DeepWalk论文精读:(4)总结及不足
模块4
1 研究背景
随着互联网的发展,社交网络逐渐复杂化、多元化。在一个社交网络中,充斥着不同类型的用户,用户间产生各式各样的互动联系,形成大小不一的社群。为了对社交网络进行研究分析,需要将网络中的节点(用户)进行分类。
2 解决的问题
利用节点在图中的局部结构信息,对社交网络中的结点进行分类。由于这部分信息常常是隐藏的,不体现在初始输入$X$当中,故需要一些算法对结点的局部结构进行挖掘。DeepWalk最重要解决的是网络中节点的集体分类(Collective Classification)或关联分类(Relational Classification),但若能将节点用一个“好的”向量进行表示,分类工作也会很容易进行。故DeepWalk的核心任务是,在连续向量空间中以低维度的稠密形式表征网络结点,方便后续利用统计模型完成结点的分类。
如下图例子所示,是将(a)中原本网络的各个节点映射表示为到(b)二维空间的二维坐标。
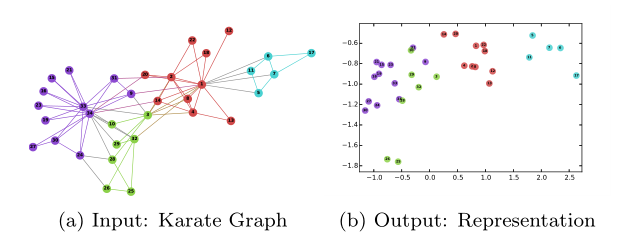
3 主要贡献
3.1 解决方法
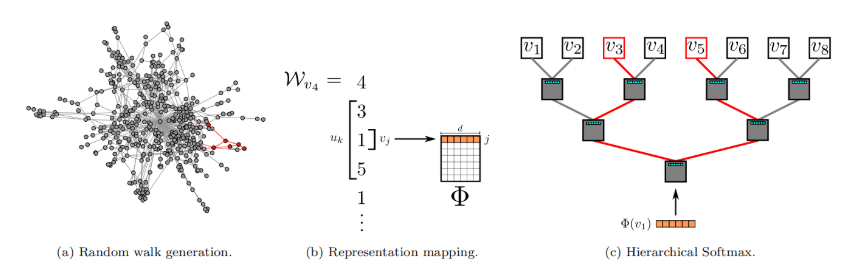
DeepWalk的核心算法包含随机游走序列生成器和节点向量更新两部分。这两部分可以结合的关键点在于:数据呈现幂律分布。
3.1.1 随机游走
在网络上施行随机游走算法:从根节点$v_i$出发,随机访问一个邻居,然后再访问邻居的邻居......每一步都访问前一步所在节点的邻居,直到序列长度达到设定的最大值$t$。网络中任何节点均可作为根节点,施行随机游走算法$\gamma$次,得到$\gamma \cdot |V|$个随机游走序列。随机游走伪代码如下所示:

3.1.2 节点向量更新
对于一个随机游走序列,每一个节点都可作为中心节点,根据设定的窗口大小$\omega$,选取序列里中心节点前后各$\omega$,共$2\omega$个节点。利用SkipGram算法[26, 27]按照如下优化方式进行优化:
$$
minimize \space -\log \Pr(u_k|\Phi(v_j))
$$
即最大化在$v_j$附近出现$u_k$的概率。其中,$u_k$是这$2\omega$个节点中的每一个,$\Phi(v_j) \in \mathbb{R}^d$是将节点映射到它的嵌入表示的函数,也即我们最终要得到的结果。SkipGram伪代码如下所示:

利用Hierarchical Softmax二叉树[29, 30],将所有节点作为二叉树的叶子节点,就可以用从根节点到叶子节点的路径来表示每个节点。即有下式:
$$
\Pr(u_k|\Phi(v_j))=\prod_{l=1}^{\lceil\log|V|\rceil}\Pr(b_l|\Phi(v_j))
$$
可对SkipGram算法进行加速。
3.1.3 幂律分布
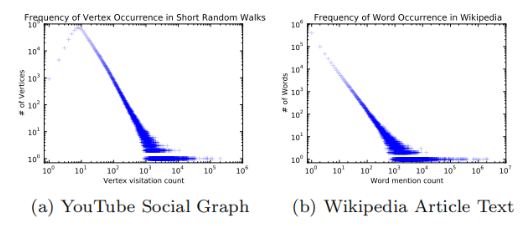
之所以DeepWalk可以由随机游走和SkipGram结合得到,是因为作者观察到,数据输入服从幂律分布,曾用于自然语言模型的SkipGram算法可以很好地处理这一分布。
3.2 实验及其结论
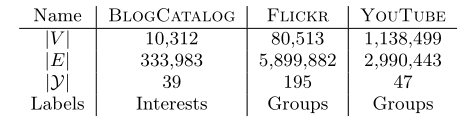
作者选用了下图所示三个数据集:BlogCatalog, Flickr, YouTube。采用的评价方式为Macro-F1和Micro-F1。
3.2.1 准确性
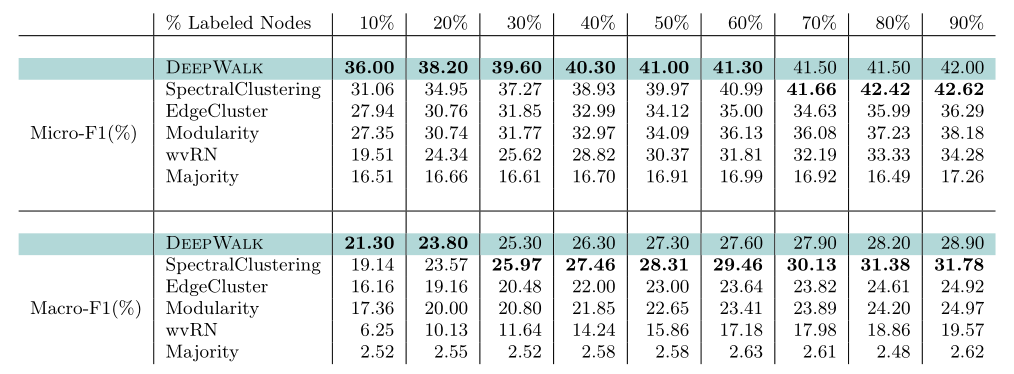
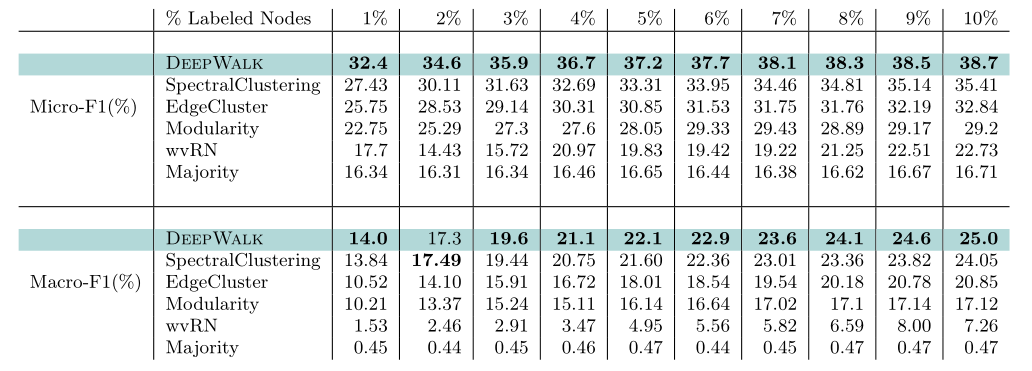
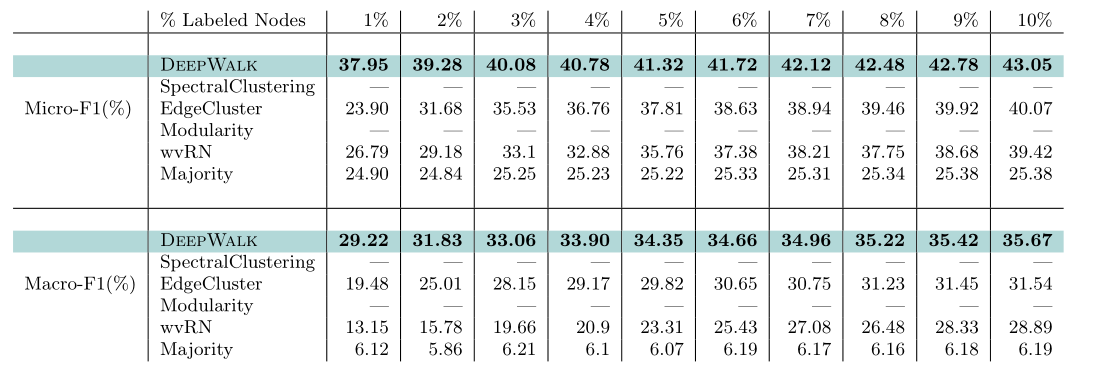
作者在三个数据集上分别取不同数量的带标签节点进行训练,并对剩余结点进行预测,得出结论:在多标签分类的任务上使用DeepWalk有两点好处——
- 可以适用于大规模的图
- 仅需要少量有标记的样本就拥有很高的分类准确率
3.2.2 敏感性
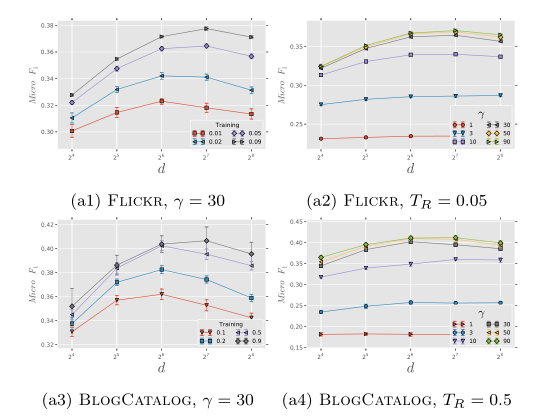
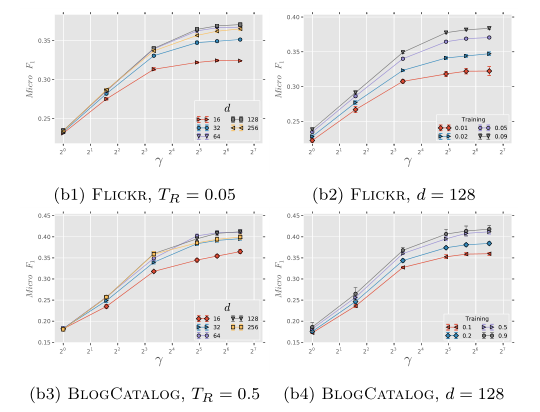
作者固定窗口大小$\omega$=10 和 随机游走序列长度$t$=40,改变嵌入维度$d$、每个节点作为根节点的次数$\gamma$、训练集比例$T_R$。得到以下结论:
- 存在最优的维度,且最优维度的大小和$T_R$的大小有关
- $\gamma$的增大可以提升模型效果,但当$\gamma$大于10后提升逐渐减小,当$\gamma$大于30后无法提升效果。
3.2.3 并行化
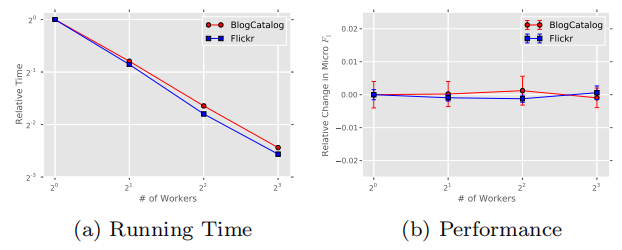
作者增加并行任务的个数,使用非同步的随机梯度下降(ASGD)方法更新向量,可以线性地减少训练时间,但不会降低准确性,证明DeepWalk算法适用于大规模的学习。[36, 8]
4 存在的不足
4.1 带权边与度量相似度
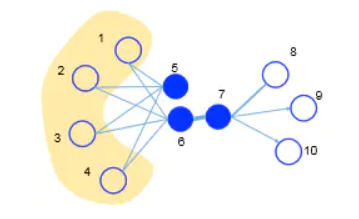
DeepWalk只适用于无权边,只能忽略边的权重,然而这在网络中是十分重要的。LINE[100]考虑了边的权重,且明确地定义了一阶相似度和二阶相似度。其中一阶相似度是两个顶点之间的自身相似(不考虑其他顶点),二阶相似度是两个节点邻近网络结构之间的相似性,即共享相似邻居的顶点倾向于彼此相似。如下图的节点6和节点7,由于有边直接相连,故有一阶相似性;节点5和节点6没有边直接相连,但它们有公共邻居1, 2, 3, 4,故有二阶相似性。
在LINE定义了一阶相似度和二阶相似度之后,GraRep[101]考虑了三阶、四阶等更高阶的相似度。
此外,DeepWalk是一种基于DFS的方法,而LINE和GrapRep是一种基于BFS的方法。
4.2 空间结构相似性 > 相邻性
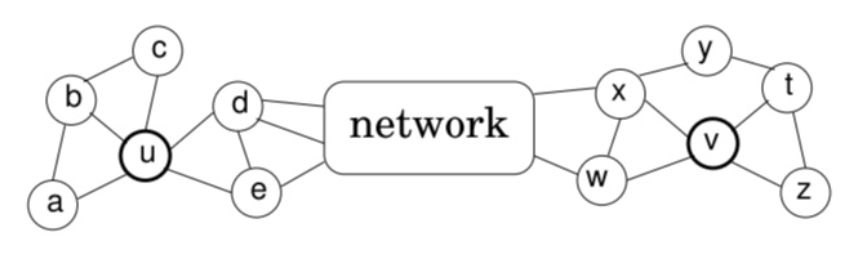
前述方法都基于近邻相似的假设,即认为只有相近的节点才比较相似。而struc2vec[102]认为两个不是近邻的节点也可能拥有很高的相似性,所以只应考虑结点的空间结构相似性。前述方法之所以有效是因为,现实世界中相邻的节点往往有着比较相似的空间环境。如下图所示的节点u和节点v并不相邻,但他们拥有相似的空间环境,最终得到的嵌入表示也应该类似。
4.3 归纳式学习
前述方法都是直推式学习,即在一个确定的网络中去学习顶点的嵌入表示,无法直接泛化到在训练过程没有出现过的顶点,属于直推式(transductive)的学习。
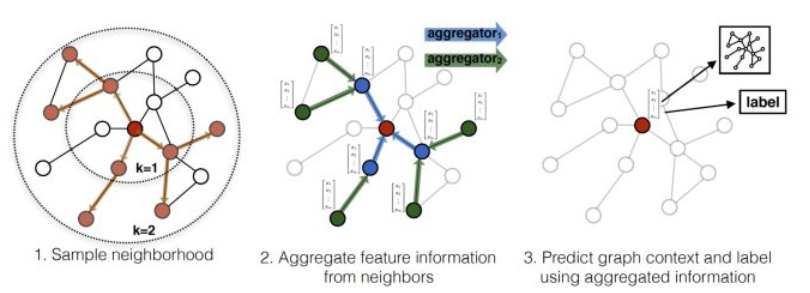
GraphSAGE[103]则是一种能够利用顶点的属性信息,高效产生未知顶点嵌入表示的一种归纳式(inductive)学习的框架。其核心思想是通过一个节点的邻居节点,学习到一个聚合函数,然后对任意节点应用该聚合函数来得到该节点的嵌入表示。
参考文献
3.1.2 节点向量更新
[26] T. Mikolov, K. Chen, G. Corrado, and J. Dean. Efficient estimation of word representations in vector space. CoRR, abs/1301.3781, 2013.
[27] T. Mikolov, I. Sutskever, K. Chen, G. S. Corrado, and J. Dean. Distributed representations of words and phrases and their compositionality. In Advances in Neural Information Processing Systems 26, pages 3111–3119. 2013.
[29] A. Mnih and G. E. Hinton. A scalable hierarchical distributed language model. Advances in neural information processing systems, 21:1081–1088, 2009
[30] F. Morin and Y. Bengio. Hierarchical probabilistic neural network language model. In Proceedings of the international workshop on artificial intelligence and statistics, pages 246–252, 2005.
3.2.3 并行化
[36] B. Recht, C. Re, S. Wright, and F. Niu. Hogwild: A lock-free approach to parallelizing stochastic gradient descent. In Advances in Neural Information Processing Systems 24, pages 693–701. 2011.
[8] J. Dean, G. Corrado, R. Monga, K. Chen, M. Devin, Q. Le, M. Mao, M. Ranzato, A. Senior, P. Tucker, K. Yang, and A. Ng. Large scale distributed deep networks. In P. Bartlett, F. Pereira, C. Burges, L. Bottou, and K. Weinberger, editors, Advances in Neural Information Processing Systems 25, pages 1232–1240. 2012.
4 存在的不足
[100] Tang J, Qu M, Wang M, et al. Line: Large-scale information network embedding[C]. International Conference on World Wide Web(WWW 2015), 2015: 1067-1077.
[101] Cao S, Lu W, Xu Q. Grarep: Learning graph representations with global structural information[C]. ACM International Conference on Information and Knowledge Management (CIKM 2015), 2015: 891-900.
[102] Ribeiro L F, Saverese P H, Figueiredo D R. struc2vec: Learning node representations from structural identity[C]. ACM SIGKDD International Conference on Knowledge Discovery and Data Mining(SIGKDD 2017), 2017: 385-394.
[103] Hamilton W L, Ying Z, Leskovec J. Inductive Representation Learning on Large Graphs[C]. Neural Information Processing Systems (NIPS 2017), 2017: 1024-1034.
DeepWalk论文精读:(4)总结及不足的更多相关文章
- DeepWalk论文精读:(3)实验
模块三 1 实验设计 1.1 数据集 BLOGCATALOG[39]:博客作者网络.标签为作者感兴趣的主题. FLICKR[39]:照片分享网站的用户网络.标签为用户的兴趣群组,如"黑白照片 ...
- DeepWalk论文精读:(1)解决问题&相关工作
模块1 1. 研究背景 随着互联网的发展,社交网络逐渐复杂化.多元化.在一个社交网络中,充斥着不同类型的用户,用户间产生各式各样的互动联系,形成大小不一的社群.为了对社交网络进行研究分析,需要将网络中 ...
- 【深度学习 论文篇 02-1 】YOLOv1论文精读
原论文链接:https://gitee.com/shaoxuxu/DeepLearning_PaperNotes/blob/master/YOLOv1.pdf 笔记版论文链接:https://gite ...
- 用深度学习(DNN)构建推荐系统 - Deep Neural Networks for YouTube Recommendations论文精读
虽然国内必须FQ才能登录YouTube,但想必大家都知道这个网站.基本上算是世界范围内视频领域的最大的网站了,坐拥10亿量级的用户,网站内的视频推荐自然是一个非常重要的功能.本文就focus在YouT ...
- AFM论文精读
深度学习在推荐系统的应用(二)中AFM的简单回顾 AFM模型(Attentional Factorization Machine) 模型原始论文 Attentional Factorization M ...
- Faster-RCNN论文精读
State-of-the-art object detection networks depend on region proposal algorithms to hypothesize objec ...
- [论文阅读]阿里DIN深度兴趣网络之总体解读
[论文阅读]阿里DIN深度兴趣网络之总体解读 目录 [论文阅读]阿里DIN深度兴趣网络之总体解读 0x00 摘要 0x01 论文概要 1.1 概括 1.2 文章信息 1.3 核心观点 1.4 名词解释 ...
- [论文解读] 阿里DIEN整体代码结构
[论文解读] 阿里DIEN整体代码结构 目录 [论文解读] 阿里DIEN整体代码结构 0x00 摘要 0x01 文件简介 0x02 总体架构 0x03 总体代码 0x04 模型基类 4.1 基本逻辑 ...
- 论文解读(GraRep)《GraRep: Learning Graph Representations with Global Structural Information》
论文题目:<GraRep: Learning Graph Representations with Global Structural Information>发表时间: CIKM论文作 ...
随机推荐
- 28.1 api-- Object(toString equals)
/* * String toString() : 返回该对象的字符串表示 * return getClass().getName() + "@" + Integer.toHexSt ...
- 28 api的使用2
本文将讲解如下api的使用: Object.System.Date.DateFormat.Calendar.Integer-- int的包装类等 1. 类 Object 是类层次结构的根类.每个类都使 ...
- hadoop(九)启动|关闭集群(完全分布式六)|11
前置章节:hadoop集群namenode启动ssh免密登录(hadoop完全分布式五)|11 集群启动 配置workers(3.x之前是slaves), 删除localhost,添加102/103/ ...
- AJ学IOS 之ipad开发Popover的调色板应用_popover显示后其他控件仍然能进行交互
AJ分享,必须精品 一:效果 后面的是xcode的控制台 二:代码 ViewController #import "ViewController.h" #import " ...
- 干货:python面对对象类继承简介
前言 文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 作者:python视觉算法 PS:如有需要Python学习资料的小伙伴可以加 ...
- 原创Pig0.16.0安装搭建
tar -zxvf pig-0.16.0.tar.gz -C ~ vi ~/.bash_profile export PIG_HOME=/home/hadoop/pig-0.16.0 export ...
- adb命令查看手机应用内存使用情况
adb shell回车 一.procrank VSS >= RSS >= PSS >= USSVSS - Virtual Set Size 虚拟耗用内存(包含共享库占用的内存)是单个 ...
- 纯js时钟特效详细代码分析实例教程
电子时钟是网上常见的功能,在学习date对象和定时器功能时,来完成一个电子时钟的制作是不错的选择.学习本教程之前,读者需要具备html和css技能,同时需要有简单的javascript基础. 先准备一 ...
- JS Math&Date的方法 (下)
Date - 时间日期对象 一:Date 时间对象 - 它是处理时间日期的 时间日期对象 - js提供了一个专门用来创建日期对象的构造函数 Date new Date() 这是一 ...
- Gradle系列之Groovy基础篇
原文发于微信公众号 jzman-blog,欢迎关注交流. 上一篇学习了 Gradle 的入门知识,Gradle 基于 Groovy,今天学习一下 Groovy 的基础知识,Groovy 是基于 JVM ...