python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)
//2019.07.19/20
python中pandas数据分析基础(数据重塑与轴向转化、数据分组与分组运算、离散化处理、多数据文件合并操作)
3.1 数据重塑与轴向转换
1、层次化索引使得一个轴上拥有多个索引
2、series多层次索引:
(1)series的层次化索引:主要可以通过
s[索引第1层:索引第二次]可以进行相应的索引
(2)对于series可以通过s.unstack()函数将其转换为DataFrame
具体举例代码如下:
s=pd.Series(range(1,10),index=[["a","a","a","b","b","c","c","d","d"],[1,2,3,1,2,3,1,2,3]])
#多层次索引列表的定义
print(s)
print(s.index)
print(s["a"])
print(s["a":"c"]) #进行外层索引,直接用s[]即可
print(s["a",1]) #多层索引需要用到[,]
print(s.unstack())#利用unstack可以将series转换为dataframe,实现的效果如下所示:

s1=s.unstack()
3、DataFrame的多层次索引:
(1)对于多层次索引的表格的定义:
da=pd.DataFrame(np.arange(12).reshape(4,3),index=[["a","a","b","b"],[1,2,1,2]],columns=[["A","A","B"],["Z","X","C"]]) #多层次索引表格的定义
(2)对于其中的列设置为索引需要函数df.set_index([]),如果需要转换回来则可以用函数df.reset_index()
(3)对于行索引层1和2之间进行交换可以用到函数df.swaplevel("索引名1","索引名2")
(4)对于dataframe类型的数据表格可以先利用stack()将其转换为series,然后再利用unstack()可以转换过来成为原始的dataframe
3.2 数据的分组与分组运算(主要是groupby技术的应用)
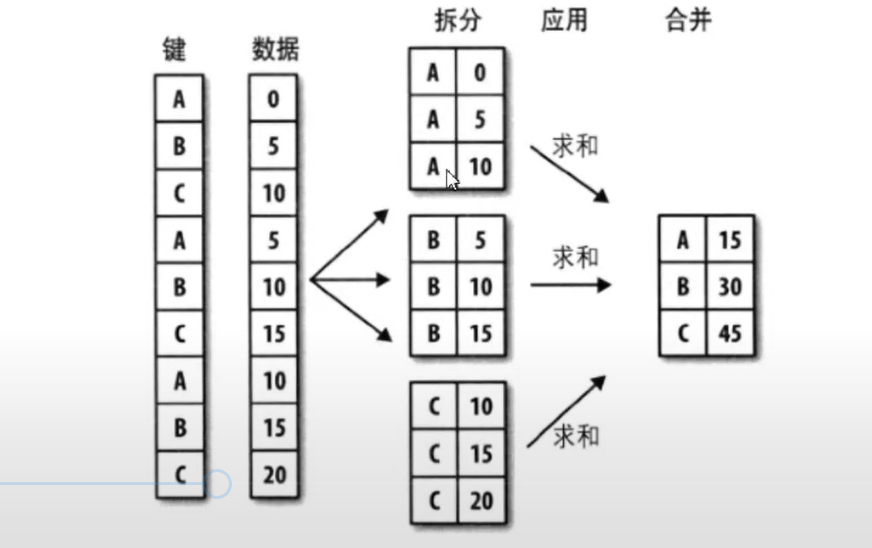
1、对于数据的分组和分组运算主要是指groupby函数的应用,具体函数的规则如下:
df[](指输出数据的结果属性名称).groupby([df[属性],df[属性])(指分类的属性,数据的限定定语,可以有多个).mean()(对于数据的计算方式——函数名称)
举例如下:
print(df["评分"].groupby([df["地区"],df["类型"]]).mean())
#上面语句的功能是输出表格所有数据中不同地区不同类型的评分数据平均值
3.3数据的离散化
1、数据的离散化是指不太关心数据的具体数值,对数据进行一定的区间分类,使得整体的数据离散成为几个不同的类型
2、数据的分类主要使用函数cut函数:
pd.cut(df,bins,right=True,labels=None,retbins=False,precision=3,include_lowest=False)
(1)df:是指需要进行离散化的数组,series或者dataframe
(2)bins:是指划分的依据
(3)right=True:指的是默认状态下右边是闭区间,是包含右边的数据的
(4)include_lowest=False:是指默认状态下左边是不包含的开区间
(5)labels:是指离散化区间的定义列表,如果不输入,则默认状态下为None,即不会输出离散化区间的定义名称,只会输出相应所处的区间
(6)retbins=False:是指返回df数据返回值所对应的binst列表(很少用到)
(7)precision=3:是指精度的设置(很少用到)
举例如下:
print(pd.cut(df["评分"],[0,4.2,4.5,4.8,5.0],labels=list("DCBA")))
#将评分列数据按照大小区间(0,4.2],(4.2,4.5],(4.5,4.8],(4.8,5.0]划分为ABCD四个等级
df["评分等级"]=pd.cut(df["评分"],[0,4.2,4.5,4.8,5.0],labels=list("DCBA"))
print(df)
#df列表里面增加评分等级的一列属性数据
bins=np.percentile(df["评分人数"],[0,20,40,60,80,100])
#将评分人数进行分位数划分(0,20%,40%,60%,80%,100%)
print(pd.cut(df["评分人数"],bins=np.percentile(df["评分人数"],[0,20,40,60,80,100]),labels=list("EDCBA")))
df["热门程度"]=pd.cut(df["评分人数"],bins=np.percentile(df["评分人数"],[0,20,40,60,80,100]),labels=list("EDCBA"))
print(df)
print(df[(df.热门程度=="A")&(df.评分等级=="D")]) #查询大烂片集合
print(df[(df.评分等级=="C")&(df.热门程度=="D")]) #高分冷门电影
3.4合并数据集
1、append
append主要是对两组数据集进行合并,它的函数形式是:
df2.append(df1):表示在df2的后面按照行的形式进行相应的合并,主要用于批量小数据之间的合并以及在表格中增加少量的行时进行的操作函数。
具体举例代码如下:
d1=df[df.评分>4.8]
d2=df[df.评分人数>10000]
print(d1)
print(d2)
d3=d2.append(d1)
print(d3)
2、merge
merge函数的各个输入参数如下:
#pd.merge(left,right,how="inner",on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=True,suffixes=("_x","_y"),copy=True,indicator=False)
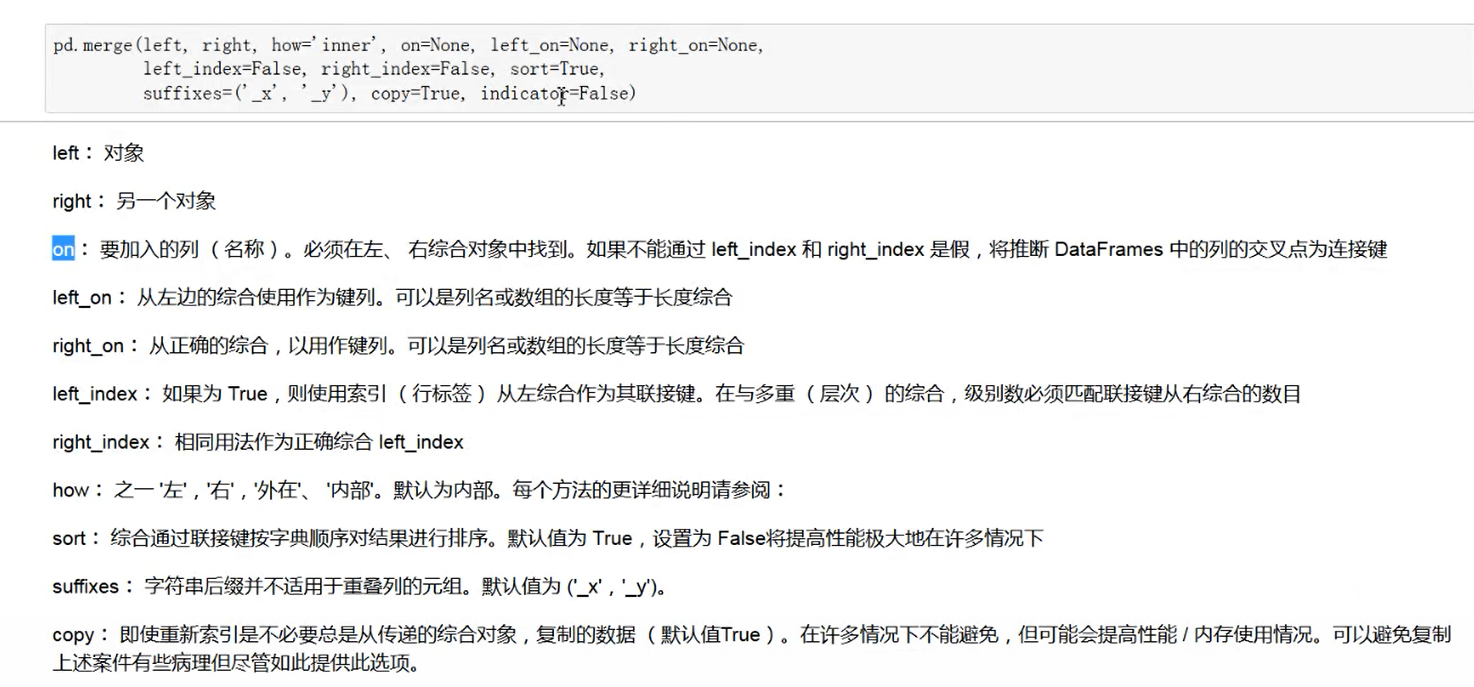

它是数据表格合并最为常用的函数形式,可以实现比较多种类不同合并要求的表格之间的合并
具体举例代码如下:
df1=df.loc[:5]
print(df1)
df2=df.loc[:5][["名字","类型"]]
print(df2)
df2["票房"]=["1234","12345","1234567","23412","12456","125778"]
print(df2)
print(df2.sample(frac=1)) #打乱df2的数据排列
df2.index=range(len(df2))
print(df2)
print(pd.merge(df1,df2,how="inner",on="名字")) #合并1和2表格(按照独特的属性,不同列属性进行合并,相同的属性会产生_y的两行)
3、concat
concat主要进行多批量表格数据之间的合并,它的函数形形式如下:
concat([df1,df2...],axis=0/1) #df1,df2是指需要合并的表格数据,axis=0/1决定了表格之间合并的方式是行之间合并还是列之间合并。
具体举例代码如下:
df1=df[:10]
df2=df[100:110]
df3=df[200:210]
print(pd.concat([df1,df2,df3],axis=0)) #axis=0/1的作用是设置不同的表格之间合并的方式是行合并还是列合并
整体的入门运行代码如下所示(可以直接拷贝运行,含有详细的代码注释,可以轻松帮助你入门理解):
import numpy as np
import pandas as pd #导入相应的pandas模块和numpy模块
df=pd.read_excel("D:/Byrbt2018/Study/Python数据分析课程+练习+讲解/Python数据分析课程+练习+讲解/作业/作业4/作业4/酒店数据1.xlsx")#导入w我们的表格数据文件
pd.set_option("max_columns",1000) #设置pyhton输出数据的行和列的最大行数目(大于设定值之后才会出现省略号)
pd.set_option("max_rows",1000)
print(df) #输出表格文件 #3.1数据重塑与轴向旋转
s=pd.Series(range(1,10),index=[["a","a","a","b","b","c","c","d","d"],[1,2,3,1,2,3,1,2,3]])
#多层次索引列表的定义
print(s)
print(s.index)
print(s["a"])
print(s["a":"c"]) #进行外层索引,直接用s[]即可
print(s["a",1]) #多层索引需要用到[,]
print(s.unstack())#利用unstack可以将series转换为dataframe
s1=s.unstack()
print(s1.fillna(0)) #将其中的空值填充为0
da=pd.DataFrame(np.arange(12).reshape(4,3),index=[["a","a","b","b"],[1,2,1,2]],columns=[["A","A","B"],["Z","X","C"]]) #定义一个4x3的表格文件
#多层次索引表格的定义
print(da)
print(da["A"])
da.index.names=["row1","row2"] #对于行每次索引的命名
da.columns.names=["col1","col2"] #对于列每次索引的命名
print(da)
print(da.swaplevel("row1","row2")) #行属性的调换函数
print(df.index)
df=df.set_index(["地区","类型"]) #将表格中的一些列直接设置为索引
print(df)
print(df.index[0]) #输出多层索引为元组
print(df.loc["东区"]["评分人数"]) #输出索引为东区的所有评分人数的列数据
print(df.loc["中西区","商务出行"]["评分人数"]) #多索引输出数据
df=df.reset_index() #取消层次化索引
print(df[:5])
#数据轴向旋转
da=df[:5]
print(da)
print(da.T) #对于表格数据进行行和列的交换用df,T函数
print(da)
print(da.stack()) #利用stack()可以将dataframe转换为series
print(da.stack().unstack()) #利用stack()可以将dataframe转换为series,然后再利用unstack()可以转换过来成为原始的dataframe #3.2数据的分组与分组运算(主要是groupby技术的应用)
g=df.groupby(df["地区"]) #按照地区家进行汇总
print(type(g))
print(g.mean())
print(df["评分"].groupby(df["类型"]).mean()) #查询不同类型胡平均评分
#对于多个分组变量进行分组
print(df.groupby([df["地区"],df["类型"]]).mean())
print(df.pivot_table(df,index=["地区","类型"],aggfunc=np.mean))
a=df.pivot_table(df,index=["地区","类型"],aggfunc=np.mean)
b=df.groupby([df["地区"],df["类型"]]).mean()
#以上两个函数df.pivot_table和groupby的操作作用a和b一样的
print(df["评分"].groupby([df["地区"],df["类型"]]).mean())
print(df["评分"].groupby([df["地区"],df["类型"]]).mean().unstack())
print(df["评分"].groupby([df["地区"],df["类型"]]).mean().unstack().fillna(0)) #3.3.数据离散化处理
print(df["评分"])
print(pd.cut(df["评分"],[0,4.2,4.5,4.8,5.0],labels=list("DCBA")))
df["评分等级"]=pd.cut(df["评分"],[0,4.2,4.5,4.8,5.0],labels=list("DCBA"))
print(df)
print(pd.cut(df["评分人数"],bins=np.percentile(df["评分人数"],[0,20,40,60,80,100]),labels=list("EDCBA")))
df["热门程度"]=pd.cut(df["评分人数"],bins=np.percentile(df["评分人数"],[0,20,40,60,80,100]),labels=list("EDCBA"))
print(df)
print(df[(df.热门程度=="A")&(df.评分等级=="D")]) #查询大烂片集合
print(df[(df.评分等级=="C")&(df.热门程度=="D")]) #高分冷门电影print(pd.cut(df["评分"],[0,4.2,4.5,4.8,5.0],labels=list("DCBA")))
df["评分等级"]=pd.cut(df["评分"],[0,4.2,4.5,4.8,5.0],labels=list("DCBA"))
print(df)
print(pd.cut(df["评分人数"],bins=np.percentile(df["评分人数"],[0,20,40,60,80,100]),labels=list("EDCBA")))
df["热门程度"]=pd.cut(df["评分人数"],bins=np.percentile(df["评分人数"],[0,20,40,60,80,100]),labels=list("EDCBA"))
print(df)
print(df[(df.热门程度=="A")&(df.评分等级=="D")]) #查询大烂片集合
print(df[(df.评分等级=="C")&(df.热门程度=="D")]) #高分冷门电影 #3.4合并数据集
#1、append合并数据集
d1=df[df.评分>4.8]
d2=df[df.评分人数>10000]
print(d1)
print(d2)
d3=d2.append(d1)
print(d3)
#2、merge
#merge函数的各个输入参数如下:
#pd.merge(left,right,how="inner",on=None,left_on=None,right_on=None,left_index=False,right_index=False,sort=True,suffixes=("_x","_y"),copy=True,indicator=False)
df1=df.loc[:5]
print(df1)
df2=df.loc[:5][["名字","类型"]]
print(df2)
df2["票房"]=["1234","12345","1234567","23412","12456","125778"]
print(df2)
print(df2.sample(frac=1)) #打乱df2的数据排列
df2.index=range(len(df2))
print(df2)
print(pd.merge(df1,df2,how="inner",on="名字")) #合并1和2表格(按照独特的属性,不同列属性进行合并,相同的属性会产生_y的两行)
#3、concat:多个数据集的批量合并
df1=df[:10]
df2=df[100:110]
df3=df[200:210]
print(pd.concat([df1,df2,df3],axis=0)) #axis=0/1的作用是设置不同的表格之间合并的方式是行合并还是列合并

运行结果如下所示:

python中pandas数据分析基础3(数据索引、数据分组与分组运算、数据离散化、数据合并)的更多相关文章
- python pandas数据分析基础入门2——(数据格式转换、排序、统计、数据透视表)
//2019.07.18pyhton中pandas数据分析学习——第二部分2.1 数据格式转换1.查看与转换表格某一列的数据格式:(1)查看数据类型:某一列的数据格式:df["列属性名称&q ...
- pyhton pandas数据分析基础入门(一文看懂pandas)
//2019.07.17 pyhton中pandas数据分析基础入门(一文看懂pandas), 教你迅速入门pandas数据分析模块(后面附有入门完整代码,可以直接拷贝运行,含有详细的代码注释,可以轻 ...
- pyhton中pandas数据分析模块快速入门(非常容易懂)
//2019.07.16python中pandas模块应用1.pandas是python进行数据分析的数据分析库,它提供了对于大量数据进行分析的函数库和各种方法,它的官网是http://pandas. ...
- Python中pandas模块解析
Pandas基于两种数据类型: series 与 dataframe . 1.Series 一个series是一个一维的数据类型,其中每一个元素都有一个标签.类似于Numpy中元素带标签的数组.其中, ...
- python中并发编程基础1
并发编程基础概念 1.进程. 什么是进程? 正在运行的程序就是进程.程序只是代码. 什么是多道? 多道技术: 1.空间上的复用(内存).将内存分为几个部分,每个部分放入一个程序,这样同一时间在内存中就 ...
- python中网络编程基础
一:什么是c\s架构 1.c\s即client\server 客户端\服务端架构. 客户端因特定的请求而联系服务器并发送必要的数据等待服务器的回应最后完成请求 服务端:存在的意义就是等待客户端的请求, ...
- 简单介绍下python中函数的基础语法
python 函数 定义 函数是指将一组语句的集合通过一个名字(函数名)封装起来,要想执行这个函数,只需调用其函数名即可. 特性 减少代码重复 使程序变得可扩展 使程序变得易于维护 函数的创建 pyt ...
- python中pandas里面的dataframe数据的筛选小结
pandas大家用的都很多,像我这种用的不够熟练,也不够多的就只能做做笔记,尽量留下点东西吧. 筛选行: a. 按照列的条件筛选 df = pandas.DataFrame(...) # suppos ...
- [转]python中pandas库中DataFrame对行和列的操作使用方法
转自:http://blog.csdn.net/u011089523/article/details/60341016 用pandas中的DataFrame时选取行或列: import numpy a ...
随机推荐
- python爬虫(七) mozillacookiejar
MozillaCookiejar 保存百度得Cookiejar信息: from urllib import request from urllib import parse from http.coo ...
- 【转载】Cmd Markdown 公式指导手册
目录 Cmd Markdown 公式指导手册 一.公式使用参考 1.如何插入公式 2.如何输入上下标 3.如何输入括号和分隔符 4.如何输入分数 5.如何输入开方 6.如何输入省略号 7.如何输入矢量 ...
- USN日志
转载:https://www.iteye.com/blog/univasity-805234 https://blog.51cto.com/velika/1440105 源码:https://f ...
- 学习SpringMVC 文件上传 遇到的问题,403:returned a response status of 403 Forbidden ,409文件夹未找到
问题一: 409:文件夹没有创建好,找不到指定的文件夹,创建了即可. 问题二: 403:returned a response status of 403 Forbidden 我出现这个错误的原因是因 ...
- LeetCode刷题--21.合并两个有序链表(简单)
题目描述 将两个有序链表合并为一个新的有序链表并返回.新链表是通过拼接给定的两个链表的所有节点组成的. 示例: 输入:1 -> 2 -> 4 ,1 -> 3 -> 4 输出:1 ...
- 基于IntelliJ IDEA的代码评审插件 Code Review Plugin
一.阿里规范公约 1.左上角 File -> Settings -> Plugins -> 搜索:Alibaba Java Coding Guidelines,安装插件并重启IDEA ...
- java并发:初探消费者和生产者模式
消费者和生产者模式 用继承Thread方式,用wait和notifyAll方法实现. 消费者和生产者模式的特点 1. 什么时候生产:仓库没有满的时候,生产者这可以生产,消费者也可以消费,仓库满的时候停 ...
- Keras入门——(6)长短期记忆网络LSTM(三)
参考: https://blog.csdn.net/u012735708/article/details/82769711 https://zybuluo.com/hanbingtao/note/58 ...
- springcloud gateway 项目打包部署运行
新建一个springboot项目然后做了一个小demo跳转到baidu pom <?xml version="1.0" encoding="UTF-8"? ...
- JS enter键一键登录
$("body").keydown(function (event) { ) { //enter键键值为13 $('.finish-btn').click(); // $('.fi ...