python成长之路第三篇(4)_作用域,递归,模块,内置模块(os,ConfigParser,hashlib),with文件操作
打个广告欢迎加入linux,python资源分享群群号:478616847
目录:
1、作用域
2、递归
3、模块介绍
4、内置模块-OS
5、内置模块-ConfigParser
6、内置模块-hashlib
7、with文件操作
代码执行环境默认为3.5.1
一、作用域
(1)什么是作用域,官方来说作用域就是就是有不同的命名空间,就像下面的代码一样,a=1它的作用域是全局的,也在全局的命名空间当中,当函数 action中的a=2它就在局部的作用域中,也在局部的命名空间当中,运行一下下面的代码!
#!/usr/bin/env python
# -*- coding:utf-8 -*-
a = 1
def action():
a = 2 action()
print(a) #我们来看,上面的代码,当我们运行完成后我们得到的结果是1,这就是作用域的结果,明明是相同的变量但是a=2是在局部作用域当中所以当我们打印a的时候还是1。作用域
(2)那么我们如果想要在局部作用域中使用全局作用域中的变量和内容怎么办,python中的global语句是被用来声明全局的,在函数内可把全局变量重新赋值。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
a = 1
def action():
global a
a = 2
action()
print(a)作用域_2
二、递归
在此之前我们已经了解到了函数,还介绍了几个内置函数,那么我们想,我们在使用函数的时候都是来引用这个函数的函数名也就是像上面的例子中的action(),那么我们说,函数本身能否来去调用函数本身呢?答案是能,那么我们将这种调用的方法叫做递归!递归的意义在于提示代码执行效率,在这里我们来使用两个经典的例子
(1)阶乘
什么是阶乘,我们可以这么来看,有一个数是n,那么n的阶乘定义就是nx(n-1)x(n-2)x(n-3)…..x1
首先我们用普通的方法来去实现:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
n = 4
def factorial():
global n #设置全局变量
for i in range(1,n):
n*=i
factorial() #执行函数
print(n)递归_阶乘
这个很容易理解,因为是乘法运算所以先乘哪个都一样,所以我们使用range,生成1-n的数字,那么i就分别等于1,2,3因为range的特点最后的数字会比n小,然后在使用 n*=i也就是 n = n*i,最终就算出了结果我们来看递归版本:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
def factorial(n):
if n == 1:
return n
else:
return n*factorial(n-1)
c = factorial(5)
print(c)递归_阶乘
首先我们先不管它跟普通方法的代码量和优点,我们就先来理解这个递归,有条件的同学使用下pycharm断点来看下执行过程,好我们来解释下这个流程:
递归的返回值:
我们来看首先我们传入数字n = 5 ,然后进入函数,来执行函数自己调用自己的操作,那么我按照现在的理解来看,当调用第四次n等于了1,那么按照道理来说执行了return n,那么这时候按理来说c应该等于1,为什么c不等于1而是120呢?
我们来剖析递归的流程请看图
我们来解释一下1、当n = 5 的时候调用 n = 4 当n = 4的时候调用 n=3 一次类推 2、那么我们调用函数的返回值的表达式是return n*factorial(n-1)这样我们就
可以知道每次返回的是下一次的执行结果,n*factorial(n-1)就等于
5*(5-1)*(4-1)*(3-1) *(2-1)*1
3、因为python的特性所以每次返回的是计算出来的值然后就变成了 #这是最终结果的表达式,1是从n = 1返回上来的
fact(5) -> 5*factorial(4) -> 5*(4*(3*(2*factorial(1))))
-> 5*(4*(3*(2))) #将每一层的值计算出来返回上层
-> 5*(4*(6))
> 5*24 #顶层
-> 120 #最终c = 120流程剖析

(2)二分查找
上面的例子我们看不出递归如何提升了代码的执行效率那么我们看这个例子,什么是二分查找,我们假设这么个情景,我们需要判断一个数,是否在一组数中,假设这组数有 100个,那么我们需要挨个进行比较,可以使用for循环,或者if in,if in 也是使用的 for循环的机制来去找,那么加入这组数有10000个呢?并且要找的数在最后,那么岂不是要循环10000次?这样的方法太low,所以出来了二分查找。
递归写法:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
def seek(data,find_in): #定义一个函数,接收数组,和要找的值
mid = int(len(data)/2) #将这个数组除2
if len(data) >1: #判断剩余的数组是否大于1,如果大于1则进行二分算法否则就是没找到退出
if data[mid] > find_in: #判断这个除以2的数大于还是小于我们要找的数
seek(data[:mid],find_in)#如果大于则确定这个数在数组中间位置的右边,并将值传给这个函数,再次判断
elif data[mid] < find_in:
seek(data[mid:],find_in)#如果小于则确定这个数在数组中间位置的左边
else: #当这个数组不大于也不小于我们要找的数时,那就表示这个数组等于 我们要找的数
print("ok")#那么也就是说我们要找的数在这个数组中
else:
print("no")
datas = range(1,10000000)
seek(datas,1000000)二分查找
那么这样写就可以用少量的次数就能判断我们要找的数是否在数组里bisect模块python的标准库中bisect模块也是非常有效的实现二分查找,这个模块是判断数字实在数组中的哪里,如果数字小于等于数组中的最小的数小则返回0,数字大于等于数组中的最大的数则返回最大的数在列表中的位置,否则返回这个数在列表中的正确位置。bisect.bisect源码剖析:#!/usr/bin/env python
# -*- coding:utf-8 -*- #bisect.bisect
def bisect_right(a, x, lo=0, hi=None): #a是传入的列表,x是要找的数字,lo和hi不用传入 if lo < 0: #先判断 lo列表的长度,默认为0 ,这里是报错提示,传入的lo不能比0小
raise ValueError('lo must be non-negative')
if hi is None: #判断hi是否为空
hi = len(a) #如果为空则把列表a的长度赋值给hi
while lo < hi: #判断lo是否小于hi
mid = (lo+hi)//2 #如果不小于则 执行mid = (lo+hi)//2也就是取出列表中的中间数的标识符
if x < a[mid]: hi = mid #判断要找的数字是否小于传入列表的中间数,如果小于则hi = mid 也就是中间数的标识符然后再次循环
else: lo = mid+1 #只要要找的数不小于传入列表的中间数则执行这句 lo = mid+1,
return lo bisect = bisect_right #这句话表示向下兼容,意思是使用函数bisect.bisect就等于bisect.bisect_right
#推荐大家传入变量来去进行pycharm的断点看看执行流程bisect.bisrct
三、模块介绍
首先什么是模块,模块的定义呢在这里就是实现某个功能的代码集合
(1)模块分为三种:
- 自定义模块
- 内置模块
- 开源模块
自定义模块,就是我们自己来写功能,然后其他的代码来去调用我们的这个功能
例子: 就像下面的图一样将不同的功能分开
内置模块,就是python自带的一些功能
开源模块,就是别人开发好的方法功能,我们安装到我们的python中使用
(安装方法)
在linux下安装:
在使用源码安装时,需要使用到gcc编译和python开发环境
yum install gcc
yum install python-devel下载源码
解压源码
进入目录
编译源码 python setup.py build
安装源码 python setup.py install

(2)导入模块
- import
- from xxx import xxx
- from xxx import xxx as xxx
- from xxx import *
import,和from xxx import xxx
用于导入相应的模块,模块其实就是一些函数和类的集合文件,它能实现一些相应的功能,那么他们的区别是什么
例子:
这里以接下来要说的os模块为例,os模块下有rename方法是用来重命名文件或者目录的,我们清晰的看到用from导入的模块后我们直接就可以使用rename方法,而import就需要我们是os.rename来使用这个rename方法(也就是需要指定模块名)
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from os import rename
rename('method.py','test.py') import os
os.rename('method.py','test.py') #这里推荐import来去导入因为这样可以使你的程序更加易读,也可以避免名称的冲突import和fromxximport区别
from xxx import xxx as xxx 用于起个别名
#!/usr/bin/env python
# -*- coding:utf-8 -*-
from os import rename as newname newname('method.py','test.py') import os as os_name os_name.rename('method.py','test.py')
#最后一个就不用解释了相信大家都明白了。别名
(3)sys.path
sys.path这是什么鬼?我们发现没有在系统自带的模块中我们只需要import就可以直接导入,然而我们自己写的模块就只能导入当前路径下的,这就是因为这个sys.path下面存储着系统查找模块时的路径,所以喽就能系统自带的模块了,就跟linux查找命令一样的道理,那么我们可不可以把其他路径加入到这里面呢,让我们好导入其他目录下的自定义模块,这里是肯定可以的,我们使用sys.path.append('路径')来去添加
python模块中有一个包的概念,就是说目录下有一个 __init__.py文件那么我们就称为这个目录为包
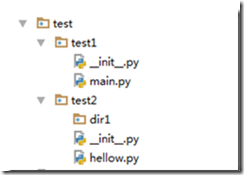
例子:
首先我们常见的目录结构是一个文件夹下面接着好几个包就像下面,每个包中存着各自要实现的功能代码
我们使用下面两个方法将test1中的main文件可以导入test目录下的任意包中的方法:
- os.path.abspath() 这个功能是获取当前文件下的目录
- sys.path.append('路径') 这个方法是添加系统默认查找路径
那么我们在main.py文件中就可以这么写:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import os
import sys
PATH = os.path.dirname(os.path.dirname(__file__)) #因为我们这里的目录结构是二层目录所以我们就需要获取当前文件的目录的目录,这样才可以获取到我们的父目录 testsys.path.append(PATH)#将获取的路径添加到系统默认查找路径中,然后我们就可以使用test目录下的包中的方法了 if __name__ == "__main__": #这句话表示这个文件是个入口
from test2 import hellow #导入这个包中的这个文件
hellow.hello() #执行这个文件中的hello函数 hellow.py内容:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
def hello():
print("How are you doing tomorrow!!")main和hellow文件内容
四、内置模块-OS
这个模块提供了一种便携式的方式使用操作系统来处理目录和文件相关的功能。
(1)os.getcwd()
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#获取当前工作目录,即当前python脚本工作的目录路径 import os
print(os.getcwd())
#结果为E:\pycharm\exercisegetwcd
(2)os.chdir("dirname")
#!/usr/bin/env python
# -*- coding:utf-8 -*- #改变当前脚本工作目录;相当于shell下cd
#请在linux下执行 import os
path = "/tmp" # 查看当前工作目录
retval = os.getcwd()
print ("当前工作目录为 %s" % retval) # 修改当前工作目录
os.chdir( path )
# 查看修改后的工作目录
retval = os.getcwd()
print ("目录修改成功 %s" % retval)chdir
(3)os.curdir
返回当前目录: 返回值为('.')
(4)os.pardir
获取当前目录的父目录字符串名:返回值为('..')
(5)os.makedirs('dir1/dir2')
可生成多层递归目录余mkdir –d /dir1/dir2
(6)os.removedirs('dir1/dir2')
若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推,如果在dir1下面建立个文件dir1就不会被删除
(7)os.mkdir('dir')
生成单级目录;相当于shell中mkdir dir
(8)os.rmdir('dir')
删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dir
(9)os.listdir('dirname')
列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
(10)os.remove()
删除一个文件
(11)os.rename("oldname","newname")
重命名文件/目录
(12)os.stat('path/filename')
获取文件/目录信息
(13)os.sep
输出操作系统特定的路径分隔符,win下为"\\",Linux下为"/"
(14)os.linesep
输出当前平台使用的行终止符,win下为"\t\n",Linux下为"\n"
(15)os.pathsep
输出用于分割文件路径的字符串
(16)os.name
输出字符串表示当前使用平台。win->'nt'; Linux->'posix'
(17)os.system("bash command")
#!/usr/bin/env python
# -*- coding:utf-8 -*- #运行shell命令,直接显示 import os
print(os.system("ping www.baidu.com"))system
(18)os.environ
获取系统环境变量
(19)os.path.abspath(path)
#!/usr/bin/env python
# -*- coding:utf-8 -*- #返回path规范化的绝对路径
import os
print(os.path.abspath('hellow.py')abspath
(20)os.path.split(path)
#!/usr/bin/env python
# -*- coding:utf-8 -*- #将path分割成目录和文件名二元组返回,不会判断文件或者目录是否存在 import os
fileName=r"C:\Users\SS\test.txt"
print(os.path.split(fileName))split
(21)os.path.dirname(path)
#!/usr/bin/env python
# -*- coding:utf-8 -*- #去掉文件名,返回目录路径
import os
print(os.path.dirname(os.__file__)(22)os.path.basename(path)
返回path最后的文件名。
#!/usr/bin/env python
# -*- coding:utf-8 -*-
#如果path以/或\结尾,那么就会返回空值,即os.path.split(path)的第二个元素 import os
print(os.path.basename(r"d\aaa\aa.txt") )basebame
(23)os.path.exists(path)
如果path存在,返回True;如果path不存在,返回False
(24)os.path.isabs(path)
如果path是绝对路径,返回True
(25)os.path.isfile(path)
如果path是一个存在的文件,返回True。否则返回False
(26)os.path.isdir(path)
如果path是一个存在的目录,则返回True。否则返回False
(27)os.path.join(path1[, path2[, ...]])
#!/usr/bin/env python
# -*- coding:utf-8 -*- #将多个路径组合后返回,第一个绝对路径之前的参数将被忽略 imprort os os.path.join('b','b','ss.txt')
#输出#‘b/b/ss.txt’join
(28)os.path.getatime(path)
返回path所指向的文件或者目录的最后存取时间
(29)os.path.getmtime(path) 返回path所指向的文件或者目录的最后修改时间
注!28和29返回的时间是unix时间戳,可以使用detetime库来处理这个时间戳
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import datetime, os
a = os.path.getmtime('/')
aa = datetime.datetime.fromtimestamp(t)
aaa = aa.strftime('%Y') # %Y是时间处理的格式,只能返回年份。更多格式写法请百度
print (aaa)datetime
五、内置模块-ConfigParser
这个内置模块呢一般用处用来做配置文件的操作,那么这个模块能够处理什么样的配置文件呢?我们来看下
语法
读操作
-read(filename) 直接读取ini文件内容
-sections() 得到所有的section,并以列表的形式返回
-options(section) 得到该section的所有option
-items(section) 得到该section的所有键值对
-get(section,option) 得到section中option的值,返回为string类型
-getint(section,option) 得到section中option的值,返回为int类型写操作
-add_section(section) 添加一个新的section
-set( section, option, value) 对section中的option进行设置例 :
先在脚本目录下创建aaa文件内容如下
[a]
one = 1
two = ins [b]
one = 2
two = ins示例代码#!/usr/bin/env python
# -*- coding:utf-8 –*-
#首先我们加载模块
import configparser
#创建一个config对象 c = configparser.ConfigParser()
#读取aaa文件
c.read("aaa")
#读取aaa中的section ['a', 'b']
print(c.sections())
#读取aaa中的section 是a 的option(选项的意思)
print(c.options('a')) #['one', 'two']
#读取aaa中的section 是a 的所有键值对(选项和值)
print(c.items('a'))#[('one', '1'), ('two', 'int')]
#读取aaa中的section 是a的option是one的值,返回的是str类型
print(c.get('a','one'))
print(type(c.get('a','one'))) #
#读取aaa中的section 是a的option是one的值,返回的是int类型
print(c.getint('a','one'))
print(type(c.getint('a','one'))) #写:
#!/usr/bin/env python
# -*- coding:utf-8 –*-
#首先我们加载模块
import configparser
#创建一个config对象 c = configparser.ConfigParser()
#读取aaa文件
c.read("aaa")
#读取aaa中的section ['a', 'b']
print(c.sections())
#读取aaa中的section 是a 的option(选项的意思)
print(c.options('a')) #['one', 'two']
#读取aaa中的section 是a 的所有键值对(选项和值)
print(c.items('a'))#[('one', '1'), ('two', 'int')]
#读取aaa中的section 是a的option是one的值,返回的是str类型
print(c.get('a','one'))
print(type(c.get('a','one'))) #
#读取aaa中的section 是a的option是one的值,返回的是int类型
print(c.getint('a','one'))
print(type(c.getint('a','one'))) #官方入口
六、内置模块-hashlib
hashlib是个加密模块,主要提供了 SHA1, SHA224, SHA256, SHA384, SHA512 ,MD5 算法
语法:
#!/usr/bin/env python
# -*- coding:utf-8 -*- import hashlib
c = "test"
#这里要进行转换编码
c = c.encode(encoding='utf-8')
# ######## md5 ######## hash = hashlib.md5()
hash.update(c)
print(hash.hexdigest()) # ######## sha1 ######## hash = hashlib.sha1()
hash.update(c)
print (hash.hexdigest()) # ######## sha256 ######## hash = hashlib.sha256()
hash.update(c)
print (hash.hexdigest()) # ######## sha384 ######## hash = hashlib.sha384()
hash.update(c)
print (hash.hexdigest()) # ######## sha512 ########添加自定义的 hash = hashlib.sha512()
hash.update(c)
print (hash.hexdigest())hashlib
上面的算法虽然比较强,但是通过撞库仍然可以破解,所以为了防止这样,还可以在加密算法中key来做加密
#!/usr/bin/env python
# -*- coding:utf-8 -*-
import hashlib
c = "test"
c = c.encode(encoding='utf-8')
key = "aaa"
key = key.encode(encoding='utf-8')
# ######## md5 ########
hash = hashlib.md5(key)
hash.update(c)
print(hash.hexdigest())加key
hmac模块
python 还有一个 hmac 模块,它内部对我们创建 key 和 内容 再进行处理然后再加密#!/usr/bin/env python
# -*- coding:utf-8 -*- import hmac
c = "test"
c = c.encode(encoding='utf-8')
key = "aaa"
key = key.encode(encoding='utf-8')
hash = hmac.new(key)
hash.update(c)
print(hash.hexdigest())hmac语法
七、with文件操作
对于我们来说普通的操作文件每次执行完文件还要给他加上关闭的语句这样非常麻烦,所以python2.7以后就增加了with
with又支持同时对多个文件的上下文进行管理所以非常的方便
例:
#!/usr/bin/env python
# -*- coding:utf-8 -*-
with open("aaa") as test1 ,open("ss","w") as test2:
test2.write(test1.read()) #读出文件aaa的内容写入文件sswith
python成长之路第三篇(4)_作用域,递归,模块,内置模块(os,ConfigParser,hashlib),with文件操作的更多相关文章
- python成长之路第三篇(1)_初识函数
目录: 函数 为什么要使用函数 什么是函数 函数的返回值 文档化函数 函数传参数 文件操作(二) 1.文件操作的步骤 2.文件的内置方法 函数: 一.为什么要使用函数 在日常写代码中,我们会发现有很多 ...
- python成长之路第三篇(3)_内置函数及生成器迭代器
打个广告欢迎加入linux,python资源分享群群号:478616847 目录: 1.lambda表达式 2.map内置函数 3.filter内置函数 4.reduce内置函数 5.yield生成器 ...
- python成长之路第三篇(2)_正则表达式
打个广告欢迎加入linux,python资源分享群群号:478616847 目录: 1.什么是正则表达式,python中得正则简介 2.re模块的内容 3.小练习 一.什么是正则表达式(re) 正则表 ...
- (转)Python成长之路【第九篇】:Python基础之面向对象
一.三大编程范式 正本清源一:有人说,函数式编程就是用函数编程-->错误1 编程范式即编程的方法论,标识一种编程风格 大家学习了基本的Python语法后,大家就可以写Python代码了,然后每个 ...
- python成长之路【第九篇】:网络编程
一.套接字 1.1.套接字套接字最初是为同一主机上的应用程序所创建,使得主机上运行的一个程序(又名一个进程)与另一个运行的程序进行通信.这就是所谓的进程间通信(Inter Process Commun ...
- python成长之路【第二篇】:列表和元组
1.数据结构数据结构是通过某种方式(例如对元素进行编号)组织在一起的数据元素的集合,这些数据元素可以是数字或者字符,甚至可以是其他数据结构.在Python中,最基本的数据结构是序列(sequence) ...
- python成长之路【第一篇】:python简介和入门
一.Python简介 Python(英语发音:/ˈpaɪθən/), 是一种面向对象.解释型计算机程序设计语言. 二.安装python windows: 1.下载安装包 https://www.pyt ...
- python成长之路——第三天
一.collections系列: collections其实是python的标准库,也就是python的一个内置模块,因此使用之前导入一下collections模块即可,collections在pyt ...
- 我的Python成长之路---第三天---Python基础(12)---2016年1月16日(雾霾)
四.函数 日常生活中,要完成一件复杂的功能,我们总是习惯把“大功能”分解为多个“小功能”以实现.在编程的世界里,“功能”可称呼为“函数”,因此“函数”其实就是一段实现了某种功能的代码,并且可以供其它代 ...
随机推荐
- 黑马程序员——读取Plist文件
-iOS培训,iOS学习-------型技术博客.期待与您交流!------------ 读取Plist文件 一:新建一个plist文件,并将plist文件数据填入plist文件中,这里pli ...
- WordPress插件开发记录
1.a标签在新的网页中打开内容 <a href="网址" target="_blank"></a> 2.PDO的$re ...
- BZOJ 2007 海拔
http://www.lydsy.com/JudgeOnline/problem.php?id=2007 思路: 显然海拔是一片0,另一片1,答案就是01的分界线的流量. 本题中的图是平面图,所以求最 ...
- keil C 应注意的几个问题
我们使用Keil C调试某系统时积累的一些经验 1.在Windows2000下面,我们可以把字体设置为Courier,这样就可以显示正常.2.当使用有片外内存的MCU(如W77E58,它有1K片外内存 ...
- Intel 凌动 D525 产品参数Intel 凌动 Z3735F 产品参数
https://item.taobao.com/item.htm?spm=a230r.1.14.8.kauehT&id=40450541158&ns=1&abbucket=19 ...
- 关于Yeoman使用的总结
Yeoman由三部分组成 Yo 用于项目构建. Grunt 用于项目管理,任务制定. Bower 用于项目依赖管理. 经过一段时间的使用,对这些东西有了一些个人总结: 总体上说这些内容学习曲线略高,不 ...
- cf486A Calculating Function
A. Calculating Function time limit per test 1 second memory limit per test 256 megabytes input stand ...
- Mysql 创建用户并对其赋予操作权限
授权命令GRANT 语句的语法如下: GRANT privileges (columns) ON what TO user IDENTIFIEDBY "password" WITH ...
- sem_timedwait的用法
#include <semaphore.h> int sem_timedwait(sem_t *sem, const struct timespec *abs_timeout); Link ...
- 如何在cmd窗口启动Tomcat
平时,一般使用tomcat/bin/startup.bat目录在windows环境启动Tomcat,或者使用IDE配置后启动. 下面来简单介绍下如果在cmd窗口直接输入命令启动Tomcat: 1.将t ...