Prometheus 聚合查询的两个方案
问题背景
多个 Prometheus 集群或者多个 VictoriaMetrics 集群,在 Grafana 和夜莺里通常需要创建多个不同的数据源,这也就意味着,数据没法聚合查询,比如统一做一下 sum 之类的运算会比较麻烦,本文讲述两种 Prometheus 生态的聚合查询方案,以供参考。
场景模拟
我在本地模拟一个这样的场景:两套时序库,比如一套采集的 tomcat 相关机器的指标,一套采集的 oracle 相关机器的指标,相当于按业务切分的两套时序库。这里涉及三个组件:
- node_exporter:仅用于模拟提供监控指标
- prometheus9090:监听在 9090 端口的 prometheus,用于采集 node_exporter 的监控指标,会为数据附加上
service="tomcat"的标签,表示这是 tomcat 业务的监控指标 - prometheus9091:监听在 9091 端口的 prometheus,用于采集 node_exporter 的监控指标,会为数据附加上
service="oracle"的标签,表示这是 oracle 业务的监控指标
prometheus9090 的配置文件 prometheus.9090.yml 如下:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "node_exporter"
static_configs:
- targets: ["localhost:9100"]
labels:
service: tomcatprometheus9091 的配置文件 prometheus.9091.yml 如下:
global:
scrape_interval: 15s
evaluation_interval: 15s
scrape_configs:
- job_name: "node_exporter"
static_configs:
- targets: ["localhost:9100"]
labels:
service: oracle最后,我把这俩时序库作为数据源配置到夜莺中,你也可以使用 Grafana 测试,分别查询这俩数据源,得到预期结果。
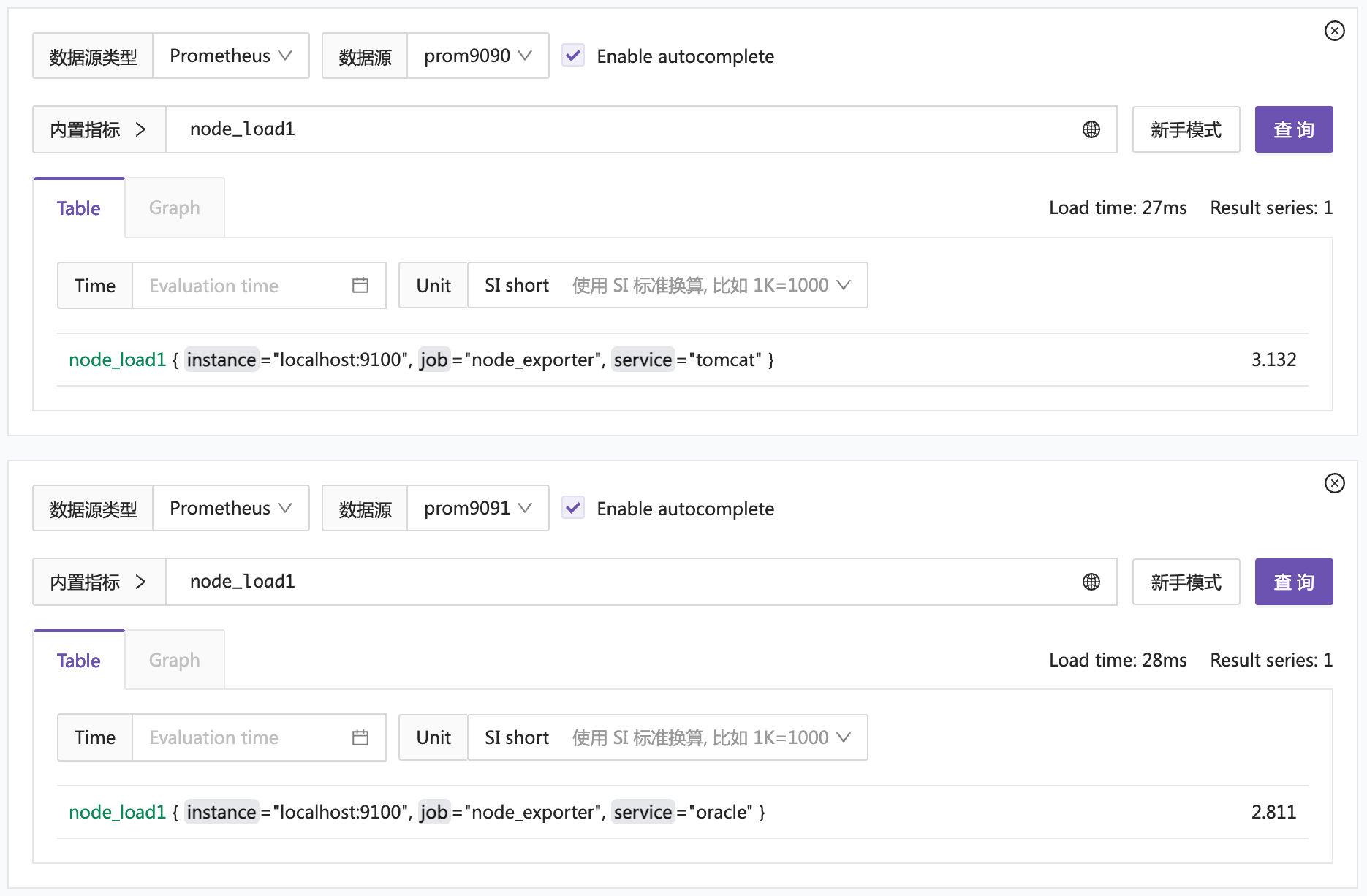
下面我们来看看如何聚合查询这两个数据源。
方案一:promxy
看这个名字就知道了,定位就是 prometheus 的 proxy,promxy 的 Github 地址是:https://github.com/jacksontj/promxy。按照 README 去安装就可以了,我的 promxy 的配置文件内容如下:
global:
evaluation_interval: 5s
promxy:
server_groups:
- static_configs:
- targets:
- localhost:9090
- static_configs:
- targets:
- localhost:9091然后,把 promxy 作为数据源配置到夜莺或者 Grafana 中,注意 promxy 默认监听的端口是 8082,之后,就可以查询这个数据源的数据做测试了。
先查个简单的:node_load1
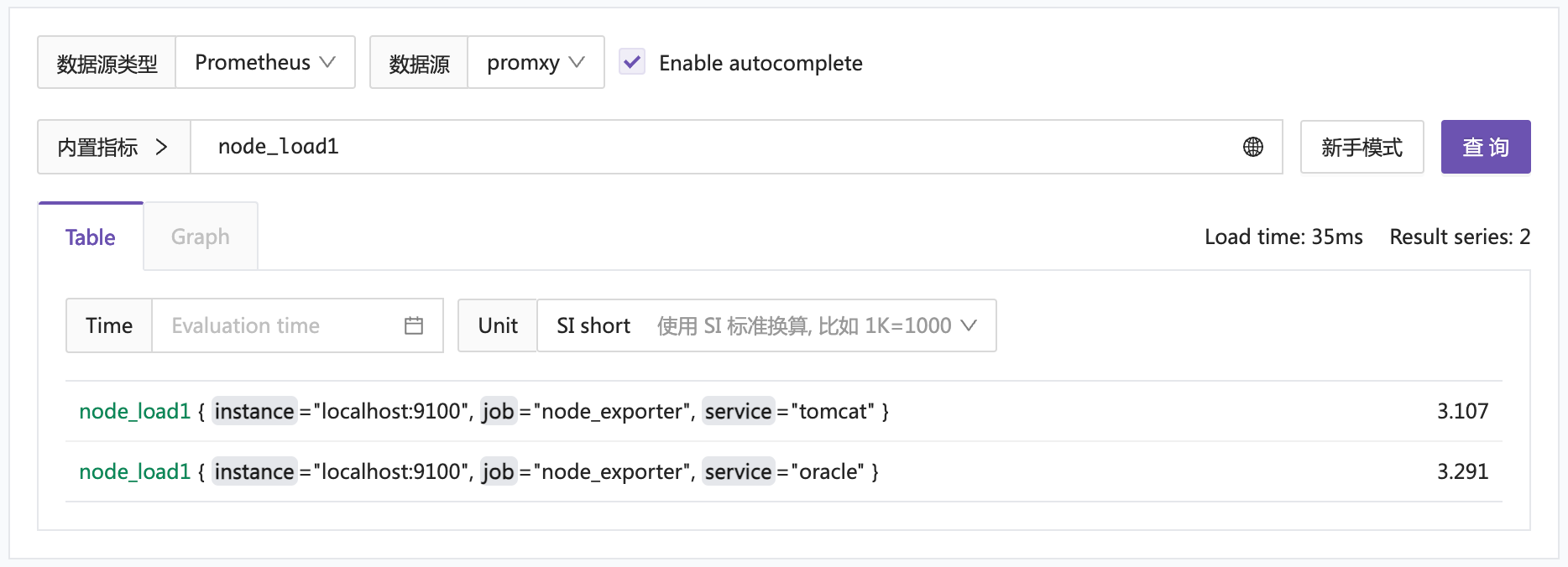
同时查到了两个时序库的数据,挺好的。然后做个聚合查询测试:
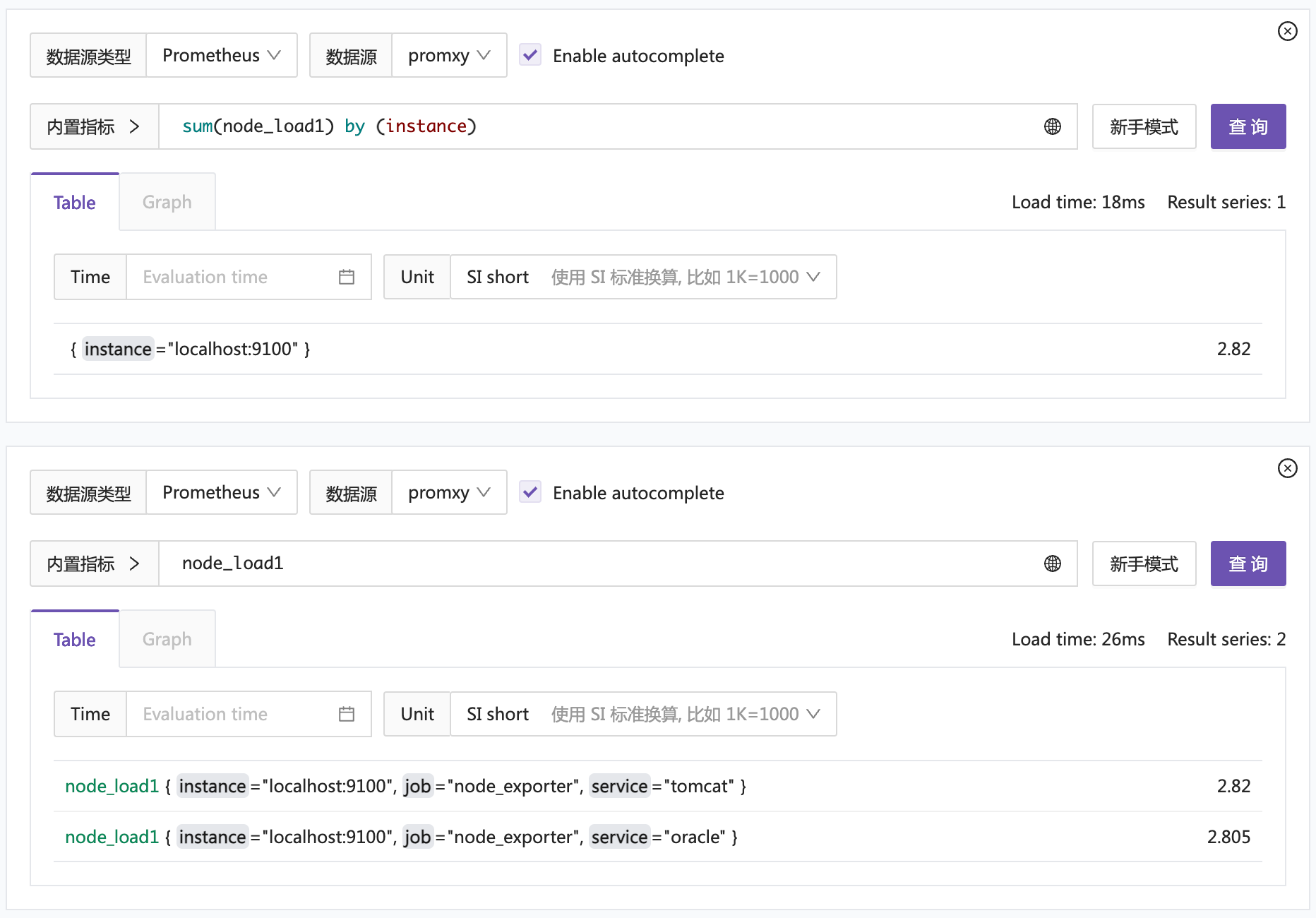
完犊子了,这个 sum 并未生效,看起来像是只查询了一个时序库的数据。这是个很基本的场景,不应该有 bug 才对,为啥会如此呢?我尝试两个解决办法:
- 在夜莺资深用户群扔了这个问题,资深群都是监控重度用户,可能有用过 promxy 的
- 下载了 promxy 的代码,准备从代码找找线索
资深群里确实有人用,有朋友提醒,promxy 中有个 server_group 的概念,是否应该为不同的 server_group 附加不同的标签呢?我直观感觉,应该是不需要的,因为这已经是多个 server_group 了,已经可以区分了才对,而且 TSDB 里已经有 service 标签做区分了。但是,我还是尝试了一下,修改 promxy 的配置文件如下:
global:
evaluation_interval: 5s
promxy:
server_groups:
- static_configs:
- targets:
- localhost:9090
labels:
region: a
- static_configs:
- targets:
- localhost:9091
labels:
region: b额外附加了 region 的标签。然后重启 promxy 再次查询:
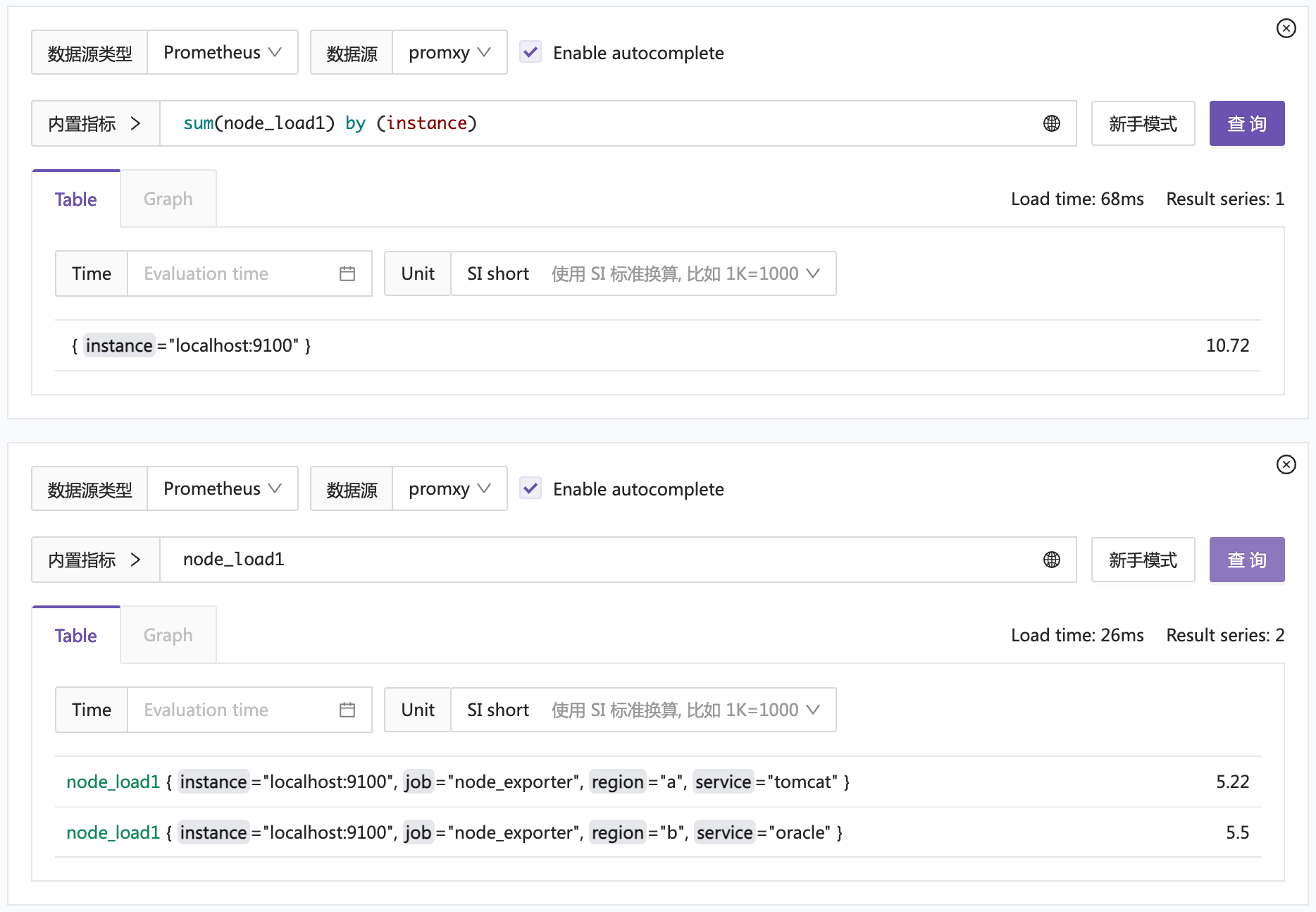
竟然就行了,哈哈。好吧,群里的朋友也反馈,之前他们没有踩到这个坑,是因为他们默认就给附加了标签。也不知道是 promxy 的 bug 还是有意为之。反正大家注意就好了。
方案二:Prometheus remote read
实际上,Prometheus 自身提供 remote read 能力,可以使用这个能力做聚合。我继续启动了一个 Prometheus 进程,监听在 9092 端口,配置文件 prometheus.9092.yml 如下:
global:
scrape_interval: 15s
evaluation_interval: 15s
remote_read:
- url: http://localhost:9090/api/v1/read
- url: http://localhost:9091/api/v1/read把 9090 和 9091 作为 remote read 后端配上即可。然后把 9092 这个 Prometheus 作为数据源配置到夜莺或者 Grafana 中,查询这个数据源的数据做测试。
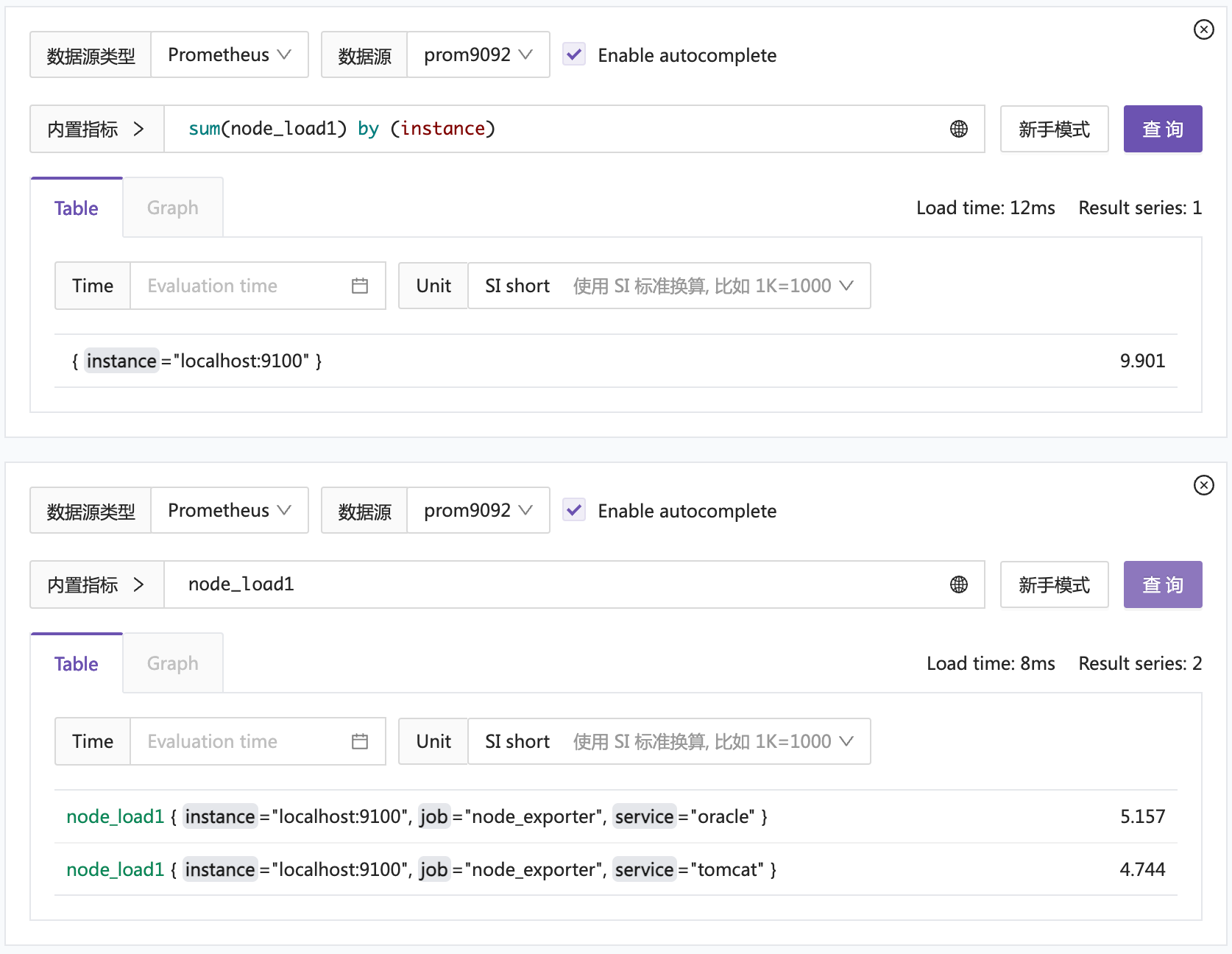
看起来是没问题的,不管是直接查询简单的 selector,还是聚合查询,都没问题。挺好的。
方案对比
首先,Prometheus remote read 方案,在编写 promql 的时候没有提示:

而 promxy 方案有提示:

这个原因是 remote read 方案只能查监控数据,没法查索引,自然也就没法有 suggestion 了。
其次,Prometheus read remote 只能查询那些支持 remote read 的后端,比如 VictoriaMetrics 就不支持 remote read,如果你的后端是 VictoriaMetrics,就只能使用 promxy 了。
如上,希望可以帮到你 :)
另外,本人创业两年了,我们公司主要是做监控、可观测性。我们希望通过合作努力,让中小公司具备行业顶尖的监控/可观测性能力,如果你有这方面的需求,欢迎联系我们:
Prometheus 聚合查询的两个方案的更多相关文章
- MongoDB的使用学习之(七)MongoDB的聚合查询(两种方式)附项目源码
先来张在路上…… 铛铛铛……项目源码下载地址:http://files.cnblogs.com/ontheroad_lee/MongoDBDemo.rar 此项目是用Maven创建的,没有使用Mave ...
- 3W字干货深入分析基于Micrometer和Prometheus实现度量和监控的方案
前提 最近线上的项目使用了spring-actuator做度量统计收集,使用Prometheus进行数据收集,Grafana进行数据展示,用于监控生成环境机器的性能指标和业务数据指标.一般,我们叫这样 ...
- 7.prometheus之查询API
一.格式概述 二.表达式查询 2.1 Instant queries(即时查询) 2.2 范围查询 三.查询元数据 3.1 通过标签匹配器找到度量指标列表 3.2 获取标签名 3.3 查询标签值 四. ...
- ElasticSearch(ES)使用Nested结构存储KV及聚合查询
自建博客地址:https://www.bytelife.net,欢迎访问! 本文为博客同步发表文章,为了更好的阅读体验,建议您移步至我的博客 本文作者: Jeffrey 本文链接: https://w ...
- mongodb高级聚合查询
在工作中会经常遇到一些mongodb的聚合操作,特此总结下.mongo存储的可以是复杂类型,比如数组.对象等mysql不善于处理的文档型结构,并且聚合的操作也比mysql复杂很多. 注:本文基于 mo ...
- ThinkPHP 数据库操作(四) : 聚合查询、时间查询、高级查询
聚合查询 在应用中我们经常会用到一些统计数据,例如当前所有(或者满足某些条件)的用户数.所有用户的最大积分.用户的平均成绩等等,ThinkPHP为这些统计操作提供了一系列的内置方法,包括: 用法示例: ...
- Django-model聚合查询与分组查询
Django-model聚合查询与分组查询 聚合函数包含:SUM AVG MIN MAX COUNT 聚合函数可以单独使用,不一定要和分组配合使用:不过聚合函数一般和group by 搭配使用 agg ...
- python全栈开发day68-ORM操作:一般操作、ForeignKey操作、ManyToManyField、聚合查询和分组查询、F查询和Q查询等
ORM操作 https://www.cnblogs.com/maple-shaw/articles/9403501.html 一.一般操作 1. 必知必会13条 <1> all(): 查询 ...
- django聚合查询
聚合¶ Django 数据库抽象API 描述了使用Django 查询来增删查改单个对象的方法.然而,有时候你需要获取的值需要根据一组对象聚合后才能得到.这份指南描述通过Django 查询来生成和返回聚 ...
- python 全栈开发,Day74(基于双下划线的跨表查询,聚合查询,分组查询,F查询,Q查询)
昨日内容回顾 # 一对多的添加方式1(推荐) # book=Book.objects.create(title="水浒传",price=100,pub_date="164 ...
随机推荐
- 力扣237(java&python)-删除链表中的节点(中等)
题目: 有一个单链表的 head,我们想删除它其中的一个节点 node. 给你一个需要删除的节点 node .你将 无法访问 第一个节点 head. 链表的所有值都是 唯一的,并且保证给定的节点 n ...
- HarmonyOS NEXT 实战开发—Grid和List内拖拽交换子组件位置
介绍 本示例分别通过onItemDrop()和onDrop()回调,实现子组件在Grid和List中的子组件位置交换. 效果图预览 使用说明: 拖拽Grid中子组件,到目标Grid子组件位置,进行两者 ...
- 重磅发布|新一代云原生数据仓库AnalyticDB「SQL智能诊断」功能详解
简介: AnalyticDB For MySQL为用户提供了高效.实时.功能丰富并且智能化的「SQL智能诊断」和「SQL智能调优」功能,提供用户SQL性能调优的思路.方向和具体的方法,降低用户使用成 ...
- [ML] 详解 ChatGLM-webui 的启动使用与 ChatGLM-6B 常见问题
1. ChatGLM-webui 总共支持以下几个命令选项: 2. 以 windows 为例,在 PowerShell 里运行命令: # 安装依赖 pip install torch==1.13. ...
- dotnet core 不自动从 https 到 http 的 302 重定向
本文记录一个已知问题,或者准确来说是设计如此的行为,在 dotnet core 下,无论是 dotnet core 3.1 还是 dotnet 5 或 dotnet 6 或 dotnet 7 等,如果 ...
- dotnet 使用 NamedPipeClientStream 连接一个不存在管道服务名将不断空跑 CPU 资源
本文记录一个开发和代码审查过程中,需要关注的细节.在 dotnet 里,在 .NET 6 和以下版本,包括 .NET Framework 版本,使用 NamedPipeClientStream 进行连 ...
- dotnet C# 序列化 XML 时进行自动格式化
默认的序列化对象为 XML 字符串时,是没有进行格式化的,也就是所有的内容都在相同的一行.本文告诉大家方法,在序列化对象时,转换的 XML 是格式化的.或者说拿到 XML 字符串,对这个 XML 字符 ...
- Visual Studio 2019 自带混淆工具DotFuscator不需要去网络下载
http://t.zoukankan.com/daizhipeng-p-13492298.html 大家是否还在困扰发布的项目dll容易被人反编译呢,VS2019默认是没有安装DotFuscator的 ...
- xtrabackup备份恢复
tar -xzvf percona-xtrabackup-2.1.9-744-Linux-x86_64.tar.gz cd percona-xtrabackup-2.1.9-Linux-x86_64/ ...
- linux-centos7.6-gpt-uefi安装
目录 linux-centos7.6-gpt-uefi安装 一.需要 二.环境 三.vm新建虚拟机系统环境 四.开始安装 linux-centos7.6-gpt-uefi安装 一.需要 安装的系统适用 ...