《最新出炉》系列初窥篇-Python+Playwright自动化测试-38-如何截图-下篇
1.简介
这个系列的文章也讲解和分享了差不多三分之一吧,突然有小伙伴或者童鞋们问道playwright有没有截图的方法。答案当然是:肯定有的。宏哥回过头来看看确实这个非常基础的知识点还没有讲解和分享。那么在这个契机下就把它插队分享和讲解一下。Playwright提供了一个截屏的API:page.screenshot。使用该API,只需要指定截图的图片的保存路径及文件名即可。如果仅指定文件名,默认保存在当前目录。
2.截图语法
截图介绍官方API的文档地址:https://playwright.dev/python/docs/screenshots
2.1截图参数
screenshot方法可以进行截图,参数如下:
timeout:以毫秒为单位的超时时间,0为禁用超时
path:设置截图的路径
type:图片类型,默认jpg
quality:像素,不适用于jpg
omit_background: 隐藏默认白色背景,并允许捕获具有透明度的屏幕截图。不适用于“jpeg”图像。
full_page:如果为true,则获取完整可滚动页面的屏幕截图,而不是当前可见的视口。默认为
`假`。
clip:指定结果图像剪裁的对象clip={'x': 10 , 'y': 10, 'width': 10, 'height': 10}
3.按照元素截图(截取页面一部分)
有时候,我们可能只想截取页面的一部分,那么,Playwright也支持将想要截取的部分筛选出来,然后调用截图API进行截图。参数同上,只是调用截图方法的对象不同,快速截图是page,按照元素截图是page下的元素,有时截取单个元素的屏幕截图很有用。语法如下:
page.locator(".header").screenshot(path="screenshot.png")
3.1代码设计
使用示例,截图百度页面的form 表单输入框和搜索按钮,如下图所示:
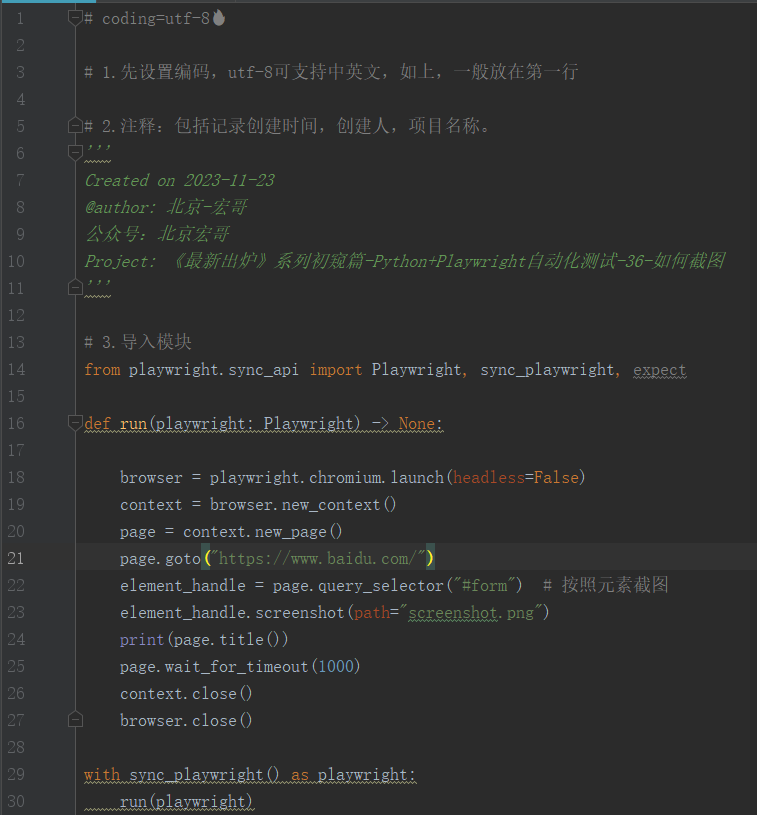
3.2参考代码
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-11-23
@author: 北京-宏哥
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-36-如何截图
''' # 3.导入模块
from playwright.sync_api import Playwright, sync_playwright, expect def run(playwright: Playwright) -> None: browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/")
element_handle = page.query_selector("#form") # 按照元素截图
element_handle.screenshot(path="screenshot.png")
print(page.title())
page.wait_for_timeout(1000)
context.close()
browser.close() with sync_playwright() as playwright:
run(playwright)
3.3运行代码
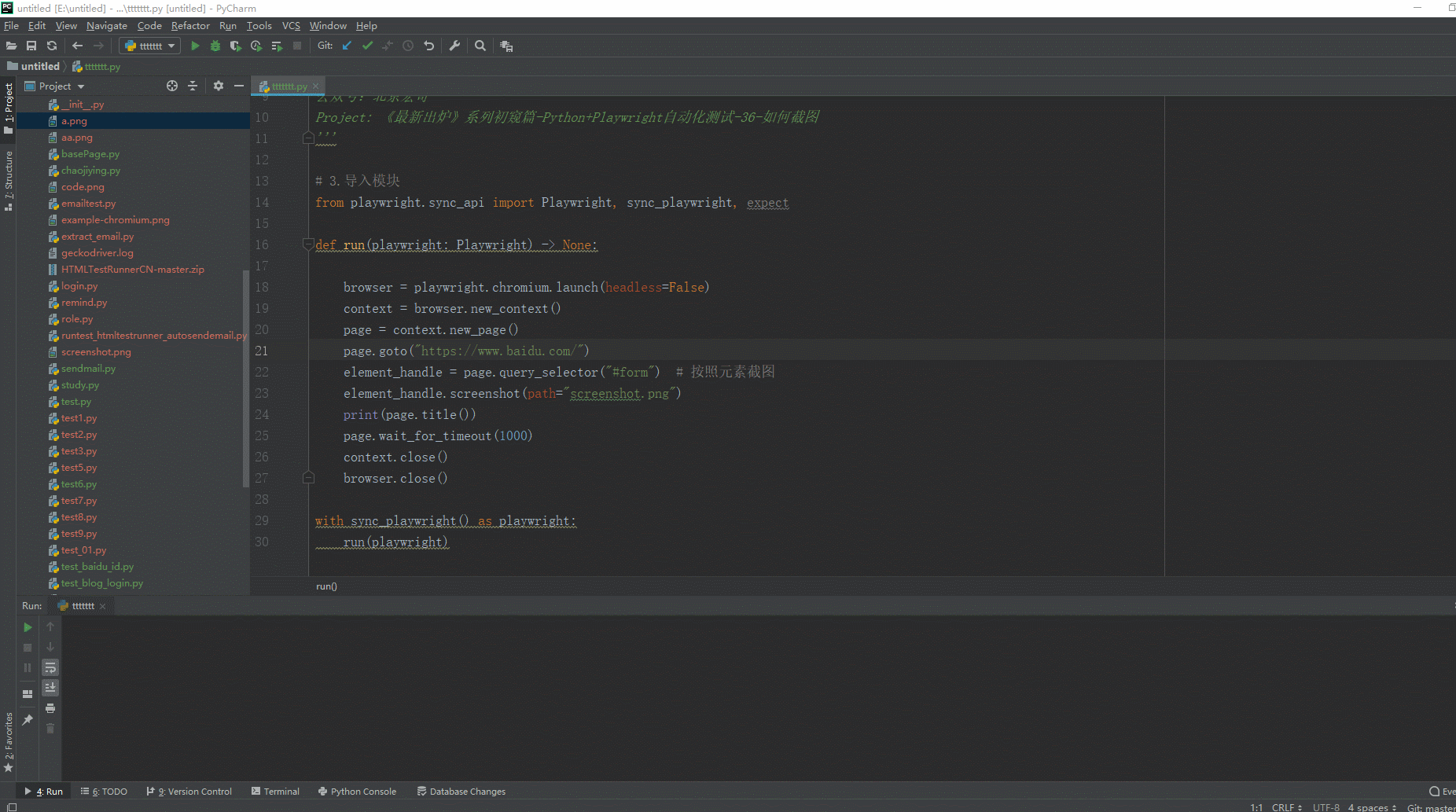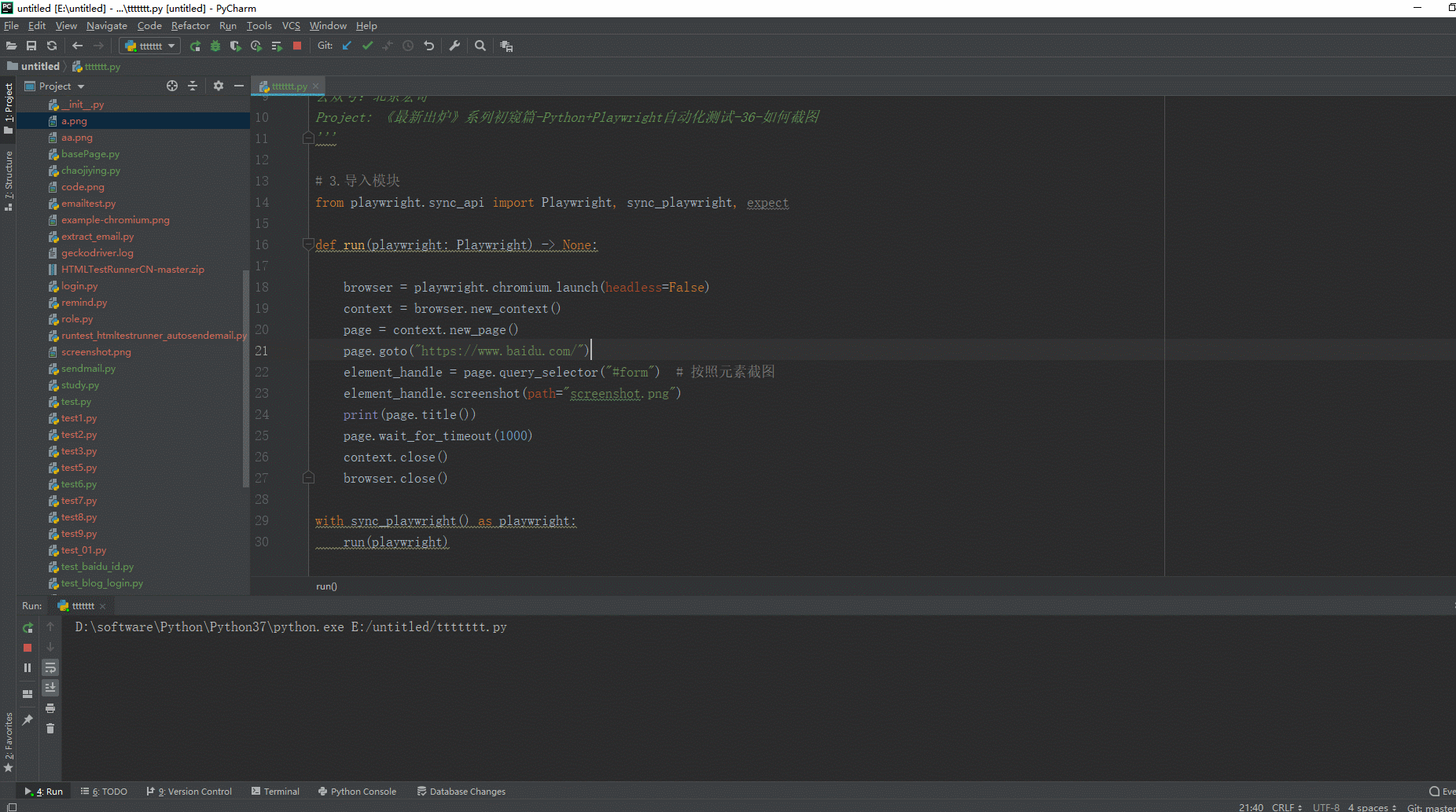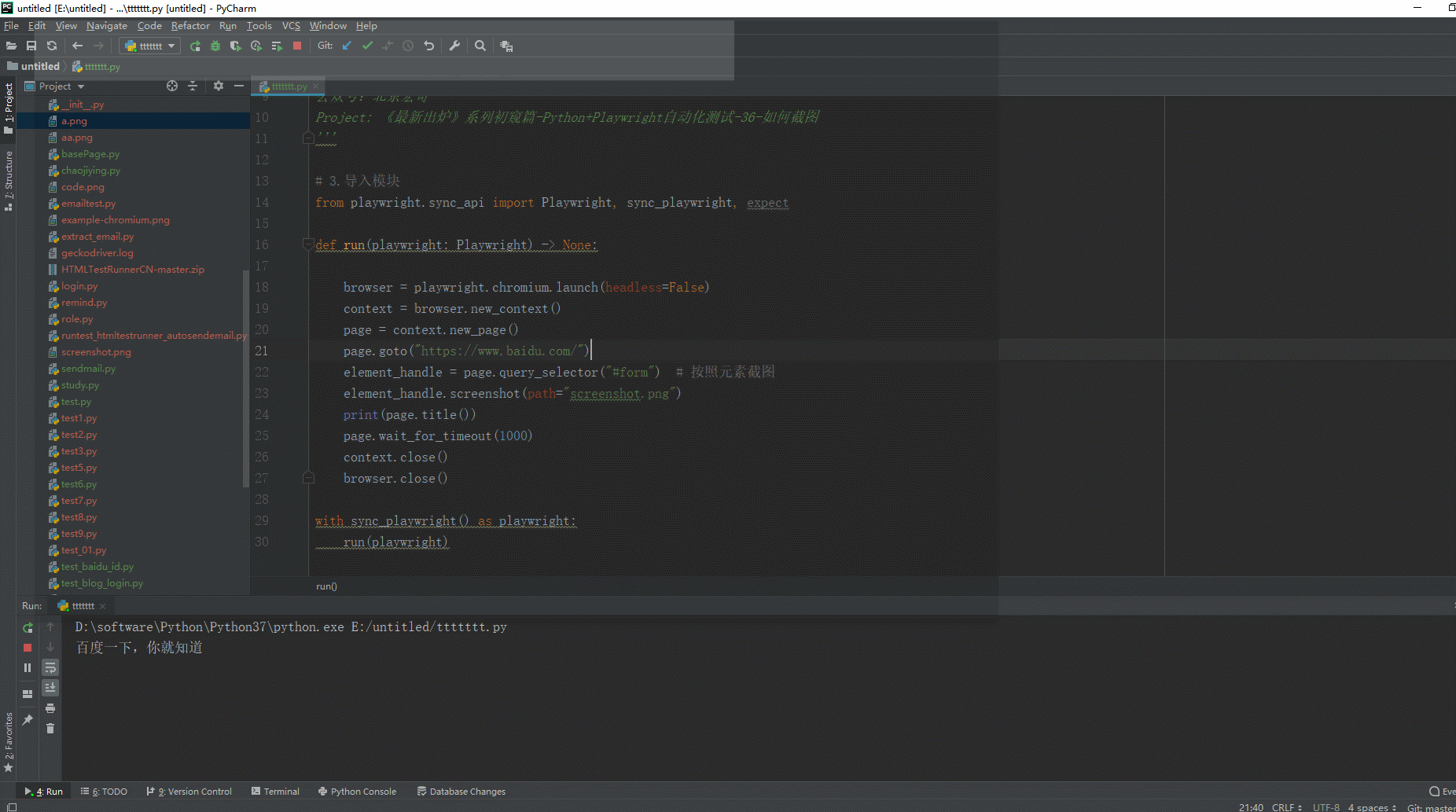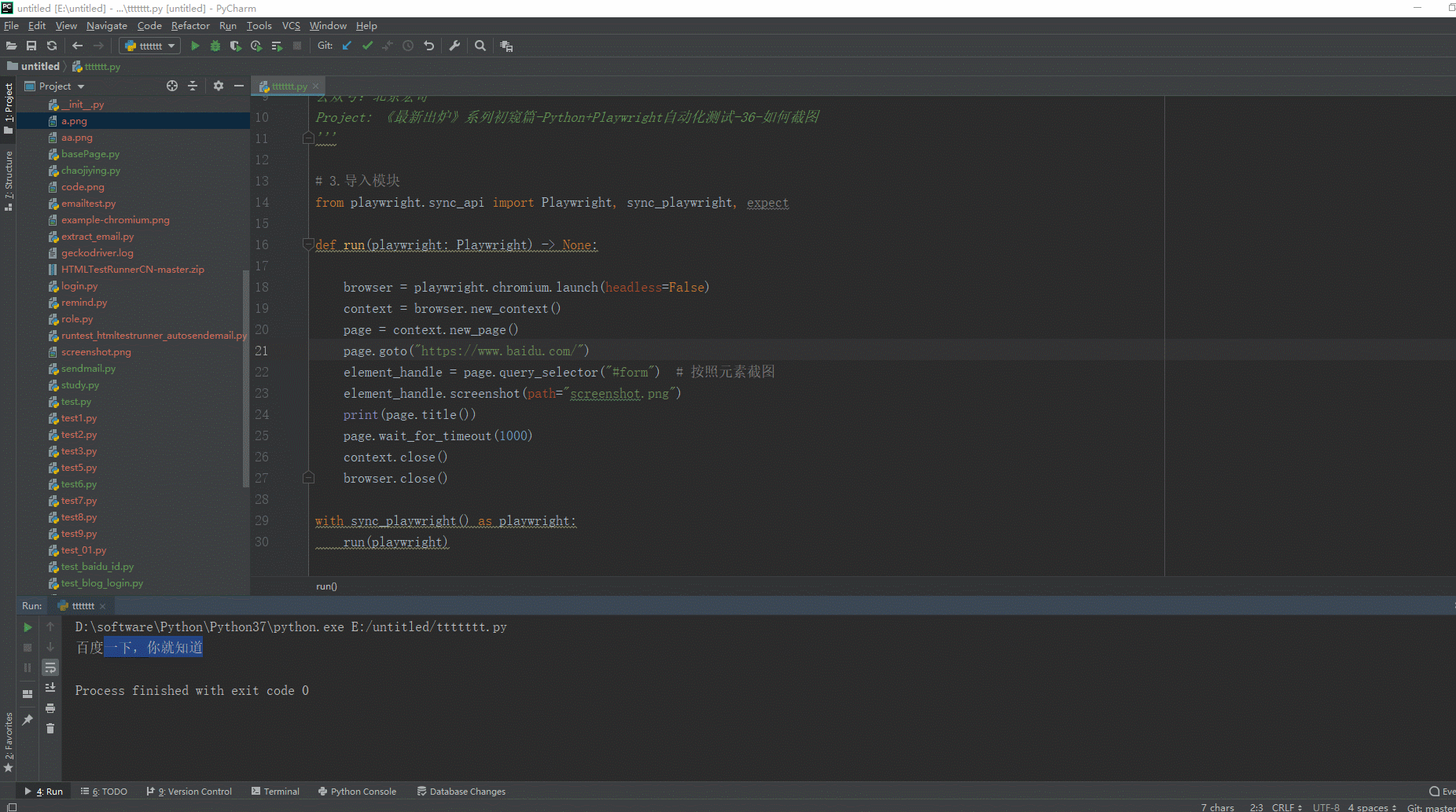
1.运行代码,右键Run'Test',控制台输出,如下图所示:
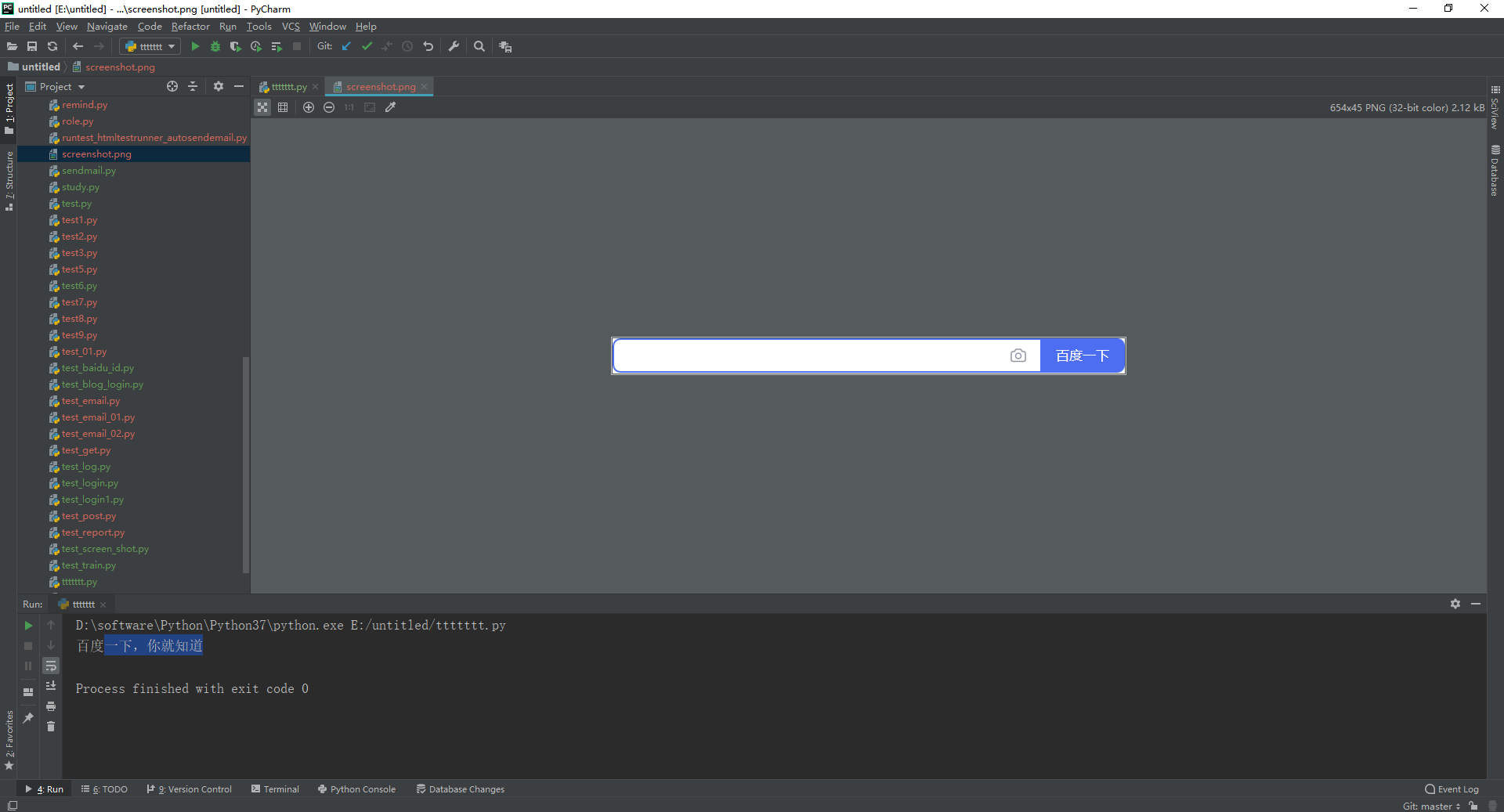
2.运行代码后电脑端的浏览器的动作。如下图所示:
4.捕捉到缓冲区
使用base64对图片数据进行加密、解密。除了可以将页面截图保存为图片之外,也可以使用base64对图片数据进行加密和解密,将图片转换为一串字符。您可以获取包含图像的缓冲区并对其进行后处理或将其传递给第三方像素差异工具,而不是写入文件。语法如下:
screenshot_bytes = page.screenshot()
print(base64.b64encode(screenshot_bytes).decode())
4.1代码设计
示例:截取页面后,转换为一串字符并输出。
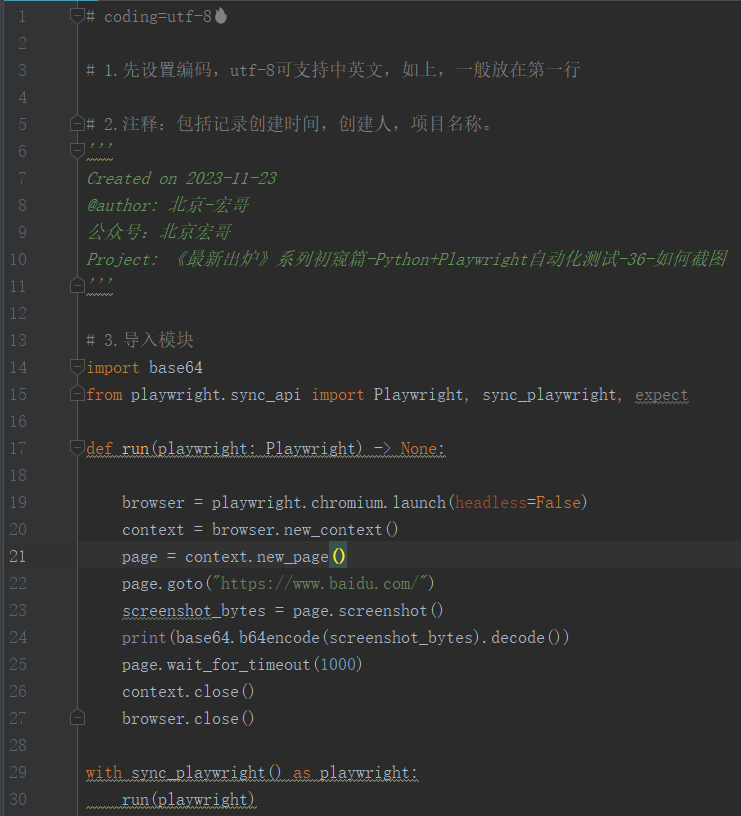
4.2参考代码
# coding=utf-8 # 1.先设置编码,utf-8可支持中英文,如上,一般放在第一行 # 2.注释:包括记录创建时间,创建人,项目名称。
'''
Created on 2023-11-23
@author: 北京-宏哥
公众号:北京宏哥
Project: 《最新出炉》系列初窥篇-Python+Playwright自动化测试-36-如何截图
''' # 3.导入模块
import base64
from playwright.sync_api import Playwright, sync_playwright, expect def run(playwright: Playwright) -> None: browser = playwright.chromium.launch(headless=False)
context = browser.new_context()
page = context.new_page()
page.goto("https://www.baidu.com/")
screenshot_bytes = page.screenshot()
print(base64.b64encode(screenshot_bytes).decode())
page.wait_for_timeout(1000)
context.close()
browser.close() with sync_playwright() as playwright:
run(playwright)
4.3运行代码
1.运行代码,右键Run'Test',控制台输出(转换为一串字符并输出),如下图所示:
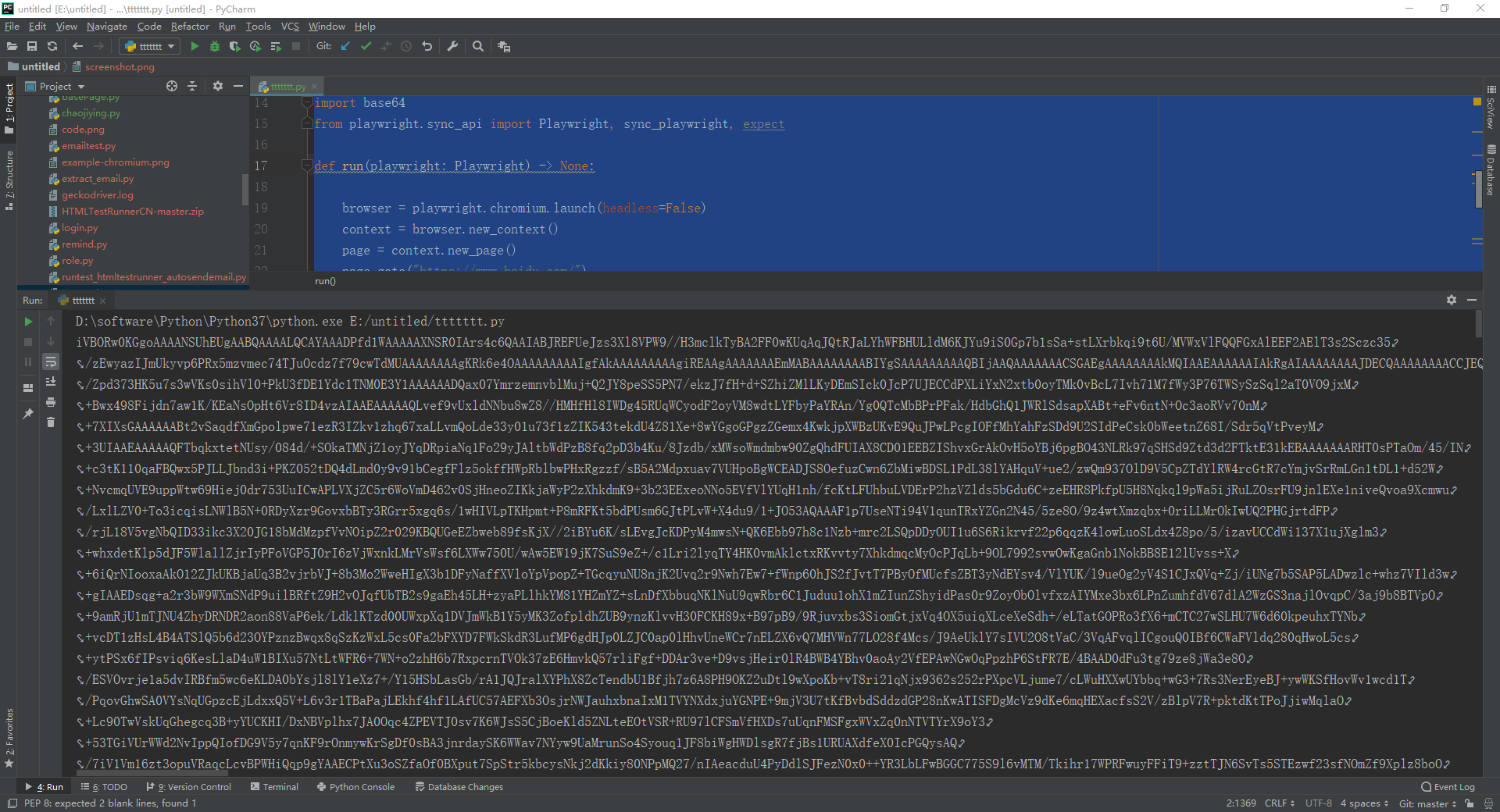
2.运行代码后电脑端的浏览器的动作。如下图所示:

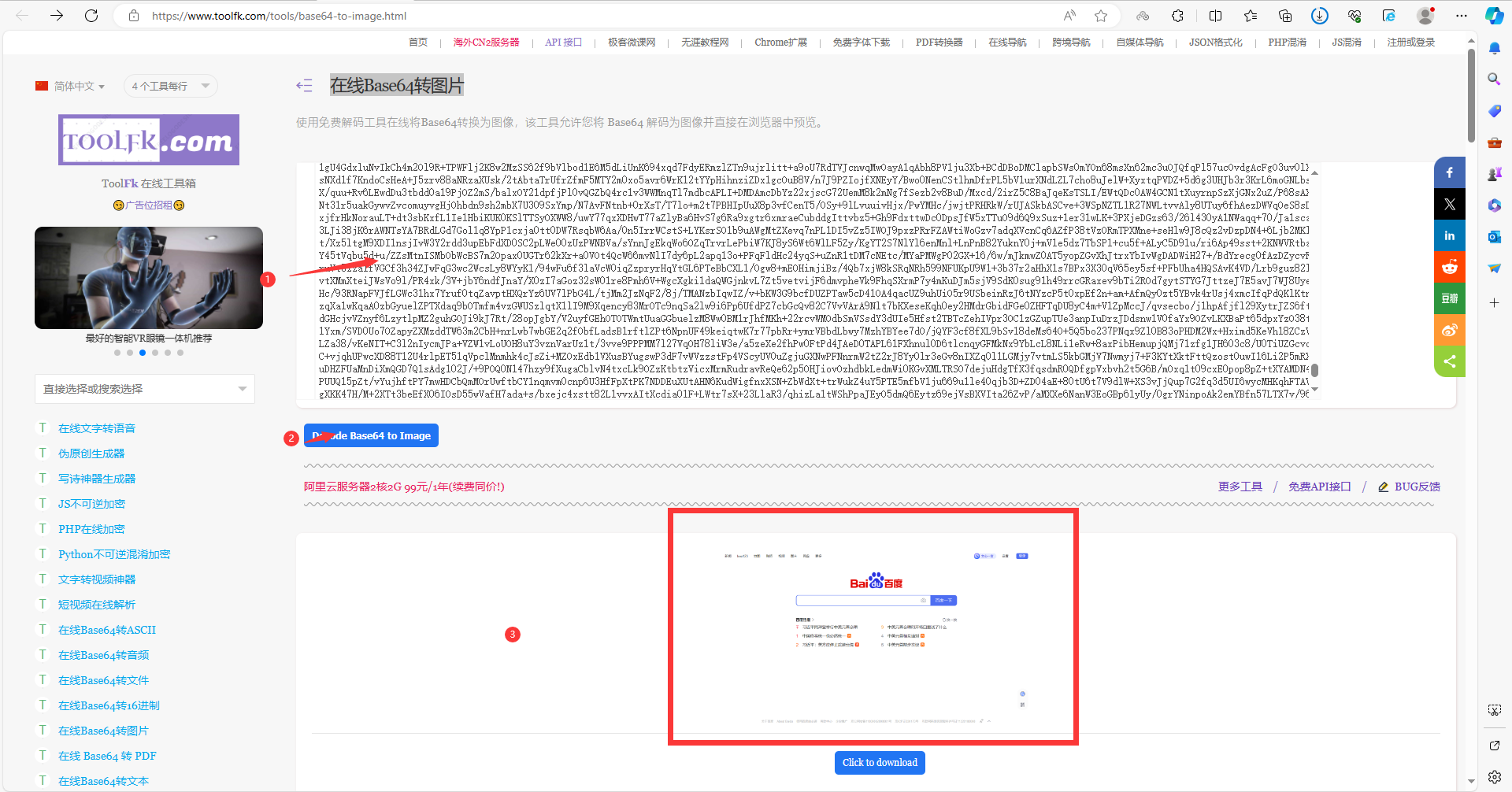
4.4在线Base64转图片
随便百度一个在线Base64转图片的地址,然后将我们上边控制台打印的Base64的字符串复制后,粘贴到工具里,将其转换成图片看看是不是我们的截图结果,如下图所示:
5.小结
好了,今天时间不早了,关于playwright的截图就先介绍讲解到这里,到此截图基础知识就差不多了,感谢您耐心的阅读!!!
《最新出炉》系列初窥篇-Python+Playwright自动化测试-38-如何截图-下篇的更多相关文章
- python web自动化测试中失败截图方法汇总
在使用web自动化测试中,用例失败则自动截图的网上也有,但实际能落地的却没看到,现总结在在实际应用中失败截图的几种方法: 一.使用unittest框架截图方法: 1.在tearDown中写入截图的 ...
- Flutter 即学即用系列博客——04 Flutter UI 初窥
前面三篇可以算是一个小小的里程碑. 主要是介绍了 Flutter 环境的搭建.如何创建 Flutter 项目以及如何在旧有 Android 项目引入 Flutter. 这一篇我们来学习下 Flutte ...
- Spark系列-初体验(数据准备篇)
Spark系列-初体验(数据准备篇) Spark系列-核心概念 在Spark体验开始前需要准备环境和数据,环境的准备可以自己按照Spark官方文档安装.笔者选择使用CDH集群安装,可以参考笔者之前的文 ...
- Python系列之入门篇——HDFS
Python系列之入门篇--HDFS 简介 HDFS (Hadoop Distributed File System) Hadoop分布式文件系统,具有高容错性,适合部署在廉价的机器上.Python ...
- Python系列之入门篇——MYSQL
Python系列之入门篇--MYSQL 简介 python提供了两种mysql api, 一是MySQL-python(不支持python3),二是PyMYSQL(支持python2和python3) ...
- python爬虫 scrapy2_初窥Scrapy
sklearn实战-乳腺癌细胞数据挖掘 https://study.163.com/course/introduction.htm?courseId=1005269003&utm_campai ...
- WWDC15 Session笔记 - Xcode 7 UI 测试初窥
https://onevcat.com/2015/09/ui-testing/ WWDC15 Session笔记 - Xcode 7 UI 测试初窥 Unit Test 在 iOS 开发中已经有足够多 ...
- Scrapy001-框架初窥
Scrapy001-框架初窥 @(Spider)[POSTS] 1.Scrapy简介 Scrapy是一个应用于抓取.提取.处理.存储等网站数据的框架(类似Django). 应用: 数据挖掘 信息处理 ...
- 初窥Kaggle竞赛
初窥Kaggle竞赛 原文地址: https://www.dataquest.io/mission/74/getting-started-with-kaggle 1: Kaggle竞赛 我们接下来将要 ...
- scrapy2_初窥Scrapy
递归知识:oop,xpath,jsp,items,pipline等专业网络知识,初级水平并不是很scrapy,可以从简单模块自己写. 初窥Scrapy Scrapy是一个为了爬取网站数据,提取结构性数 ...
随机推荐
- stm32 文件系统数据读写源码解析
一 概念 fatfs文件系统在文件读写中不可或却.熟悉和深入理解是一个不可或缺的前提. 这里面需要先明确几个概念:文件open的属性,这个非常重要.可以并列使用. 二 源码解析 A 写入数据: i ...
- 2.4G无线音频传输方案市场调研分析
基本概念 所谓的2.4G音频传输,不是使用标准的wifi和蓝牙协议传输,而是使用私有的2.4G通信协议来实现点对点,一对多和多对一的音频传输.2.4G私有协议音频传输,有这低延时,距离远,声音高清 ...
- Django使用Bootstrap的经典方法
前面的话 Bootstrap是简单.灵活的用于搭建WEB页面的HTML.CSS.Javascript的工具集.Bootstrap基于HTML5和CSS3,具有漂亮的设计.友好的学习曲线.卓越的兼容性, ...
- 记录--uni-app实现蓝牙打印小票
这里给大家分享我在网上总结出来的一些知识,希望对大家有所帮助 说明 基于uni-app开发,调用官方蓝牙相关api实现连接蓝牙与向蓝牙热敏打印机发送字节流,可打印文字,二维码,图片,调整字体大小等,本 ...
- KingbaseES V8R3 集群运维案例--sys_rewind恢复备库节点
案例说明: 在KingbaseES V8R3集群执行failover切换后,原主库被人为误(未配置recovery.conf)启动:或者人为promote备库为主库后.需要将操作节点再重新加入集群 ...
- debian12 linux root能用lightdm登陆xfce桌面,普通用户不能用lightdm登陆xfce桌面,闪一下黑屏和一个_,又回到lightdm
Fn+Ctrl+F3,进入tty,发现登陆普通用户后再使用startxfce4可以直接进桌面 下面参照 https://forums.opensuse.org/t/normal-user-can-no ...
- TVM 代码生成—TIR to LLVM IR
本文地址:https://www.cnblogs.com/wanger-sjtu/p/17573212.html TVM在编译过程中,经历了 graph LR A[3rd IR] --> B[R ...
- 在DAYU200上实现OpenHarmony视频播放器
内容简介 本文介绍了如何使用ArkUI框架提供的video组件,实现一个具有简易播放器.通过VideoController控制器来控制倍速.全屏.进度调节等功能. 由于使用本地视频文件会影响App的包 ...
- Caused by: java.lang.reflect.InaccessibleObjectException: Unable to make field private final java.lang.Class java.lang.invoke.SerializedLambda.capturingClass accessible
完整日志: Caused by: java.lang.reflect.InaccessibleObjectException: Unable to make field private final j ...
- VS 在 Release 模式下使用断点调试程序
修改方法: 项目属性 --> c/c++ --> 常规 --> 调试信息格式 选择程序数据库 (默认:无) 项目属性 --> c/c++ --> 优化 --> 优化 ...