Galaxy生物信息分析平台的数据集对象清理
由于微信不允许外部链接,你需要点击文章尾部左下角的 "阅读原文",才能访问文中链接。
Galaxy Project 是在云计算背景下诞生的一个生物信息学可视化分析开源项目。该项目由美国国家科学基金会(NSF)、美国国家人类基因组研究所(NHGRI)、哈克生命科学研究所(The Huck Institutes of the Life Sciences)、宾州州立大学网络科学研究所(The Institute for CyberScience at Penn State),以及约翰霍普金斯大学(Johns Hopkins University)提供支持,是目前生物医学研究领域最受欢迎的在线生物信息分析工具之一。
The Galaxy Project is supported in part by NSF, NHGRI, The Huck Institutes of the Life Sciences, The Institute for CyberScience at Penn State, and Johns Hopkins University.
从 2015 年起,Galaxy 源码从 bitbucket 转移至 GitHub 托管,截止 2018 年 10 月该项目在 GitHub 上有 506 个 star,192 个贡献者,51 个 release 发布版本。
基于 Galaxy Project admin 配置文档,今天我们来聊一聊其数据集删除、清理的一些细节。
1
背景
Galaxy 右侧栏历史面板中显示的 Histories,是作为记录保存在 Galaxy 数据库的 History 表中的。 在其他字段中,History 表包括以下内容:
| id | update_time | user_id | deleted | purged |当用户第一次访问 Galaxy 主页时,会创建一个新的 Galaxy 会话,并将会话信息存储在浏览器 cookie 中。 这时候 Galaxy 将自动创建一个新的历史记录并将其与会话 cookie 相关联。 此时,会话和历史都没有与用户 ID 相关联,因为用户尚未登录。使用 Galaxy 不需要登录,但如果用户登录了,则其用户 ID 将与 Galaxy 会话、以前创建的历史记录相关联。 在这种情况下,下次用户访问 Galaxy 主页并登录时,历史记录面板将显示符合以下所有条件的历史记录:
与他们的用户 ID 相关联
包含其最新更新,先前存储的历史记录
未被删除的(
history.deleted字段包含的值为 False)
当用户执行分析时,与数据集相关联的每一个条目将会添加到历史记录中。 这些条目称为 HistoryDatasetAssociation 对象。 与数据集有关的信息存储在 Galaxy 数据库的 Dataset 表中,而数据本身则存储在磁盘上。 Galaxy 配置文件中包含了一个 file_path 的属性,该属性指向存储数据集的磁盘的位置。 在其他列(字段)中,Dataset 表包括以下内容:
| id | update_time | deleted | purged | file_size |在其他的列字段中,HistoryDatasetAssociation 表包含了以下内容:
| id | update_time | history_id | deleted | dataset_id |每条 HistoryDatasetAssociation 记录都通过 HistoryDatasetAssociation.history_id 和 HistoryDatasetAssociation.dataset_id 列中的值将数据集 (Dataset) 与历史记录相关联。 任意多个的 HistoryDatasetAssociation 记录都可以指向一个基础的 Dataset 数据集 —— 这就是复制 histories,历史条目和 libraries 库的工作方式,这些都无需复制实际的文件内容。
在其他的列字段中,LibraryDatasetDatasetAssociation 表包含了以下内容:
| id | update_time | library_dataset_id | deleted | dataset_id |每一条的 LibraryDatasetDatasetAssociation 记录都通过LibraryDatasetDatasetAssociation.library_dataset_id 和 LibraryDatasetDatasetAssociation.dataset_id 列中的值将 Dataset 数据集与可版本化的库数据集记录相关联。 任意数量的 LibraryDatasetDatasetAssociation 记录都可以指向一个基础的 Dataset 数据集。
2
清除不需要的历史,库和数据集
只有在所有 HistoryDatasetAssociations 和 LibraryDatasetDatasetAssociations 都标记为已删除时,一个数据集才能真正被删除(或清除)。
Galaxy 发行版中包含 6 个脚本可用于清除不需要的历史记录,库和数据集。 这些脚本位于 GALAXY_ROOT/scripts/cleanup_datasets 目录中并命名为:
delete_userless_histories.sh
purge_histories.sh
purge_datasets.sh
purge_folders.sh
purge_libraries.sh
delete_datasets.sh
请注意,我们应该在运行脚本之前激活 Galaxy 虚拟环境,如下所示。
source /path/to/galaxy/root/.venv/bin/activate
sh delete_userless_histories.sh
sh purge_histories.sh这些脚本都在同一目录中执行一个名为 cleanup_datasets.py 的 Python 脚本,在命令行上发送不同的参数值。 如果需要,可以忽略这些脚本,并且可以手动执行 cleanup_datasets.py 脚本(使用 GALAXY_ROOT 作为工作目录),传入所需的参数值。 但是,我们也可以在 cron 中轻松配置这些脚本以自动执行。 脚本执行的顺序将影响结果; 为获得最佳效果,建议的运行顺序为:
delete_userless_histories.sh
purge_histories.sh
purge_libraries.sh
purge_folders.sh
purge_datasets.sh
如果希望在删除外部容器(历史记录,库/库文件夹)之前删除数据集,则可以在 purge_datasets.sh 脚本之前使用 delete_datasets.sh 脚本。 此脚本可能需要一些时间才能完成。
Available Flags
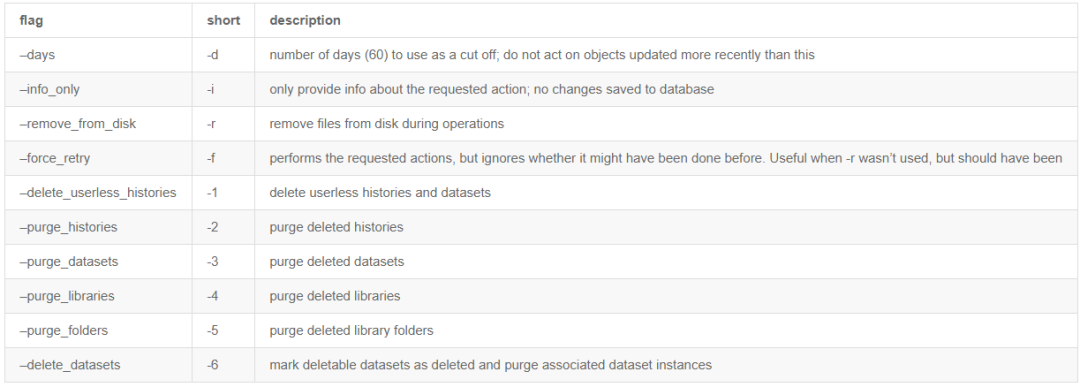
以下是有关 cleanup_datasets.py 脚本可以执行的每个函数的更多详细信息。
Deleting Userless Histories
如上所述,使用 Galaxy 默认是不需要登录的,并且在许多情况下,用户执行分析而无需登录以“一次性”方式查看结果,而不关心保留分析以供以后查看。 在这种情况下,创建的历史记录没有关联的用户 ID。cleanup_dataset.py 脚本可用于删除在指定时间段内未更改的这些类型的历史记录。 删除无用户历史记录的命令如下:
python cleanup_datasets.py config/galaxy.ini -d 60 -1请注意,传递给脚本的第一个参数是 Galaxy 的配置文件。这是脚本获取有关数据库连接和磁盘上数据文件位置的信息所必需的。-d 标志后面的值是从最后一次更新历史记录以来经过的天数(即,在此示例中,History.update_time 列中的值超过 60 天)。根据此条件,将检索所有不包含 user_id 列中的值且其 update_time 列值超过 60 天的历史记录。-1 标志告诉 cleanup_datasets.py 脚本执行名为 delete_userless_histories() 的方法,该方法包含在脚本中。此方法通过将 History.delete 列的值设置为 True 来删除 update_time 值早于指定天数的无用户历史记录。执行相同的命令,但提供 -i 标志不会写入任何更改;本程序执行后将提供有关要删除的历史记录的 info 信息。
Purging Deleted Histories
在历史记录的生命周期中,“已删除”阶段之后的阶段是“已清除”阶段,即历史记录生命周期的最后一个阶段。 清除历史记录时,将清除与历史记录关联的所有 HistoryDatasetAssociation 记录。 清除 HistoryDatasetAssociation 时,会将其标记为已删除。 另外,只有当同时清除了与该数据集的所有关联时,HDA 关联的数据集才会被标记为已删除(HDA 和 LDDA 都标记为已删除);当发生这种情况时,用户不再能够取消使用 HDA 和 LDDA —— 如果使用 “-r”,则会从磁盘中删除关联的文件和元数据文件(主数据集文件仍保留在磁盘上,并且可由管理员检索)。 清除历史记录和相关 HDA 的命令如下:
python cleanup_datasets.py config/galaxy.ini -d 60 -2 -r在此示例中,-2 标志告诉 cleanup_dataset.py 脚本执行脚本中包含的 purge_histories() 的方法。此方法检索 History.deleted 列值为 True,History.purged 列值为 False 且其 History.update_time 列值早于指定天数(在此示例中为 60 )的所有 History 记录。通过将 HistoryDatasetAssociation.deleted 列值设置为 True,也可以清除与历史记录关联的所有 HistoryDatasetAssociation 记录;轮询任何其他 DatasetAssociations(HDA / LDDA),如果它们都具有 HistoryDatasetAssociation.deleted==True,则 Dataset.deleted 列将被设置为 True。此示例中的 -r 标志告诉 cleanup_dataset.py 脚本从磁盘中删除与 HistoryDatasetAssociation 记录关联的文件(元数据等)(仅当 Dataset.deleted 设置为 True 时)。执行相同的命令但用 -i 替换 -r 标志将打印出所有历史记录和关联的 HistoryDatasetAssociation 记录,如果使用 -r 标志将清除这些记录。
Purging Deleted Datasets
当与数据集关联的所有历史记录和库记录都已经如上面所述,被删除了的时候,数据集记录将进入“已删除”阶段。
删除数据集记录生命周期的下一个阶段是“清除”阶段,即数据集记录生命周期的最后一个阶段。 清除数据集的命令类似于:
python cleanup_datasets.py config/galaxy.ini -d 60 -3 -r在此示例中,-3 标志告诉 cleanup_dataset.py 脚本执行脚本中包含的 purge_datasets() 方法。 此方法检索 Dataset.deleted 列值为 True,Dataset.purged 为 False 且其 Dataset.update_time 列的值早于指定天数(本示例中为 60 )的所有 Dataset 记录。 通过将 Dataset.purged 列设置为 True 来清除数据集记录。 如上所述,此示例中的 -r 标志告诉 cleanup_dataset.py 脚本从磁盘中删除与数据集记录关联的数据文件。 执行相同的命令但用 -i 替换 -r 标志将打印出在使用 -r 标志时将被清除的所有数据集记录。
Purging Library Folders
Besides existing in user’s history, dataset association objects exist with in
Library Folders
; they are known as
LibraryDatasetDatasetAssociations
(LDDAs). Purging a library folder is similar to purging a History. An example command is:
python cleanup_datasets.py config/galaxy.ini -d 60 -5 -rIn this example, the -5 flag tells the
cleanup_dataset.pyscript to execute thepurge_folders()method included in the script. This method retrieves allLibraryFolderrecords whoseLibraryFolder.deletedcolumn value isTrue,LibraryFolder.purgedcolumn value isFalseand whoseLibraryFolder.update_timecolumn value is older than the specified number of days ( 60 in this example ). It works recursively on all subfolders and their contents. AllLibraryDatasetDatasetAssociationsrecords associated with theLibraryFolderrecord are also purged by setting theLibraryDatasetDatasetAssociation.deletedcolumn value toTrue; any additionalDatasetAssociations(HDA/LDDA) are polled and if they all haveHistoryDatasetAssociation(LibraryDatasetDatasetAssociation).deleted==True, theDataset.deletedcolumn is set toTrue. The-rflag in this example tells thecleanup_dataset.pyscript to remove the files (metadata etc) associated with theLibraryDatasetDatasetAssociationrecord (but not the actual Dataset file) from disk (only ifDataset.deletedis to be set toTrue). Executing the same command but replacing the -r flag with -i will print out all of theLibraryFoldersand associatedLibraryDatasetDatasetAssociationrecords that will be purged if the -r flag is used.As is the case with
Histories
, the
purge_datasets
script will need to be used to remove actual
Datasets
from disk.
Purging Libraries
Purging a library is similar to purging a
LibraryFolder
. All libraries which are not purged, but are deleted and exceed the modified date are retrieved. The library is marked as purged and
purge_folder
is called on the library’s root folder, deleting all contents. An example command is:
python cleanup_datasets.py config/galaxy.ini -d 60 -4 -rIn this example, the -4 flag tells the
cleanup_dataset.pyscript to execute thepurge_libraries()method included in the script. This method retrieves allLibraryrecords whoseLibrary.deletedcolumn value is True,Library.purgedcolumn value is False and whoseLibraryFolder.update_timecolumn value is older than the specified number of days ( 60 in this example ). The Library’s Root Folder is then obtained and allLibraryDatasetDatasetAssociationsrecords associated with theLibraryFolderrecord are also purged by setting theLibraryDatasetDatasetAssociation.deletedcolumn value to True; any additionalDatasetAssociations(HDA/LDDA) are polled and if they all haveHistoryDatasetAssociation(LibraryDatasetDatasetAssociation).deleted==True, theDataset.deletedcolumn is set to True. The -r flag in this example tells thecleanup_dataset.pyscript to remove the files (metadata etc) associated with theLibraryDatasetDatasetAssociationrecord (but not the actual Dataset file) from disk (only ifDataset.deletedis to be set to True). Executing the same command but replacing the -r flag with -i will print out all of the Libraries,LibraryFoldersand associatedLibraryDatasetDatasetAssociationrecords that will be purged if the -r flag is used.
Deleting Datasets / Purging Dataset Instances
有时,在清除数据集实例并将基础数据集标记为已删除之前,不希望等待包含的历史记录或库/库文件夹被删除。-6 标志用于此目的。 此脚本将查找未删除但与 DatasetAssociation 相关联的所有数据集记录,该 DatasetAssociation 被标记为已删除并根据指定的截止值进行更新。 如果所有关联都标记为已删除,则 Dataset 将标记为已删除,并清除每个 DatasetAssociation。 之后需要运行 purge_datasets.sh 脚本以从磁盘中删除基础数据集。
An example command is:
python cleanup_datasets.py config/galaxy.ini -d 60 -6 -r
更多关于 Galaxy (release_18.05) 的数据集对象清理与实际操作,可以点击文章左下角 "阅读原文" 登陆博客查看。
·end·
—如果喜欢,快分享给你的朋友们吧—
我们一起愉快的玩耍吧
本文分享自微信公众号 - 生信科技爱好者(bioitee)。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
Galaxy生物信息分析平台的数据集对象清理的更多相关文章
- 1002-谈谈ELK日志分析平台的性能优化理念
在生产环境中,我们为了更好的服务于业务,通常会通过优化的手段来实现服务对外的性能最大化,节省系统性能开支:关注我的朋友们都知道,前段时间一直在搞ELK,同时也记录在了个人的博客篇章中,从部署到各个服务 ...
- Hermes:来自腾讯的实时检索分析平台
实时检索分析平台(Hermes)是腾讯数据平台部为大数据分析业务提供一套实时的.多维的.交互式的查询.统计.分析系统,为各个产品在大数据的统计分析方面提供完整的解决方案,让万级维度.千亿级数据下的秒级 ...
- LinkedIn文本分析平台:主题挖掘的四大技术步骤
作者 Yongzheng (Tiger) Zhang ,译者 木环 ,本人只是备份一下.. LinkedIn前不久发布两篇文章分享了自主研发的文本分析平台Voices的概览和技术细节.LinkedIn ...
- 手把手教你搭建 ELK 实时日志分析平台
本篇文章主要是手把手教你搭建 ELK 实时日志分析平台,那么,ELK 到底是什么呢? ELK 是三个开源项目的首字母缩写,这三个项目分别是:Elasticsearch.Logstash 和 Kiban ...
- 中国空气质量在线监测分析平台之JS加密、JS混淆处理
中国空气质量在线监测分析平台数据爬取分析 页面分析:确定url.请求方式.请求参数.响应数据 1.访问网站首页:https://www.aqistudy.cn/html/city_detail.htm ...
- C#曲线分析平台的制作(四,highcharts+ajax加载后台数据)
在上一篇博客:C#曲线分析平台的制作(三,三层构架+echarts显示)中已经完成了后台的三层构架的简单搭建,为实现后面的拓展应用开发和review 改写提供了方便.而在曲线分析平台中,往往有要求时间 ...
- C#曲线分析平台的制作(一,ajax+json前后台数据传递)
在最近的项目学习中,需要建立一个实时数据的曲线分析平台,这其中的关键在于前后台数据传递过程的学习,经过一天的前辈资料整理,大概有了一定的思路,现总结如下: 1.利用jquery下ajax函数实现: & ...
- 3款自助型BI分析平台功能盘点,帮助你预测商业发展方向
在快速发展的今天,商业智能BI已经不同于传统的商业智能BI,商业智能BI已经逐渐转变为自助和业务主导的模式,自助BI分析平台应运而生,自助BI分析平台逐渐成为许多企业的选择. 自助式BI分析平台与传统 ...
- ELK+redis搭建nginx日志分析平台
ELK+redis搭建nginx日志分析平台发表于 2015-08-19 | 分类于 Linux/Unix | ELK简介ELKStack即Elasticsearch + Logstas ...
- 使用elk+redis搭建nginx日志分析平台
elk+redis 搭建nginx日志分析平台 logstash,elasticsearch,kibana 怎么进行nginx的日志分析呢?首先,架构方面,nginx是有日志文件的,它的每个请求的状态 ...
随机推荐
- CSharp读写world文档数据
背景 在工作中需要对比数据,然后输出一份world文档的对比报告.这需要用C#来读写world文件. 用到的工具 NPOI NPOI 地址:NPOI NPOI版本:2.6.0 个人项目的运行时版本:. ...
- Spring Data Redis 框架
系统性学习,移步IT-BLOG 一.简介 对于类似于首页这种每天都有大量的人访问,对数据库造成很大的压力,严重时可能导致瘫痪.解决方法:一种是数据缓存.一种是网页静态化.今天就讨论数据缓存的实现 Re ...
- MyBatis 重点知识归纳
一.MyBatis 简介 [1]MyBatis 是支持定制化 SQL,存储过程以及高级映射的优秀持久化框架.[2]MyBatis 避免了几乎所有的 JDBC 代码和手动设置参数以及获取查询结果集.[3 ...
- 一遍博客带你上手Servlet
概念 Servlet其实就是Java提供的一门动态web资源开发技术.本质就是一个接口. 快速入门 创建web项目,导入servlet依赖坐标(注意依赖范围scope,是provided,只在编译和测 ...
- Linux线程同步必知,常用方法揭秘!
一.为什么要线程同步 在Linux 多线程编程中,线程同步是一个非常重要的问题.如果线程之间没有正确地同步,就会导致程序出现一些意外的问题,例如: 竞态条件(Race Condition):多个线程同 ...
- java idea配置流程
这篇文章主要介绍了IntelliJ IDEA2021.1 配置大全(超详细教程),需要的朋友可以参考下 一.IDEA下载 idea.jdk.tomcat.maven下载地址请参考上一篇博客:https ...
- Nvidia GPU热迁移-Singularity
1 背景 在GPU虚拟化和池化的加持下,可以显著提高集群的GPU利用率,同时也可以较好地实现弹性伸缩.但有时会遇到需要GPU资源再分配的场景,此时亟需集群拥有GPU任务热迁移的能力.举个简单的例子,比 ...
- STM32启动分析之main函数是怎样跑起来的
1.MDK目标文件 1)MDK中C程序编译后的结果,即可执行文件数据分类: RAM ZI bss 存储未初始化的或初始化为0的全局变量和静态变量 heap 堆,系统malloc和free操作的内存 s ...
- 【机器学习与深度学习理论要点】20. 什么是激活函数,为什么要用激活函数,常见的激活函数和特点,softmax函数
1)什么是激活函数,为什么要用激活函数? 激活函数,指神经网络中将输入信号的总和转换为输出信号的函数,激活函数将多层感知机输出转换为非线性,使得神经网络可以任意逼近任何非线性函数,这样神经网络就可以应 ...
- lombok版本报错问题java.lang.IllegalAccessError: class lombok.javac.apt.LombokProcessor (in unnamed module
lombok版本报错问题 记录一个项目部署时遇到的问题,我本地采用的JDK8的版本,然后我的服务器采用的是JDK17,然后在用maven进行打包的时候,发现package失败. 复现 我在本地采用的l ...