强化学习中经验池的替代设计——A3C算法
读论文《Asynchronous methods for deep reinforcement learning》有感
----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------
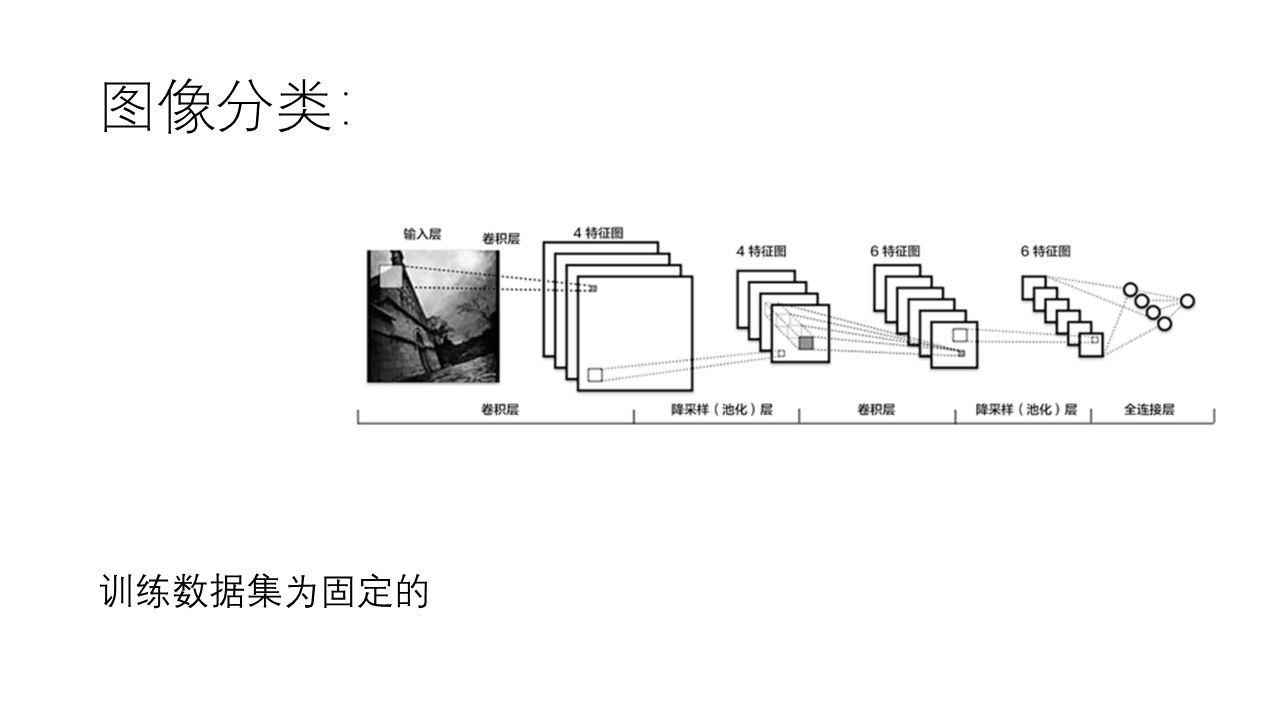
----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------

----------------------------------------------------------
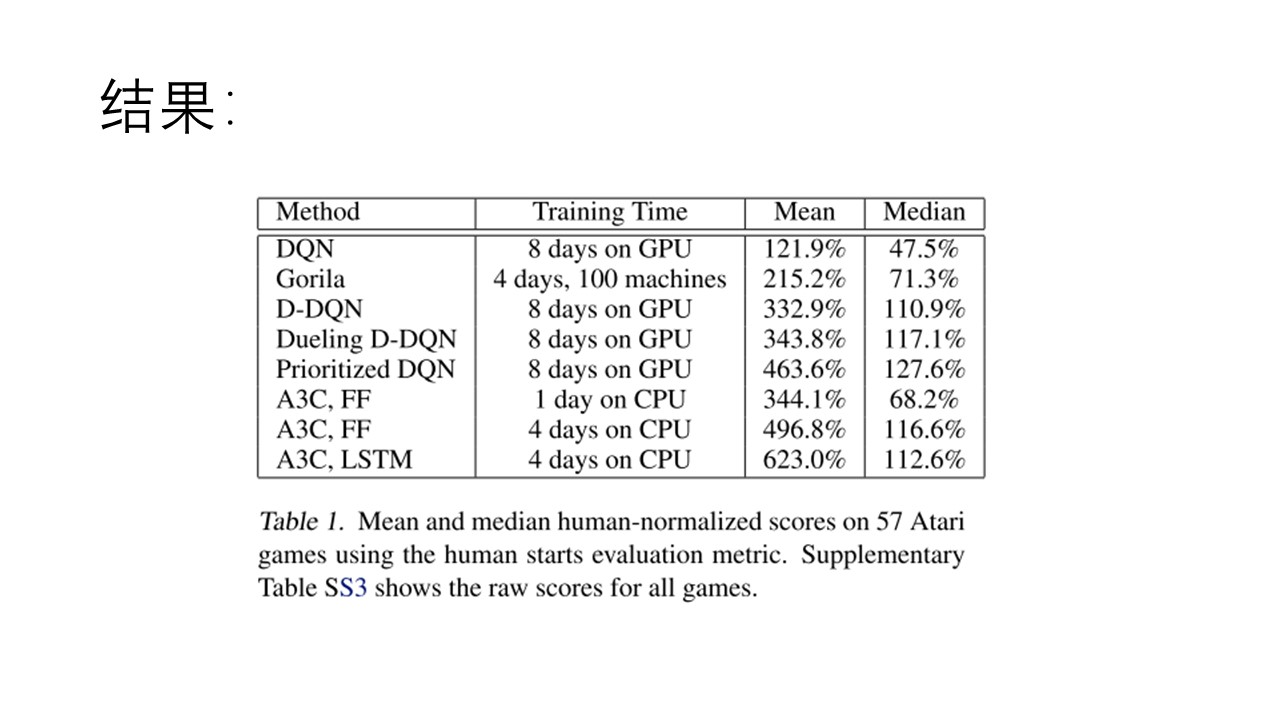
----------------------------------------------------------
强化学习中经验池的替代设计——A3C算法的更多相关文章
- 强化学习中REIINFORCE算法和AC算法在算法理论和实际代码设计中的区别
背景就不介绍了,REINFORCE算法和AC算法是强化学习中基于策略这类的基础算法,这两个算法的算法描述(伪代码)参见Sutton的reinforcement introduction(2nd). A ...
- 深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward 推荐资料 <深度强化学习中稀疏奖励问题研究综述>1 李宏毅深度强化学习Sparse Reward4 强化学习算法在被引入深度神经网络后,对大量样本的需求更加 ...
- 强化学习中的无模型 基于值函数的 Q-Learning 和 Sarsa 学习
强化学习基础: 注: 在强化学习中 奖励函数和状态转移函数都是未知的,之所以有已知模型的强化学习解法是指使用采样估计的方式估计出奖励函数和状态转移函数,然后将强化学习问题转换为可以使用动态规划求解的 ...
- 强化学习(五)—— 策略梯度及reinforce算法
1 概述 在该系列上一篇中介绍的基于价值的深度强化学习方法有它自身的缺点,主要有以下三点: 1)基于价值的强化学习无法很好的处理连续空间的动作问题,或者时高维度的离散动作空间,因为通过价值更新策略时是 ...
- 强化学习中的经验回放(The Experience Replay in Reinforcement Learning)
一.Play it again: reactivation of waking experience and memory(Trends in Neurosciences 2010) SWR发放模式不 ...
- SpiningUP 强化学习 中文文档
2020 OpenAI 全面拥抱PyTorch, 全新版强化学习教程已发布. 全网第一个中文译本新鲜出炉:http://studyai.com/course/detail/ba8e572a 个人认为 ...
- webservice入门程序学习中经验总结
***第一步:创建客户端服务 1)创建一个服务接口 2)创建一个实现类实现接口 3)创建一个方法开启服务 这三步注意点:::实现类上必须添加@WebService标签 :::发布服务的时候用到的函数是 ...
- 强化学习模型实现RL-Adventure
源代码:https://github.com/higgsfield/RL-Adventure 在Pytorch1.4.0上解决bug后的复现版本:https://github.com/lucifer2 ...
- ICML 2018 | 从强化学习到生成模型:40篇值得一读的论文
https://blog.csdn.net/y80gDg1/article/details/81463731 感谢阅读腾讯AI Lab微信号第34篇文章.当地时间 7 月 10-15 日,第 35 届 ...
- 强化学习算法DQN
1 DQN的引入 由于q_learning算法是一直更新一张q_table,在场景复杂的情况下,q_table就会大到内存处理的极限,而且在当时深度学习的火热,有人就会想到能不能将从深度学习中借鉴方法 ...
随机推荐
- Unity 3D 的NEW (堆内存)
用容器装 在AWEKE NEW 运行时NEW 会导致分配内存时界面卡住, new class 的时候 才刷新程序帧 AWEKE 是程序启动时还没走完第一帧的开头执行 AWEKE 里面的代码 常量也在A ...
- C#.NET Winform使用线程承载WCF (硬编码配置)
winform同步承载WCF时,遇到大量请求,可能会阻塞UI线程.这时就需要开个线程来承载WCF. 1.硬编码形式创建WCF服务,WCFServer类: using CommonUtils; usin ...
- mysql加解密,substring substring_index函数
mysql加解密,substring substring_index函数 SELECT to_base64(AES_ENCRYPT('测试串','key12345678')) ;SELECT AES_ ...
- 向Web服务器端上传文件
server.py import flaskapp = flask.Flask(__name__)@app.route('/upload', methods=['POST'])def uploadFi ...
- Wireshark找不到接口
在管理员权限下的命令行窗口输入net start npf即可. 注意是管理员权限下的,否则会拒绝访问.
- python中globals()的用法
python中globals()的用法 1. 获取所有的全局变量, 获取到的内容如下: {'__name__': '__main__', '__doc__': None, '__package__': ...
- Log4Net配置详解及输出自定义消息类示例
1.简单使用实例 1.1 添加log4net.dll的引用. 在NuGet程序包中搜索log4net并添加,此次我所用版本为2.0.17.如下图: 1.2 添加配置文件 右键项目,添加新建项, ...
- Win10 下安装使用easyocr图片识别工具
[前言] 最近在做图像识别相关的工作,找到了一个名为EasyOCR的pythoh 库. 使用过程中出现了一些问题,现做简单记录. [正文] 1. 安装EasyOCR 我用了最简单的方法:pip3 in ...
- Java 集合元素排序接口Comparable
什么是Comparable public interface Comparable<T> { /** * Compares this object with the specified o ...
- Oracle 日期减年数、两日期相减
-- 日期减年数 SELECT add_months(DEF_DATE,12*USEFUL_LIFE) FROM S_USER --两日期相减 SELECT round(sysdate-PEI.STA ...