[转帖]TiDB 数据库的调度
https://docs.pingcap.com/zh/tidb/stable/tidb-scheduling#%E4%BF%A1%E6%81%AF%E6%94%B6%E9%9B%86
PD (Placement Driver) 是 TiDB 集群的管理模块,同时也负责集群数据的实时调度。本文档介绍一下 PD 的设计思想和关键概念。
场景描述
TiKV 集群是 TiDB 数据库的分布式 KV 存储引擎,数据以 Region 为单位进行复制和管理,每个 Region 会有多个副本 (Replica),这些副本会分布在不同的 TiKV 节点上,其中 Leader 负责读/写,Follower 负责同步 Leader 发来的 Raft log。
需要考虑以下场景:
- 为了提高集群的空间利用率,需要根据 Region 的空间占用对副本进行合理的分布。
- 集群进行跨机房部署的时候,要保证一个机房掉线,不会丢失 Raft Group 的多个副本。
- 添加一个节点进入 TiKV 集群之后,需要合理地将集群中其他节点上的数据搬到新增节点。
- 当一个节点掉线时,需要考虑快速稳定地进行容灾。
- 从节点的恢复时间来看
- 如果节点只是短暂掉线(重启服务),是否需要进行调度。
- 如果节点是长时间掉线(磁盘故障,数据全部丢失),如何进行调度。
- 假设集群需要每个 Raft Group 有 N 个副本,从单个 Raft Group 的副本个数来看
- 副本数量不够(例如节点掉线,失去副本),需要选择适当的机器的进行补充。
- 副本数量过多(例如掉线的节点又恢复正常,自动加入集群),需要合理的删除多余的副本。
- 从节点的恢复时间来看
- 读/写通过 Leader 进行,Leader 的分布只集中在少量几个节点会对集群造成影响。
- 并不是所有的 Region 都被频繁的访问,可能访问热点只在少数几个 Region,需要通过调度进行负载均衡。
- 集群在做负载均衡的时候,往往需要搬迁数据,这种数据的迁移可能会占用大量的网络带宽、磁盘 IO 以及 CPU,进而影响在线服务。
以上问题和场景如果多个同时出现,就不太容易解决,因为需要考虑全局信息。同时整个系统也是在动态变化的,因此需要一个中心节点,来对系统的整体状况进行把控和调整,所以有了 PD 这个模块。
调度的需求
对以上的问题和场景进行分类和整理,可归为以下两类:
第一类:作为一个分布式高可用存储系统,必须满足的需求,包括几种
- 副本数量不能多也不能少
- 副本需要根据拓扑结构分布在不同属性的机器上
- 节点宕机或异常能够自动合理快速地进行容灾
第二类:作为一个良好的分布式系统,需要考虑的地方包括
- 维持整个集群的 Leader 分布均匀
- 维持每个节点的储存容量均匀
- 维持访问热点分布均匀
- 控制负载均衡的速度,避免影响在线服务
- 管理节点状态,包括手动上线/下线节点
满足第一类需求后,整个系统将具备强大的容灾功能。满足第二类需求后,可以使得系统整体的资源利用率更高且合理,具备良好的扩展性。
为了满足这些需求,首先需要收集足够的信息,比如每个节点的状态、每个 Raft Group 的信息、业务访问操作的统计等;其次需要设置一些策略,PD 根据这些信息以及调度的策略,制定出尽量满足前面所述需求的调度计划;最后需要一些基本的操作,来完成调度计划。
调度的基本操作
调度的基本操作指的是为了满足调度的策略。上述调度需求可整理为以下三个操作:
- 增加一个副本
- 删除一个副本
- 将 Leader 角色在一个 Raft Group 的不同副本之间 transfer(迁移)
刚好 Raft 协议通过 AddReplica、RemoveReplica、TransferLeader 这三个命令,可以支撑上述三种基本操作。
信息收集
调度依赖于整个集群信息的收集,简单来说,调度需要知道每个 TiKV 节点的状态以及每个 Region 的状态。TiKV 集群会向 PD 汇报两类消息,TiKV 节点信息和 Region 信息:
每个 TiKV 节点会定期向 PD 汇报节点的状态信息
TiKV 节点 (Store) 与 PD 之间存在心跳包,一方面 PD 通过心跳包检测每个 Store 是否存活,以及是否有新加入的 Store;另一方面,心跳包中也会携带这个 Store 的状态信息,主要包括:
- 总磁盘容量
- 可用磁盘容量
- 承载的 Region 数量
- 数据写入/读取速度
- 发送/接受的 Snapshot 数量(副本之间可能会通过 Snapshot 同步数据)
- 是否过载
- labels 标签信息(标签是具备层级关系的一系列 Tag,能够感知拓扑信息)
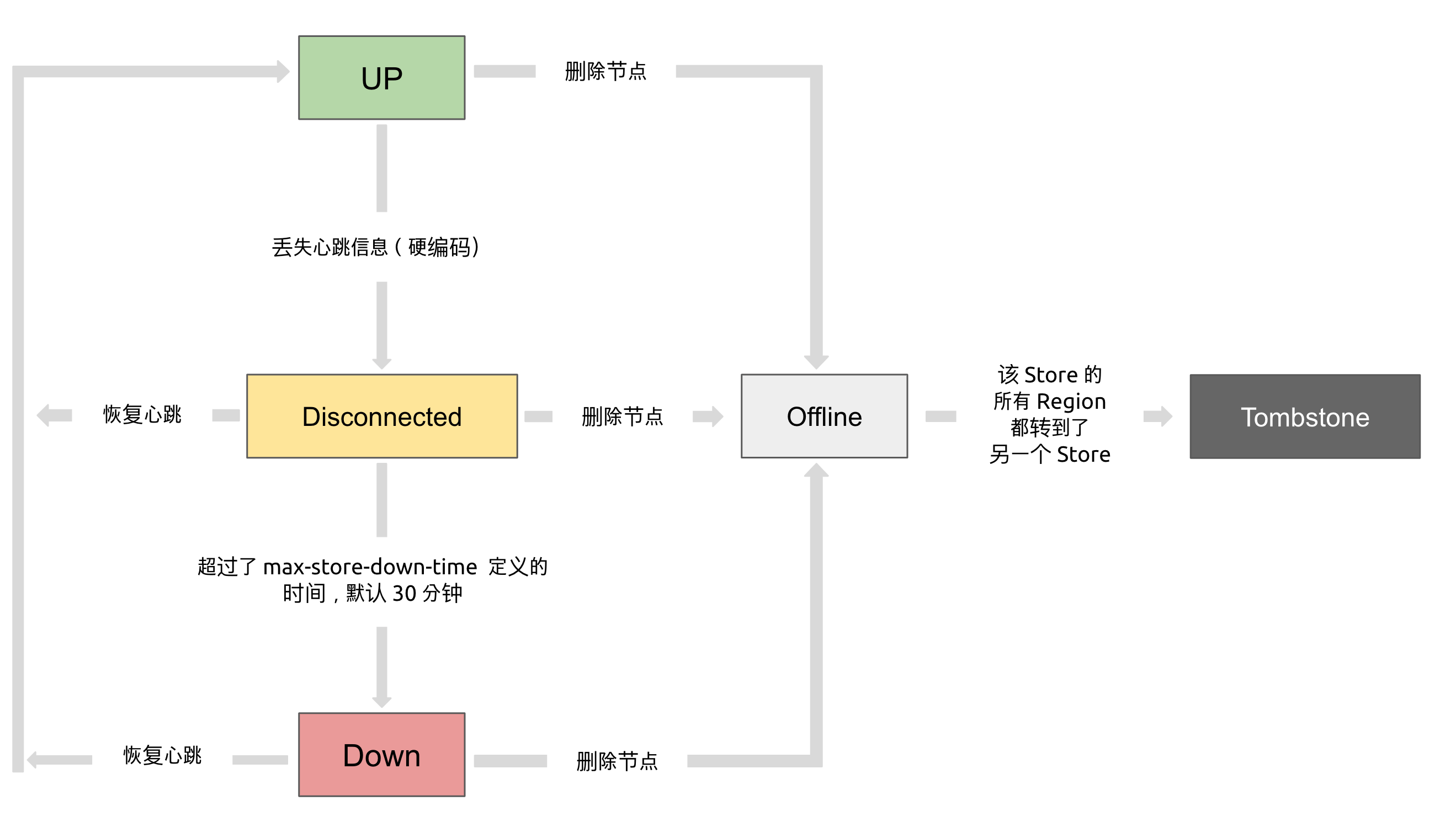
通过使用 pd-ctl 可以查看到 TiKV Store 的状态信息。TiKV Store 的状态具体分为 Up,Disconnect,Offline,Down,Tombstone。各状态的关系如下:
- Up:表示当前的 TiKV Store 处于提供服务的状态。
- Disconnect:当 PD 和 TiKV Store 的心跳信息丢失超过 20 秒后,该 Store 的状态会变为 Disconnect 状态,当时间超过
max-store-down-time指定的时间后,该 Store 会变为 Down 状态。 - Down:表示该 TiKV Store 与集群失去连接的时间已经超过了
max-store-down-time指定的时间,默认 30 分钟。超过该时间后,对应的 Store 会变为 Down,并且开始在存活的 Store 上补足各个 Region 的副本。 - Offline:当对某个 TiKV Store 通过 PD Control 进行手动下线操作,该 Store 会变为 Offline 状态。该状态只是 Store 下线的中间状态,处于该状态的 Store 会将其上的所有 Region 搬离至其它满足搬迁条件的 Up 状态 Store。当该 Store 的
leader_count和region_count(在 PD Control 中获取) 均显示为 0 后,该 Store 会由 Offline 状态变为 Tombstone 状态。在 Offline 状态下,禁止关闭该 Store 服务以及其所在的物理服务器。下线过程中,如果集群里不存在满足搬迁条件的其它目标 Store(例如没有足够的 Store 能够继续满足集群的副本数量要求),该 Store 将一直处于 Offline 状态。 - Tombstone:表示该 TiKV Store 已处于完全下线状态,可以使用
remove-tombstone接口安全地清理该状态的 TiKV。
每个 Raft Group 的 Leader 会定期向 PD 汇报 Region 的状态信息
每个 Raft Group 的 Leader 和 PD 之间存在心跳包,用于汇报这个 Region 的状态,主要包括下面几点信息:
- Leader 的位置
- Followers 的位置
- 掉线副本的个数
- 数据写入/读取的速度
PD 不断的通过这两类心跳消息收集整个集群的信息,再以这些信息作为决策的依据。
除此之外,PD 还可以通过扩展的接口接受额外的信息,用来做更准确的决策。比如当某个 Store 的心跳包中断的时候,PD 并不能判断这个节点是临时失效还是永久失效,只能经过一段时间的等待(默认是 30 分钟),如果一直没有心跳包,就认为该 Store 已经下线,再决定需要将这个 Store 上面的 Region 都调度走。
但是有的时候,是运维人员主动将某台机器下线,这个时候,可以通过 PD 的管理接口通知 PD 该 Store 不可用,PD 就可以马上判断需要将这个 Store 上面的 Region 都调度走。
调度的策略
PD 收集了这些信息后,还需要一些策略来制定具体的调度计划。
一个 Region 的副本数量正确
当 PD 通过某个 Region Leader 的心跳包发现这个 Region 的副本数量不满足要求时,需要通过 Add/Remove Replica 操作调整副本数量。出现这种情况的可能原因是:
- 某个节点掉线,上面的数据全部丢失,导致一些 Region 的副本数量不足
- 某个掉线节点又恢复服务,自动接入集群,这样之前已经补足了副本的 Region 的副本数量过多,需要删除某个副本
- 管理员调整副本策略,修改了 max-replicas 的配置
一个 Raft Group 中的多个副本不在同一个位置
注意这里用的是『同一个位置』而不是『同一个节点』。在一般情况下,PD 只会保证多个副本不落在一个节点上,以避免单个节点失效导致多个副本丢失。在实际部署中,还可能出现下面这些需求:
- 多个节点部署在同一台物理机器上
- TiKV 节点分布在多个机架上,希望单个机架掉电时,也能保证系统可用性
- TiKV 节点分布在多个 IDC 中,希望单个机房掉电时,也能保证系统可用性
这些需求本质上都是某一个节点具备共同的位置属性,构成一个最小的『容错单元』,希望这个单元内部不会存在一个 Region 的多个副本。这个时候,可以给节点配置 labels 并且通过在 PD 上配置 location-labels 来指名哪些 label 是位置标识,需要在副本分配的时候尽量保证一个 Region 的多个副本不会分布在具有相同的位置标识的节点上。
副本在 Store 之间的分布均匀分配
由于每个 Region 的副本中存储的数据容量上限是固定的,通过维持每个节点上面副本数量的均衡,使得各节点间承载的数据更均衡。
Leader 数量在 Store 之间均匀分配
Raft 协议要求读取和写入都通过 Leader 进行,所以计算的负载主要在 Leader 上面,PD 会尽可能将 Leader 在节点间分散开。
访问热点数量在 Store 之间均匀分配
每个 Store 以及 Region Leader 在上报信息时携带了当前访问负载的信息,比如 Key 的读取/写入速度。PD 会检测出访问热点,且将其在节点之间分散开。
各个 Store 的存储空间占用大致相等
每个 Store 启动的时候都会指定一个 Capacity 参数,表明这个 Store 的存储空间上限,PD 在做调度的时候,会考虑节点的存储空间剩余量。
控制调度速度,避免影响在线服务
调度操作需要耗费 CPU、内存、磁盘 IO 以及网络带宽,需要避免对线上服务造成太大影响。PD 会对当前正在进行的操作数量进行控制,默认的速度控制是比较保守的,如果希望加快调度(比如停服务升级或者增加新节点,希望尽快调度),那么可以通过调节 PD 参数动态加快调度速度。
调度的实现
本节介绍调度的实现
PD 不断地通过 Store 或者 Leader 的心跳包收集整个集群信息,并且根据这些信息以及调度策略生成调度操作序列。每次收到 Region Leader 发来的心跳包时,PD 都会检查这个 Region 是否有待进行的操作,然后通过心跳包的回复消息,将需要进行的操作返回给 Region Leader,并在后面的心跳包中监测执行结果。
注意这里的操作只是给 Region Leader 的建议,并不保证一定能得到执行,具体是否会执行以及什么时候执行,由 Region Leader 根据当前自身状态来定。
[转帖]TiDB 数据库的调度的更多相关文章
- jdbc与TiDB数据库交互的过程
以下是使用jdbc操作TiDB数据库,得到的交互过程和指令的说明 ==>代表发送给数据库的指令 // 加载驱动程序Class.forName(driver); // 连接数据库 Connecti ...
- 安装Tidb数据库出现SSD硬盘IOPS不到40000的错误
今天安装tidb数据库出现IOPS过低的问题,这里如果仅仅是测试的话我们可以降低这个值,大概遇到的问题是: 解决方法: 1.我们在中控机的目录下修改某个配置文件: [tidb@:vg_adn_tidb ...
- TiDB数据库 mydumper与loader导入数据
从mysql导出数据最好的方法是使用tidb官方的工具mydumper. 导入tidb最好的方法是使用loader工具,大概19.4G每小时的速度. 详细的步骤可以参考官网:https://pingc ...
- TiDB数据库 使用syncer工具同步实时数据
mysql> select campaign_id ,count(id) from creative_output group by campaign_id; rows min 44.23 se ...
- 从一个简单的Delete删数据场景谈TiDB数据库开发规范的重要性
故事背景 前段时间上线了一个从Oracle迁移到TiDB的项目,某一天应用端反馈有一个诡异的现象,就是有张小表做全表delete的时候执行比较慢,而且有越来越慢的迹象.这个表每次删除的数据不超过20行 ...
- mysql数据库事件调度(Event)
mysql中的事件调度器可以定时对数据库增加,删除和执行操作,相当于数据库中的临时触发器,与Linux系统中的执行计划任务一样,这样就可以大大降低工作量. 1.开启事件调度器 [root@node1 ...
- Tidb数据库报错:Transaction too large
Tidb是一个支持ACID的分布式数据库,当你导入一个非常大的数据集时,这时候产生的事务相当严重,并且Tidb本身对事物的大小也是有一个严格的控制. 有事务大小的限制主要在于 TiKV 的实现用了一致 ...
- TiDB数据库 mydumper命令导出数据报错:(mydumper:1908): CRITICAL **: Couldn't acquire global lock, snapshots will not be consistent: Access denied for user 'super'@'%' (using password: YES)
今天想使用Tidb官方提供的mydumper来备份AWS上的RDS集群中mysql数据库的某个表,发现报错了 [tidb@:xxx /usr/local/tidb-tools]$ -t -F -B x ...
- 记录一次向TiDB数据库导入数据的例子
导出数据 今天从Mysql的某个库中导出一个表大概有20分钟吧,等了一会终于导出成功了.查看一下文件的大小: [tidb@:vg_adn_CkhsTest ~]$du -h ./creative_ou ...
- [转帖]时序数据库技术体系(二):初识InfluxDB
时序数据库技术体系(二):初识InfluxDB https://sq.163yun.com/blog/article/169866295296581632 把生命浪费在美好事物上2018-06-26 ...
随机推荐
- Tpon 1.0 一键查询网站存在过的路径
Tpon 1.0 寻找网站存在过的路径 该工具能够让你发现意料之外的路径 工具描述 编写该工具旨在寻找网站存在过的网站路径,这个地址可能是机器爬下来的也可能是某些人访问过的,在表面你可能看不到它的入口 ...
- MindSpore实践:对篮球运动员目标的检测
摘要:本文讲述的是MindSpore对篮球运动员目标的检测应用,通过AI技术辅助对篮球赛场进行分析. 本文分享自华为云社区<MindSpore大V博文系列:AI对篮球运动员目标的检测>,原 ...
- java算法易筋经:常见java-API使用技巧
摘要:算法练习的本质也在于锻炼编程思维,强化程序员的内力.因此给自己后面会持续更新的算法技巧内容简称算法易筋经. 本文分享自华为云社区<<java算法易筋经>之常见java-API使 ...
- 常遇到读多写少,教你用ReadWriteLock实现一个通用的缓存中心
摘要:本文我们就来说说使用ReadWriteLock如何实现一个通用的缓存中心. 本文分享自华为云社区<[高并发]原来ReadWriteLock也能开发高性能缓存,看完我也能和面试官好好聊聊了! ...
- 列举GaussDB(DWS)常见的查询时索引失效场景
摘要:使用GaussDB(DWS)时,有时为了加快查询速度,需要对表建立索引.有时我们会遇到明明建立了索引,查询计划中却发现索引没有被使用的情况.本文将列举几种常见的场景和优化方法. 本文分享自华为云 ...
- iOS分发证书过期或手动吊销,会影响App的下架吗?
iOS distribution发布证书过期或者被手动revoke了app会被下架吗? 在距离distribution 证书过期一个月(或被手动revoke了)的时候会受到apple的邮件 编辑 ...
- 火山引擎 DataTester :让字节“跳动”起来的 A/B 实验平台
更多技术交流.求职机会,欢迎关注字节跳动数据平台微信公众号,回复[1]进入官方交流 火山引擎 DataTester 不仅对外提供服务,同时也是当前字节跳动内部所应用的 AB 实验平台. DataTes ...
- MyBatis 核心组件 —— Configuration
概述 Mybatis 的核心组件如下所示: Configuration:用于描述 MyBatis 的主配置信息,其他组件需要获取配置信息时,直接通过 Configuration 对象获取.除此之外,M ...
- STM32CubeMX教程16 DAC - 输出3.3V内任意电压
1.准备材料 开发板(正点原子stm32f407探索者开发板V2.4) STM32CubeMX软件(Version 6.10.0) keil µVision5 IDE(MDK-Arm) ST-LINK ...
- ChatGpt windows+mac os+linux三平台桌面版下载
1 前言 ChatGPT这段时间还是挺火的,有不了解的小伙伴可以看看这篇ChatGPT为何打响AI新时代的礼炮,一路火花带闪电[1],能简单的了解: 什么是ChatGPT ChatGPT为什么这么火 ...