2023-07-20:假设一共有M个车库,编号1~M,时间点从早到晚是从1~T, 一共有N个记录,每一条记录如下{a, b, c}, 表示一辆车在b时间点进入a车库,在c时间点从a车库出去, 一共有K
2023-07-20:假设一共有M个车库,编号1 ~ M,时间点从早到晚是从1 ~ T,
一共有N个记录,每一条记录如下{a, b, c},
表示一辆车在b时间点进入a车库,在c时间点从a车库出去,
一共有K个查询,每个查询只有一个数字X,表示请问在X时刻,
有多少个车库包含车的数量>=3,请返回K个查询的答案。
1 <= M, N, K <= 10^5,
1 <= T <= 10^9。
大厂笔试面经帖子。
答案2023-07-20:
算法1(getAns1)的大体过程如下:
1.遍历所有记录,找到最大时间点 maxT。
2.将每个车库和每个时间点的数量初始化为0。
3.遍历记录,对于每条记录,获取车库编号 s、进入时间 l、离开时间 r,将该时间段内车库 s 的数量加1。
4.遍历查询,对于每个查询时间点 t,统计数量大于等于3的车库数目。
5.返回所有查询的结果。
算法2(getAns2)的大体过程如下:
1.遍历所有记录和查询,将时间点按照从小到大的顺序存储到数组 times 中,并记录每个时间点的排名。
2.对于每条记录,更新记录的起始时间和结束时间为对应的排名。
3.根据车库编号对记录进行排序。
4.创建一个线段树数据结构,并初始化。
5.遍历记录,将统计数量大于等于3的时间段加入到线段树中。
6.遍历查询,使用线段树查询对应时间点的结果。
7.返回所有查询的结果。
两种算法实现的是相同的功能,但是基于不同的数据结构和算法思路。算法1使用二维数组 stores 来统计每个车库和时间点的数量,而算法2使用线段树来高效地统计数量大于等于3的时间段。
算法1的总时间复杂度是O(n + m),总空间复杂度是O(maxT * K + m)。
算法2的总时间复杂度是O((n + m) log(n + m) + n log n + maxT * log(maxT) + (n + m) log(maxT)),总空间复杂度是O(n + m + maxT)。
go完整代码如下:
package main
import (
"fmt"
"math/rand"
"sort"
"time"
)
func getMax(a, b int) int {
if a > b {
return a
}
return b
}
func getAns1(m int, records [][]int, queries []int) []int {
maxT := 0
for _, r := range records {
maxT = getMax(maxT, getMax(r[1], r[2]))
}
for _, t := range queries {
maxT = getMax(maxT, t)
}
stores := make([][]int, m+1)
for i := range stores {
stores[i] = make([]int, maxT+1)
}
for _, record := range records {
s := record[0]
l := record[1]
r := record[2] - 1
for i := l; i <= r; i++ {
stores[s][i]++
}
}
k := len(queries)
ans := make([]int, k)
for i := 0; i < k; i++ {
curAns := 0
for j := 1; j <= m; j++ {
if stores[j][queries[i]] >= 3 {
curAns++
}
}
ans[i] = curAns
}
return ans
}
func getAns2(m int, records [][]int, queries []int) []int {
n := len(records)
k := len(queries)
tn := (n << 1) + k
times := make([]int, tn+1)
ti := 1
for _, record := range records {
times[ti] = record[1]
ti++
times[ti] = record[2] - 1
ti++
}
for _, query := range queries {
times[ti] = query
ti++
}
sort.Ints(times)
for _, record := range records {
record[1] = rank(times, record[1])
record[2] = rank(times, record[2]-1)
}
for i := 0; i < k; i++ {
queries[i] = rank(times, queries[i])
}
sort.Slice(records, func(i, j int) bool {
return records[i][0] < records[j][0]
})
st := NewSegmentTree(tn)
for l := 0; l < n; {
r := l
for r < n && records[l][0] == records[r][0] {
r++
}
countRange(records, l, r-1, st)
l = r
}
ans := make([]int, k)
for i := 0; i < k; i++ {
ans[i] = st.query(queries[i])
}
return ans
}
// type Record struct {
// Garage int
// Start int
// End int
// }
type SegmentTree struct {
Tn int
Sum []int
Lazy []int
}
func NewSegmentTree(n int) *SegmentTree {
tn := n
sum := make([]int, (tn+1)<<2)
lazy := make([]int, (tn+1)<<2)
return &SegmentTree{Tn: tn, Sum: sum, Lazy: lazy}
}
func (st *SegmentTree) pushUp(rt int) {
st.Sum[rt] = st.Sum[rt<<1] + st.Sum[rt<<1|1]
}
func (st *SegmentTree) pushDown(rt, ln, rn int) {
if st.Lazy[rt] != 0 {
st.Lazy[rt<<1] += st.Lazy[rt]
st.Sum[rt<<1] += st.Lazy[rt] * ln
st.Lazy[rt<<1|1] += st.Lazy[rt]
st.Sum[rt<<1|1] += st.Lazy[rt] * rn
st.Lazy[rt] = 0
}
}
func (st *SegmentTree) add(l, r int) {
st.add0(l, r, 1, st.Tn, 1)
}
func (st *SegmentTree) add0(L, R, l, r, rt int) {
if L <= l && r <= R {
st.Sum[rt] += r - l + 1
st.Lazy[rt] += 1
return
}
mid := (l + r) >> 1
st.pushDown(rt, mid-l+1, r-mid)
if L <= mid {
st.add0(L, R, l, mid, rt<<1)
}
if R > mid {
st.add0(L, R, mid+1, r, rt<<1|1)
}
st.pushUp(rt)
}
func (st *SegmentTree) query(index int) int {
return st.query0(index, 1, st.Tn, 1)
}
func (st *SegmentTree) query0(index, l, r, rt int) int {
if l == r {
return st.Sum[rt]
}
m := (l + r) >> 1
st.pushDown(rt, m-l+1, r-m)
if index <= m {
return st.query0(index, l, m, rt<<1)
} else {
return st.query0(index, m+1, r, rt<<1|1)
}
}
func rank(sorted []int, v int) int {
l := 1
r := len(sorted)
ans := 0
m := 0
for l <= r {
m = (l + r) / 2
// fmt.Println(len(sorted), l, r, m, v)
if sorted[m] >= v {
ans = m
r = m - 1
} else {
l = m + 1
}
}
return ans
}
func countRange(records [][]int, l, r int, st *SegmentTree) {
n := r - l + 1
help := make([][2]int, n<<1)
size := 0
for i := l; i <= r; i++ {
if records[i][1] <= records[i][2] {
help[size][0] = records[i][1]
help[size][1] = 1
size++
help[size][0] = records[i][2]
help[size][1] = -1
size++
}
}
sort.Slice(help[:size], func(i, j int) bool {
if help[i][0] != help[j][0] {
return help[i][0] < help[j][0]
} else {
return help[j][1] < help[i][1]
}
})
count := 0
start := -1
for i := 0; i < size; i++ {
point := help[i][0]
status := help[i][1]
if status == 1 {
count++
if count >= 3 {
if start == -1 {
start = point
}
}
} else {
if start != -1 && start <= point {
st.add(start, point)
}
count--
if count >= 3 {
start = point + 1
} else {
start = -1
}
}
}
}
// 为了测试
func randomRecords(n, m, t int) [][]int {
records := make([][]int, n)
for i := 0; i < n; i++ {
records[i] = make([]int, 3)
}
for i := 0; i < n; i++ {
records[i][0] = rand.Intn(m) + 1
a := rand.Intn(t) + 1
b := rand.Intn(t) + 1
records[i][1] = min(a, b)
records[i][2] = max(a, b)
}
return records
}
// 为了测试
func randomQueries(k, t int) []int {
queries := make([]int, k)
for i := 0; i < k; i++ {
queries[i] = rand.Intn(t) + 1
}
return queries
}
func min(a, b int) int {
if a < b {
return a
}
return b
}
func max(a, b int) int {
if a > b {
return a
}
return b
}
func same(ans1, ans2 []int) bool {
if len(ans1) != len(ans2) {
return false
}
for i := 0; i < len(ans1); i++ {
if ans1[i] != ans2[i] {
return false
}
}
return true
}
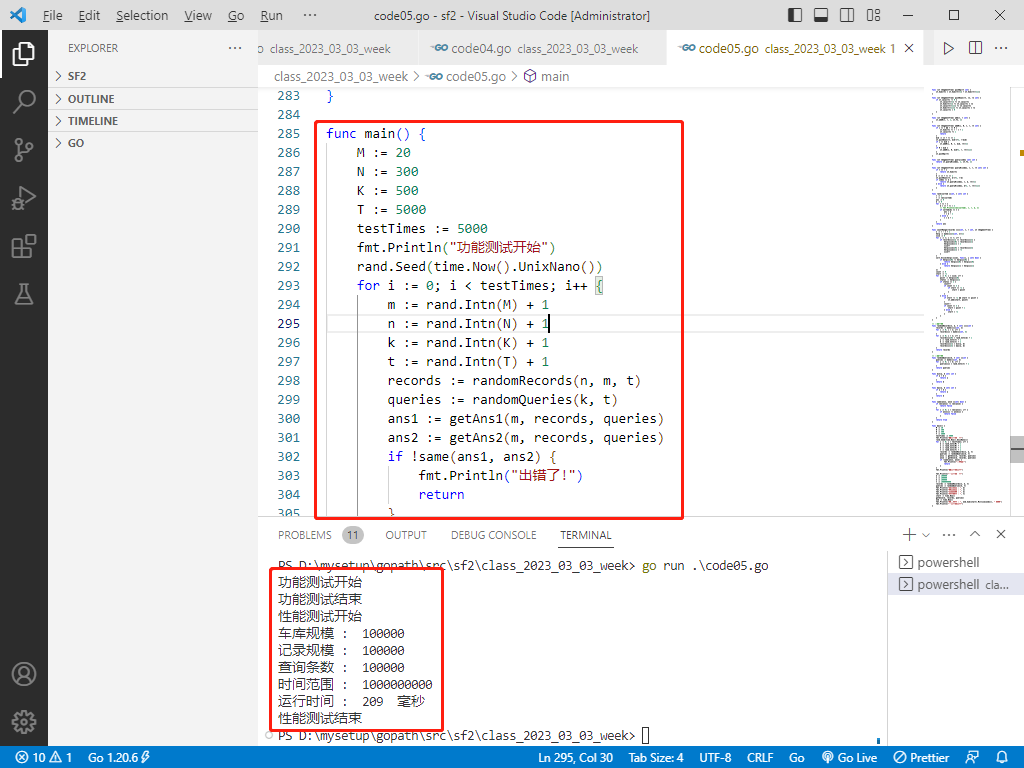
func main() {
M := 20
N := 300
K := 500
T := 5000
testTimes := 5000
fmt.Println("功能测试开始")
rand.Seed(time.Now().UnixNano())
for i := 0; i < testTimes; i++ {
m := rand.Intn(M) + 1
n := rand.Intn(N) + 1
k := rand.Intn(K) + 1
t := rand.Intn(T) + 1
records := randomRecords(n, m, t)
queries := randomQueries(k, t)
ans1 := getAns1(m, records, queries)
ans2 := getAns2(m, records, queries)
if !same(ans1, ans2) {
fmt.Println("出错了!")
return
}
}
fmt.Println("功能测试结束")
fmt.Println("性能测试开始")
m := 100000
n := 100000
k := 100000
t := 1000000000
records := randomRecords(n, m, t)
queries := randomQueries(k, t)
fmt.Println("车库规模 : ", m)
fmt.Println("记录规模 : ", n)
fmt.Println("查询条数 : ", k)
fmt.Println("时间范围 : ", t)
start := time.Now()
getAns2(m, records, queries)
end := time.Now()
fmt.Println("运行时间 : ", end.Sub(start).Milliseconds(), " 毫秒")
fmt.Println("性能测试结束")
}
2023-07-20:假设一共有M个车库,编号1~M,时间点从早到晚是从1~T, 一共有N个记录,每一条记录如下{a, b, c}, 表示一辆车在b时间点进入a车库,在c时间点从a车库出去, 一共有K的更多相关文章
- Codeforces 158 B. Taxi[贪心/模拟/一辆车最多可以坐4人同一个群的小朋友必须坐同一辆车问最少需要多少辆车]
http://codeforces.com/problemset/problem/158/B B. Taxi time limit per test 3 seconds memory limit pe ...
- 2021.07.20 P3951 小凯的疑惑(最大公因数,未证)
2021.07.20 P3951 小凯的疑惑(最大公因数,未证) 重点: 1.最大公因数 题意: 求ax+by最大的表示不了的数(a,b给定 x,y非负). 分析: 不会.--2021.07.20 代 ...
- 2021.07.20 CF1477A Nezzar and Board(最大公因数,未证)
2021.07.20 CF1477A Nezzar and Board(最大公因数,未证) CF1477A Nezzar and Board - 洛谷 | 计算机科学教育新生态 (luogu.com. ...
- MySQL中查询时间最大的一条记录
在项目中要查询用户最近登录的一条记录的 ip 直接写如下 SQL: SELECT ip,MAX(act_time) FROM users_login GROUP BY login_id; 但是这样是取 ...
- “取出数据表中第10条到第20条记录”的sql语句+select top 使用方法
1.首先.select top使用方法: 參考问题 select top n * from和select * from的差别 select * from table -- 取全部数据.返回无序集合 ...
- 当前时间、前n天、后n天、取前n条记录、从第n条开始取m条
当前时间:NOW() 前n天:DATE_SUB(NOW(),INTERVAL n DAY) 后n天:DATE_SUB(NOW(),INTERVAL -n DAY) 取前n条记录:SELECT * FR ...
- group by查询每组时间最新的一条记录
最近需要查询每组时间最新的记录 表如下:
- 一个表中的id有多个记录,把所有这个id的记录查出来,并显示共有多少条记录数
一个表中的id有多个记录,把所有这个id的记录查出来,并显示共有多少条记录数 select id ,Count(*) from table_name group by id having count( ...
- sql 分组后按时间降序排列再取出每组的第一条记录
原文:sql 分组后按时间降序排列再取出每组的第一条记录 竞价记录表: Aid 为竞拍车辆ID,uid为参与竞价人员ID,BidTime为参与竞拍时间 查询出表中某人参与的所有车辆的最新的一条的竞价记 ...
- “取出数据表中第10条到第20条记录”的sql语句+selecttop用法
1.首先,select top用法: 参考问题 select top n * from和select * from的区别 select * from table -- 取所有数据,返回无序集合 sel ...
随机推荐
- 连接MongoDB+Docker安装MongoDB
一.连接MongoDB 工具:studio 3T 下载:https://studio3t.com/download-thank-you/?OS=win64 1.无设置密码 最终成功页面 2.设置了密码 ...
- Network Science:巴拉巴西网络科学阅读笔记2 第一章图论
第一章:图论 完全图又被称为团. Metcalfe's Law: Metcalfe's law states that the value of a telecommunications networ ...
- ts中报错信息收集
1. 错误代码 参考:https://www.mmbyte.com/article/92849.html 1 state.localuserInfo = JSON.parse(localStorage ...
- vue上传文件(原生方法)
前言: 组件库的文件上传不适合项目,这里我们利用input标签实现文件上传 首先input type=file 标签是这个亚子的,而且样式不能改,我们利用css的方法,将一个定位到这个下面来,然后i ...
- vue处理图片路径出问题时显示默认图片
<img :src="item.url? item.url: '' " alt :onerror="defaultImg" /> 这里一定要判断sr ...
- 2022-09-02:以下go语言代码输出什么?A:9;B:11;C:编译错误;D:不确定。
2022-09-02:以下go语言代码输出什么?A:9:B:11:C:编译错误:D:不确定. package main import ( "fmt" ) func main() { ...
- 2020-11-08:在Mysql中,三个字段A、B、C的联合索引,查询条件是B、A、C,会用到索引吗?
福哥答案2020-11-08: 会走索引,原因是mysql优化器会把BAC优化成ABC. CREATE TABLE `t_testabc2` ( `id` int(11) NOT NULL AUTO_ ...
- 2022-04-23:给定一个长度为4的整数数组 cards 。你有 4 张卡片,每张卡片上都包含一个范围在 [1,9] 的数字。您应该使用运算符 [‘+‘, ‘-‘, ‘*‘, ‘/‘] 和括号 ‘
2022-04-23:给定一个长度为4的整数数组 cards .你有 4 张卡片,每张卡片上都包含一个范围在 [1,9] 的数字.您应该使用运算符 ['+', '-', '*', '/'] 和括号 ' ...
- SpringBoot配置与打包基础
本篇主要记录SpringBoot使用的基础配置 SpringBoot Maven配置 SpringBoot maven依赖关系 我们创建springboot项目后,会发现项目的pom文件都会继承自sp ...
- Django4全栈进阶之路10 url路由设置
在 Django 4 中,可以在主路由文件中设置和管理子路由.通常,我们会为每个应用程序创建一个子路由文件,以便更好地组织代码和管理路由. 以下是 Django 4 中设置主路由和子路由的示例: 首先 ...