Python写一个简单的爬虫
爬取的目标网站:
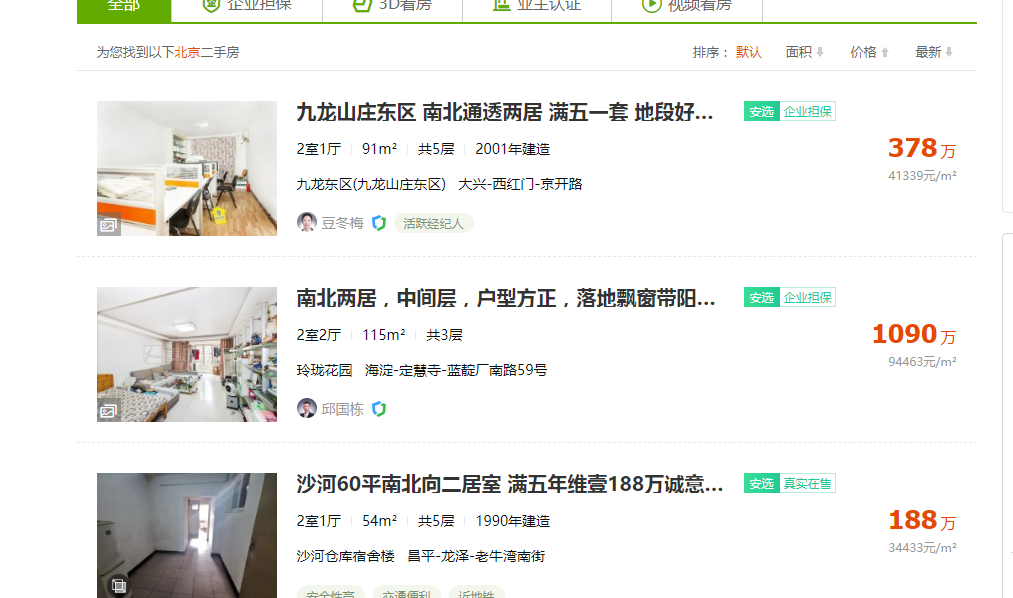
code
#!/usr/bin/env python
# -*- coding: utf-8 -*-
import requests
from lxml import etree class Main:
def __init__(self):
self.headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/69.0.3497.100 Safari/537.36',
}
self.url = "https://beijing.anjuke.com/sale/?pi=baidu-cpc-bj-tyong1&kwid=2341817153&utm_term=%e6%89%be%e6%88%bf&bd_vid=9128294385511928514" def lord(self):
response = requests.get(url=self.url, headers=self.headers).text
tree = etree.HTML(response)
# 将页面源码数据中的房子的名称和价格进行爬取
li_list = tree.xpath('//ul[@class="houselist-mod houselist-mod-new"]/li')
# 将li标签表示的局部页面内容指定数据进行解析
for li in li_list:
title = li.xpath('./div[2]/div[1]/a/text()')[0].strip()
describe = li.xpath('./div[2]/div[2]/span/text()')
site = li.xpath('./div[2]/div[3]/span/text()')[0].split()[1]
price = li.xpath('./div[3]/span[1]/strong/text()')
print('标题:{}\n描述:{}\n地点:{}\n价格{}万\n'.format(title, describe, site, price))
with open('date.txt','a+',encoding='utf-8') as f1:
f1.write('标题:{}\n描述:{}\n地点:{}\n价格{}万\n\n'.format(title, describe, site, price))
f1.close() if __name__ == '__main__':
obj = Main()
obj.lord()
输出结果

Python写一个简单的爬虫的更多相关文章
- 用node.js从零开始去写一个简单的爬虫
如果你不会Python语言,正好又是一个node.js小白,看完这篇文章之后,一定会觉得受益匪浅,感受到自己又新get到了一门技能,如何用node.js从零开始去写一个简单的爬虫,十分钟时间就能搞定, ...
- 用Python写一个简单的Web框架
一.概述 二.从demo_app开始 三.WSGI中的application 四.区分URL 五.重构 1.正则匹配URL 2.DRY 3.抽象出框架 六.参考 一.概述 在Python中,WSGI( ...
- python写一个简单的CMS识别
前言: 收集了一点cms路径,打算在写一个.之前已经写了 有需要的可以自己翻我的博客 思路: 网站添加路径判断是否为200,并且无过滤列表中的字符 代码: import requests import ...
- 利用python写一个简单的小爬虫 爬虫日记(1)(好好学习)
打开py的IDLE >>>import urllib.request >>>a=urllib.request.urlopen("http://www.ba ...
- Python运维三十六式:用Python写一个简单的监控系统
市面上有很多开源的监控系统:Cacti.Nagios.Zabbix.感觉都不符合我的需求,为什么不自己做一个呢? 用Python两个小时徒手撸了一个简易的监控系统,给大家分享一下,希望能对大家有所启发 ...
- 用python写一个简单的文件上传
用Pycharm创建一个django项目.目录如下: <!DOCTYPE html> <html lang="en"> <head> <m ...
- 使用python写一个简单的C段扫
纠结C段查询N久..刚刚拿骚棒FD去抓御剑的包,发现emmm...申请了必应的Key 然后去拿必应API查.这里疼[心]原本也想去弄的.但是人懒. 然后就没有然后了. 代码: 生成IP段的脚本图1 # ...
- golang写一个简单的爬虫
package main import( "fmt" "io/ioutil" "net/http" ) func gethtml(url s ...
- python (1)一个简单的爬虫: python 在windows下 创建文件夹并写入文件
1.一个简单的爬虫:爬取豆瓣的热门电影的信息 写在前面:如何创建本来存在的文件夹并写入 t_path = "d:/py/inn" #本来不存在inn,先定义路径,然后如果不存在,则 ...
随机推荐
- 吴裕雄 Bootstrap 前端框架开发——Bootstrap 表单:表单控件状态
<!DOCTYPE html> <html> <head> <meta charset="utf-8"> <title> ...
- C. Magic Grid 构造矩阵
C. Magic Grid time limit per test 1 second memory limit per test 256 megabytes input standard input ...
- ORACLE锁表问题
1.查询锁表的信息 select sess.sid,sess.serial#, lo.oracle_username,lo.os_user_name, ao.object_name,lo.locked ...
- 「JSOI2007」建筑抢修
传送门 Luogu 解题思路 显然先把所有楼按照报废时间递增排序. 然后考虑 \(1\cdots i-1\) 都能修完, \(i\) 修不完的情况. 显然我们在这 \(i\) 个里面至多只能修 \(i ...
- 【高软作业4】:Tomcat 观察者模式解析 之 Lifecycle
一. 预备 如果你是Windows用户,使用Eclipse,并且想自行导入源码进行分析,你可能需要:Eclipse 导入 Tomcat 源码 如果你已遗忘 观察者模式,那么你可以通过该文章回顾:设计模 ...
- 前端学习笔记系列一:15vscode汉化、快速复制行、网页背景图有效设置、 dl~dt~dd标签使用
ctrl+shift+p,调出configure display language,选择en或zh,若没有则选择安装使用其它语言,则直接呼出扩展程序搜索界面,选择,然后安装,重启即可. shift+a ...
- 线程与FORK
1.线程锁的问题 需要调用进程线程锁处理函数 prefork-----获取父亲进程锁----在fork掉用之前,目的是为了在子进程中获取到可释放的锁 parentfork----释放父亲进程锁 chi ...
- 最新获取 QQ头像 和 昵称接口
网上找来的测试可用... 获取QQ头像 http://q2.qlogo.cn/headimg_dl?bs=QQ号&dst_uin=QQ号&dst_uin=QQ号&;dst_ui ...
- swoole之建立 http server
一.代码部分 <?php /** * 传统:nginx <-> php-fpm(fast-cgi process manager) <-> php * swoole:ht ...
- 洛谷P2296 寻找道路
\(\Large\textbf{Description:} \large {在有向图 G 中,每条边的长度均为 1,现给定起点和终点,请你在图中找一条从起点到终点的路径,该路径满足以下条件:}\) \ ...