Google出品的NotebookLM 人工智能笔记本,一款基于RAG的personalized AI产品
Google推出了实验性的NotebookLM产品,一款基于RAG的个性化AI助手产品,基于用户提供的可信信息,通过RAG,帮助用户洞察和学习参考内容,然后借助AI整理笔记,转换为用户最终需要的大纲、博客、商业计划书等最终目的。
在之前的博客中,当时提到:"AI搜索产品的边界绝不止步于搜索,往上往下,往上如何更懂用户真实诉求,往下通过Agents组合解决复杂的问题,给用户提供端到端的个性化解决方案"。google的这款NotebookLM 也比较契合这样的思路,基于用户提供的信息,结合搜索技术,提供个性化的笔记AI助手,但整体比较克制,重点强调可信,也就是遵循用户提供的信息,并未结合google的强项通用搜索。
下面步入正题,我们来介绍NotebookLM的功能,并做一个尝试。
官方介绍
官方介绍是,NotebookLM 是一个基于用户信任信息(也就是用户自己提供的文档)的个性化(私人的)人工智能助手。
目前,NotebookLM 仅在US提供服务,体验需要魔法
功能特点
- 虚拟研究助手: 用户可以上传与项目相关的文档,NotebookLM 会立即成为这些信息的专家。说人话就是,NotebookLM会解析文档,拆分为chunk,这就理解了文档内容。
- 帮助用户洞察信息 (Go from information to insight) NotebookLM 提供了一个强大的新界面,使用户能够轻松地从阅读到提问再到写作,AI 助手会在每一步提供帮助。 上传文档后,用户可以在提问框进行提问,NotebookLM通过
RAG能力进行回答,并能查看参考文档内容。
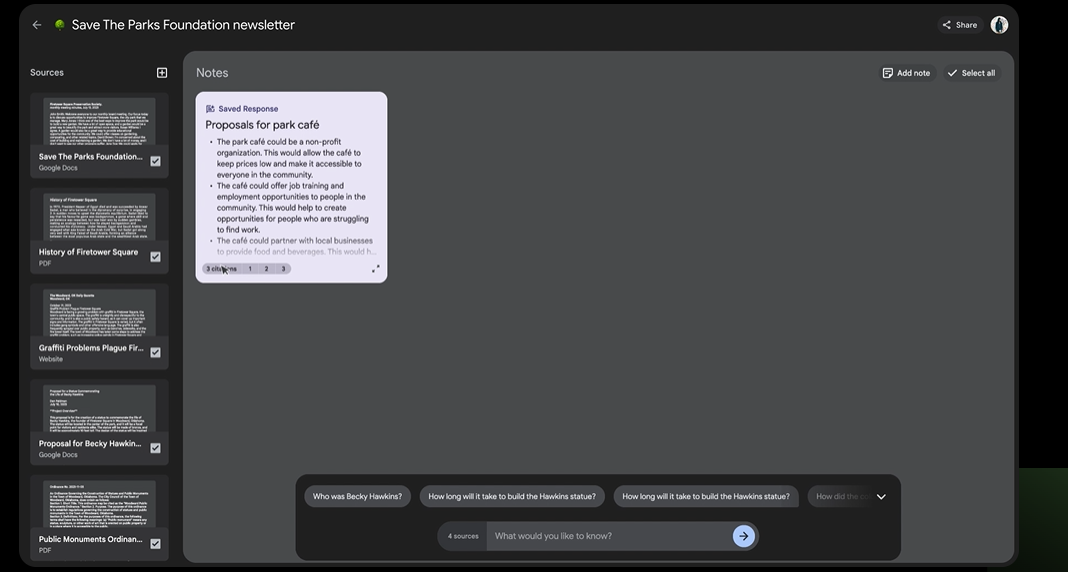
如果机器回复的内容获得用户的认可,用户可以将回复内容保存到notes,所以设想下协作模式,就是用户先上传要学习的参考文档,然后就自己关注的点(其实就是整理大纲)进行提问,最后将这些回复内容都保存到笔记。
当你所有关心的问题都提问后,你就获得了许多有用有价值的notes片段。基于这些片段,就可以:
- 快速起草内容,选中整理的笔记(就是上面保存的),NotebookLM 可以帮助用户快速转化为大纲、博客文章、商业计划等。

隐私说明
google强调用户的个人数据不会被用于训练 NotebookLM,因此任何私人或敏感信息都将保持私密,除非用户选择与合作者共享资源。
行业评价
- Tiago Forte(《Building A Second Brain》一书的作者)评价 NotebookLM 为“为创意工作利用 AI 而创建的最佳软件”。
NotebookLM 体验
看完了官方介绍,我们来实战上手。
新建笔记本
首先新建一个笔记本,修改名称为"人工智能与搜索引擎"
上传参考文档
这里我们上传王树森的《搜索引擎技术》pdf作为参考文档。
可以直接上传PDF,文本文件,也可以从google云盘选择,或者直接复制文本。
洞察理解文档
现在开始提问,我们要了解搜索引擎与人工智能,我们开始提问:
Q: 搜索引擎的原理是什么
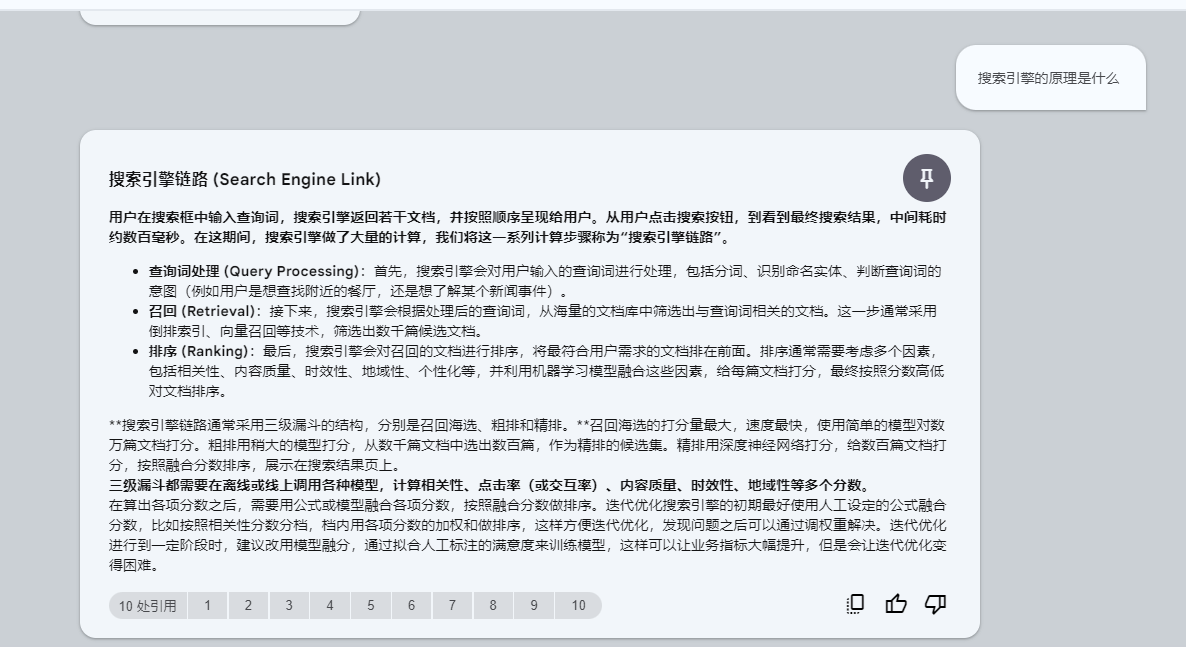
可以看到,NotebookLM比较好的回复了搜索引擎链路,包含三级漏斗等信息。
点击引用可以查看原文。
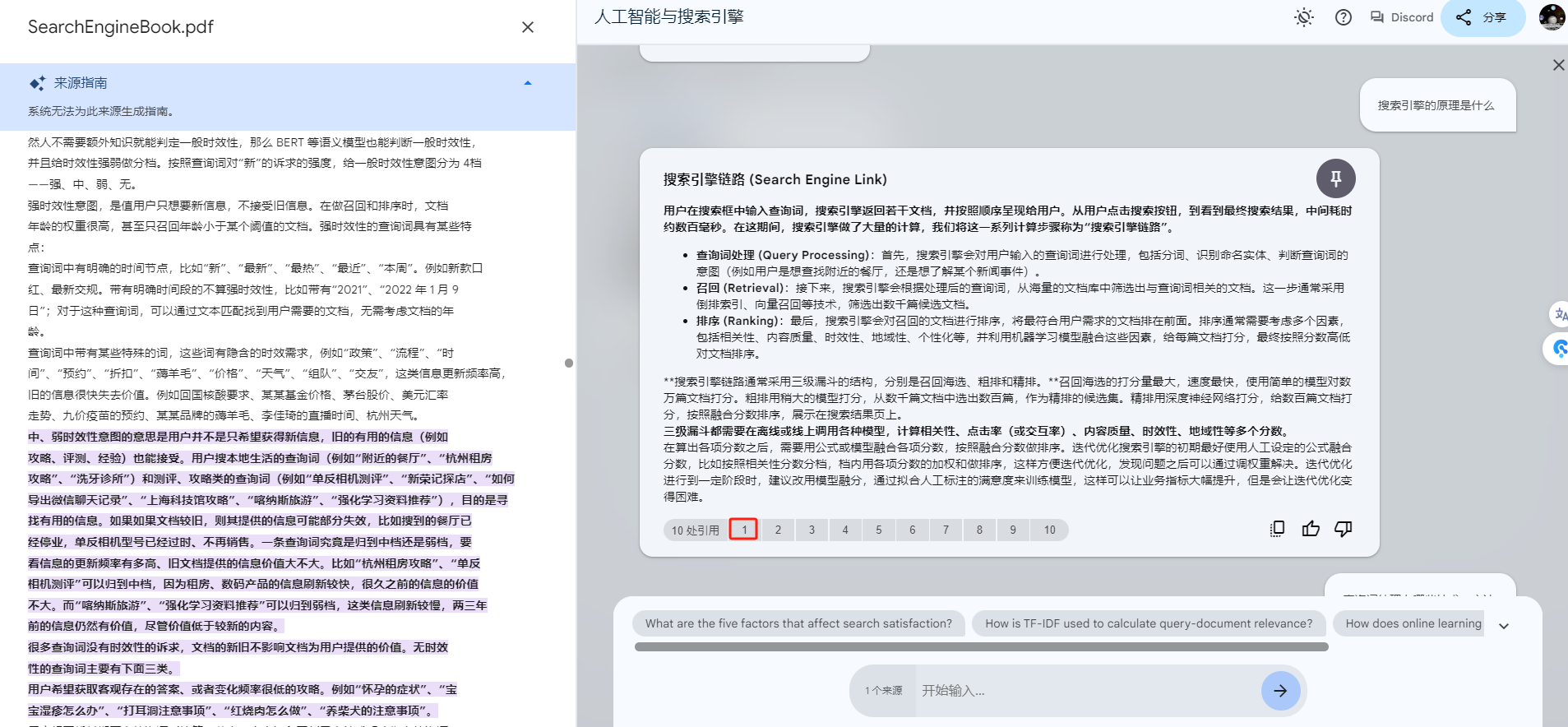
现在我们了解了基本的链路,那么我们接着看每一块有什么样的技术。
Q: 搜索引擎中Query Processing具体处理方法
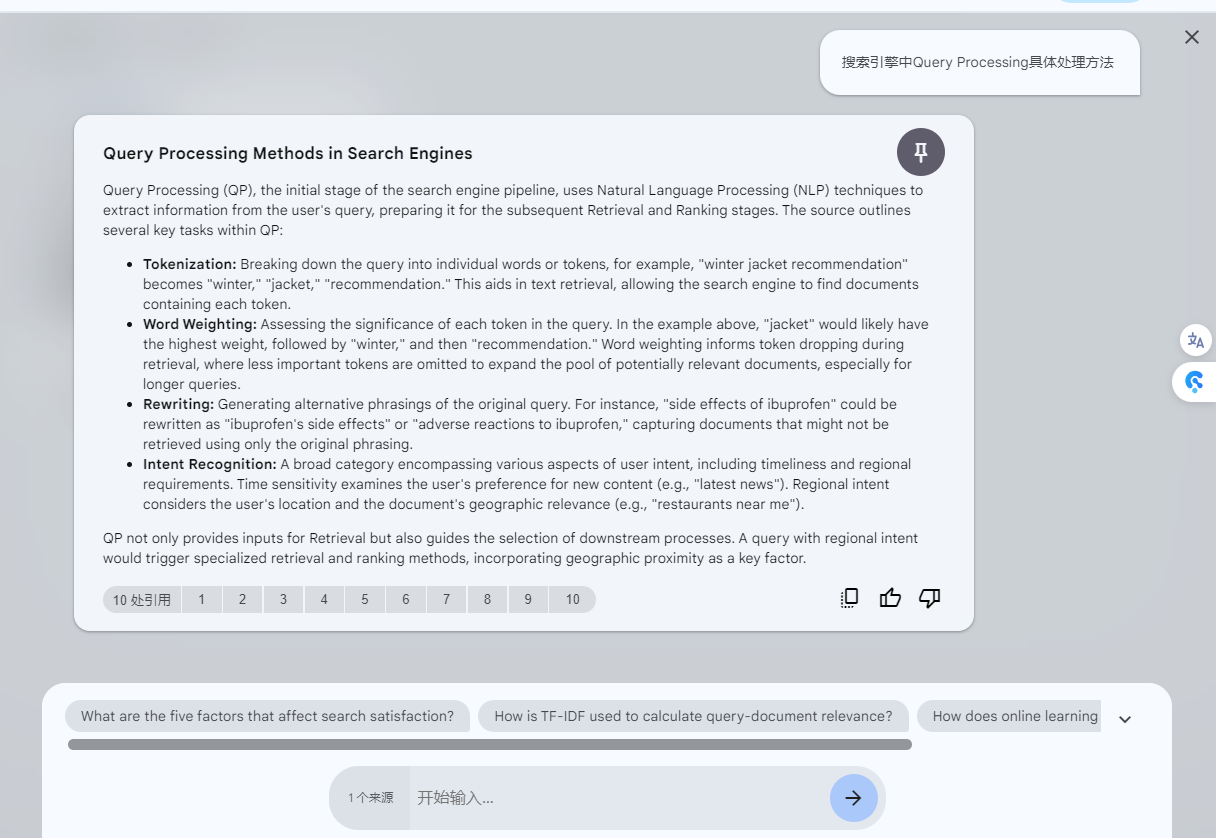
回复不稳定,用英文就行了回复,不过内容还是靠谱的。
接着,我们来问召回的技术方案。
Q: 搜索引擎的召回 (Retrieval)部分,通常用有哪些召回方案,用到哪些人工智能技术,请用中文回答
这里试下,加上用中文回答的指令。
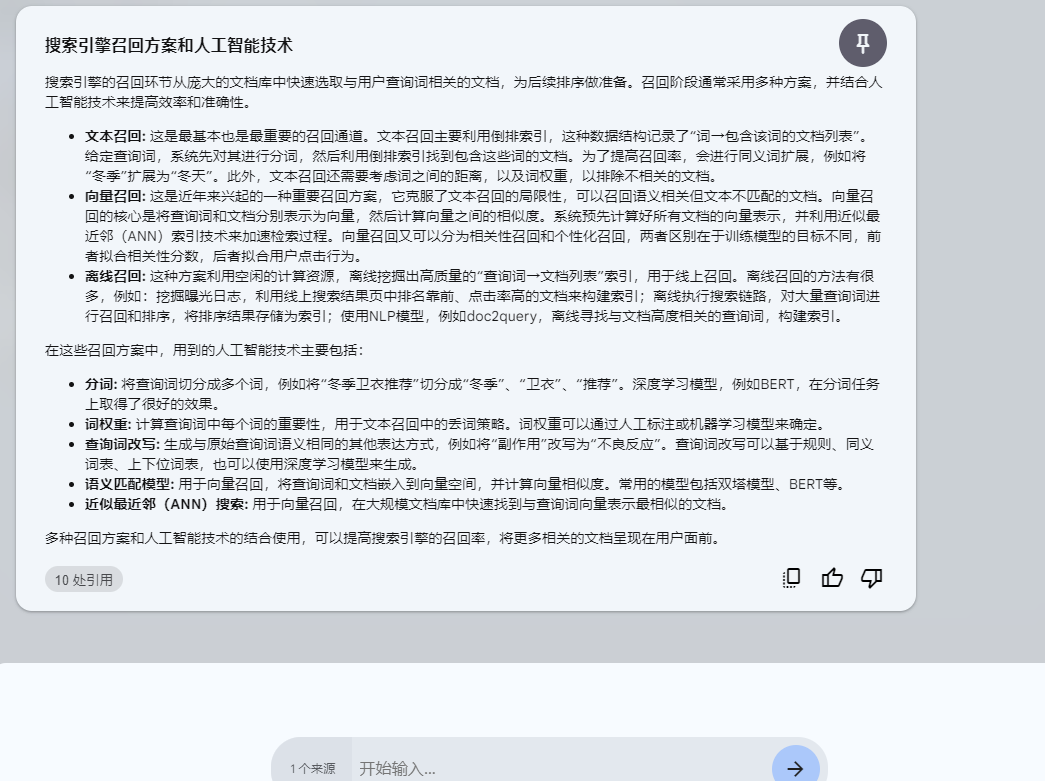
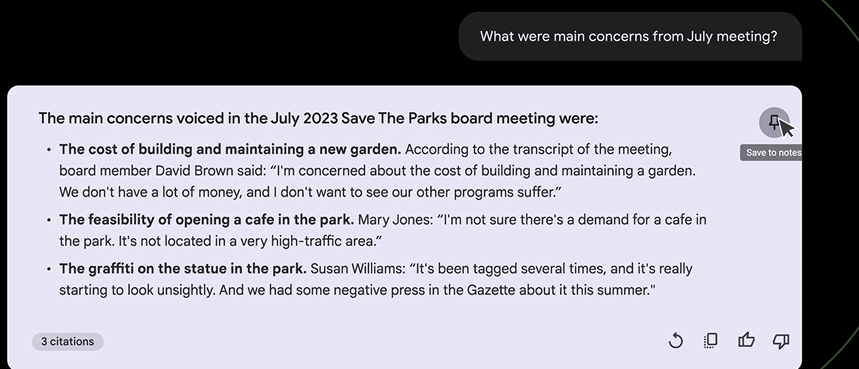
回答比较好,提出了三种召回方案,以及用到的技术,我们保存起来,继续提问。
Q: 详细介绍下搜索引擎排序的三级漏斗,采用的模型方案,用中文回复
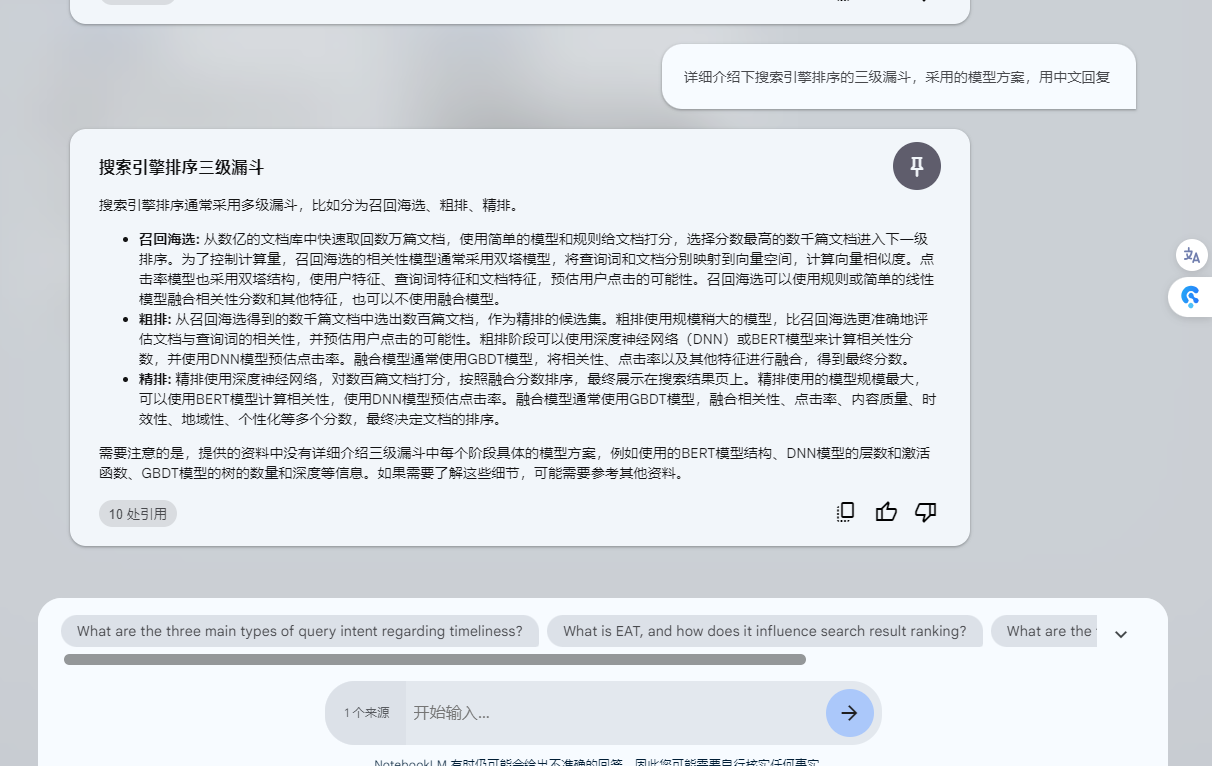
三级漏斗介绍了,但是模型方案回答一般般,先保存起来,
快速起草内容
提问演示告一段落,我们开始将上述提问后保存的notes整理。注意这里的notes可以自己添加,随时记录自己的想法。
通过上面的提问,我们保存了4个notes,我们选中:
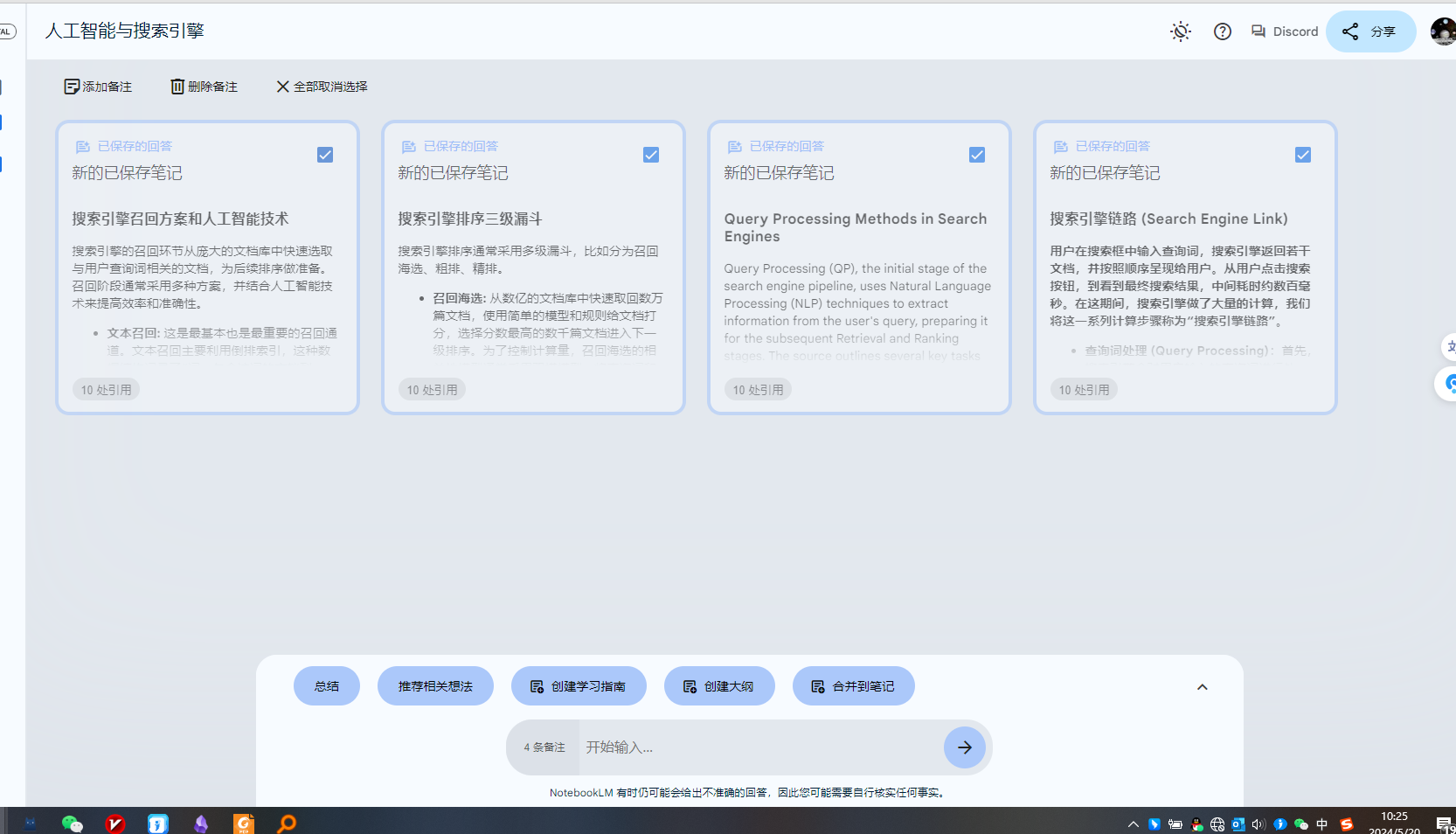
可以看到,系统给出了总结 、创建大纲、合并到笔记等功能,我们试下创建学习指南:
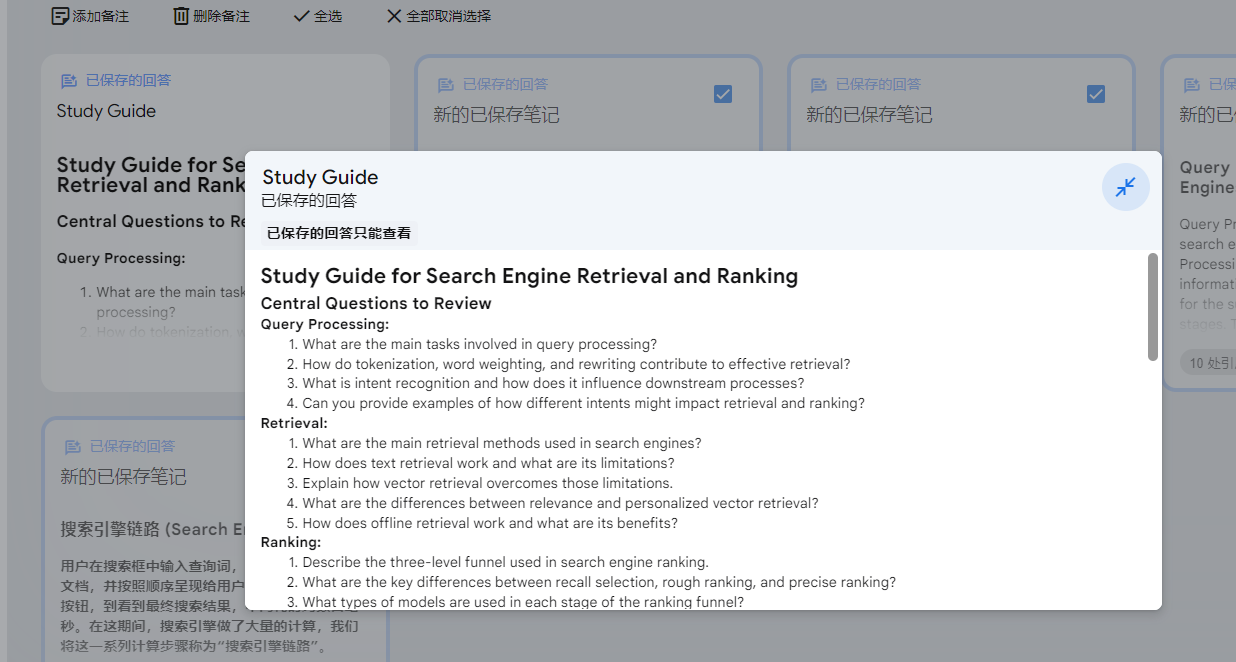
系统生成了一个学习指南,可以看到包含QP、召回、排序等。
我们试下其他的,还是选中这四个:
Q: 基于这些内容创建一篇博客,用markdown输出,用中文回复
下面看成品
## 搜索引擎的工作原理
用户在搜索框中输入查询词,搜索引擎返回若干文档,并按照顺序呈现给用户。从用户点击搜索按钮,到看到最终搜索结果,中间耗时约数百毫秒。在这期间,搜索引擎做了大量的计算,我们将这一系列计算步骤称为“搜索引擎链路”。搜索引擎链路通常采用三级漏斗的结构,分别是召回海选、粗排和精排。
**搜索引擎链路主要包含三个核心步骤:**
1. **查询词处理(Query Processing)**
- **分词:**将查询词切分成多个词,例如将“冬季卫衣推荐”切分成“冬季”、“卫衣”、“推荐”。深度学习模型,例如BERT,在分词任务上取得了很好的效果。
- **词权重:**计算查询词中每个词的重要性,用于文本召回中的丢词策略。词权重可以通过人工标注或机器学习模型来确定。
- **查询词改写:**生成与原始查询词语义相同的其他表达方式,例如将“副作用”改写为“不良反应”。查询词改写可以基于规则、同义词表、上下位词表,也可以使用深度学习模型来生成。
- **意图识别:**判断用户查询的意图,例如用户是想查找附近的餐厅,还是想了解某个新闻事件。这包括时间敏感性,检查用户是否偏好新内容(例如“最新消息”),以及区域意图,考虑用户的位置和文档的地理相关性(例如“我附近的餐厅”)。
2. **召回(Retrieval)**
- **文本召回:** 这是最基本也是最重要的召回通道。文本召回主要利用倒排索引,这种数据结构记录了“词→包含该词的文档列表”。给定查询词,系统先对其进行分词,然后利用倒排索引找到包含这些词的文档。为了提高召回率,会进行同义词扩展,例如将“冬季”扩展为“冬天”。此外,文本召回还需要考虑词之间的距离,以及词权重,以排除不相关的文档。
- **向量召回:** 这是近年来兴起的一种重要召回方案,它克服了文本召回的局限性,可以召回语义相关但文本不匹配的文档。向量召回的核心是将查询词和文档分别表示为向量,然后计算向量之间的相似度。系统预先计算好所有文档的向量表示,并利用近似最近邻(ANN)索引技术来加速检索过程。向量召回又可以分为相关性召回和个性化召回,两者区别在于训练模型的目标不同,前者拟合相关性分数,后者拟合用户点击行为。
- **离线召回:** 这种方案利用空闲的计算资源,离线挖掘出高质量的“查询词→文档列表”索引,用于线上召回。离线召回的方法有很多,例如:挖掘曝光日志,利用线上搜索结果页中排名靠前、点击率高的文档来构建索引;离线执行搜索链路,对大量查询词进行召回和排序,将排序结果存储为索引;使用NLP模型,例如doc2query,离线寻找与文档高度相关的查询词,构建索引。
3. **排序 (Ranking)**
- **召回海选:** 从数亿的文档库中快速取回数万篇文档,使用简单的模型和规则给文档打分,选择分数最高的数千篇文档进入下一级排序。为了控制计算量,召回海选的相关性模型通常采用双塔模型,将查询词和文档分别映射到向量空间,计算向量相似度。点击率模型也采用双塔结构,使用户特征、查询词特征和文档特征,预估用户点击的可能性。召回海选可以使用规则或简单的线性模型融合相关性分数和其他特征,也可以不使用融合模型。
- **粗排:** 从召回海选得到的数千篇文档中选出数百篇文档,作为精排的候选集。粗排使用规模稍大的模型,比召回海选更准确地评估文档与查询词的相关性,并预估用户点击的可能性。粗排阶段可以使用深度神经网络(DNN)或BERT模型来计算相关性分数,并使用DNN模型预估点击率。融合模型通常使用GBDT模型,将相关性、点击率以及其他特征进行融合,得到最终分数。
- **精排:** 精排使用深度神经网络,对数百篇文档打分,按照融合分数排序,最终展示在搜索结果页上。精排使用的模型规模最大,可以使用BERT模型计算相关性,使用DNN模型预估点击率。融合模型通常使用GBDT模型,融合相关性、点击率、内容质量、时效性、地域性、个性化等多个分数,最终决定文档的排序。
**人工智能技术在搜索引擎召回方案中的应用:**
- **分词:** 将查询词切分成多个词,例如将“冬季卫衣推荐”切分成“冬季”、“卫衣”、“推荐”。深度学习模型,例如BERT,在分词任务上取得了很好的效果。
- **词权重:** 计算查询词中每个词的重要性,用于文本召回中的丢词策略。词权重可以通过人工标注或机器学习模型来确定。
- **查询词改写:** 生成与原始查询词语义相同的其他表达方式,例如将“副作用”改写为“不良反应”。查询词改写可以基于规则、同义词表、上下位词表,也可以使用深度学习模型来生成。
- **语义匹配模型:** 用于向量召回,将查询词和文档嵌入到向量空间,并计算向量相似度。常用的模型包括双塔模型、BERT等。
- **近似最近邻(ANN)搜索:** 用于向量召回,在大规模文档库中快速找到与查询词向量表示最相似的文档。
多种召回方案和人工智能技术的结合使用,可以提高搜索引擎的召回率,将更多相关的文档呈现在用户面前。
需要注意的是,提供的资料中没有详细介绍三级漏斗中每个阶段具体的模型方案,例如使用的BERT模型结构、DNN模型的层数和激活函数、GBDT模型的树的数量和深度等信息。如果需要了解这些细节,可能需要参考其他资料。成品:
NotebookLM 评价
优点:
- 良好的产品设计方案,可以碎片化的记录零星的思考,通过RAG为零星的思考整理提炼内容,最后将零星的思考内容汇总输出内容,帮助用户实现端到端的应用
可优化的方向:
- 通过查看chunk,还是按照文本长度做的分片,未做语义结构化分片
- 支持网页、笔记导入
- 增加网页检索开关,可以制定检索范围、比如维基百科
- 语言保持
- 生成的内容尚不支持修改
- 引入更多的多模能力,输入端支持多模输入,输出支持个性化的多模输出
总结
NotebookLM 给了我们一个很好的LLM时代的personalized AI 产品范例,一个很好的RAG落地产品。很多时候,能力还是哪个能力,通过交互的创新,就能打造出"The best software ever created for leveraging AI in your creative work"。
Google出品的NotebookLM 人工智能笔记本,一款基于RAG的personalized AI产品的更多相关文章
- Google出品的自动Web安全扫描程序 Skipfish 下载及安装使用方法
Skipfish是由google出品的一款自动化的网络安全扫描工具,该工具可以安装在linux.freebsd.MacOS X系统和windows(cygwin). 谷歌工程师Michal Zalew ...
- Android:Google出品的序列化神器Protocol Buffer使用攻略
习惯用 Json.XML 数据存储格式的你们,相信大多都没听过Protocol Buffer Protocol Buffer 其实 是 Google出品的一种轻量 & 高效的结构化数据存储格式 ...
- 快来看看Google出品的Protocol Buffer,别只会用Json和XML了
前言 习惯用 Json.XML 数据存储格式的你们,相信大多都没听过Protocol Buffer Protocol Buffer 其实 是 Google出品的一种轻量 & 高效的结构化数据存 ...
- 快来看看Google出品的Protocol Buffer,别仅仅会用Json和XML了
前言 习惯用 Json.XML 数据存储格式的你们,相信大多都没听过Protocol Buffer Protocol Buffer 事实上 是 Google出品的一种轻量 & 高效的结构化数据 ...
- QQ 腾讯QQ(简称“QQ”)是腾讯公司开发的一款基于Internet的即时通信(IM)软件
QQ 编辑 腾讯QQ(简称“QQ”)是腾讯公司开发的一款基于Internet的即时通信(IM)软件.腾讯QQ支持在线聊天.视频通话.点对点断点续传文件.共享文件.网络硬盘.自定义面板.QQ邮箱等多种功 ...
- 一款基于css3的动画按钮
之前为大家分享了 推荐10款纯css3实现的实用按钮.今天给大家带来一款基于css3的动画按钮.实现的效果图如下: 在线预览 源码下载 实现的代码. html代码: <div class=& ...
- 一款基于HTML5的高性能WEBGIS介绍
远景地理信息系统(RemoteGIS)是一款基于HTML5的GIS平台软件,它使用Javascript开发,旨在解决当前WEBGIS矢量数据在数据量和刷新性能上的瓶颈,并利用WEB程序的跨平台特性,打 ...
- 30款基于 jQuery & CSS3 的加载动画和进度条插件
我们所生活每一天看到的新技术或新设计潮流的兴起,Web 开发正处在上升的时代.HTML5 & CSS3 技术的发展让 Web 端可以实现的功能越来越强大. 加载动画和进度条使网站更具吸引力.该 ...
- 一款基于Netty开发的WebSocket服务器
代码地址如下:http://www.demodashi.com/demo/13577.html 一款基于Netty开发的WebSocket服务器 这是一款基于Netty框架开发的服务端,通信协议为We ...
- Processon 一款基于HTML5的在线作图工具
CSDN的蒋涛不久前在微博上评价说ProcessOn是web版的visio,出于好奇私下对ProcessOn进行了一番研究.最后发现无论是在用户体验上,还是在技术上,ProcessOn都比微软的Vis ...
随机推荐
- 本周四晚19:00知识赋能第3期直播丨OpenHarmony智能家居项目之控制面板功能实现
OpenAtom OpenHarmony(以下简称"OpenHarmony")开源开发者成长计划项目自 2021 年 10 月 24 日上线以来,在开发者中引发高度关注. 成长计划 ...
- HarmonyOS—使用Web组件加载页面
页面加载是Web组件的基本功能.根据页面加载数据来源可以分为三种常用场景,包括加载网络页面.加载本地页面.加载HTML格式的富文本数据. 页面加载过程中,若涉及网络资源获取,需要配置ohos.pe ...
- HDC 2022重磅首发《鸿蒙生态应用开发白皮书》,附全文
原文:https://mp.weixin.qq.com/s/sEicsV_82770nAlcSCzwIw,点击链接查看更多技术内容. 11月4-6日,华为开发者大会2022(HDC)在东莞松山湖举 ...
- How to install Django-Install Python Django | Django 安装指南【官方版】
How to install Django¶ This document will get you up and running with Django. Install Python--Linux ...
- 树莓派和esp8266在局域网下使用UDP通信,esp8266采集adc数据传递给树莓派,树莓派在web上显示结果
树莓派和esp8266需要在同一局域网下 esp8266使用arduino开发: 接入一个电容土壤湿度传感器,采集湿度需要使用adc #include <ESP8266WiFi.h> #i ...
- 嘉楠k210 多线程 点亮流水灯
from Maix import GPIO from fpioa_manager import fm import _thread import time fm.register(24, fm.fpi ...
- 第七課-Channel Study For HTTP Listener & Web Service Sender Intercommunicates Response Handler
示例说明: 系统A发送XML格式患者信息到Mirth的Source端HTTP Listener,完成患者信息入库逻辑:然后Mirth的Destinations端Web Service Sender调用 ...
- OpenYurt 如何 “0 侵入” 攻破云边融合难点
简介: 随着 5G.IoT.直播.CDN 等行业和业务的发展,越来越多的算力和业务开始下沉到距离数据源或者终端用户更近的位置,以期获得很好的响应时间和成本,这是一种明显区别于传统中心模式的计算方式-- ...
- 5分钟搞定AlertManager接入短信、语音等10+种通知渠道
简介: Alert Manager是开源监控系统Prometheus中用于处理告警信息的服务,通过将日志服务开放告警配置为Alert Manager中的一个Receiver,可以将Alert Man ...
- [FAQ] 腾讯企业邮箱成员的名字如何多次更改 ?
可以通过给成员的邮箱增加别名,先点击成员信息最右侧的 "编辑",在编辑页面顶部的 "更多操作" 这个按钮中,比较隐蔽. Refer:腾讯邮箱成员名字更改 Lin ...