如何利用BeautifulSoup选择器抓取京东网商品信息
昨天小编利用Python正则表达式爬取了京东网商品信息,看过代码的小伙伴们基本上都坐不住了,辣么多的规则和辣么长的代码,悲伤辣么大,实在是受不鸟了。不过小伙伴们不用担心,今天小编利用美丽的汤来为大家演示一下如何实现京东商品信息的精准匹配~~
HTML文件其实就是由一组尖括号构成的标签组织起来的,每一对尖括号形式一个标签,标签之间存在上下关系,形成标签树;因此可以说Beautiful Soup库是解析、遍历、维护“标签树”的功能库。
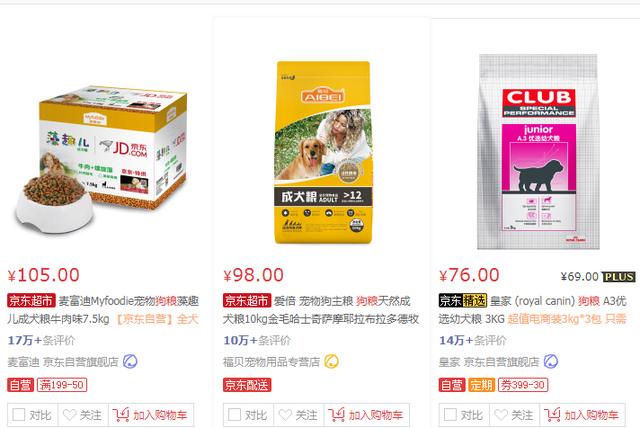
首先进入京东网,输入自己想要查询的商品,向服务器发送网页请求。在这里小编仍以关键词“狗粮”作为搜索对象,之后得到后面这一串网址:https://search.jd.com/Search?keyword=%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数的意思就是我们输入的keyword,在本例中该参数代表“狗粮”,具体详情可以参考Python大神用正则表达式教你搞定京东商品信息。所以,只要输入keyword这个参数之后,将其进行编码,就可以获取到目标URL。之后请求网页,得到响应,尔后利用bs4选择器进行下一步的数据采集。
商品信息在京东官网上的部分网页源码如下图所示:

仔细观察源码,可以发现我们所需的目标信息是存在
直接上代码,如下图所示:
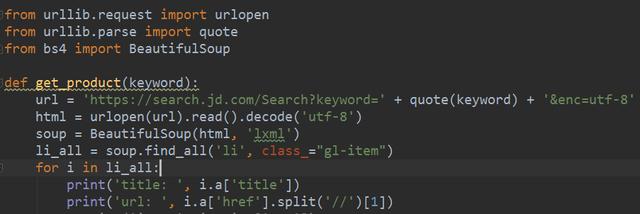
通常URL编码的方式是把需要编码的字符转化为%xx的形式,一般来说URL的编码是基于UTF-8的,当然也有的于浏览器平台有关。在Python的urllib库中提供了quote方法,可以实现对URL的字符串进行编码,从而可以进入到对应的网页中去。
之后利用美丽的汤去提取目标信息,如商品的名字、链接、图片和价格,具体的代码如下图所示:
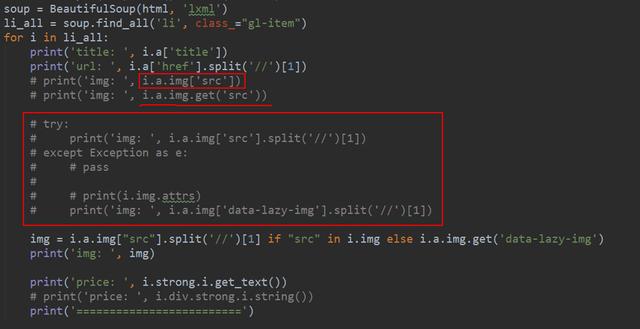
在本例中,有个地方需要注意,部分图片的链接是空值,所以在提取的时候需要考虑到这个问题。其解决方法有两个,其一是如果使用img['src']会有报错产生,因为匹配不到对应值;但是使用get['src']就不会报错,如果没有匹配到,它会自动返回None。此外也可以利用try+except进行异常处理,如果匹配不到就pass,小伙伴们可以自行测试一下,这个代码测速过程在上图中也有提及哈。使用get方法获取信息,是bs4中的一个小技巧,希望小伙伴们都可以学以致用噢~~~
最后得到的效果图如下所示:
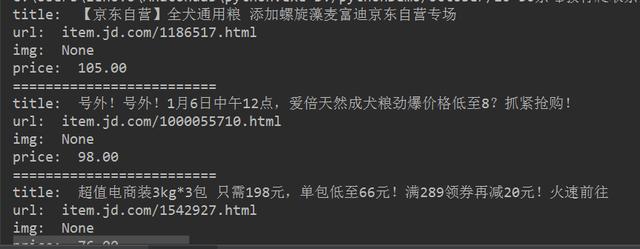
新鲜的狗粮出炉咯~~~
小伙伴们,有没有发现利用BeautifulSoup来获取目标信息比正则表达式要简单一些呢?
想学习更多Python网络爬虫与数据挖掘知识,可前往专业网站:http://pdcfighting.com/
如何利用BeautifulSoup选择器抓取京东网商品信息的更多相关文章
- 如何利用CSS选择器抓取京东网商品信息
前几天小编分别利用Python正则表达式.BeautifulSoup.Xpath分别爬取了京东网商品信息,今天小编利用CSS选择器来为大家展示一下如何实现京东商品信息的精准匹配~~ CSS选择器 目前 ...
- 如何利用Xpath抓取京东网商品信息
前几小编分别利用Python正则表达式和BeautifulSoup爬取了京东网商品信息,今天小编利用Xpath来为大家演示一下如何实现京东商品信息的精准匹配~~ HTML文件其实就是由一组尖括号构成的 ...
- 使用selenium+BeautifulSoup 抓取京东商城手机信息
1.准备工作: chromedriver 传送门:国内:http://npm.taobao.org/mirrors/chromedriver/ vpn: selenium BeautifulSo ...
- 使用Pyquery+selenium抓取淘宝商品信息
配置文件,配置好数据库名称,表名称,要搜索的产品类目,要爬取的页数 MONGO_URL = 'localhost' MONGO_DB = 'taobao' MONGO_TABLE = 'phone' ...
- 003.[python学习] 简单抓取豆瓣网电影信息程序
声明:本程序仅用于学习爬网页数据,不可用于其它用途. 本程序仍有很多不足之处,请读者不吝赐教. 依赖:本程序依赖BeautifulSoup4和lxml,如需正确运行,请先安装.下面是代码: #!/us ...
- php+phpquery简易爬虫抓取京东商品分类
这是一个简单的php加phpquery实现抓取京东商品分类页内容的简易爬虫.phpquery可以非常简单地帮助你抽取想要的html内容,phpquery和jquery非常类似,可以说是几乎一样:如果你 ...
- 简单的抓取淘宝关键字信息、图片的Python爬虫|Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇)
Python3中级玩家:淘宝天猫商品搜索爬虫自动化工具(第一篇) 淘宝改字段,Bugfix,查看https://github.com/hunterhug/taobaoscrapy.git 由于Gith ...
- 【爬虫】利用Scrapy抓取京东商品、豆瓣电影、技术问题
1.scrapy基本了解 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架.可以应用在包括数据挖掘, 信息处理或存储历史数据等一系列的程序中.其最初是为了页面抓取(更确切来说,网络抓 ...
- java网络爬虫----------简单抓取慕课网首页数据
© 版权声明:本文为博主原创文章,转载请注明出处 一.分析 1.目标:抓取慕课网首页推荐课程的名称和描述信息 2.分析:浏览器F12分析得到,推荐课程的名称都放在class="course- ...
随机推荐
- 使用sys模块写一个软件安装进度条
import sys,time for i in range(50): sys.stdout.write('#') sys.stdout.flush() #强制刷新将内存中的文件写一条,输出一条. t ...
- centos6.X修改ssh默认端口号
先查看下服务器端口号范围: # sysctl -a|grep ip_local_port_range net.ipv4.ip_local_port_range = 32768 61000 新ss ...
- 用两张图告诉你,为什么你的App会卡顿?
有什么料? 从这篇文章中你能获得这些料: 知道setContentView()之后发生了什么? 知道Android究竟是如何在屏幕上显示我们期望的画面的? 对Android的视图架构有整体把握. 学会 ...
- 国际站中国区,孟买上Redis 4.0 集群版
信息摘要: 国际站中国区,孟买上线Redis 4.0 集群版适用客户: 所有用户版本/规格功能: redis 4.0 集群版产品文档: https://www.alibabacloud.com/hel ...
- DP 60题 -3 HDU1058 Humble Numbers DP求状态数的老祖宗题目
Humble Numbers Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others) T ...
- mock-server 之 mock 接口测试
1.mock 介绍 mock 除了用在单元测试过程中,还有一个用途,当前端开发在开发页面的时候,需要服务端提供 API 接口,此时服务端没开发完成,或者说没搭建测试环境,这个时候前端开发会自己 moc ...
- 数据库SQL---范式
1.数据冗余导致的问题:冗余存储.更新异常.插入异常.删除异常. 2.函数依赖:一种完整性约束. 在关系模式r(R)中,α属于R,β属于R. 1)α函数确定β(β函数依赖于α):记作α→β,对于任意合 ...
- 《Docker从入门到跑路》之多阶段构建
多阶段构建就是在一个Dokcerfile中定义多个FROM,每个FROM都可以使用不同的基础镜像,并表示开始一个新的构建阶段,我们可以很方便的将一个阶段的文件复制到另外一个阶段中,在最终的阶段保存你需 ...
- redis系列之3----redis高级应用(主从、事务与锁、持久化)
文章主目录 安全性设置 主从复制 事务与锁 持久化机制 发布以及订阅消息 上文<详细讲解redis数据结构(内存模型)以及常用命令>介绍了redis的数据类型以及常用命令,本文我们来学习下 ...
- keepalived高可用服务配置管理
实验环境: 主机 ipaddress 服务 备注 k8s-master1 10.0.0.63 nginx k8s-master2 10.0.0.64 nginx k8s-node1 10.0.0.65 ...