协方差cov
摘录wiki如下(红色字体是特别标注的部分):
http://zh.wikipedia.org/wiki/%E5%8D%8F%E6%96%B9%E5%B7%AE
协方差
协方差(Covariance)在概率论和统计学中用于衡量两个变量的总体误差。而方差是协方差的一种特殊情况,即当两个变量是相同的情况。
期望值分别为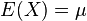 与
与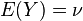 的两个实数随机变量X 与Y 之间的协方差定义为:
的两个实数随机变量X 与Y 之间的协方差定义为:
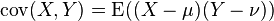 ,
,
其中E是期望值。它也可以表示为:
 ,
,
直观上来看,协方差表示的是两个变量的总体的误差,这与只表示一个变量误差的方差不同。 如果两个变量的变化趋势一致,也就是说如果其中一个大于自身的期望值,另外一个也大于自身的期望值,那么两个变量之间的协方差就是正值。 如果两个变量的变化趋势相反,即其中一个大于自身的期望值,另外一个却小于自身的期望值,那么两个变量之间的协方差就是负值。
如果X 与Y 是统计独立的,那么二者之间的协方差就是0,这是因为
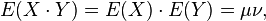
但是反过来并不成立,即如果X 与Y 的协方差为0,二者并不一定是统计独立的。只能说是线性无关
取决于协方差的相关性η(这东西又叫皮尔逊系数,参见另一篇博文)
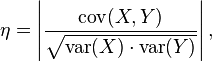 =E(XY)/√EX2√EY2
=E(XY)/√EX2√EY2
更准确地说是线性相关性,是一个衡量线性独立的无量纲数,其取值在[0,+1]之间。相关性η = 1时称为“完全线性相关”,此时将Yi对Xi作Y-X 散点图,将得到一组精确排列在直线上的点;相关性数值介于0到1之间时,其越接近1表明线性相关性越好,作散点图得到的点的排布越接近一条直线。
相关性为0(因而协方差也为0)的两个随机变量又被称为是不相关的,或者更准确地说叫作“线性无关”、“线性不相关”,这仅仅表明X 与Y 两随机变量之间没有线性相关性,并非表示它们之间一定没有任何内在的(非线性)函数关系,和前面所说的“X、Y二者并不一定是统计独立的”说法一致。
如果要用公式写一下的话,注意,当X,Y是线性相关的变量时(均去中心化,那么Y和X就是倍数关系),Y=aX。截距b被去中心化了
对η还是要再说明一下:这个东西是衡量X,Y的线性相关程度的。也可以通俗的讲,η衡量的是X,Y的关系有“多像”线性相关。也就是说它是从线性相关的角度来观察X和Y的。如果XY就是线性相关的,那自然η就是1,确实“很像”;但如果XY是其他相关,比如对数相关y=log(x)y之类的,η也是衡量这个对数相关有“多像”线性相关。更深究一点,衡量有“多像”这个事情,实际上是衡量Y与X的变化趋势是否保持一致,比如x扩大几倍,y也扩大几倍。倍数越不一样说明越不像线性相关。
属性
如果X 与Y 是实数随机变量,a 与b 不是随机变量,那么根据协方差的定义可以得到:
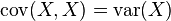 ,
,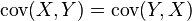 ,
, ,
,
对于随机变量序列X1, ..., Xn与Y1, ..., Ym,有
 ,
,
对于随机变量序列X1, ..., Xn,有
 。
。
协方差矩阵[编辑]
分别为m 与n 个标量元素的列向量随机变量X 与Y,二者对应的期望值分别为μ与ν,这两个变量之间的协方差定义为m×n 矩阵

两个向量变量的协方差cov(X, Y)与cov(Y, X)互为转置矩阵。
协方差cov的更多相关文章
- 从多个角度来理解协方差(covariance)
起源:协方差自然是由方差衍生而来的,方差反应的是一个变量(一维)的离散程度,到二维了,我们可以对每个维度求其离散程度,但我们还想知道更多.我们想知道两个维度(变量)之间的关系,直观的举例就是身高和体重 ...
- python cov()
在PCA中涉及到了方差var和协方差cov,下面详细了解这两个函数的用法.numpy中var和cov函数求法和MATLAB中var和cov函数求法类似. 首先均值,样本方差,样本协方差公式分别为 其中 ...
- R语言实战(三)基本图形与基本统计分析
本文对应<R语言实战>第6章:基本图形:第7章:基本统计分析 =============================================================== ...
- 【总结】matlab求两个序列的相关性
首先说说自相关和互相关的概念. 自相关 在统计学中的定义,自相关函数就是将一个有序的随机变量系列与其自身作比较.每个不存在相位差的系列,都与其都与其自身相似,即在此情况下,自相关函数值最大. 在信号 ...
- R--相关分布函数、统计函数的使用
分布函数家族: *func()r : 随机分布函数d : 概率密度函数p : 累积分布函数q : 分位数函数 func()表示具体的名称如下表: 例子 #r : 随机分布函数 #d : 概率密度函数 ...
- R与数据分析旧笔记(五)数学分析基本
R语言的各种分布函数 rnorm(n,mean=0,sd=1)#高斯(正态) rexp(n,rate=1)#指数 rgamma(n,shape,scale=1)#γ分布 rpois(n,lambda) ...
- 皮尔逊相似度计算的例子(R语言)
编译最近的协同过滤算法皮尔逊相似度计算.下顺便研究R简单使用的语言.概率统计知识. 一.概率论和统计学概念复习 1)期望值(Expected Value) 由于这里每一个数都是等概率的.所以就当做是数 ...
- 数据分析之pandas教程-----概念篇
目录 1 pandas基本概念 1.1 pandas数据结构剖析 1.1.1 Series 1.1.2 DataFrame 1.1.3 索引 1.1.4 pandas基本操作 1.1.4. ...
- 皮尔森相似度计算举例(R语言)
整理了一下最近对协同过滤推荐算法中的皮尔森相似度计算,顺带学习了下R语言的简单使用,也复习了概率统计知识. 一.概率论和统计学概念复习 1)期望值(Expected Value) 因为这里每个数都是等 ...
随机推荐
- 软件体系结构经典问题——KWIC的分析和解决
KWIC作为一个早年间在ACM的Paper提出的一个问题,被全世界各个大学的软件设计课程奉为课堂讲义或者作业的经典.(From Wiki,FYI,D. L. Parnas uses a KWIC In ...
- Java中Array.sort()的几种用法
****************************************************** * 精品书籍推荐:<Java从入门到经通> * 本书系统全面.浅显易懂,非常适 ...
- hdu - 4651 - Partition
题意:把一个整数N(1 <= N <= 100000)拆分不超过N的正整数相加,有多少种拆法. 题目链接:http://acm.hdu.edu.cn/showproblem.php?pid ...
- Android学习总结——实现Home键功能
实现Home键功能简而言之就是回到桌面,让Activity不销毁,程序后台运行. 实现方法: Intent intent= new Intent(Intent.ACTION_MAIN); intent ...
- Hard Process(二分)
Hard Process Time Limit:1000MS Memory Limit:262144KB 64bit IO Format:%I64d & %I64u Submi ...
- 《你必须知道的495个C语言问题》知识笔记及补充
1. extern在函数声明中是什么意思? 它能够用作一种格式上的提示表明函数的定义可能在还有一个源文件里.但在 extern int f(); 和 int f(); 之间并没有实质的差别. 补充:e ...
- 【二分查找+优化O(n)】【续UVA1121】Subsequence
之前的二分答案做法 http://blog.csdn.net/zy691357966/article/details/40212215 二分查找做法: 我们首先试试只枚举终点.对于终点j,我们的目标是 ...
- 关于asp.net简单的下载问题
关于asp.net的下载,只需将打开相应的文件路径就能在浏览器上实现下载功能,比如项目的同级目录上有一个文件 苍老师.zip<a href="苍老师.zip">< ...
- mysql命令学习笔记(1):show table status like 'user';显示表的相关信息
show table status like 'user';显示表的相关信息 +------------+--------+---------+------------+------+-------- ...
- JQ 替换节点
<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN" "http://www.w3.org/ ...