reinforcement learning常用的游戏环境,gym框架使用的标准Atari游戏集合
reinforcement learning常用的游戏环境,gym框架使用的标准Atari游戏集合。*.bin文件为Atari2600游戏的常用游戏环境的模拟文件,也称为roms文件。
文件地址:
https://gitee.com/devilmaycry812839668/atari_roms
======================================================
在强化学习中使用gym搭建游戏环境,操作如下:
pip install gym[atari]
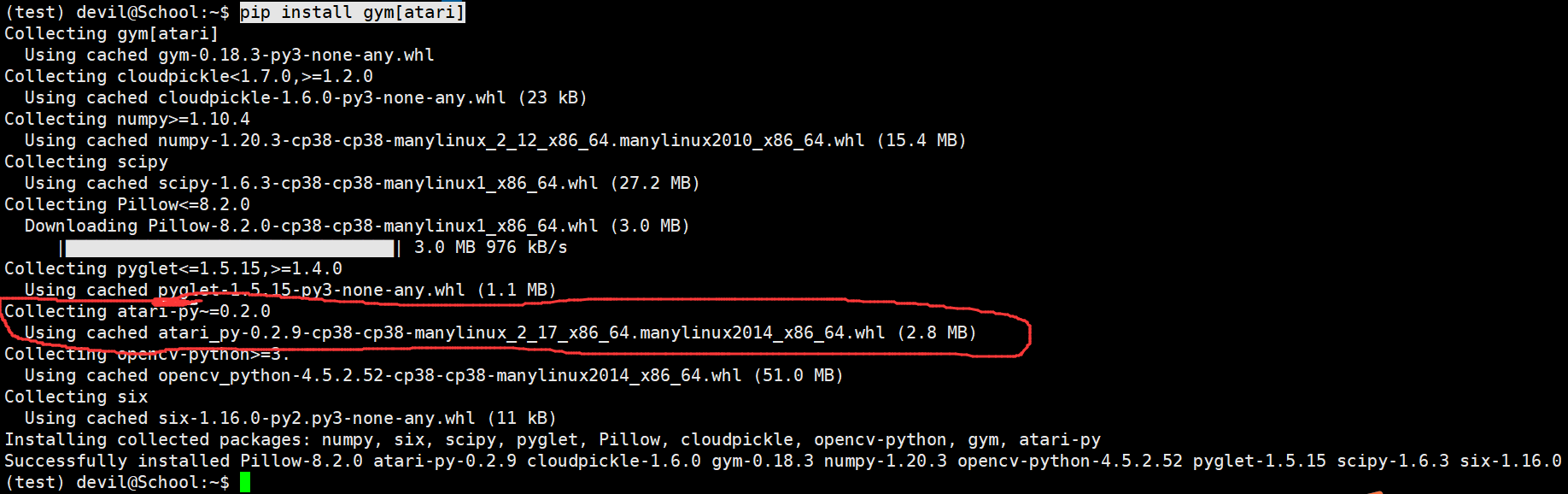
可以看到 使用gym 安装atari游戏环境的时候其实也是自动去安装 Atari环境库的,即,atari-py
https://github.com/openai/atari-py/
安装成功后运行环境:
import gym
env = gym.make("SpaceInvaders-v0")
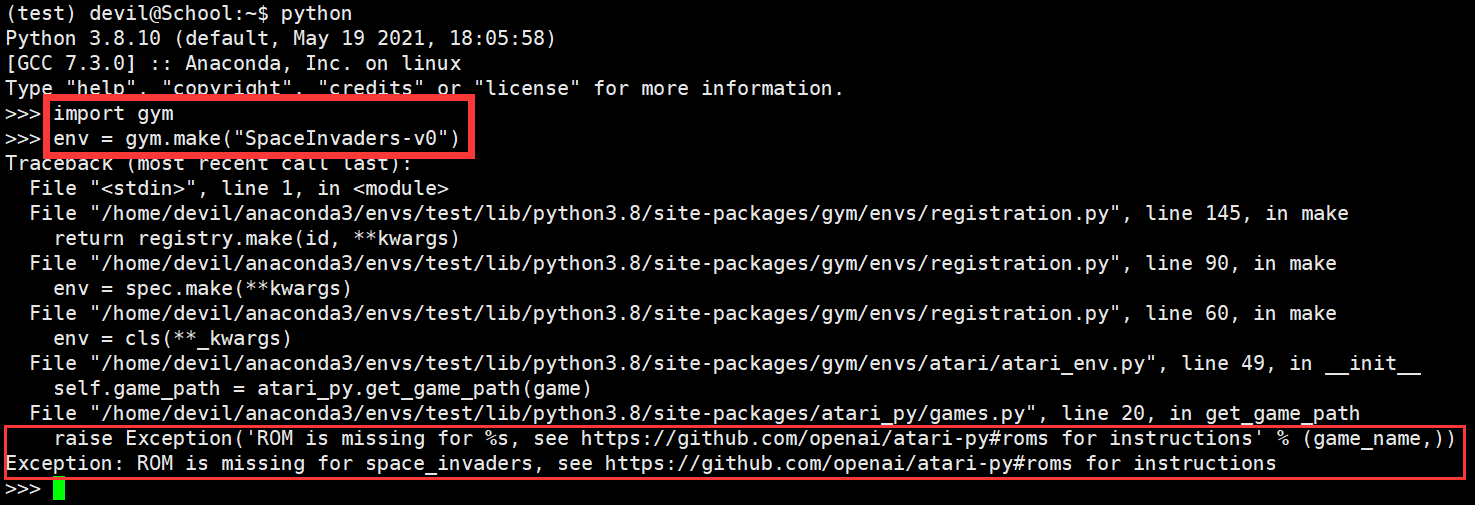
发现运行 Atari环境下的游戏是报错的,提示就是没有 roms文件,也就是 https://gitee.com/devilmaycry812839668/atari_roms 下的 *.bin 文件。
解决方法就是在 https://gitee.com/devilmaycry812839668/atari_roms 中把里面的 *.bin 文件下载下来放到自己本机 atari_py 模块下的 atari_roms文件夹下面。
具体:
查找 gym 的安装路径:

通过gym的路径找到 atari_py 的路径( gym 一般与atari_py 安装在同一目录下):

把 下载好的 bin 文件拷贝到 atari_py 下面的 atari_roms 中:

测试是否安装成功:
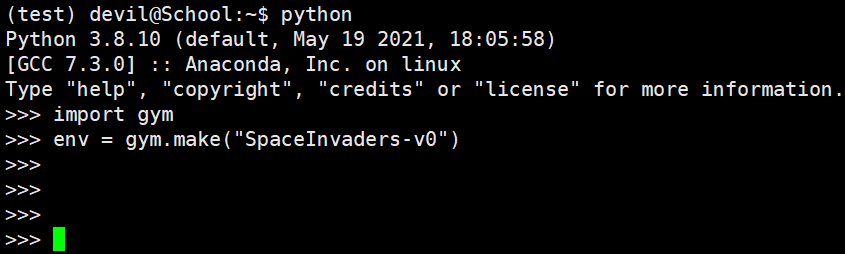
成功运行 atari 游戏环境。
reinforcement learning常用的游戏环境,gym框架使用的标准Atari游戏集合的更多相关文章
- 18 Issues in Current Deep Reinforcement Learning from ZhiHu
深度强化学习的18个关键问题 from: https://zhuanlan.zhihu.com/p/32153603 85 人赞了该文章 深度强化学习的问题在哪里?未来怎么走?哪些方面可以突破? 这两 ...
- Discovering Reinforcement Learning Algorithms
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:2007.08794v1 [cs.LG] 17 Jul 2020 Abstract 强化学习(RL)算法根据经过多年研究手动发 ...
- Statistics and Samples in Distributional Reinforcement Learning
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1902.08102v1 [stat.ML] 21 Feb 2019 Abstract 我们通过递归估计回报分布的统计量,提供 ...
- (转) Deep Learning in a Nutshell: Reinforcement Learning
Deep Learning in a Nutshell: Reinforcement Learning Share: Posted on September 8, 2016by Tim Dettm ...
- 转:高层游戏引擎——基于OGRE所实现的高层游戏引擎框架
高层游戏引擎——基于OGRE所实现的高层游戏引擎框架 这是意念自己的毕业论文,在一个具体的实践之中,意念主要负责的是物件和GUI之外的其他游戏系统.意念才学疏陋,望众位前辈不吝赐教.由于代码质量不高. ...
- github上DQN代码的环境搭建,及运行(Human-Level Control through Deep Reinforcement Learning)conda配置
最近师弟在做DQN的实验,由于是强化学习方面的东西,正好和我现在的研究方向一样于是我便帮忙跑了跑实验,于是就有了今天的这个内容. 首先在github上进行搜寻,如下图: 发现第一个星数最多,而且远高于 ...
- Deep Reinforcement Learning: Pong from Pixels
这是一篇迟来很久的关于增强学习(Reinforcement Learning, RL)博文.增强学习最近非常火!你一定有所了解,现在的计算机能不但能够被全自动地训练去玩儿ATARI(译注:一种游戏机) ...
- [Reinforcement Learning] 强化学习介绍
随着AlphaGo和AlphaZero的出现,强化学习相关算法在这几年引起了学术界和工业界的重视.最近也翻了很多强化学习的资料,有时间了还是得自己动脑筋整理一下. 强化学习定义 先借用维基百科上对强化 ...
- Reinforcement Learning, Fast and Slow
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! 1 DeepMind, London, UK2 University College London, London, UK3 Prince ...
- Improved robustness of reinforcement learning policies upon conversion to spiking neuronal network platforms applied to Atari Breakout game
郑重声明:原文参见标题,如有侵权,请联系作者,将会撤销发布! arXiv:1903.11012v3 [cs.LG] 19 Aug 2019 Neural Networks, 25 November 2 ...
随机推荐
- Apollo启动配置排查,超时时间的配置
Apollo启动配置排查 1.排查下来是 本地的服务 apollo 配置fake发布到线上去了.2.或者是引用的apollo jar包中指向的apollo服务器地址是否正确. 3.超时时间的配置 ## ...
- 支付宝 返回的form如何在前端打开
支付宝支付时返回了一段标签标签大概是 <form></form><script></script> 试了innerHtml怎么试都不能用,是那种直接把字 ...
- ACPI Table 与 Device Tree
背景 在分析Linux内核驱动的时候,有时候会看到一些acpi字样的接口. 之前一直没搞明白ACPI是什么,现在知道了. Reference : https://www.cnblogs.com/jun ...
- Electron 的 安装
背景 因为搞嵌入式开发的时候,每次烧写不同版本的固件的时候,经常需要重命名,有时候烧错版本我也不知道: 因此我认为对固件的管理比较麻烦,所以我希望能够有一个比较好的工具来做管理,找了一圈没有发现合适的 ...
- R语言遍历文件夹求取其中所有栅格文件的平均值
本文介绍基于R语言中的raster包,遍历读取多个文件夹下的多张栅格遥感影像,分别批量对每一个文件夹中的多个栅格图像计算平均值,并将所得各个结果栅格分别加以保存的方法. 其中,本文是用R语言来 ...
- Fake权限验证小例子
前言 关于本地测试如何进行Fake权限验证 正文 在我们使用swagger调试本地接口的时候,我们常常因为每次需要填写token而耽误工作,不可能每次调试的时候都去本地测试环境请求一个token进行验 ...
- 【electron-vite+live2d+vue3+element-plus】实现桌面模型宠物+桌面管理系统应用(踩坑)
脚手架 项目使用 electron-vite 脚手架搭建 ps:还有一个框架是 electron-vite ,这个框架我发现与pixi库有冲突,无法使用,如果不用pixi也可以用这个脚手架. node ...
- 【ClickHouse】6:clickhouse集群高可用
背景介绍: 有四台CentOS7服务器安装了ClickHouse HostName IP 安装程序 程序端口 shard(分片) replica(备份) centf8118.sharding1.db ...
- 【Zabbix】Zabbix5.0安装部署问题汇总
报错信息:No package 'oniguruma' found 解决方法:https://www.limstash.com/articles/202003/1563 报错信息: PHP bcmat ...
- Docker下安装Nginx代理服务器【工作实操版】
一.Nginx下载 使用命令拉取nginx镜像到本地,此处我们获取排名第一的是官方最新镜像,其它版本可以去DockerHub查询 docker pull nginx 二.先启动一个nginx容器用于c ...