文献阅读报告 - Social BiGAT + Cycle GAN
原文文献
Social BiGAT : Kosaraju V, Sadeghian A, Martín-Martín R, et al. Social-BiGAT: Multimodal Trajectory Forecasting using Bicycle-GAN and Graph Attention Networks[C]//Advances in Neural Information Processing Systems. 2019: 137-146.
Cycle GAN : Zhu J Y, Park T, Isola P, et al. Unpaired image-to-image translation using cycle-consistent adversarial networks[C]//Proceedings of the IEEE international conference on computer vision. 2017: 2223-2232.

Highlights
- 多元化特征抽取与注意力机制:使用VGG网络提取场景图像特征,使用LSTM提取行人轨迹特征,使用基于Scale-Dot和GAT的注意力机制合成预测轨迹的最终特征向量。
- 基于Cycle GAN增强预测的多元化:异于Info-GAN模型,采用了新模型结构和训练方法,以保证GAN网络生成轨迹时对Latent Code的敏感性,从而有助于轨迹生成的MultiModel特性。使用了两个G网分别负责\(noise \rightarrow_G trajectory\)和\(trajectory \rightarrow_G noise\),并定义了一致性损失(Consistence Loss)和循环型的多步训练方式\(z \rightarrow trajectory' \rightarrow z'\)和\(trajectory \rightarrow z' \rightarrow trajectory'\)(其中未带有 ' 的表示Ground Truth)。
- 有效的功能抽象与迁移能力:文章中体现了作者对各种模型适用性与差异性的有效理解,例如根据数据差异采用了GAT、Scale-Dot等多种注意力机制;并且能够从其他具体问题中举一反三,例如将Cycle GAN所适用的图像风格转换任务迁移至多元化路径生成,并重新定义设计了G网和D网的结构分布。
Summary
感谢之前有一位读者在向我推荐的Social BiGAT这篇文章,正逢这段时间有空,便仔细读一读,并也对其中的要点进行总结。Social BiGAT是继Social LSTM, Social GAN, SoPhie后的Social-Family新成员,从整体成果上来说是用Cycle-GAN和GAT网络的新方法更好解决在Social GAN时提出的老问题:
- 社会交互(Social Interaction)
- 静态场景(Context Cues)
- 预测的多元性(Multimodal prediction)
同时,从整体上来看,Social BiGAT其实已有向模型融合的趋势发展,对于模型结构的使用有显著的工具箱特点,就像是先明确问题而后从备选模型中信手拈来进行拼接。训练与测试数据仍采用ETH和UCY数据库,最外层仍然是GAN模型的结构(注意仅仅是结构,模型在训练上与GAN存在比较大的差异):
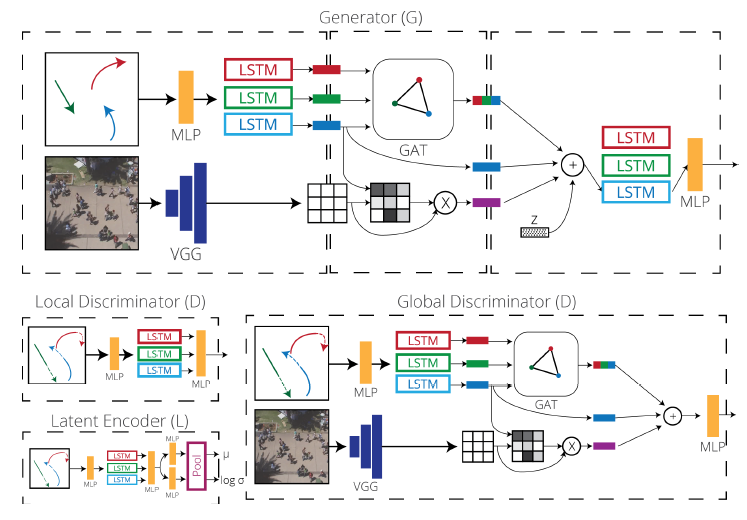
- 对于G网:在使用LSTM的Decoder进行轨迹预测生成前,加入了噪音和多类Encoder进行特征提取并恰当地使用多种注意力结构,进过注意力机制处理的拼接向量经过递交给Decoder进行预测。
- 对于D网,分成了两个,分别探讨轨迹在整体环境中和局部环境中的合理性,核心作用是促进G网生成与真实轨迹”无法分辨“(indistinguishable)的轨迹。
- 此外,为保证模型对噪音反应的敏感性和合理性,Social BiGAT还借鉴了Cycle GAN的思想,引入了由预测轨迹反推噪音的Latent Encoder(本质上就是Cycle GAN中的逆向生成网F),并结合多步训练的模式与方法建立了噪音与预测轨迹之间的双射关系,最终更好地解决了预测结果多元性的问题。
由于BiGAT具有模型融合的特点,其中一些思想方法其实已经在之前研究中已有提出,例如:
- 使用层数和已知路径时序相同的GAT网络,每一层中以结点为行人,以同层边代表交互,处理Social Interaction。
- 使用标准的Q-K-V注意力机制,针对每一个行人提取经过CNN网络后的背景特征中的有效信息,处理Context Cues。
因此我将侧重在本模型中所新采用的Cycle GAN结构,首先介绍Cycle GAN原文中任务与模型,而后分析BiGAT的作者是如何不等价但等效地将Cycle GAN用到<噪音 - 预测轨迹>这一对组合上。
Cycle GAN
概览
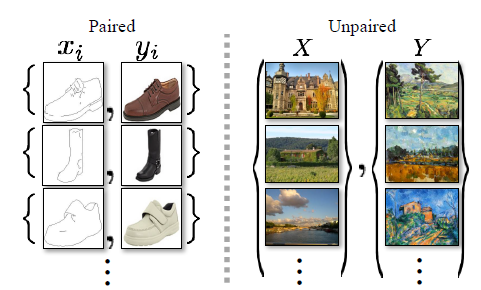
Cycle GAN可以被理解为一种Autoencoder(自编码器),最初提出时,旨在解决图像翻译(Image-to-Image Translation)中缺乏配对(Paired)数据的问题,缺少配对数据一方面是因为人工标注在某些领域中存在困难:例如绘画风格迁移,很少存在能够准确在现实世界中找到一幅画作中的风景;而另一方面是因为人工标注的数据总量比较有限。
因此,文章决定在训练时从更大的范围和抽象上进行,模型原本需要建立一一对应的配对(Paired)数据的映射,而现在仅需要建立两个图像集合之间(不需要数据之间配对)的映射。
因此对于参与模型训练的数据,如果严格从单个图像级的标签角度,则属于非监督学习,而如果上升至图像集合的级别,其实又属于监督学习。
模型结构
朴素模型:建立GAN网络,G网络学习\(X \rightarrow Y\)的映射,而D网作用则是激励G网生成的图像与真实图像无法分辨。
朴素模型问题:
- 约束不足:由于训练G网时是建立在集合层级(Set Level)的,即D网和目标函数仅能约束G网建立向目标集合的映射。因此模型所习得的向目标集合的映射其实是有无穷无尽的可能,这其中只有少部分是真正所期望的映射。
- 模式坍塌:在实际实验中,模型习得的映射使得不同输入都到达同样的输出,使得优化停止。
使用循环网络约束映射:
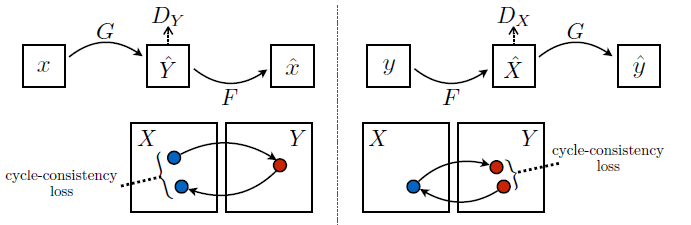
由于不存在严格的配对数据,因此基于目标集合\(Y\)构造目标函数并不可行,因此模型使用了一种较为经典的依托传递性(transitivity)的循环一致性损失(Cycle Consistency Loss)对生成模型加以更强的约束。具体来说,模型在结构和训练上均有特点:
- 模型:定义了”两套“GAN网络<\(G, D_Y\)>和<\(F, D_X\)>,分别致力于使用生成对抗式网络实现集合(域)X和Y之间的相互映射。
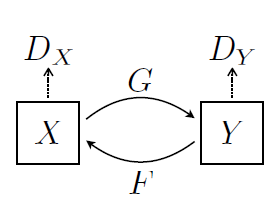
- 训练:两套GAN网络无法独立训练,需通过\(x \rightarrow G(x) \rightarrow F(G(x)) \sim x\)和\(y \rightarrow F(y) \rightarrow G(F(y)) \sim y\)两步数据流进行训练。
训练时的两类数据流构成了多步训练,前者称作forward cycle consistency,后者称作backward cycle consistency。文章中仅通过实验结果的方式证明两类一致性约束训练缺一不可,但笔者并没有找到理论上的一些猜想和假设,该部分有待进一步研究。
因此,对于综合GAN网络的损失和一致性损失,共同形成了整个网络的目标函数:
- \(L(G,F,D_X,D_Y) = L_{GAN}(G,D_Y) + L_{GAN}(F,D_X) + \lambda L_{cyc}(G,F)\)
- \(L_{GAN}(G,D_Y) = E_{y\sim p_{data}}[logD_Y(y)]+E_{x\sim p_{data}}[log(1 - D_Y(G(x)))]\)
- \(L_{GAN}(F,D_X) = E_{x\sim p_{data}}[logD_X(x)]+E_{y\sim p_{data}}[log(1 - D_X(F(y)))]\)
- \(L_{cyc}(G,F) = E_{x\sim p_{data}}||F(G(x))-x||_1 + E_{y\sim p_{data}}||G(F(y))-y||_1\)
使用Cycle GAN生成多轨迹的预测
训练与目标函数
BiGAT使用了Cycle GAN的思想以更好地实现模型对多条可行性轨迹的预测,整体上是为Cycle GAN找到了一个新的应用方向,但从细节上,由于任务类型的不同BiGAT还是需要据实进行修改,在这里笔者先贴出模型的训练过程和最终目标函数,再逐个分析其与原模型各部分的对应情况。
目标函数和训练过程沿用原模型由两部分组成,第一步是\(z \rightarrow Y' \rightarrow z'\)的前向循环,第二步是\(Y \rightarrow z' \rightarrow Y'\)的前向约束。
\(G*,D*,E* = argmin_{G,E}argmax_D(L_{gan1} + L_z + L_{gan2} + L_{traj} + L_{kl})\)
- 在前向约束中,由\(G-D_1\)网目标函数和噪音z的一致性目标函数组成:
- \(L_{gan1} = E(logD(X_i,Y_i)) + E(log(1 - D(X_i,\hat Y_i)))\)
- \(L_z = ||E(\hat Y_i) - z||_1\)
- 在后向约束中,由\(G-D_2\)网目标函数,路径Y的一致性目标函数和L网的生成分布目标函数组成:
- \(L_{gan2} = E(logD(X_i,Y_i)) + E(log(1 - D(X_i,G(X_i,E(Y_i)))))\)
- \(L_{traj} = ||Y_i - G(X_i, E(Y_i))||_2\)
- \(L_{kl} = E[D_{kl}(E(Y_i)||N(0,I))]\)
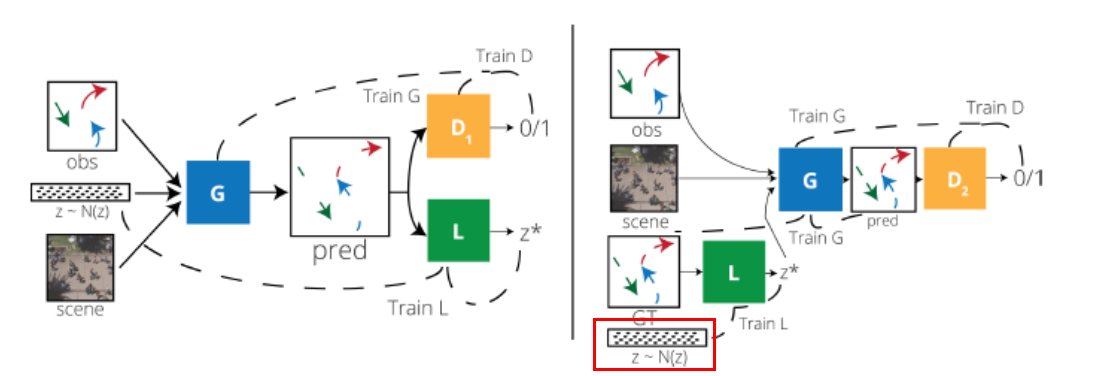
BiGAT与Cycle GAN等效性分析
如果没有阅读过Cycle GAN原文(其实就算阅读了),这部分初看也有些眼花缭乱,和原本的Cycle GAN的差异还是比较大的,但如果再仔细揣摩,会发现二者在原理上实属相同,这其实也是作者对网络模型功能深度理解与灵活运用的体现。
- 此前需要明确的是,BiGAT只将循环GAN用在了输入噪音z与生成轨迹之间,其他的输入例如轨迹、场景等会参与该过程,但不是该问题的主角,可以被抽象为一个无关的编码输入。
- 首先,是BiGAT各网络模块在Cycle GAN中的对应关系:生成轨迹的G网连通其轨迹场景等编码器 + \(D_1\) + \(D_2\)三部分负责\(z \rightarrow traj\)的映射,而L网则负责\(traj \rightarrow z\)的映射。不同于Cycle GAN中的两对GAN<\(G,D\)>和\(<F,D>\)负责两个相反方向的映射,BiGAT中的两个D网均用于建立\(z \rightarrow traj\)方向的映射,而E网(图中的L模块)无需独立的D网即可被训练出\(traj \rightarrow z\)的映射,这也反映了GAN网络的设置是方便于训练映射,而不是必须的。
- 而后,是各目标函数与Cycle GAN中的对应关系:
- \(z \rightarrow traj\) 映射目标函数:\(L_{gan1}, L_{gan2}\)
- \(traj \rightarrow z\) 映射目标函数:\(L_{gan2}, L_{kl}\)。由此可知E网(反向映射网)的训练是依托于正向映射判别器的,而非Cycle GAN中对称地划分。(KL散度辅助生成正态分布)
- 一致性目标函数:\(L_{traj}, L_z\)
在BiGAT中,对于L模块(E网)的训练是基于真实路径利用E网得到的噪音z'再参与生成的路径是否被判别器D2识别,但若直接使用Cycle GAN中的想法,则是真实路径经过E网得到的噪音z‘是否满足为判别器所接受,笔者在此的一种想法是将[Y,E(Y)]输入一个判别器D3,用以训练E网建立正确的映射。>
文献阅读报告 - Social BiGAT + Cycle GAN的更多相关文章
- 文献阅读报告 - Social GAN: Socially Acceptable Trajectories with Generative Adversarial Networks
paper:Gupta A , Johnson J , Fei-Fei L , et al. Social GAN: Socially Acceptable Trajectories with Gen ...
- 文献阅读报告 - Social Ways: Learning Multi-Modal Distributions of Pedestrian Trajectories with GANs
文献引用 Amirian J, Hayet J B, Pettre J. Social Ways: Learning Multi-Modal Distributions of Pedestrian T ...
- 文献阅读报告 - Social LSTM:Human Trajectory Prediction in Crowded Spaces
概览 简述 文献所提出的模型旨在解决交通中行人的轨迹预测(pedestrian trajectory prediction)问题,特别是在拥挤环境中--人与人交互(interaction)行为常有发生 ...
- 文献阅读报告 - Situation-Aware Pedestrian Trajectory Prediction with Spatio-Temporal Attention Model
目录 概览 描述:模型基于LSTM神经网络提出新型的Spatio-Temporal Graph(时空图),旨在实现在拥挤的环境下,通过将行人-行人,行人-静态物品两类交互纳入考虑,对行人的轨迹做出预测 ...
- 文献阅读报告 - 3DOF Pedestrian Trajectory Prediction
文献 Sun L , Yan Z , Mellado S M , et al. 3DOF Pedestrian Trajectory Prediction Learned from Long-Term ...
- 文献阅读报告 - Move, Attend and Predict
Citation Al-Molegi A , Martínez-Ballesté, Antoni, Jabreel M . Move, Attend and Predict: An Attention ...
- 文献阅读报告 - Pedestrian Trajectory Prediction With Learning-based Approaches A Comparative Study
概述 本文献是一篇文献综述,以自动驾驶载具对外围物体行动轨迹的预测为切入点,介绍了基于运动学(kinematics-based)和基于机器学习(learning-based)的两大类预测方法. 并选择 ...
- 文献阅读报告 - Context-Based Cyclist Path Prediction using RNN
原文引用 Pool, Ewoud & Kooij, Julian & Gavrila, Dariu. (2019). Context-based cyclist path predic ...
- 文献阅读笔记——group sparsity and geometry constrained dictionary
周五实验室有同学报告了ICCV2013的一篇论文group sparsity and geometry constrained dictionary learning for action recog ...
随机推荐
- gitlab的搭建与使用(一)
yum install curl policycoreutils openssh-server openssh-clients postfix -y systemctl enable sshd sys ...
- C程序的执行和当前进程的结束
内核使程序执行的唯一方法,就是调用exec函数,这个函数又会启动一个C程序启动例程,这个启动例程是C程序的启动地址.负责调用main函数,并接受mainn函数的返回值. 使得进程结束的唯一方式是隐式的 ...
- 动态代理Cglib
jar包 <!-- https://mvnrepository.com/artifact/cglib/cglib --><dependency> <groupId> ...
- MySql向SQLServer迁移常见问题
-- MySql与SQLServer update inner join语法区别-- MySql: UPDATE A LEFT JOIN B ON A.B_ID = B.B_ID SET A.A_NA ...
- HDU 5565:Clarke and baton
Clarke and baton Accepts: 14 Submissions: 79 Time Limit: 12000/6000 MS (Java/Others) Memory Limi ...
- 任意promise串行执行算法 - 童彪
// 任意promise串行执行算法 - 童彪 function runAllPromise() { var p1 = new Promise((resove, reject) => { s ...
- JS监听video视频播放时间
采用原生时间监听element.addEventListener(event, function, useCapture) //监听播放时间 var video = document.getEleme ...
- Linux centosVMware vim 编辑模式、vim命令模式、vim实践
一.编辑模式.命令模式 在一般模式下输入:或/可进入命令模式.在该模式下可进行走索某个字符或字符串,也可保存.替换.退出.显示行号等. /word:在光标之后查找一个字符串word,按n向后继续搜索 ...
- 《C++ Primer(中文版)(第5版)》斯坦利·李普曼 (Stanley B. Lippman) (作者), 约瑟·拉乔伊 (Josee Lajoie) (作者), 芭芭拉·默 (Barbara E. Moo) (作者) azw3
内容简介: 这本久负盛名的C++经典教程,时隔八年之久,终迎来的重大升级.除令全球无数程序员从中受益,甚至为之迷醉的——C++ 大师 Stanley B. Lippman 的丰富实践经验,C++标准委 ...
- unity3d Asset Store下载的资源在哪?
win7 C:\Users\(用户名)\AppData\Roaming\Unity\Asset Store\ 用户名为中文的时候,是不能直接在unity3d中打开的.