【2023最新B站评论爬虫】用python爬取上千条哔哩哔哩评论
您好,我是@马哥python说,一枚10年程序猿。
一、爬取目标
之前,我分享过一些B站的爬虫:
【Python爬虫案例】用Python爬取李子柒B站视频数据
【Python爬虫案例】用python爬哔哩哔哩搜索结果
【爬虫+情感判定+Top10高频词+词云图】"谷爱凌"热门弹幕python舆情分析
但我学习群中小伙伴频繁讨论B站评论的爬取,所以,再分享一个B站视频评论的爬虫。
二、展示爬取结果
首先,看下部分爬取数据:
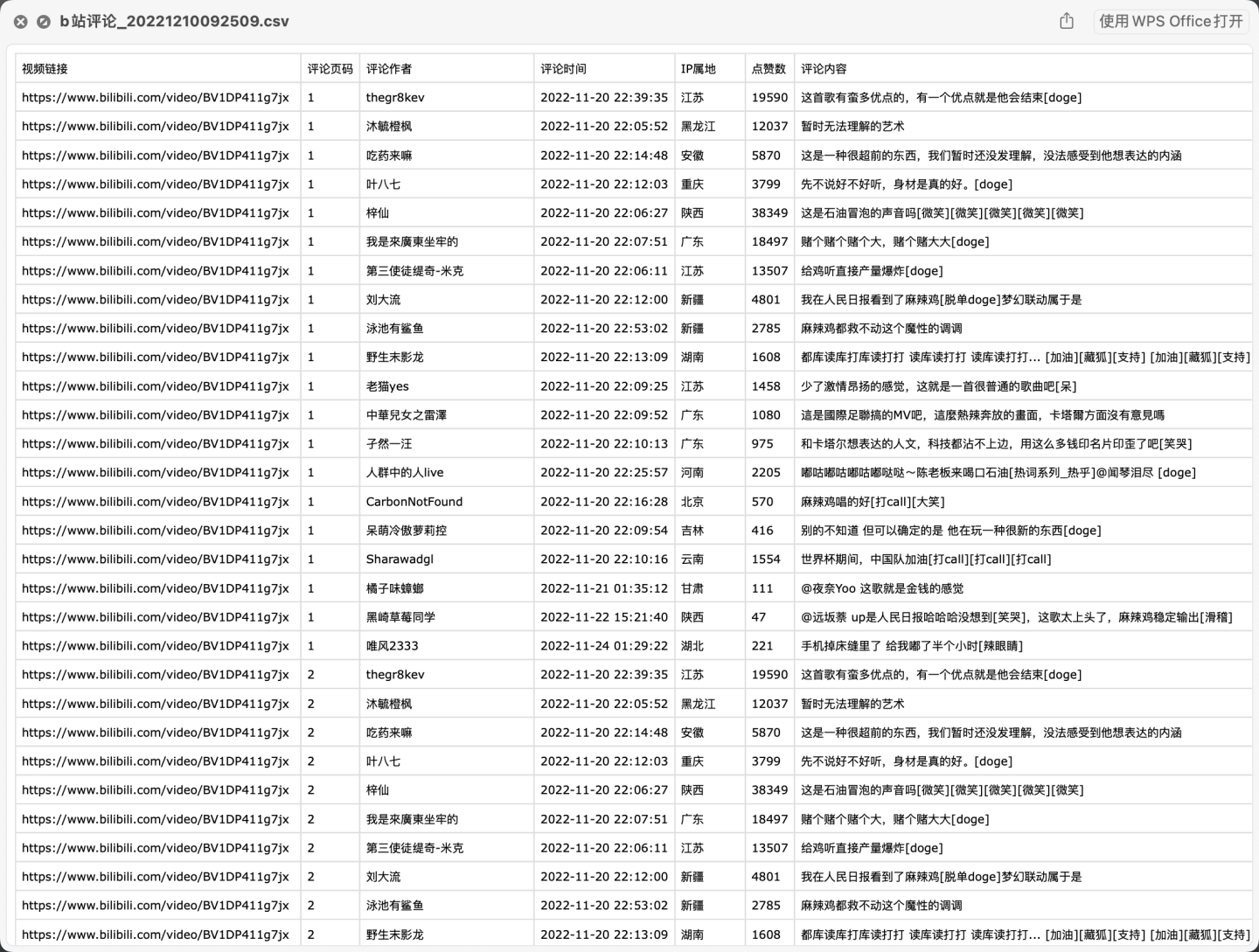
爬取字段含:视频链接、评论页码、评论作者、评论时间、IP属地、点赞数、评论内容。
三、爬虫代码
导入需要用到的库:
import requests # 发送请求
import pandas as pd # 保存csv文件
import os # 判断文件是否存在
import time
from time import sleep # 设置等待,防止反爬
import random # 生成随机数
定义一个请求头:
# 请求头
headers = {
'authority': 'api.bilibili.com',
'accept': 'application/json, text/plain, */*',
'accept-language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
# 需定期更换cookie,否则location爬不到
'cookie': "需换成自己的cookie值",
'origin': 'https://www.bilibili.com',
'referer': 'https://www.bilibili.com/video/BV1FG4y1Z7po/?spm_id_from=333.337.search-card.all.click&vd_source=69a50ad969074af9e79ad13b34b1a548',
'sec-ch-ua': '"Chromium";v="106", "Microsoft Edge";v="106", "Not;A=Brand";v="99"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
'sec-fetch-dest': 'empty',
'sec-fetch-mode': 'cors',
'sec-fetch-site': 'same-site',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36 Edg/106.0.1370.47'
}
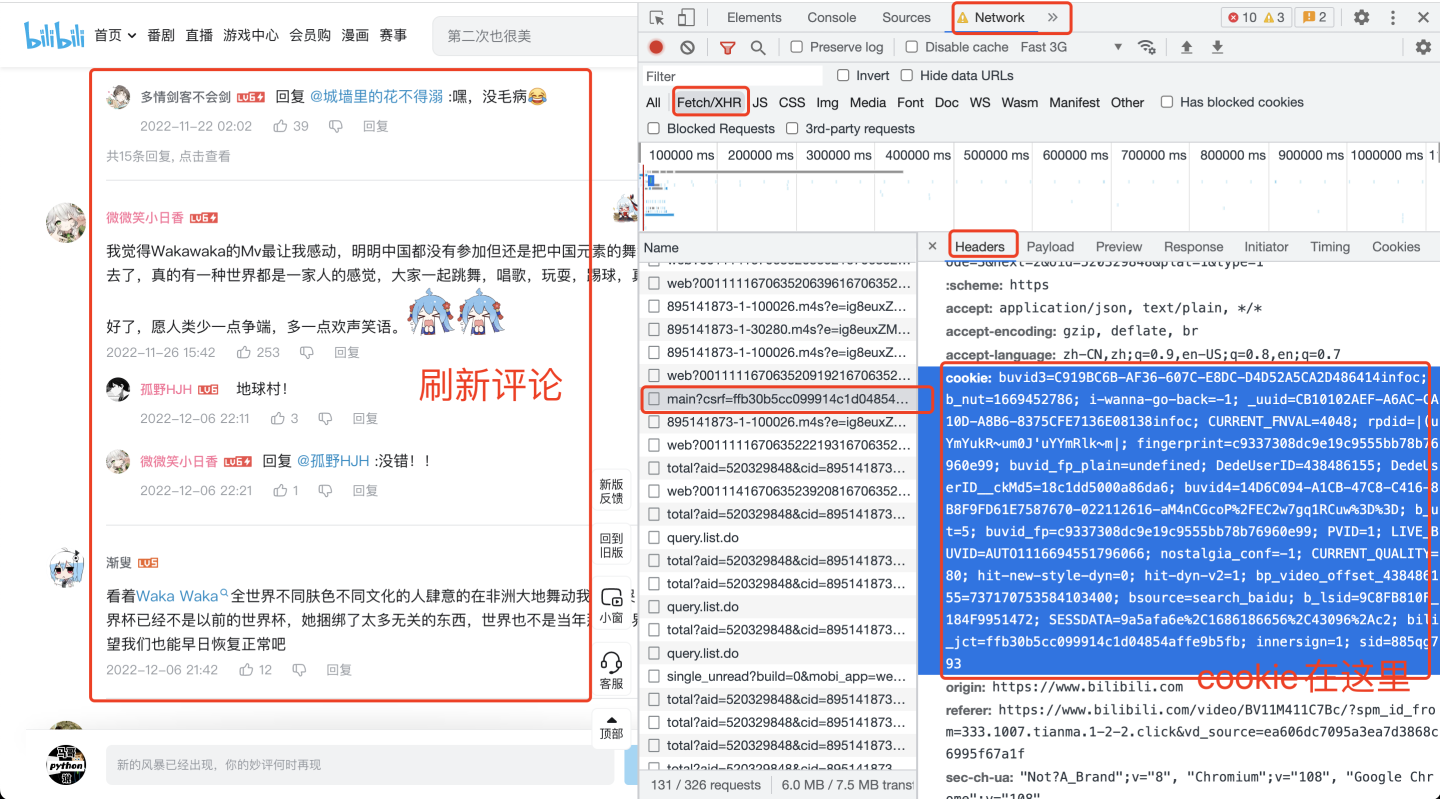
请求头中的cookie是个很关键的参数,如果不设置cookie,会导致数据残缺或无法爬取到数据。
那么cookie如何获取呢?打开开发者模式,见下图:
由于评论时间是个十位数:
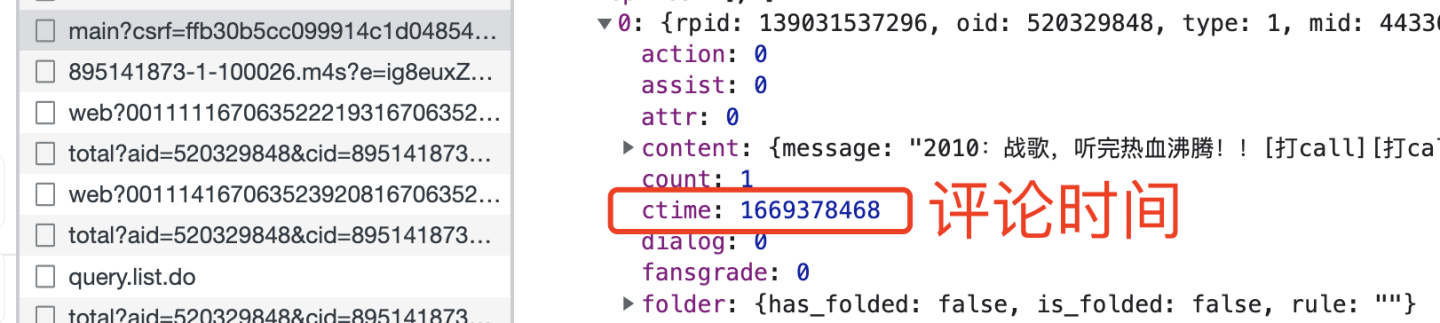
所以开发一个函数用于转换时间格式:
def trans_date(v_timestamp):
"""10位时间戳转换为时间字符串"""
timeArray = time.localtime(v_timestamp)
otherStyleTime = time.strftime("%Y-%m-%d %H:%M:%S", timeArray)
return otherStyleTime
向B站发送请求:
response = requests.get(url, headers=headers, ) # 发送请求
接收到返回数据了,怎么解析数据呢?看一下json数据结构:

0-19个评论,都存放在replies下面,replies又在data下面,所以,这样解析数据:
data_list = response.json()['data']['replies'] # 解析评论数据
这样,data_list里面就是存储的每条评论数据了。
接下来吗,就是解析出每条评论里的各个字段了。
我们以评论内容这个字段为例:
comment_list = [] # 评论内容空列表
# 循环爬取每一条评论数据
for a in data_list:
# 评论内容
comment = a['content']['message']
comment_list.append(comment)
其他字段同理,不再赘述。
最后,把这些列表数据保存到DataFrame里面,再to_csv保存到csv文件,持久化存储完成:
# 把列表拼装为DataFrame数据
df = pd.DataFrame({
'视频链接': 'https://www.bilibili.com/video/' + v_bid,
'评论页码': (i + 1),
'评论作者': user_list,
'评论时间': time_list,
'IP属地': location_list,
'点赞数': like_list,
'评论内容': comment_list,
})
# 把评论数据保存到csv文件
df.to_csv(outfile, mode='a+', encoding='utf_8_sig', index=False, header=header)
注意,加上encoding='utf_8_sig',否则可能会产生乱码问题!
下面,是主函数循环爬取部分代码:(支持多个视频的循环爬取)
# 随便找了几个"世界杯"相关的视频ID
bid_list = ['BV1DP411g7jx', 'BV1M24y117K3', 'BV1nt4y1N7Kj']
# 评论最大爬取页(每页20条评论)
max_page = 30
# 循环爬取这几个视频的评论
for bid in bid_list:
# 输出文件名
outfile = 'b站评论_{}.csv'.format(now)
# 转换aid
aid = bv2av(bid=bid)
# 爬取评论
get_comment(v_aid=aid, v_bid=bid)
四、同步视频
演示视频:
https://www.zhihu.com/zvideo/1584884344677437440
五、附完整源码
附完整代码:公众号"老男孩的平凡之路"后台回复"爬B站评论"即可获取。
【2023最新B站评论爬虫】用python爬取上千条哔哩哔哩评论的更多相关文章
- Python爬取腾讯新闻首页所有新闻及评论
前言 这篇博客写的是实现的一个爬取腾讯新闻首页所有的新闻及其所有评论的爬虫.选用Python的Scrapy框架.这篇文章主要讨论使用Chrome浏览器的开发者工具获取新闻及评论的来源地址. Chrom ...
- 这届网友实在是太有才了!用python爬取15万条《我是余欢水》弹幕
年初时我们用数据解读了几部热度高,但评分差强人意的国产剧,而最近正午阳光带着两部新剧来了,<我是余欢水>和<清平乐>,截止到目前为止,这两部剧在豆瓣分别为7.5分和7.9分,算 ...
- 【Python3爬虫】我爬取了七万条弹幕,看看RNG和SKT打得怎么样
一.写在前面 直播行业已经火热几年了,几个大平台也有了各自独特的“弹幕文化”,不过现在很多平台直播比赛时的弹幕都基本没法看的,主要是因为网络上的喷子还是挺多的,尤其是在观看比赛的时候,很多弹幕不是喷选 ...
- Python爬取爱奇艺【老子传奇】评论数据
# -*- coding: utf-8 -*- import requests import os import csv import time import random base_url = 'h ...
- 【Python爬虫案例】用Python爬取李子柒B站视频数据
一.视频数据结果 今天是2021.12.7号,前几天用python爬取了李子柒的油管评论并做了数据分析,可移步至: https://www.cnblogs.com/mashukui/p/1622025 ...
- Python爬虫实例:爬取B站《工作细胞》短评——异步加载信息的爬取
很多网页的信息都是通过异步加载的,本文就举例讨论下此类网页的抓取. <工作细胞>最近比较火,bilibili 上目前的短评已经有17000多条. 先看分析下页面 右边 li 标签中的就是短 ...
- 用Python爬取B站、腾讯视频、爱奇艺和芒果TV视频弹幕!
众所周知,弹幕,即在网络上观看视频时弹出的评论性字幕.不知道大家看视频的时候会不会点开弹幕,于我而言,弹幕是视频内容的良好补充,是一个组织良好的评论序列.通过分析弹幕,我们可以快速洞察广大观众对于视频 ...
- 【转载】教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神
原文:教你分分钟学会用python爬虫框架Scrapy爬取心目中的女神 本博文将带领你从入门到精通爬虫框架Scrapy,最终具备爬取任何网页的数据的能力.本文以校花网为例进行爬取,校花网:http:/ ...
- Python爬虫实例:爬取猫眼电影——破解字体反爬
字体反爬 字体反爬也就是自定义字体反爬,通过调用自定义的字体文件来渲染网页中的文字,而网页中的文字不再是文字,而是相应的字体编码,通过复制或者简单的采集是无法采集到编码后的文字内容的. 现在貌似不少网 ...
- Python爬虫实例:爬取豆瓣Top250
入门第一个爬虫一般都是爬这个,实在是太简单.用了 requests 和 bs4 库. 1.检查网页元素,提取所需要的信息并保存.这个用 bs4 就可以,前面的文章中已经有详细的用法阐述. 2.找到下一 ...
随机推荐
- linux 安装mysql8.0.11
1.使用系统的root账户 2.切换到/use/local 目录下 3.下载mysql ?wget https://dev.mysql.com/get/Downloads/MySQL-8.0/mysq ...
- MySQL索引Innodb存储引擎
MySQL索引优化 一.基础理解 MySQL语句的查询效率主要和索引树的高度有关,想要降低查询的次数提高查询的速度,减少直接对磁盘的I/O流的次数,就要让索引树的高度越低越好. 索引的定义:索引是帮助 ...
- 提高生产力!这10个Lambda表达式必须掌握,开发效率嘎嘎上升!
在Java8及更高版本中,Lambda表达式的引入极大地提升了编程的简洁性和效率.本文将围绕十个关键场景,展示Lambda如何助力提升开发效率,让代码更加精炼且易于理解. 集合遍历 传统的for-ea ...
- N次剩余小记
前言 上周在 51nod 交了一些3.4级的题目,然后发现没有写过1级题, 就找到了一道 51nod 1014 \(X^2 \bmod P\) 的题目,当然这题虽然是暴力,但也可以用二次剩余做. 我就 ...
- 深入探讨Java面试中内存泄漏:如何识别、预防和解决
引言 在编写和维护Java应用程序时,内存泄漏是一个重要的问题,可能导致性能下降和不稳定性.本文将介绍内存泄漏的概念,为什么它在Java应用程序中如此重要,并明确本文的目标,即识别.预防和解决内存泄漏 ...
- CentOS升级内核-- CentOS9 Stream/CentOS8 Stream/CentOS7
官方文档在此 升级原因 当我们安装一些软件(对,我说的就是Kubernetes),可能需要新内核的支持,而CentOS又比较保守,不太升级,所以需要我们手工升级. # 看下目前是什么版本内核 unam ...
- 聊聊 Redis Stream
Redis Stream 是 Redis 5.0 版本中引入的一种新的数据结构,它用于实现简单但功能强大的消息传递模式. 这篇文章,我们聊聊 Redis Stream 基本用法 ,以及如何在 Spri ...
- 必须经典GPT4.0
学习C#编程,有一些经典的教材和资源值得关注.下面列出了一些建议供你参考: 1. <C# 编程黄皮书>(C# Programming Yellow Book):Rob Miles 编著的这 ...
- mockjs 模拟实现增删改查
/*mUtils.js用于解析get请求的参数*/ export const param2Obj = url => { const search = url.split('?')[1] if ( ...
- 旧版本的centOS下载(国内-清华)
链接如下: https://mirrors.tuna.tsinghua.edu.cn/centos-vault/