Python 自动登录哔哩哔哩(2captcha打码平台)
前言
研究爬虫的各位小伙伴都知道,需要登录才能获取信息的网站,是比较难爬的,原因就是在于,现在各大网站为了反爬,都加入了图片验证码,滑动验证码之类的干扰
本篇就针对哔哩哔哩的滑动验证码进行讲解和破解
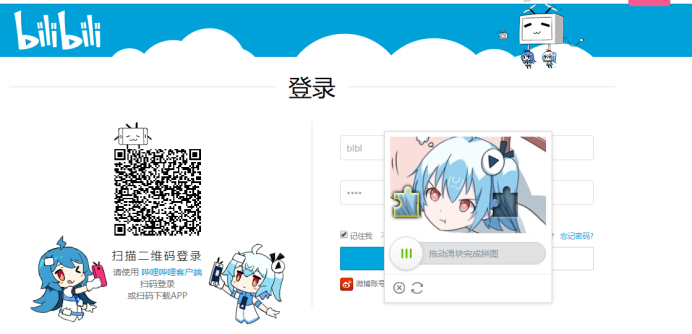
关于破解滑动验证究竟是自己使用机器学习还是第三方服务讨论
先说一下个人观点:本人作为一个爬虫老鸟,如果只是为了使用,非常建议使用第三方服务,为什么呢,来听我细细分析,
现在是2020年了,混IT的都知道,现在大红大紫的热门行业是哪个,肯定都说机器学习,都想入门机器学习,但是很多人还没入门就挂了,这是为什么呢,因为入门机器学习,是需要有高数的底子的,可不是以前学一个语言,会常用逻辑就可以入门的了,这也是为什么到现在为止,依然还有非常大的机器学习人才缺口,再说一下为什么自己做爬虫不建议使用机器学习,三个字,玩不起,
首先,你需要有大量的数据,然后再有一个不错的主机用于训练,再然后,就是需要你有高数的底子,如果这三个都有,并且学习了机器学习,你才可以勉强破解滑动验证码,并且不敢保证自己训练的准确度,
这就是我推荐使用第三方接口的原因,因为第三方接口就是专门做这类机器学习的,它们有强大的人力物力专门做破解各种验证码,并且识别率非常高,现在一般都是90%以上,价格还香,何乐不为了,自己做是头发掉的少还是加不够多
当然,并不是说我不让学习机器学习,毕竟现在是一个人工智能时代,如果已有不错的数学基础,并且有很强大兴趣,在工作之余,可以入坑机器学习的,毕竟趋势如此,
本人的观点是,如果是爬虫遇到了滑动验证码,直接使用第三方平台,如果你很有兴趣,继续需坑机器学习,
本文使用的第三方服务:https://2captcha.com/
根据本人测试,是目前识别率最高的平台,价格还行,3美元几百次吧
所需工具
En.... 我们这里不需要 selenium,2captcha打码平台很神奇,我们只需要 requests 模块就可以啦,
2captcha打码平台参数分析
既然我们选择了第三方平台,我们务必要看一下人家的文档,下面我们就2captcha平台的极验破解,看一下人家的操作
首先打开人家官网
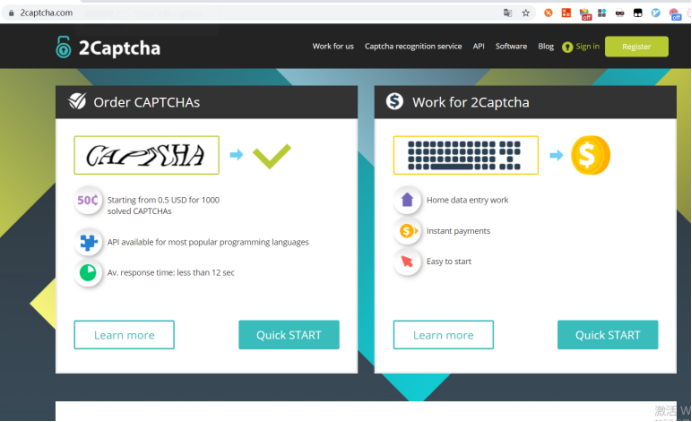
嗯...纯英文,我也看不懂..怎么办呢,别着急,我带你们一步一步分析主要功能
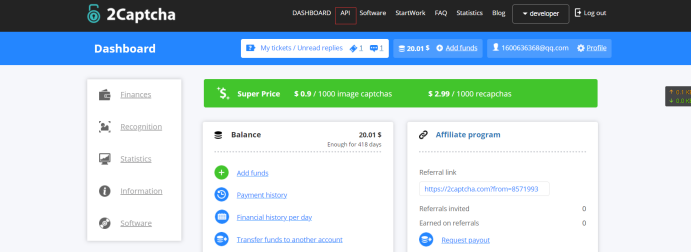
登录账号
登录完成后,会自动跳到主页
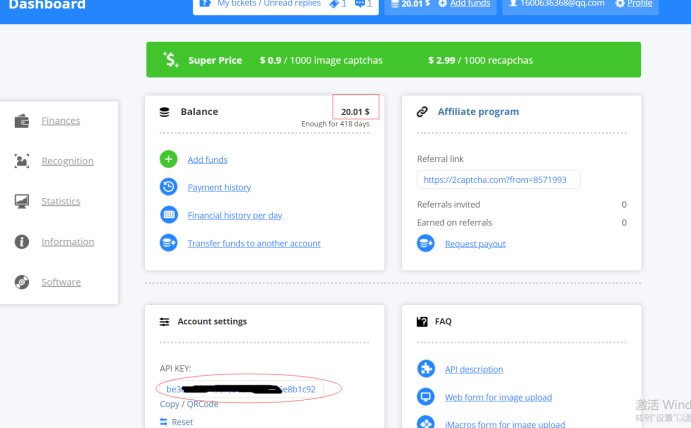
红色圈起来的地方表示剩余多少钱,没有钱的话记得要氪金,否则是不能用滴,氪金过程这里就不多做解释了哈,问题不大
蓝色圈起来的地方表示这是你的唯一key,每次请求要带上这个key的,所以要保管好
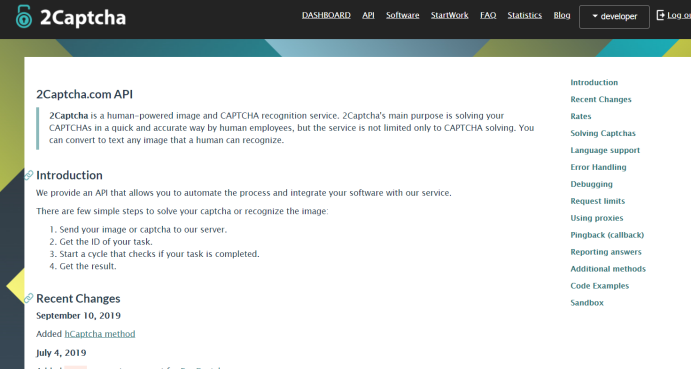
进入主题,研究文档
点击红色圈的地方,API,一般API都是文档,let's go
En....什么玩意..完全看不懂,别慌,往下滑
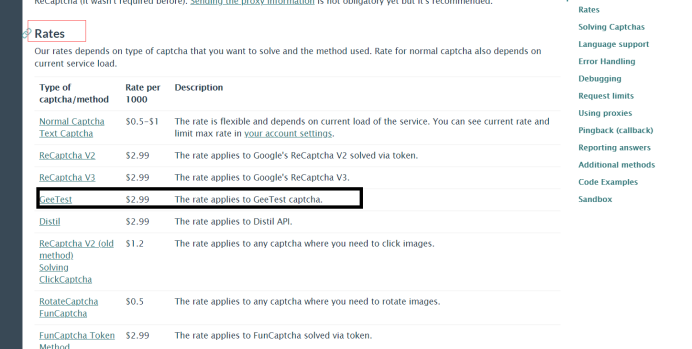
滑动到Rates,我们能看到一个列表,我们要解决的就是极验(GeeTest),所以我们只看GeeTest就好了
点击GeeTest
Go

好了,已经懵逼了,但是,怕什么,我们有翻译!!!
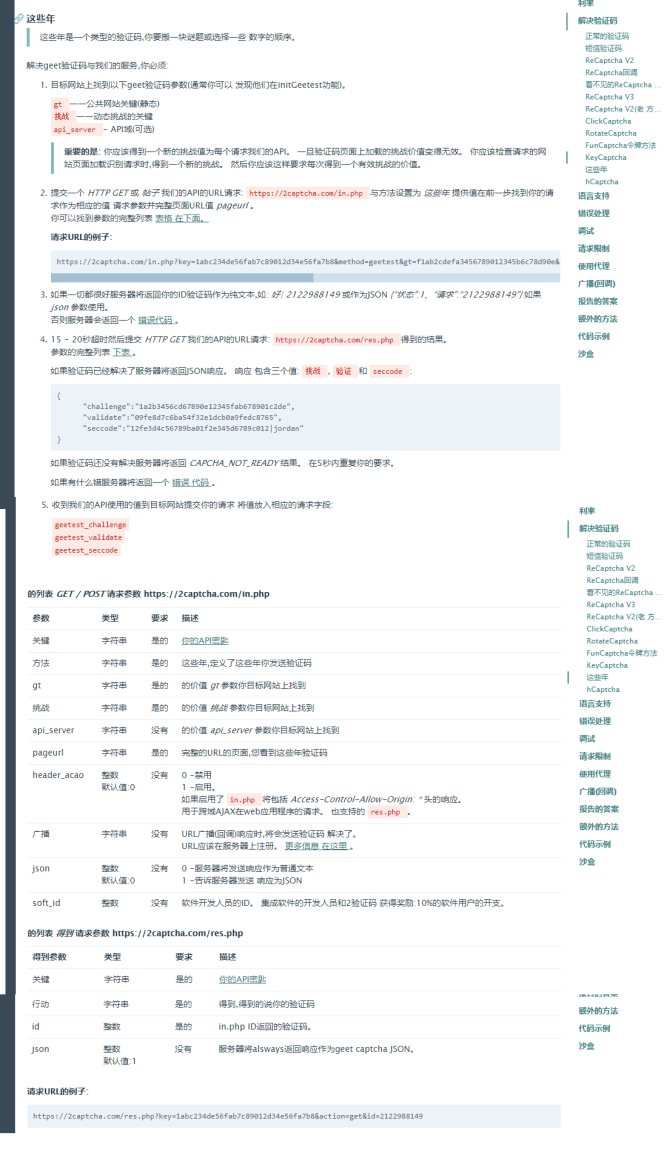
这里大概整理一下它的意思
首先,找到目标网站的gt,challenge和api_server三个值,然后,加上其他一些参数发送到 https://2captcha.com/in.php,会返回一个任务ID
然后等个15秒左右以后,再向 https://2captcha.com/res.php 请求,带上任务ID加上一些其他参数,会返回三个值,返回的三个值+用户名密码等的向目标网站请求,就可以通过验证了
开始行动
在目标网站上,我们寻找一下gt,challenge,api_server三个东西,我们切换到哔哩哔哩找一下
我们点击network,刷新网页,重新加载所有请求,crtl+f,搜索challenge,竟然发现
combine 这个接口返回的是这个
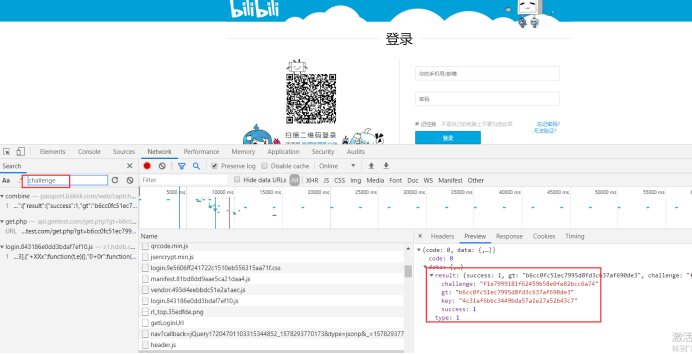
竟然在 https://passport.bilibili.com/web/captcha/combine?plat=11 请求中 找到了,但是到底之不是这个呢,人家 2captcha文档 说了,通常可以在initGeetest发现他,我们尝试下
点击Elements,按ctrl+shift+f全局搜索一下,搜索 initGeetest
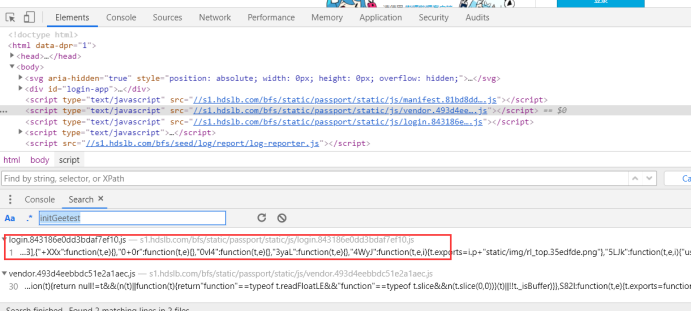
还真有一个,我们点进去看看
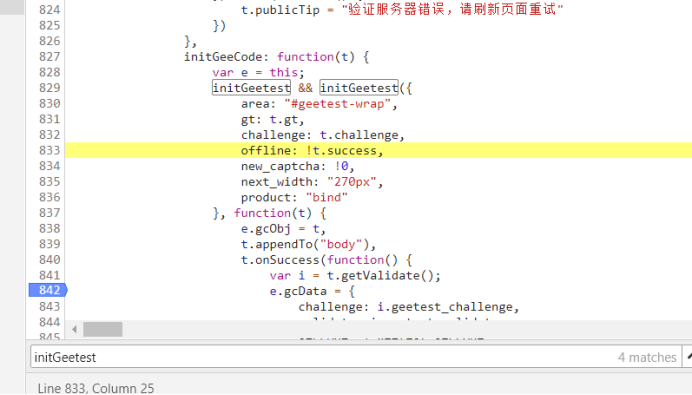
还真有这个,我们打上断点,再次刷新,匹配一下是否和network里的一样
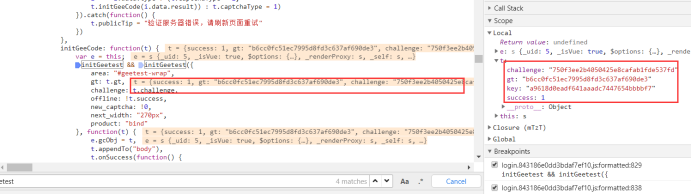
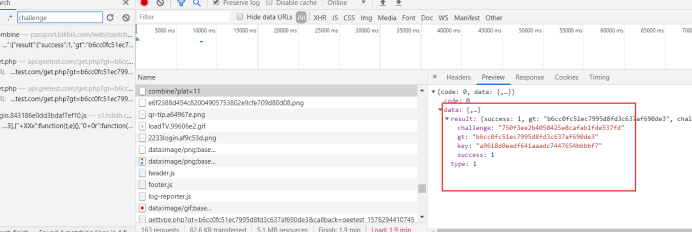
上面是断点的值,下面是network的值,至少看着一样的,我们至少可以确定,有很大关系
至少我们确定了两个值,gt和challenge,还差一个api_server
我们随便输入账号密码点击登录一下,触发一下极验,在elements中,搜索api_server
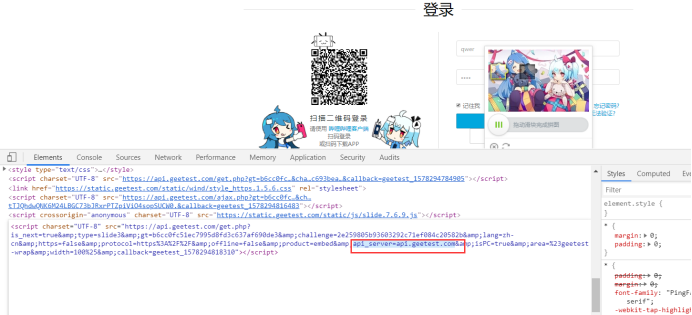
红色圈起来的地方就表示是api_server,基本参数都找齐了
刚才我们也说了,参数都找齐了,那我们就该请求打码平台了
那我们,就干呐,前面说到,在network中,请求 https://passport.bilibili.com/web/captcha/combine?plat=11 就可以获得gt,challenge,外加一个key
Ok,我们来请求一下
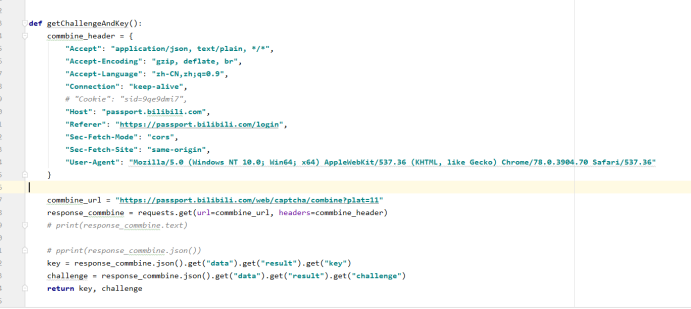
这样,我们就拿到了gt,challenge
我们请求一下打码平台的接口,带上自己参数
打码平台需要请求两次,第一次返回的是任务ID,第二次才是滑动模块的成功值
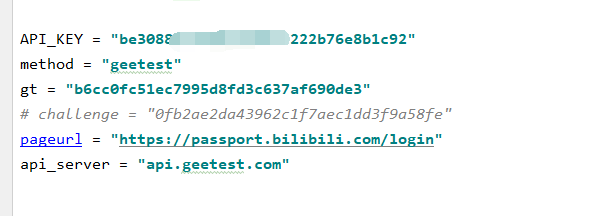
注:challenge是动态的,其他的是静态的
API_KEY是打码平台的key

两个函数,我们就成功的拿到了打码平台返回的值

红色圈起来的,就是破解极验的第一个关键参数,这个参数拿到之后呢,就已经跟人家打码平台没关系啦,我们只需要带着相关参数,登录哔哩哔哩就好了,但是这个参数要往哪发呢,在network经过一番查找后,似乎发现一个和登录有关的接口
https://passport.bilibili.com/web/login/v2
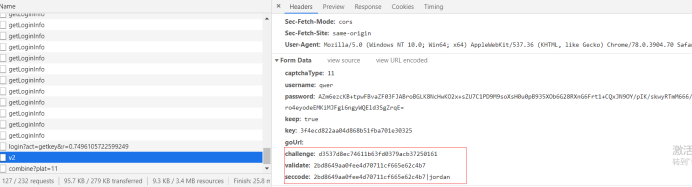
我们可以看到,红色框圈起来的部分,正式 2captcha平台 返回给我们的数据,key,正是 https://passport.bilibili.com/web/captcha/combine?plat=11 返回的key,但是password,进行了加密,他是如何加密的呢
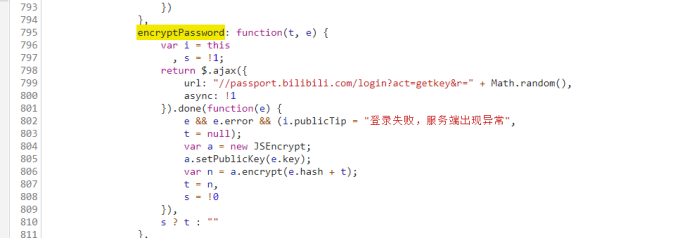
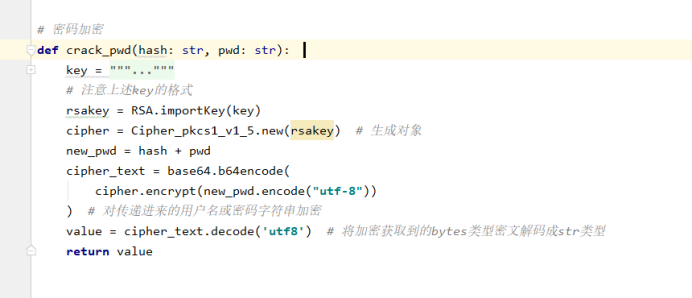
经过不断的断点,不断地断点.....终于确定了,密码会经过这个函数进行加密,它本质是 RSA非对称加密 听着就吓人,不慌,盘它,
这个函数逻辑是先请求//passport.bilbilli.com/login?act=get&r="" ,带上一个随机数,然后会返回一个随机hash,和一个公钥key
公钥key是固定的,然后将随机hash和密码进行加密,发送后他后,后台进行解密
破解代码
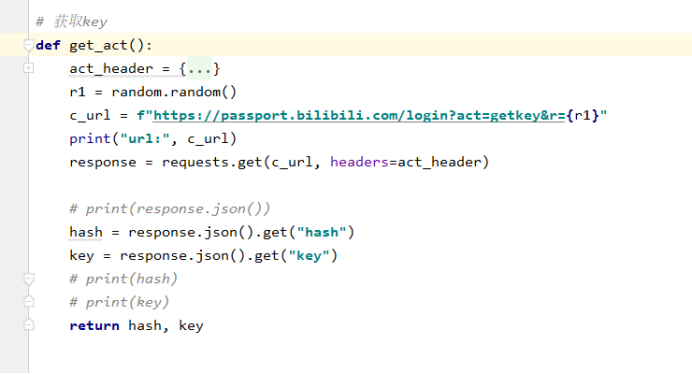
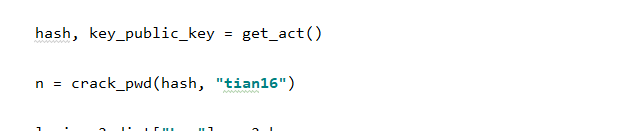
通过上述两个函数,就模拟出了密码,最后,最后,我们只需要拼接所有参数,请求一下就ok了
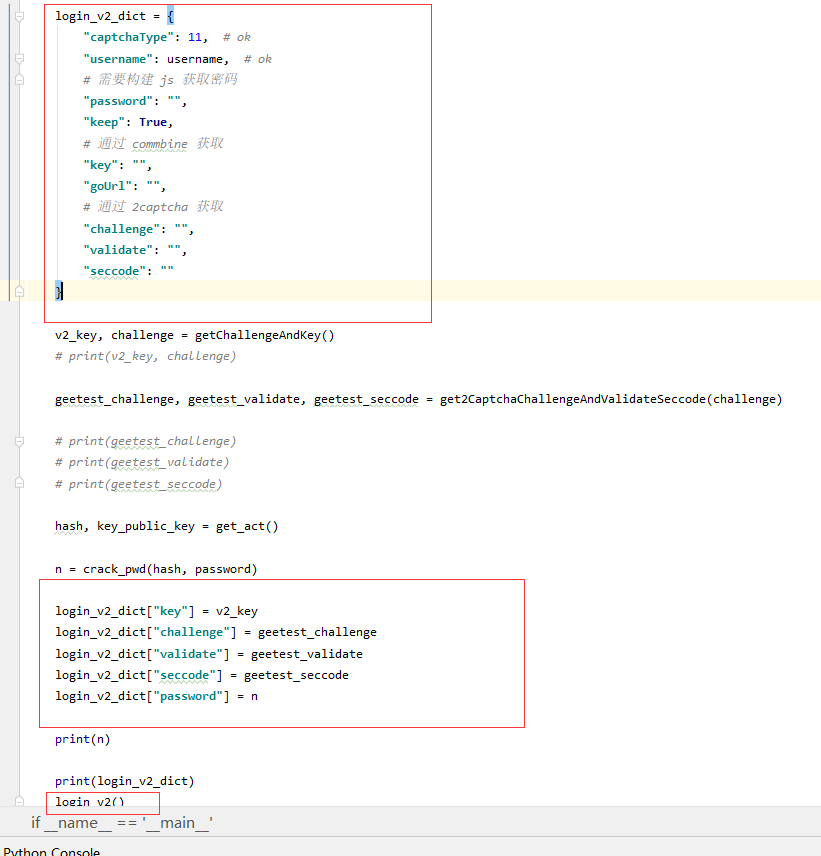
示例效果
如果账号密码错误
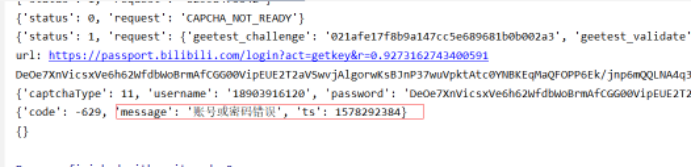
如果账号密码正确

第一个表示跳转的url,第二个是返回的cookie,以后我们想干什么,只需要带着这个cookie就好了
完整代码
from pprint import pprint
import time
import random
import requests
import base64
from Crypto.PublicKey import RSA
from Crypto.Cipher import PKCS1_v1_5 as Cipher_pkcs1_v1_5 API_KEY = "be308827049bfeb0c4c222b76e8b1c92"
method = "geetest"
gt = "b6cc0fc51ec7995d8fd3c637af690de3"
# challenge = "0fb2ae2da43962c1f7aec1dd3f9a58fe"
pageurl = "https://passport.bilibili.com/login"
api_server = "api.geetest.com" def getChallengeAndKey():
commbine_header = {
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
# "Cookie": "sid=9qe9dmi7",
"Host": "passport.bilibili.com",
"Referer": "https://passport.bilibili.com/login",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"
} commbine_url = "https://passport.bilibili.com/web/captcha/combine?plat=11"
response_commbine = requests.get(url=commbine_url, headers=commbine_header)
# print(response_commbine.text) # pprint(response_commbine.json())
key = response_commbine.json().get("data").get("result").get("key")
challenge = response_commbine.json().get("data").get("result").get("challenge")
return key, challenge def get2CaptchaChallengeAndValidateSeccode(challenge):
captcha_url = f"https://2captcha.com/in.php?key={API_KEY}&method={method}>={gt}&challenge={challenge}&pageurl={pageurl}&api_server={api_server}&json=1"
r = requests.get(captcha_url)
print(r.json())
rid = r.json().get("request") # print(rid, type(rid)) time.sleep(15) while True:
re_cpatcha_url = f"https://2captcha.com/res.php?key={API_KEY}&action=get&id={int(rid)}&json=1"
# print(re_cpatcha_url)
r2 = requests.get(re_cpatcha_url)
print(r2.json())
if r2.json().get("status") == 1:
geetest_challenge = r2.json().get("request").get("geetest_challenge")
geetest_validate = r2.json().get("request").get("geetest_validate")
geetest_seccode = r2.json().get("request").get("geetest_seccode") return geetest_challenge, geetest_validate, geetest_seccode time.sleep(5) # 密码加密
def crack_pwd(hash: str, pwd: str):
key = """-----BEGIN PUBLIC KEY-----
MIGfMA0GCSqGSIb3DQEBAQUAA4GNADCBiQKBgQDjb4V7EidX/ym28t2ybo0U6t0n
6p4ej8VjqKHg100va6jkNbNTrLQqMCQCAYtXMXXp2Fwkk6WR+12N9zknLjf+C9sx
/+l48mjUU8RqahiFD1XT/u2e0m2EN029OhCgkHx3Fc/KlFSIbak93EH/XlYis0w+
Xl69GV6klzgxW6d2xQIDAQAB
-----END PUBLIC KEY-----
"""
# 注意上述key的格式
rsakey = RSA.importKey(key)
cipher = Cipher_pkcs1_v1_5.new(rsakey) # 生成对象
new_pwd = hash + pwd
cipher_text = base64.b64encode(
cipher.encrypt(new_pwd.encode("utf-8"))
) # 对传递进来的用户名或密码字符串加密
value = cipher_text.decode('utf8') # 将加密获取到的bytes类型密文解码成str类型
return value # 获取key
def get_act():
act_header = {
"Accept": "*/*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
"Cookie": "sid=9qe9dmi7; _uuid=A8F38E21-6734-4291-C4EC-404AEA0294C750293infoc; buvid3=8548F035-99E8-41F8-BDA1-C63065B96FD5155813infoc",
"Host": "passport.bilibili.com",
"Referer": "https://passport.bilibili.com/login",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36",
"X-Requested-With": "XMLHttpRequest"
}
r1 = random.random()
c_url = f"https://passport.bilibili.com/login?act=getkey&r={r1}"
print("url:", c_url)
response = requests.get(c_url, headers=act_header) # print(response.json())
hash = response.json().get("hash")
key = response.json().get("key")
# print(hash)
# print(key)
return hash, key def login_v2():
login_v2_header = {
"Accept": "application/json, text/plain, */*",
"Accept-Encoding": "gzip, deflate, br",
"Accept-Language": "zh-CN,zh;q=0.9",
"Connection": "keep-alive",
# "Cookie": "sid=9qe9dmi7",
"Host": "passport.bilibili.com",
"Referer": "https://passport.bilibili.com/login",
"Sec-Fetch-Mode": "cors",
"Sec-Fetch-Site": "same-origin",
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/78.0.3904.70 Safari/537.36"
}
login_v2_url = "https://passport.bilibili.com/web/login/v2"
r1 = requests.post(login_v2_url, headers=login_v2_header, data=login_v2_dict)
pprint(r1.json())
print(r1.cookies.get_dict()) if __name__ == '__main__':
username = ""
password = "" login_v2_dict = {
"captchaType": 11, # ok
"username": username, # ok
# 需要构建 js 获取密码
"password": "",
"keep": True,
# 通过 commbine 获取
"key": "",
"goUrl": "", # 通过 2captcha 获取
"challenge": "",
"validate": "",
"seccode": ""
} v2_key, challenge = getChallengeAndKey()
# print(v2_key, challenge) geetest_challenge, geetest_validate, geetest_seccode = get2CaptchaChallengeAndValidateSeccode(challenge) # print(geetest_challenge)
# print(geetest_validate)
# print(geetest_seccode) hash, key_public_key = get_act() n = crack_pwd(hash, password) login_v2_dict["key"] = v2_key
login_v2_dict["challenge"] = geetest_challenge
login_v2_dict["validate"] = geetest_validate
login_v2_dict["seccode"] = geetest_seccode
login_v2_dict["password"] = n print(n) print(login_v2_dict)
login_v2()
Python 自动登录哔哩哔哩(2captcha打码平台)的更多相关文章
- python自动登录代码
公司有很多管理平台,账号有禁用机制,每个月至少登录一次,否则禁用.导致有时候想登录某个平台的时候,发现账号已经被禁用了,还得走流程解禁.因此用python实现了一下自动登录,每天定时任务运行一次.ps ...
- 吴裕雄--天生自然PYTHON学习笔记:python自动登录网站
打开 www. 5 l eta . com 网站,如果己经通过某用户名进行了登录,那么先退出登录 . 登录该网站 的步骤一般如下 : ( 1 )单击右上角的“登录”按钮. ( 2 )先输入账号. ( ...
- Python 自动登录网站(处理Cookie)
http://digiter.iteye.com/blog/1300884 Python代码 def login(): cj = cookielib.CookieJar() ope ...
- 5、Selenium+Python自动登录163邮箱发送邮件
1.Selenium实现自动化,需要定位元素,以下查看163邮箱的登录元素 (1)登录(定位到登录框,登录框是一个iframe,如果没有定位到iframe,是无法定位到账号框与密码框) 定位到邮箱框( ...
- python 自动登录网页
语言:python 浏览器:chrome 工具:chrome控制台 #!/usr/bin/python # coding: GBK import urllib,urllib2,httplib,cook ...
- python 奇淫技巧之自动登录 哔哩哔哩
前言 嘿,各位小伙伴好呀,今天要带来点什么干货呢,就从我的实际开发中来给大家带来一个案例吧,如何自动登录 哔哩哔哩 接到老大通知,让我自动写一个自动登录 哔哩哔哩 的脚本,我当然是二话不说直接开怼,咱 ...
- 在Python中用Request库模拟登录(四):哔哩哔哩(有加密,有验证码)
!已失效! 抓包分析 获取验证码 获取加密公钥 其中hash是变化的,公钥key不变 登录 其中用户名没有被加密,密码被加密. 因为在获取公钥的时候同时返回了一个hash值,推测此hash值与密码加密 ...
- Python模拟登录哔哩哔哩
嘿,各位小伙伴中午好呀,今天要带来点什么干货呢,就从我的实际开发中来给大家带来一个案例吧,如何自动登录哔哩哔哩. ! 接到老大通知,让我自动写一个自动登录哔哩哔哩的脚本,我当然是二话不说直接开怼,咱们 ...
- python预课05 爬虫初步学习+jieba分词+词云库+哔哩哔哩弹幕爬取示例(数据分析pandas)
结巴分词 import jieba """ pip install jieba 1.精确模式 2.全模式 3.搜索引擎模式 """ txt ...
随机推荐
- Python 基础之字符串操作,函数及格式化format
一.字符串的相关操作 1.字符串的拼接 + strvar1 = "我爱你,"strvar2 = "亲爱的姑凉"res = strvar1 + strvar2pr ...
- UniGUI设置背景图片(09)
主要是Background和LoginBackground属性, 类似地Login窗口背景图也可这样修改 UniServerModule.MainFormDisplayMode:= mfPage;/ ...
- synchronized和volatile关键字
synchronized 同步块大家都比较熟悉,通过 synchronized 关键字来实现,所有加上synchronized 和 块语句,在多线程访问的时候,同一时刻只能有一个线程能够用 synch ...
- CSS相关(1)
CSS: 字体: 网页默认字体16px; 网站通用字体大小14px 最小是12px,最大无限大 单位换算:1em=16px 选择器:标签选择器:选择页面中所有指定标签,权重为1 通配符选择器:选择所有 ...
- 基于TF-IDF的推荐
仅作学习使用 基于TF-IDF的推荐: 将文档分词 对于每个term,计算词频TF和逆文本指数IDF,形成term的权重 计算项目文档和用户偏好文档的相似度 参考: https://blog.csdn ...
- 【FastDev4Android框架开发】RecyclerView完全解析之下拉刷新与上拉加载SwipeRefreshLayout(三十一)
转载请标明出处: http://blog.csdn.net/developer_jiangqq/article/details/49992269 本文出自:[江清清的博客] (一).前言: [好消息] ...
- status 后面的P和I是什么单词的缩写
我不是很肯定,有大概印象:P 为 performed, 已完成I 为 incomplete 未完成
- springcloud-alibaba手写负载均衡的坑,采用restTemplate,不能添加@loadbalanced注解,否则采用了robbin
采用springcloud-alibaba整合rabbion使用DiscoveryClient调用restful时遇到的一个问题,报错如下: D:\javaDevlepTool\java1.8\jdk ...
- selenium+chrome抓取淘宝宝贝-崔庆才思路
站点分析 源码及遇到的问题 在搜索时,会跳转到登录界面 step1:干起来! 先取cookie step2:载入cookie step3:放飞自我 关于phantomJS浏览器的问题 源码 站点分析 ...
- 700k把web端程序包装为桌面程序
electron因为自带cef所以体积巨大,还不是因为windows没有chromium的webview嘛,现在有了新edge后,这个项目通过依赖各个平台的webview,并依赖.net core,做 ...