sub(&cfs_rq->load, se->load.weight);
cfs_rq->nr_running--;
}
可以看到运行队列的总权重和其进程数量是同步更新的。
5 虚拟运行时间
我们再来看一下玻璃杯的水位是如果表示的。玻璃杯的水位就是进程的虚拟运行时间,是进程进行排队的键值。玻璃杯的水位等于玻璃杯中水的体积除以玻璃杯的横截面积,进程的虚拟运行时间等于进程的实际运行时间除以相对权重。进程的实际运行时间是一段一段的,所以进程的虚拟运行时间也是一段一段增长的。
进程的虚拟运行时间还会在进程入队时与运行队列的最小虚拟时间相比较,如果小的话会直接进行增加,并不对应实际的运行时间。这也就是我们前面说的对玻璃杯进行填充泡沫的操作。相对权重是相对于nice 0的权重,所以nice 0的进程其虚拟运行时间和实际运行时间是一致的。但是这种一致只是某一段时间中的一致,因为虚拟运行时间在进程入队时可能会空跳。在更新进程的真实虚拟运行时间的时候也会去更新运行队列的最小运行时间记录,使得运行队列的最小运行时间也在一直增长着。
进程的虚拟运行时间保存在task_struct中的sched_entity中的vruntime字段。运行队列的最小虚拟运行时间保证在cfs_rq的min_vruntime字段。下面我们来看一下它们的更新方法。
linux-src/kernel/sched/fair.c
static void update_curr(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
u64 now = rq_clock_task(rq_of(cfs_rq));
u64 delta_exec;
if (unlikely(!curr))
return;
delta_exec = now - curr->exec_start;
if (unlikely((s64)delta_exec <= 0))
return;
curr->exec_start = now;
schedstat_set(curr->statistics.exec_max,
max(delta_exec, curr->statistics.exec_max));
curr->sum_exec_runtime += delta_exec;
schedstat_add(cfs_rq->exec_clock, delta_exec);
curr->vruntime += calc_delta_fair(delta_exec, curr);
update_min_vruntime(cfs_rq);
if (entity_is_task(curr)) {
struct task_struct *curtask = task_of(curr);
trace_sched_stat_runtime(curtask, delta_exec, curr->vruntime);
cgroup_account_cputime(curtask, delta_exec);
account_group_exec_runtime(curtask, delta_exec);
}
account_cfs_rq_runtime(cfs_rq, delta_exec);
}
static inline u64 calc_delta_fair(u64 delta, struct sched_entity *se)
{
if (unlikely(se->load.weight != NICE_0_LOAD))
delta = __calc_delta(delta, NICE_0_LOAD, &se->load);
return delta;
}
/*
* delta_exec * weight / lw.weight
* OR
* (delta_exec * (weight * lw->inv_weight)) >> WMULT_SHIFT
*
* Either weight := NICE_0_LOAD and lw \e sched_prio_to_wmult[], in which case
* we're guaranteed shift stays positive because inv_weight is guaranteed to
* fit 32 bits, and NICE_0_LOAD gives another 10 bits; therefore shift >= 22.
*
* Or, weight =< lw.weight (because lw.weight is the runqueue weight), thus
* weight/lw.weight <= 1, and therefore our shift will also be positive.
*/
static u64 __calc_delta(u64 delta_exec, unsigned long weight, struct load_weight *lw)
{
u64 fact = scale_load_down(weight);
u32 fact_hi = (u32)(fact >> 32);
int shift = WMULT_SHIFT;
int fs;
__update_inv_weight(lw);
if (unlikely(fact_hi)) {
fs = fls(fact_hi);
shift -= fs;
fact >>= fs;
}
fact = mul_u32_u32(fact, lw->inv_weight);
fact_hi = (u32)(fact >> 32);
if (fact_hi) {
fs = fls(fact_hi);
shift -= fs;
fact >>= fs;
}
return mul_u64_u32_shr(delta_exec, fact, shift);
}
update_curr只能更新运行队列的当前进程,如果进程不在运行,没有实际运行时间就没有对应的虚拟运行时间。函数首先获取了当前时间now,然后用当前时间减去进程此次开始执行的时间exec_start,就得到了进程此次运行的实际时间delta_exec。进程的exec_start是在进程即将获取CPU的时候设置的,具体来说是调度流程中的pick_next_task设置的。然后再通过函数calc_delta_fair把实际运行时间转化为虚拟运行时间,把得到的结果加到进程的vruntime上。calc_delta_fair中对nice 0的进程直接返回实际运行时间,对于其它进程则调用__calc_delta进行运算。__calc_delta使用了一些复杂的数学运算技巧,比较难以理解,但是其逻辑是清晰的,就是虚拟运行时间等于实际运行时间乘以NICE_0_LOAD与进程权重的比值(delta_exec * weight / lw.weight)。接着就是更新运行队列的最小虚拟时间记录了,再往下是一些统计代码就不讲了。我们来看一下最小虚拟时间的更新。
linux-src/kernel/sched/fair.c
static void update_min_vruntime(struct cfs_rq *cfs_rq)
{
struct sched_entity *curr = cfs_rq->curr;
struct rb_node *leftmost = rb_first_cached(&cfs_rq->tasks_timeline);
u64 vruntime = cfs_rq->min_vruntime;
if (curr) {
if (curr->on_rq)
vruntime = curr->vruntime;
else
curr = NULL;
}
if (leftmost) { /* non-empty tree */
struct sched_entity *se = __node_2_se(leftmost);
if (!curr)
vruntime = se->vruntime;
else
vruntime = min_vruntime(vruntime, se->vruntime);
}
/* ensure we never gain time by being placed backwards. */
cfs_rq->min_vruntime = max_vruntime(cfs_rq->min_vruntime, vruntime);
#ifndef CONFIG_64BIT
smp_wmb();
cfs_rq->min_vruntime_copy = cfs_rq->min_vruntime;
#endif
}
此代码的逻辑是先在当前进程的vruntime和队首进程的vruntime之间选择一个最小值,如果此值大于原先的min_vruntime,就更新cfs_rq->min_vruntime为此值。
update_curr的调用时机都有哪些?下面我们来一一说明一下:
- 定时器中断,更新当前进程的虚拟运行时间,只有更新了之后才知道当前进程的时间片有没有用完。
- 唤醒抢占时,也要更新当前进程的虚拟运行时间,只有更新了之后才能正确判断是否能抢占。
- 进程被抢占离开CPU时,从触发抢占到执行抢占还有一段时间,需要更新一下虚拟运行时间。
- 进程阻塞离开CPU时,需要更新一下虚拟运行时间。
- 主动让出CPU时,通过sched_yield让出CPU时更新一下虚拟运行时间。
- 当前进程更改优先级时,更改优先级会改变权重,对已经运行的时间先更新一下虚拟运行时间。
- 执行fork时,子进程会继承父进程的vruntime,因此要更新一下父进程的vruntime。
- 用户空间定时器要统计进程的运行时间时。
- 调度均衡中迁移线程时入队和出队的队列都要调用update_curr,目的是为了更新min_vruntime,因为被迁移的线程要减去旧队列的min_vruntime,加上新队列的min_vruntime,所以min_vruntime的要是最新的才好。
6 调度周期与粒度
在以往的调度算法中,都会有明确的调度周期和时间片的概念。比如说以1秒为一个调度周期,把1秒按照进程的优先级分成时间片分给各个进程。进程在运行的过程中时间片不断地减少,当减到0的时候就不再参与调度了。当所有进程的时间片都减到0的时候,再重新开启一个调度周期,重新分配时间片。对于在一个调度周期内突然创建或者唤醒的进程,还要进行特殊的处理。在CFS中,你会发现好像没有调度周期和时间片的概念了,但是又好像有。没有,是因为没有统一分配时间片的地方了,也没有时间片递减的逻辑了。有,是因为代码中还有调度周期和时间片的函数和变量。
在CFS调度模型中玻璃杯的水位是一直在增长的,没有时间片递减的逻辑,也不存在什么调度周期。但是一个玻璃杯总是不能一直接水的,接水时间长了也是要把切走的。在CFS中玻璃杯一次接水的最大量就叫做时间片。这个时间片和传统的时间片是不一样的,这个时间片是个检测量,没有递减的逻辑。那么时间片是怎么计算的呢?这就和调度周期有关,CFS的调度周期也和传统的调度周期不一样,CFS的调度周期仅仅是一个计算量。调度周期的计算又和调度粒度有关。调度粒度是指玻璃杯一次接水的最小量,也就是进程在CPU上至少要运行多少时间才能被抢占。调度粒度指的是被动调度中进程一次运行最少的时间,如果进程阻塞发生主动调度,不受这个限制。时间片的计算依赖调度周期,调度周期的计算依赖调度粒度,所以我们就先来讲讲调度粒度。
内核中定义了sysctl_sched_min_granularity,代表调度粒度,默认值是0.75毫秒,但这并不最终使用的值,系统在启动的时候还会对这个变量进行赋值。我们来看一下代码。
linux-src/kernel/sched/fair.c
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
unsigned int nr_running = cfs_rq->nr_running;
u64 slice;
if (sched_feat(ALT_PERIOD))
nr_running = rq_of(cfs_rq)->cfs.h_nr_running;
slice = __sched_period(nr_running + !se->on_rq);
for_each_sched_entity(se) {
struct load_weight *load;
struct load_weight lw;
cfs_rq = cfs_rq_of(se);
load = &cfs_rq->load;
if (unlikely(!se->on_rq)) {
lw = cfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
slice = __calc_delta(slice, se->load.weight, load);
}
if (sched_feat(BASE_SLICE))
slice = max(slice, (u64)sysctl_sched_min_granularity);
return slice;
}
从代码中可以看出,调度粒度、唤醒粒度、调度延迟都是其规范值乘以一个因子。这个因子的值有三种可能:一是固定等于1,二是等于CPU的个数,三是等于1加上CPU个数对2的对数。具体使用哪种情况由变量sysctl_sched_tunable_scaling的值决定,此变量的值可以通过文件/sys/kernel/debug/sched/tunable_scaling来改变,默认值是SCHED_TUNABLESCALING_LOG。我们以8核CPU为例(下文也是如此),factor的值就是4,因此默认的调度粒度就是0.75 * 4 = 3毫秒。也就是说在一个8核系统默认配置下,调度粒度是3毫秒,一个进程如果运行还不到3毫秒是不能被抢占的。
此代码中还提到了唤醒粒度,我们也顺便讲一下。唤醒粒度是指被唤醒的进程如果其虚拟运行时间比当前进程的虚拟运行时间少的值不大于这个值的虚拟化时间就不进行抢占。唤醒粒度指的不是是否唤醒这个进程,而是唤醒这个进程之后是否进行抢占。只有当被唤醒的进程的虚拟运行时间比当前进程的少的足够多时才会进行抢占。当然这个也要同时满足调度粒度才会进行抢占。唤醒粒度的规范值是1毫秒,乘以4就是4毫秒。
此代码中还有调度延迟,它和调度周期有关,我们先来计算一下调度延迟的值。调度延迟的规范值是6毫秒,乘以4就是24毫秒。
调度周期的计算与调度粒度和调度延迟都有关系,所以我们现在才能开始计算调度周期。先来看代码
linux-src/kernel/sched/fair.c
static unsigned int sched_nr_latency = 8;
static u64 __sched_period(unsigned long nr_running)
{
if (unlikely(nr_running > sched_nr_latency))
return nr_running * sysctl_sched_min_granularity;
else
return sysctl_sched_latency;
}
调度延迟24毫秒是个固定值(在默认情况都不变的情况下),当运行队列上的进程个数小于等于8的时候,每个进程至少能分到3毫秒,符合调度粒度是3毫秒的设定。所以当running进程的个数小于等于8时,调度周期就等于调度延迟,每个进程至少能平分到3毫秒时间。当其个数大于8时,调度周期就等于运行进程的个数乘以调度粒度。在一个调度周期内如果是所有进程平分的话,一个进程能分到3毫秒。但是由于有的进程权重高,分到的时间就会大于3毫秒,就会有进程分到的时间少于3毫秒。实际上是这样的吗?我们来看一下计算时间片的代码。
linux-src/kernel/sched/fair.c
static u64 sched_slice(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
unsigned int nr_running = cfs_rq->nr_running;
u64 slice;
if (sched_feat(ALT_PERIOD))
nr_running = rq_of(cfs_rq)->cfs.h_nr_running;
slice = __sched_period(nr_running + !se->on_rq);
for_each_sched_entity(se) {
struct load_weight *load;
struct load_weight lw;
cfs_rq = cfs_rq_of(se);
load = &cfs_rq->load;
if (unlikely(!se->on_rq)) {
lw = cfs_rq->load;
update_load_add(&lw, se->load.weight);
load = &lw;
}
slice = __calc_delta(slice, se->load.weight, load);
}
if (sched_feat(BASE_SLICE))
slice = max(slice, (u64)sysctl_sched_min_granularity);
return slice;
}
变量slice被复用了,首先被用来表示调度周期。接下来的for循环,由于我们不考虑组调度,实际上只执行了一遍。slice的值等于调度周期乘以进程权重与运行队列权重的比值。如果进程的权重低于平均权重的话,那么其实将会小于调度粒度。再往下有个判断,由于BASE_SLICE的值默认是true,所以此语句会执行,slice至少等于调度粒度。由此可以得出结论,在默认情况下,进程分到的时间片不会小于调度粒度。那么此时实际的调度周期就会延长了。不过很大概率不会延长的,因为一般都会有进程因为阻塞而进行主动调度从而让出来一部分时间。
我们再来总结一下调度周期、调度延迟、调度粒度、时间片的概念意义和它们在CFS中的变量意义以及相互之间的关系。调度周期的概念是指运行队列上所有的进程都运行一遍的时间,但是在CFS中没有了标准的调度周期,调度周期是动态的,只是个计算量。调度延迟的概念是指一个进程从加入到运行队列到被放到CPU上去执行之间的时间差,显然这个时间差受进程本身和运行队列长短的影响。在CFS中,调度延迟的概念完全变了,调度延迟变成了调度周期的最小值。时间片的概念是指一个进程一次最多只能运行多长时间,然后就要被抢占了。在CFS中时间片的概念没有变,但是用法和传统的用法不一样。调度粒度是指一个进程一次至少运行多少时间才能被抢占,这个才CFS中也是如此。在CFS中,它们的计算关系是,调度周期等于调度粒度乘以Runnable进程的数量,但是不能小于调度延迟,时间片等调度周期乘以进程权重与运行队列权重的比值。
7 抢占调度
抢占调度有两个典型的触发点:定时器中断和进程唤醒。我们先来说定时器中断,定时器中断的主要目的就是为了进行抢占调度,防止有的进程一直占着CPU不放手。以前的算法会在定时器中断中检查进程的时间片是否已耗尽,如果耗尽的话就触发调度,不过在CFS中的具体做法与此有所不同。在CFS中不会规定固定的调度周期,调度周期都是即时计算出来的,不会给进程分配时间片进行递减,而是在定时器中断中统计进程此时占据CPU已经运行了多少时间,拿这个时间去给理论上它应当运行的时间比,如果超过了就触发调度。进程的理论运行时间就等于其权重与队列权重之比再乘以调度周期,调度周期的计算方法在上一节中讲过了。因此CFS中的调度周期和时间片与传统调度算法中的概念不同,它是一个动态的概念,只有当发生定时器中断了才会去计算一下,会根据当时的状态进行计算。比如当前进程在函数A中唤醒了很多进程,那么定时器中断是发生在函数A之前还是之后,调度周期和时间片的计算结果会有很大的不同。
下面我们来看一下定时器中断中的抢占逻辑:
linux-src/kernel/sched/core.c
void scheduler_tick(void)
{
int cpu = smp_processor_id();
struct rq *rq = cpu_rq(cpu);
struct task_struct *curr = rq->curr;
curr->sched_class->task_tick(rq, curr, 0);
}
linux-src/kernel/sched/fair.c
static void task_tick_fair(struct rq *rq, struct task_struct *curr, int queued)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &curr->se;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
entity_tick(cfs_rq, se, queued);
}
}
static void
entity_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr, int queued)
{
update_curr(cfs_rq);
update_load_avg(cfs_rq, curr, UPDATE_TG);
update_cfs_group(curr);
if (cfs_rq->nr_running > 1)
check_preempt_tick(cfs_rq, curr);
}
static void
check_preempt_tick(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
unsigned long ideal_runtime, delta_exec;
struct sched_entity *se;
s64 delta;
ideal_runtime = sched_slice(cfs_rq, curr);
delta_exec = curr->sum_exec_runtime - curr->prev_sum_exec_runtime;
if (delta_exec > ideal_runtime) {
resched_curr(rq_of(cfs_rq));
/*
* The current task ran long enough, ensure it doesn't get
* re-elected due to buddy favours.
*/
clear_buddies(cfs_rq, curr);
return;
}
/*
* Ensure that a task that missed wakeup preemption by a
* narrow margin doesn't have to wait for a full slice.
* This also mitigates buddy induced latencies under load.
*/
if (delta_exec < sysctl_sched_min_granularity)
return;
se = __pick_first_entity(cfs_rq);
delta = curr->vruntime - se->vruntime;
if (delta < 0)
return;
if (delta > ideal_runtime)
resched_curr(rq_of(cfs_rq));
}
定时器中断中会调用scheduler_tick,scheduler_tick会调用当前进程的调度类的task_tick函数指针,对于普通进程来说就是task_tick_fair函数。task_tick_fair会调用entity_tick,我们这里不考虑组调度,因此for循环只会执行一遍。在entity_tick中会先调用update_curr更新进程的运行时间,然后在当运行进程总数大于1的时候调用check_preempt_tick。check_preempt_tick就是定时器抢占的核心了。
在check_preempt_tick中会先计算出来进程的理论运行时间ideal_runtime和实际运行时间delta_exec。如果实际运行时间大于理论运行时间,就会调用resched_curr来触发抢占。如果不大于的话还会继续处理。先判断实际运行时间是否小于调度粒度,如果小于就返回。如果不小于就继续。此时会计算当前进程的虚拟运行时间与队首进程的虚拟运行时间的差值,如果差值大于前面计算出来的理论运行时间就会调用resched_curr来触发抢占。按照定时器中断的目的的话,后面这个操作是没有必要的,但是按照我们在CFS调度模型中的要求,尽量使所有玻璃杯在任意时刻的水位都尽量相同,这个操作是很有必要的,它能提高公平性。
下面我们来看一下唤醒抢占,唤醒分为新建唤醒和阻塞唤醒,最后都会调用check_preempt_curr函数来看一下是否需要抢占。下面我们来看一下代码:
linux-src/kernel/sched/core.c
void check_preempt_curr(struct rq *rq, struct task_struct *p, int flags)
{
if (p->sched_class == rq->curr->sched_class)
rq->curr->sched_class->check_preempt_curr(rq, p, flags);
else if (p->sched_class > rq->curr->sched_class)
resched_curr(rq);
}
linux-src/kernel/sched/fair.c
static void check_preempt_wakeup(struct rq *rq, struct task_struct *p, int wake_flags)
{
struct task_struct *curr = rq->curr;
struct sched_entity *se = &curr->se, *pse = &p->se;
struct cfs_rq *cfs_rq = task_cfs_rq(curr);
int scale = cfs_rq->nr_running >= sched_nr_latency;
int next_buddy_marked = 0;
int cse_is_idle, pse_is_idle;
if (test_tsk_need_resched(curr))
return;
/* Idle tasks are by definition preempted by non-idle tasks. */
if (unlikely(task_has_idle_policy(curr)) &&
likely(!task_has_idle_policy(p)))
goto preempt;
/*
* Batch and idle tasks do not preempt non-idle tasks (their preemption
* is driven by the tick):
*/
if (unlikely(p->policy != SCHED_NORMAL) || !sched_feat(WAKEUP_PREEMPTION))
return;
update_curr(cfs_rq_of(se));
if (wakeup_preempt_entity(se, pse) == 1) {
if (!next_buddy_marked)
set_next_buddy(pse);
goto preempt;
}
return;
preempt:
resched_curr(rq);
if (unlikely(!se->on_rq || curr == rq->idle))
return;
if (sched_feat(LAST_BUDDY) && scale && entity_is_task(se))
set_last_buddy(se);
}
static int
wakeup_preempt_entity(struct sched_entity *curr, struct sched_entity *se)
{
s64 gran, vdiff = curr->vruntime - se->vruntime;
if (vdiff <= 0)
return -1;
gran = wakeup_gran(se);
if (vdiff > gran)
return 1;
return 0;
}
static unsigned long wakeup_gran(struct sched_entity *se)
{
unsigned long gran = sysctl_sched_wakeup_granularity;
return calc_delta_fair(gran, se);
}
在check_preempt_curr中,同类进程会使用调度类的check_preempt_curr函数进行处理,不同类的进程,高类会抢占低类的进程。分时调度类中的相应函数是check_preempt_wakeup。此函数会先区分不同的调度策略,SCHED_IDLE策略的进程一定会被非SCHED_IDLE的进程抢占,非SCHED_NORMAL的进程一定不会抢占非SCHED_IDLE的进程。接下来会调用update_curr更新一下当前进程的时间统计,然后调用wakeup_preempt_entity来查看一下是否满足唤醒粒度,如果满足就触发调度。满足唤醒粒度的标准是当前进程的虚拟运行时间与被唤醒进程的虚拟运行时间的差值要大于唤醒粒度对应的虚拟时间。
8 入队与出队
CFS中排队的进程都是放在红黑树中,我们经常要对其进行出队入队查询队首的操作。
下面我们先来看一下内核中红黑树的定义与操作:
linux-src/include/linux/rbtree_types.h
struct rb_root_cached {
struct rb_root rb_root;
struct rb_node *rb_leftmost;
};
struct rb_root {
struct rb_node *rb_node;
};
struct rb_node {
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
}
linux-src/include/linux/rbtree.h
#define rb_first_cached(root) (root)->rb_leftmost
static __always_inline struct rb_node *
rb_add_cached(struct rb_node *node, struct rb_root_cached *tree,
bool (*less)(struct rb_node *, const struct rb_node *));
static inline struct rb_node *
rb_erase_cached(struct rb_node *node, struct rb_root_cached *root);
在CFS中经常会对队首进程进行操作,因此rb_root_cached中用rb_leftmost对红黑树的最下角的节点(这个节点就是vruntime最小的节点,就是队首进程)进行了缓存,方便查找。
我们经常会对运行队列进行入队出队操作,入队出队操作可以分为两类。一类是和调度执行相关的入队出队,叫做pick_next_task和put_prev_task,pick_next_task是选择一个进程把它放到CPU上去运行,put_prev_task是把正在CPU上运行的进程放回到运行队列中去。另一类是和非执行相关的入队出队,叫做enqueue_task和dequeue_task,enqueue_task是把一个非正在CPU上执行的进程放入到队列中去,dequeue_task是把一个进程从队列中拿出来,但不是拿来去CPU上运行的。
pick_next_task和put_prev_task都是在调度流程中的选择进程过程中调用的。
下面我们看一下代码(进行了高度删减):
linux-src/kernel/sched/core.c
static void __sched notrace __schedule(unsigned int sched_mode)
{
struct task_struct *prev, *next;
unsigned long *switch_count;
unsigned long prev_state;
struct rq_flags rf;
struct rq *rq;
int cpu;
cpu = smp_processor_id();
rq = cpu_rq(cpu);
prev = rq->curr;
prev_state = READ_ONCE(prev->__state);
if (!(sched_mode & SM_MASK_PREEMPT) && prev_state) {
if (signal_pending_state(prev_state, prev)) {
WRITE_ONCE(prev->__state, TASK_RUNNING);
} else {
deactivate_task(rq, prev, DEQUEUE_SLEEP | DEQUEUE_NOCLOCK);
}
}
next = pick_next_task(rq, prev, &rf);
if (likely(prev != next)) {
rq = context_switch(rq, prev, next, &rf);
} else {
}
}
void deactivate_task(struct rq *rq, struct task_struct *p, int flags)
{
p->on_rq = (flags & DEQUEUE_SLEEP) ? 0 : TASK_ON_RQ_MIGRATING;
dequeue_task(rq, p, flags);
}
static struct task_struct *
pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
return __pick_next_task(rq, prev, rf);
}
static inline struct task_struct *
__pick_next_task(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
const struct sched_class *class;
struct task_struct *p;
if (likely(prev->sched_class <= &fair_sched_class &&
rq->nr_running == rq->cfs.h_nr_running)) {
p = pick_next_task_fair(rq, prev, rf);
return p;
}
}
linux-src/kernel/sched/fair.c
struct task_struct * pick_next_task_fair(struct rq *rq, struct task_struct *prev, struct rq_flags *rf)
{
struct cfs_rq *cfs_rq = &rq->cfs;
struct sched_entity *se;
struct task_struct *p;
int new_tasks;
if (prev)
put_prev_task(rq, prev);
do {
se = pick_next_entity(cfs_rq, NULL);
set_next_entity(cfs_rq, se);
cfs_rq = group_cfs_rq(se);
} while (cfs_rq);
p = task_of(se);
return p;
}
static void put_prev_task_fair(struct rq *rq, struct task_struct *prev)
{
struct sched_entity *se = &prev->se;
struct cfs_rq *cfs_rq;
for_each_sched_entity(se) {
cfs_rq = cfs_rq_of(se);
put_prev_entity(cfs_rq, se);
}
}
static void put_prev_entity(struct cfs_rq *cfs_rq, struct sched_entity *prev)
{
if (prev->on_rq) {
__enqueue_entity(cfs_rq, prev);
}
cfs_rq->curr = NULL;
}
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
rb_add_cached(&se->run_node, &cfs_rq->tasks_timeline, __entity_less);
}
static struct sched_entity *
pick_next_entity(struct cfs_rq *cfs_rq, struct sched_entity *curr)
{
struct sched_entity *left = __pick_first_entity(cfs_rq);
struct sched_entity *se;
se = left; /* ideally we run the leftmost entity */
return se;
}
在执行调度的时候会调用到pick_next_task_fair,此函数会先put_prev_task再pick_next_entity。put_prev_task最终会使用rb_add_cached把被抢占的进程放回到队列中去,对于阻塞调度的则不会。pick_next_entity最终会使用rb_first_cached来获取队首进程用来调度。
enqueue_task和dequeue_task这两个函数会在修改进程优先级、设置进程亲和性、迁移进程等操作中成对使用。enqueue_task在进程唤醒中也会使用,下面我们来看一下代码。
linux-src/kernel/sched/core.c
static int
try_to_wake_up(struct task_struct *p, unsigned int state, int wake_flags)
{
unsigned long flags;
int cpu, success = 0;
cpu = select_task_rq(p, p->wake_cpu, wake_flags | WF_TTWU);
if (task_cpu(p) != cpu) {
set_task_cpu(p, cpu);
}
ttwu_queue(p, cpu, wake_flags);
return success;
}
static void ttwu_queue(struct task_struct *p, int cpu, int wake_flags)
{
struct rq *rq = cpu_rq(cpu);
struct rq_flags rf;
ttwu_do_activate(rq, p, wake_flags, &rf);
}
static void
ttwu_do_activate(struct rq *rq, struct task_struct *p, int wake_flags,
struct rq_flags *rf)
{
activate_task(rq, p, en_flags);
ttwu_do_wakeup(rq, p, wake_flags, rf);
}
void activate_task(struct rq *rq, struct task_struct *p, int flags)
{
enqueue_task(rq, p, flags);
p->on_rq = TASK_ON_RQ_QUEUED;
}
static inline void enqueue_task(struct rq *rq, struct task_struct *p, int flags)
{
p->sched_class->enqueue_task(rq, p, flags);
}
linux-src/kernel/sched/fair.c
static void
enqueue_task_fair(struct rq *rq, struct task_struct *p, int flags)
{
struct cfs_rq *cfs_rq;
struct sched_entity *se = &p->se;
for_each_sched_entity(se) {
if (se->on_rq)
break;
cfs_rq = cfs_rq_of(se);
enqueue_entity(cfs_rq, se, flags);
}
}
static void
enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se, int flags)
{
bool renorm = !(flags & ENQUEUE_WAKEUP) || (flags & ENQUEUE_MIGRATED);
bool curr = cfs_rq->curr == se;
update_curr(cfs_rq);
if (!curr)
__enqueue_entity(cfs_rq, se);
se->on_rq = 1;
}
static void __enqueue_entity(struct cfs_rq *cfs_rq, struct sched_entity *se)
{
rb_add_cached(&se->run_node, &cfs_rq->tasks_timeline, __entity_less);
}
可以看出enqueue_task最终也是调用rb_add_cached把进程放入到运行队列中去的。
9 CFS算法评价
现在我们对CFS调度算法的各个方面都有了基本的了解,让我们再看一下CFS调度模型图来回忆一下:

回忆完之后,我们对CFS算法进行一下分析和评价。首先CFS取消了对IO密集型和CPU密集型进程的探测,避免了由于误探而产生的问题。虽然没有对IO密集型和CPU密集型进程进行探测区分,但是CFS还是能很好地处理这两类进程。CPU密集型进程总是进程处于Runnable状态,所以能经常运行。由于其经常会运行,水位会比较高,所以就排到后面,就给其它进程留下了机会。IO密集型进程由于经常处于阻塞状态,所以其水位就会比较低,在其唤醒之后进入队列的时候经常能排在队首且很可能会抢占当前进程,所以IO密集型的进程响应性会比较高。
我们再来看公平性,CFS的名字就叫做完全公平调度,所以肯定是很公平的。公平性主要体现在以下几个方面。一是取消了对IO密集型和CPU密集型进程的探测,不会对IO密集型进程进行特殊的照顾,所以进程都一视同仁。二是优先级转权重的时候采用了等比数列,使得nice值相差1的进程获得的CPU时间比例总是相差10%,很公平。三是低优先级的进程随着别人的水位增长总是会排到前面的,一定会在可观的时间内得到执行,不会产生饥饿。
再来看适应性,由于采用了红黑树,CFS的出队入队查找操作都是O(logn)的,当进程变得很多时,调度效率也依然良好。与调度效率是O(n)的算法相比,适应性明显很强,和O(1)的算法相比,也不算太差。
吞吐量和很多因素有关,代码简洁,调度效率是O(logn)也会提高其吞吐量。
节能性的话,CFS本身并没有考虑这个问题。现在内核已经合入了EAS的代码,EAS是对CFS的扩展,主要是来解决调度器的节能问题的。
深入理解Linux进程调度(下)的更多相关文章
- 深入理解linux系统下proc文件系统内容
深入理解linux系统下proc文件系统内容 内容摘要:Linux系统上的/proc目录是一种文件系统,即proc文件系统. Linux系统上的/proc目录是一种文件系统,即proc文件系统.与其它 ...
- 【转】Linux目录下/dev/shm的理解和使用
一般来说,现场部署 都要根据内存的大小来设定/dev/shm的大小,大部分使用的是默认的值! Linux目录下/dev/shm的理解和使用 [日期:2014-05-16] 来源:Linux社区 作 ...
- 深入理解LINUX下动态库链接器/加载器ld-linux.so.2
[ld-linux-x86-64.so.2] 最近在Linux 环境下开发,搞了好几天 Compiler 和 linker,觉得有必要来写一篇关于Linux环境下 ld.so的文章了,google上搜 ...
- 从操作系统层面理解Linux下的网络IO模型
I/O( INPUT OUTPUT),包括文件I/O.网络I/O. 计算机世界里的速度鄙视: 内存读数据:纳秒级别. 千兆网卡读数据:微妙级别.1微秒=1000纳秒,网卡比内存慢了千倍. 磁盘读数据: ...
- 理解linux下的load
我们在做Linux负载计算的时候,我们需要了解负载的几个概念 1)Linux负载是什么 2)Linux负载怎么计算 3)如何区分目前负载是“好”还是“坏” 4)什么时候应该注意哪些不正常的值 1) ...
- linux进程调度之 FIFO 和 RR 调度策略
转载 http://blog.chinaunix.net/uid-24774106-id-3379478.html linux进程调度之 FIFO 和 RR 调度策略 2012-10-19 18 ...
- Linux进程调度原理
Linux进程调度原理 Linux进程调度机制 Linux进程调度的目标 1.高效性:高效意味着在相同的时间下要完成更多的任务.调度程序会被频繁的执行,所以调度程序要尽可能的高效: 2.加强交互性能: ...
- 深入理解Linux内存分配
深入理解Linux内存分配 为了写一个用户层程序,你也许会声明一个全局变量,这个全局变量可能是一个int类型也可能是一个数组,而声明之后你有可能会先初始化它,也有可能放在之后用到它的时候再初始化.除此 ...
- 读书笔记之Linux系统编程与深入理解Linux内核
前言 本人再看深入理解Linux内核的时候发现比较难懂,看了Linux系统编程一说后,觉得Linux系统编程还是简单易懂些,并且两本书都是讲Linux比较底层的东西,只不过侧重点不同,本文就以Linu ...
- 【云和恩墨】性能优化:Linux环境下合理配置大内存页(HugePage)
原创 2016-09-12 熊军 [云和恩墨]性能优化:Linux环境下合理配置大内存页(HugePage) 熊军(老熊) 云和恩墨西区总经理 Oracle ACED,ACOUG核心会员 PC S ...
随机推荐
- selenium高亮显示定位到的页面元素
from selenium import webdriver import unittest,time def highLightElement(driver,element): #封装好的高亮显示页 ...
- 实验6-使用TensorFlow完成线性回归 cannot import name ‘OrderedDict‘ from ‘typing‘错误的解决方法
找到对应的报错方法 删除 再添加from typing_extensions import OrderedDict
- python_xecel
移动并重命名工作簿 1 from pathlib import Path # 导入pathlib模块的path类 2 import time 3 4 # Press the green button ...
- 这本vue3编译原理开源电子书,初中级前端竟然都能看懂
前言 众所周知vue提供了很多黑魔法,比如单文件组件(SFC).指令.宏函数.css scoped等.这些都是vue提供的开箱即用的功能,大家平时用这些黑魔法的时候有没有疑惑过一些疑问呢. 我们每天写 ...
- 【Linux】快速文件交互 lrzsz
首先需要安装依赖: yum install -y lrzsz 没有此依赖,Linux提示找不到命令: [root@localhost ~]# rz -bash: rz: 未找到命令 [root@loc ...
- 读论文《Distilling the Knowledge in a Neural Network》——蒸馏网络 —— 蒸馏算法 —— 知识蒸馏 中的温度系数到底怎么用, temperature怎么用?
论文地址: https://arxiv.org/pdf/1503.02531.pdf 蒸馏网络的重要公式: 其中,\(p^g\)为Teacher网络,\(q\)为Student网络. 个体神经网络(C ...
- 【转载】 机器学习的高维数据可视化技术(t-SNE 介绍) 外文博客原文:How t-SNE works and Dimensionality Reduction
原文地址: https://www.displayr.com/using-t-sne-to-visualize-data-before-prediction/ 该文是网上传的比较多的一个 t-SNE ...
- 再探 游戏 《 2048 》 —— AI方法—— 缘起、缘灭(7) —— Python版本实现的《2048》游戏的TDL算法
<2048>游戏在线试玩地址: https://play2048.co/ 如何解决<2048>游戏源于外网的一个讨论帖子,而这个帖子则是讨论如何解决该游戏的最早开始,可谓是&q ...
- ubuntu环境下boost库的安装——Could NOT find Boost (missing: Boost_INCLUDE_DIR program_options) (Required is at least version "1.49.0")
在Ubuntu环境下使用cmake编译软件,报错,提示信息: Could NOT find Boost (missing: Boost_INCLUDE_DIR program_options) (Re ...
- Kotlin 循环与函数详解:高效编程指南
Kotlin 循环 当您处理数组时,经常需要遍历所有元素. 要遍历数组元素,请使用 for 循环和 in 操作符: 示例 输出 cars 数组中的所有元素: val cars = arrayOf(&q ...