基于flink和drools的实时日志处理
1、背景
日志系统接入的日志种类多、格式复杂多样,主流的有以下几种日志:
- filebeat采集到的文本日志,格式多样
- winbeat采集到的操作系统日志
- 设备上报到logstash的syslog日志
- 接入到kafka的业务日志
以上通过各种渠道接入的日志,存在2个主要的问题:
- 格式不统一、不规范、标准化不够
- 如何从各类日志中提取出用户关心的指标,挖掘更多的业务价值
为了解决上面2个问题,我们基于flink和drools规则引擎做了实时的日志处理服务。
2、系统架构
架构比较简单,架构图如下:
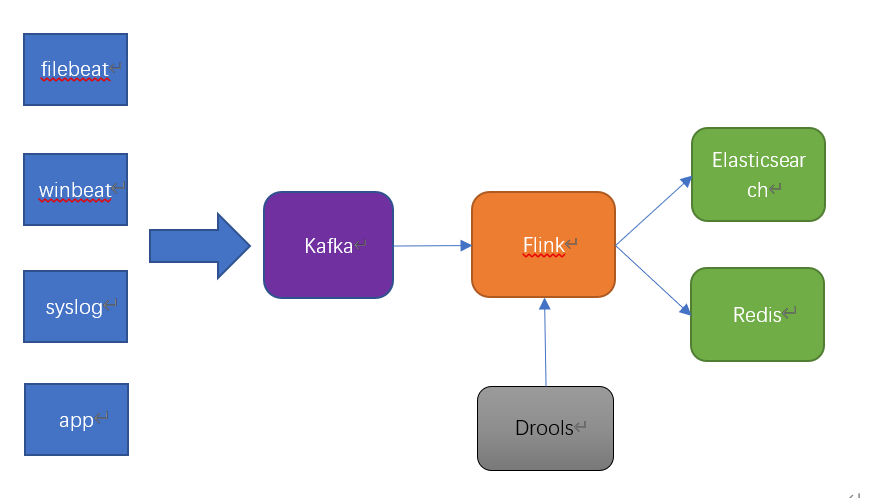
各类日志都是通过kafka汇总,做日志中转。
flink消费kafka的数据,同时通过API调用拉取drools规则引擎,对日志做解析处理后,将解析后的数据存储到Elasticsearch中,用于日志的搜索和分析等业务。
为了监控日志解析的实时状态,flink会将日志处理的统计数据,如每分钟处理的日志量,每种日志从各个机器IP来的日志量写到Redis中,用于监控统计。
3、模块介绍
系统项目命名为eagle。
eagle-api:基于springboot,作为drools规则引擎的写入和读取API服务。
eagle-common:通用类模块。
eagle-log:基于flink的日志处理服务。
重点讲一下eagle-log:
对接kafka、ES和Redis
对接kafka和ES都比较简单,用的官方的connector(flink-connector-kafka-0.10和flink-connector-elasticsearch6),详见代码。
对接Redis,最开始用的是org.apache.bahir提供的redis connector,后来发现灵活度不够,就使用了Jedis。
在将统计数据写入redis的时候,最开始用的keyby分组后缓存了分组数据,在sink中做统计处理后写入,参考代码如下:
String name = "redis-agg-log";
DataStream<Tuple2<String, List<LogEntry>>> keyedStream = dataSource.keyBy((KeySelector<LogEntry, String>) log -> log.getIndex())
.timeWindow(Time.seconds(windowTime)).trigger(new CountTriggerWithTimeout<>(windowCount, TimeCharacteristic.ProcessingTime))
.process(new ProcessWindowFunction<LogEntry, Tuple2<String, List<LogEntry>>, String, TimeWindow>() {
@Override
public void process(String s, Context context, Iterable<LogEntry> iterable, Collector<Tuple2<String, List<LogEntry>>> collector) {
ArrayList<LogEntry> logs = Lists.newArrayList(iterable);
if (logs.size() > 0) {
collector.collect(new Tuple2(s, logs));
}
}
}).setParallelism(redisSinkParallelism).name(name).uid(name);
后来发现这样做对内存消耗比较大,其实不需要缓存整个分组的原始数据,只需要一个统计数据就OK了,优化后:
String name = "redis-agg-log";
DataStream<LogStatWindowResult> keyedStream = dataSource.keyBy((KeySelector<LogEntry, String>) log -> log.getIndex())
.timeWindow(Time.seconds(windowTime))
.trigger(new CountTriggerWithTimeout<>(windowCount, TimeCharacteristic.ProcessingTime))
.aggregate(new LogStatAggregateFunction(), new LogStatWindowFunction())
.setParallelism(redisSinkParallelism).name(name).uid(name);
这里使用了flink的聚合函数和Accumulator,通过flink的agg操作做统计,减轻了内存消耗的压力。
使用broadcast广播drools规则引擎
1、drools规则流通过broadcast map state广播出去。
2、kafka的数据流connect规则流处理日志。
//广播规则流
env.addSource(new RuleSourceFunction(ruleUrl)).name(ruleName).uid(ruleName).setParallelism(1)
.broadcast(ruleStateDescriptor); //kafka数据流
FlinkKafkaConsumer010<LogEntry> source = new FlinkKafkaConsumer010<>(kafkaTopic, new LogSchema(), properties);
env.addSource(source).name(kafkaTopic).uid(kafkaTopic).setParallelism(kafkaParallelism); //数据流connect规则流处理日志
BroadcastConnectedStream<LogEntry, RuleBase> connectedStreams = dataSource.connect(ruleSource);
connectedStreams.process(new LogProcessFunction(ruleStateDescriptor, ruleBase)).setParallelism(processParallelism).name(name).uid(name);
具体细节参考开源代码。
4、小结
本系统提供了一个基于flink的实时数据处理参考,对接了kafka、redis和elasticsearch,通过可配置的drools规则引擎,将数据处理逻辑配置化和动态化。
对于处理后的数据,也可以对接到其他sink,为其他各类业务平台提供数据的解析、清洗和标准化服务。
项目地址:
https://github.com/luxiaoxun/eagle
基于flink和drools的实时日志处理的更多相关文章
- Lyft 基于 Flink 的大规模准实时数据分析平台(附FFA大会视频)
摘要:如何基于 Flink 搭建大规模准实时数据分析平台?在 Flink Forward Asia 2019 上,来自 Lyft 公司实时数据平台的徐赢博士和计算数据平台的高立博士分享了 Lyft 基 ...
- 苏宁基于Spark Streaming的实时日志分析系统实践 Spark Streaming 在数据平台日志解析功能的应用
https://mp.weixin.qq.com/s/KPTM02-ICt72_7ZdRZIHBA 苏宁基于Spark Streaming的实时日志分析系统实践 原创: AI+落地实践 AI前线 20 ...
- 趣头条基于 Flink 的实时平台建设实践
本文由趣头条实时平台负责人席建刚分享趣头条实时平台的建设,整理者叶里君.文章将从平台的架构.Flink 现状,Flink 应用以及未来计划四部分分享. 一.平台架构 1.Flink 应用时间线 首先是 ...
- 轻装上阵Flink--在IDEA上开发基于Flink的实时数据流程序
前言 本文介绍如何在IDEA上快速开发基于Flink框架的DataStream程序.先直接上手! 环境清单 案例是在win7运行.安装VirtualBox,在VirtualBox上安装Centos操作 ...
- OPPO数据中台之基石:基于Flink SQL构建实数据仓库
小结: 1. OPPO数据中台之基石:基于Flink SQL构建实数据仓库 https://mp.weixin.qq.com/s/JsoMgIW6bKEFDGvq_KI6hg 作者 | 张俊编辑 | ...
- 基于Flink构建全场景实时数仓
目录: 一. 实时计算初期 二. 实时数仓建设 三. Lambda架构的实时数仓 四. Kappa架构的实时数仓 五. 流批结合的实时数仓 实时计算初期 虽然实时计算在最近几年才火起来,但是在早期也有 ...
- 腾讯新闻基于 Flink PipeLine 模式的实践
摘要 :随着社会消费模式以及经济形态的发展变化,将催生新的商业模式.腾讯新闻作为一款集游戏.教育.电商等一体的新闻资讯平台.服务亿万用户,业务应用多.数据量大.加之业务增长.场景更加复杂,业务对实时 ...
- 字节跳动流式数据集成基于Flink Checkpoint两阶段提交的实践和优化
背景 字节跳动开发套件数据集成团队(DTS ,Data Transmission Service)在字节跳动内基于 Flink 实现了流批一体的数据集成服务.其中一个典型场景是 Kafka/ByteM ...
- 【转】ELK(ElasticSearch, Logstash, Kibana)搭建实时日志分析平台
[转自]https://my.oschina.net/itblog/blog/547250 摘要: 前段时间研究的Log4j+Kafka中,有人建议把Kafka收集到的日志存放于ES(ElasticS ...
随机推荐
- Spring/SpringBoot常用注解总结
转自:[Guide哥] 0.前言 可以毫不夸张地说,这篇文章介绍的 Spring/SpringBoot 常用注解基本已经涵盖你工作中遇到的大部分常用的场景.对于每一个注解我都说了具体用法,掌握搞懂,使 ...
- Alpha冲刺 —— 个人总结
这几日Alpha冲刺的个人进展汇总,收获满满,我成长了. 我们的团队博客链接,团队作业第五次--Alpha冲刺 4.30 今日进展 改进数据库:字段命名重新规范,在record表中添加confirme ...
- Chisel3 - Tutorial - Stack
https://mp.weixin.qq.com/s/-AVJD1IfvNIJhmZM40DemA 实现后入先出(last in, first out)的栈. 参考链接: https://gi ...
- (Java实现)洛谷 P1093 奖学金
题目描述 某小学最近得到了一笔赞助,打算拿出其中一部分为学习成绩优秀的前5名学生发奖学金.期末,每个学生都有3门课的成绩:语文.数学.英语.先按总分从高到低排序,如果两个同学总分相同,再按语文成绩从高 ...
- Java实现回文判断
1 问题描述 给定一个字符串,如何判断这个字符串是否是回文串? 所谓回文串,是指正读和反读都一样的字符串,如madam.我爱我等. 2 解决方案 解决上述问题,有两种方法可供参考: (1)从字符串两头 ...
- Java实现Labeling Balls(拓扑排序的应用)
1 问题描述 给出一些球,从1N编号,他们的重量都不相同,也用1N标记加以区分(这里真心恶毒啊,估计很多WA都是因为这里),然后给出一些约束条件,< a , b >要求编号为 a 的球必须 ...
- Pi-star MMDVM双工板介绍
Pi-star MMDVM双工板介绍(2020/2) pi-star里控制模式选择:双工模式(DUPLEX Mode)/单工模式(SIMPLE Mode) 双工板工作频率范围:144-148,219- ...
- 关于nginx的源码安装方式
Nginx(engine x)是一款是由俄罗斯的程序设计师Igor Sysoev所开发高性能的 Web和 反向代理 服务器, 也是一个 IMAP/POP3/SMTP 代理服务器.在高连接并发的情况下, ...
- yum安装配置MySQL数据库
1.配置yum源 # 先安装wget yum install wget -y 2.下载mysql源安装包 wget http://dev.mysql.com/get/mysql57-commu ...
- JMeter接口压测和性能监测
JMeter接口压力测试总结 一.安装JMeter 1. 在客户端机器上安装JMeter压测工具,我这里安装的版本是apache-jmeter-5.2.1,由于JMeter是JAVA语言开发的 ...