数据结构学习:二叉查找树的概念和C语言实现
什么是二叉查找树?
二叉查找树又叫二叉排序树,缩写为BST,全称Binary Sort Tree或者Binary Search Tree。
以下定义来自百度百科:
二叉排序树或者是一棵空树,或者是具有下列性质的二叉树:
- 若左子树不空,则左子树上所有节点的值均小于它的根节点的值;
- 若右子树不空,则右子树上所有节点的值均大于它的根节点的值;
- 左、右子树也分别为二叉排序树;
- 没有键值相等的节点。
二叉查找树C语言实现
二叉查找树是将数值比当前节点数值大的优先放到左子树,数值被当前节点大的放倒右子树;
C语言要实现以下几个接口:
- 查找节点;
- 插入节点;
- 删除节点;
查找节点
- 若根结点的关键字值等于查找的关键字,成功。
- 否则,若小于根结点的关键字值,递归查左子树。
- 若大于根结点的关键字值,递归查右子树。
- 若子树为空,查找不成功。
Positon search_tree_find(ElementType x, SearchTree root) {
if (root == NULL) {
return NULL;
}
if (x < root->value) {
root = search_tree_find(x, root->left);
}
else if (x < root->value) {
root = search_tree_find(x, root->right);
}
return root;
}
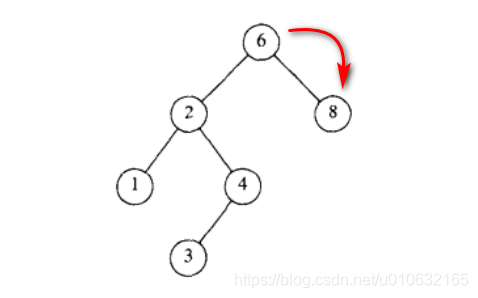
查找最大值
如下图所示找出最小值只需要递归查找右子树即可;
Positon search_tree_find_max(SearchTree root) {
if (root == NULL) {
return NULL;
}
if (root->right != NULL) {
root = search_tree_find_max(root->right);
}
return root;
}
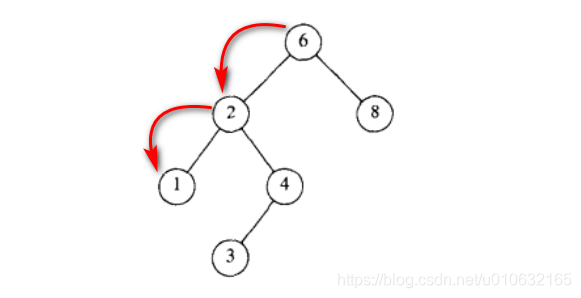
查找最小值
如下图所示找出最小值只需要递归查找左子树即可;
Positon search_tree_find_min(SearchTree root) {
if (root == NULL) {
return NULL;
}
if (root->left != NULL) {
root = search_tree_find_min(root->left);
}
return root;
}
插入节点
插入节点其实和查找节点类似,这里主要是递归得查找需要插入节点的位置,最终将节点插入,search_tree_insert最终会返回一个新的根,如下图所示,想要将5 插入到图中左侧的树中,递归查找的节点4之后,因为5大于4,所以需要往右下插入节点,但是传入的root-right == NULL成立,所以最终分配新节点,并将节点value赋值为5,然后返回一棵新树;

SearchTree search_tree_insert(ElementType x, SearchTree root) {
//如果是一棵空树,则新建一棵树
if (root == NULL) {
root = (SearchTree)malloc(sizeof(TreeNodeType));
if (root == NULL) {
return NULL;
}
root->value = x;
root->left = NULL;
root->right = NULL;
return root;
}
if (x < root->value) {
root->left = search_tree_insert(x, root->left);
}
else if (x > root->value) {
root->right = search_tree_insert(x, root->right);
}
return root;
}
删除节点
节点的删除,需要判断三种情况:
- 需要删除的是叶子节点(
直接删除节点即可); - 删除的节点只有一个子节点(
将父节点值替换为子节点,然后删除子节点即可); - 删除的节点有两个子节点(
用该节点右子树的最小节点来替换当前节点,然后将最小节点删除即可);
具体如下;删除情况如下;
1) Node to be deleted is leaf: Simply remove from the tree.
50 50
/ \ delete(20) / \
30 70 ---------> 30 70
/ \ / \ \ / \
20 40 60 80 40 60 80
2) Node to be deleted has only one child: Copy the child to the node and delete the child
50 50
/ \ delete(30) / \
30 70 ---------> 40 70
\ / \ / \
40 60 80 60 80
3) Node to be deleted has two children: Find inorder successor of the node. Copy contents of the inorder successor to the node and delete the inorder successor. Note that inorder predecessor can also be used.
50 60
/ \ delete(50) / \
40 70 ---------> 40 70
/ \ \
60 80 80
The important thing to note is, inorder successor is needed only when right child is not empty. In this particular case, inorder successor can be obtained by finding the minimum value in right child of the node.
附录
search_tree.h
#ifndef SEARCH_TREE
#define SEARCH_TREE
#ifdef __cplusplus
extern "C" {
#endif
#include <stdio.h>
typedef int ElementType;
typedef struct TreeNode TreeNodeType;
typedef TreeNodeType * SearchTree;
typedef TreeNodeType * Positon;
struct TreeNode
{
ElementType value;
TreeNodeType *left;
TreeNodeType *right;
};
SearchTree search_tree_make_empty(SearchTree root);
Positon search_tree_find(ElementType x, SearchTree root);
Positon search_tree_find_max(SearchTree root);
Positon search_tree_find_min(SearchTree root);
SearchTree search_tree_insert(ElementType x, SearchTree root);
SearchTree search_tree_delete(ElementType x, SearchTree root);
void search_tree_print(SearchTree root);
#ifdef __cplusplus
}
#endif
#endif // !SEARCH_TREE
search_tree.c
#include "search_tree.h"
SearchTree search_tree_make_empty(SearchTree root) {
if (root != NULL) {
search_tree_make_empty(root->left);
search_tree_make_empty(root->right);
}
return NULL;
}
Positon search_tree_find(ElementType x, SearchTree root) {
if (root == NULL) {
return NULL;
}
if (x < root->value) {
root = search_tree_find(x, root->left);
}
else if (x < root->value) {
root = search_tree_find(x, root->right);
}
return root;
}
Positon search_tree_find_max(SearchTree root) {
if (root == NULL) {
return NULL;
}
if (root->right != NULL) {
root = search_tree_find_max(root->right);
}
return root;
}
Positon search_tree_find_min(SearchTree root) {
if (root == NULL) {
return NULL;
}
if (root->left != NULL) {
root = search_tree_find_min(root->left);
}
return root;
}
SearchTree search_tree_insert(ElementType x, SearchTree root) {
//如果是一棵空树,则新建一棵树
if (root == NULL) {
root = (SearchTree)malloc(sizeof(TreeNodeType));
if (root == NULL) {
return NULL;
}
root->value = x;
root->left = NULL;
root->right = NULL;
return root;
}
if (x < root->value) {
root->left = search_tree_insert(x, root->left);
}
else if (x > root->value) {
root->right = search_tree_insert(x, root->right);
}
return root;
}
SearchTree search_tree_delete(ElementType x, SearchTree root) {
TreeNodeType *tmpNode = NULL;
if (root == NULL) {
return NULL;
}
if (x < root->value) {
root->left = search_tree_delete(x, root->left);
}
else if (x > root->value) {
root->right = search_tree_delete(x, root->right);
}
else {
// have two subtrees
if (root->left && root->right) {
tmpNode = search_tree_find_min(root->right);
root->value = tmpNode->value;
root->right = search_tree_delete(tmpNode->value, root->right);
}
// only have one subtree
else {
tmpNode = root;
if (root->left != NULL) {
root = root->left;
}
if (root->right != NULL) {
root = root->right;
}
free(tmpNode);
}
}
return root;
}
#define SIZE 50
void search_tree_print(SearchTree root) {
int head = 0, tail = 0;
TreeNodeType *p[SIZE] = { NULL };
TreeNodeType *tmp;
TreeNodeType *last = root;
TreeNodeType *nlast = root;
if (root != NULL) {
p[head] = root;
tail++;
// Do Something with p[head]
}
else {
return;
}
//环形队列作为缓冲器
while (head % SIZE != tail % SIZE) {
tmp = p[head % SIZE];
// Do Something with p[head]
printf("%d ", tmp->value);
if (tmp->left != NULL) { // left
p[tail++ % SIZE] = tmp->left;
nlast = tmp->left;
}
if (tmp->right != NULL) { // right
p[tail++ % SIZE] = tmp->right;
nlast = tmp->right;
}
if (last == tmp) {
printf("\n");
last = nlast;
}
head++;
}
return;
}
main.cpp
#include <iostream>
#include "search_tree.h"
using namespace std;
int main() {
SearchTree tmp = NULL;
SearchTree search_tree = NULL;
search_tree = search_tree_make_empty(search_tree);
search_tree = search_tree_insert(50, search_tree);
search_tree = search_tree_insert(40, search_tree);
search_tree = search_tree_insert(30, search_tree);
search_tree = search_tree_insert(60, search_tree);
search_tree = search_tree_insert(70, search_tree);
search_tree = search_tree_insert(80, search_tree);
search_tree_print(search_tree);
tmp = search_tree_find_min(search_tree);
printf("min value is %d\n", tmp->value);
printf("address is 0x%08x\n", tmp);
tmp = search_tree_find_max(search_tree);
printf("max value is %d\n", tmp->value);
printf("address is 0x%08x\n", tmp);
search_tree = search_tree_delete(50, search_tree);
search_tree_print(search_tree);
search_tree = search_tree_delete(70, search_tree);
search_tree_print(search_tree);
getchar();
return 0;
}
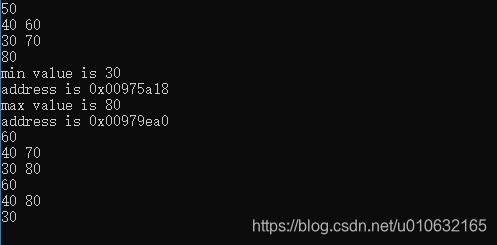
执行结果如下:
数据结构学习:二叉查找树的概念和C语言实现的更多相关文章
- 数据结构:二叉查找树(C语言实现)
数据结构:二叉查找树(C语言实现) ►写在前面 关于二叉树的基础知识,请看我的一篇博客:二叉树的链式存储 说明: 二叉排序树或者是一棵空树,或者是具有下列性质的二叉树: 1.若其左子树不空,则左子树上 ...
- Prolog学习:基本概念 and Asp.net与Dojo交互:仪器仪表实现
Asp.net与Dojo交互:仪器仪表实现 项目中需要用到仪器仪表的界面来显示实时的采集信息值,于是便遍地寻找,参考了fusionchart和anychart之后,发现都是收费的,破解的又没有这些功能 ...
- 编译原理(一)绪论概念&文法与语言
绪论概念&文法与语言 以老师PPT为标准,借鉴部分教材内容,AlvinZH学习笔记. 绪论基本概念 1. 低级语言:字位码.机器语言.汇编语言.与特定的机器有关,功效高,但使用复杂.繁琐.费时 ...
- Docker学习之基本概念
Docker学习之基本概念 作为一个后端noder,不了解docker有点说不过去,这节开始,学习一些docker层面的东西. 什么是docker Docker最初是dotCloud公司创始人Solo ...
- 前端学习 第三弹: JavaScript语言的特性与发展
前端学习 第三弹: JavaScript语言的特性与发展 javascript的缺点 1.没有命名空间,没有多文件的规范,同名函数相互覆盖 导致js的模块化很差 2.标准库很小 3.null和unde ...
- 算法设计和数据结构学习_5(BST&AVL&红黑树简单介绍)
前言: 节主要是给出BST,AVL和红黑树的C++代码,方便自己以后的查阅,其代码依旧是data structures and algorithm analysis in c++ (second ed ...
- Oracle RAC学习笔记:基本概念及入门
Oracle RAC学习笔记:基本概念及入门 2010年04月19日 10:39 来源:书童的博客 作者:书童 编辑:晓熊 [技术开发 技术文章] oracle 10g real applica ...
- Java IO学习笔记:概念与原理
Java IO学习笔记:概念与原理 一.概念 Java中对文件的操作是以流的方式进行的.流是Java内存中的一组有序数据序列.Java将数据从源(文件.内存.键盘.网络)读入到内存 中,形成了 ...
- C++数据结构之二叉查找树(BST)
C++数据结构之二叉查找树(BST) 二分查找法在算法家族大类中属于“分治法”,二分查找的过程比较简单,代码见我的另一篇日志,戳这里!因二分查找所涉及的有序表是一个向量,若有插入和删除结点的操作,则维 ...
随机推荐
- E - Roaming Atcoder
题解:https://blog.csdn.net/qq_40655981/article/details/104459253 题目大意:n个房间,,每个房间都有一个人,一共k天,在一天,一个人可以到任 ...
- [数据库]Mysql蠕虫复制增加数据
将查询出来的数据插入到指定表中,例: 将查询user表数据添加到user表中,数据会成倍增加 insert into user(uname,pwd) select uname,pwd from use ...
- 最全的 API 接口集合
对于程序员来说,为自己的程序选择一些合适的API并不是那么简单,有时候还会把你搞得够呛,今天猿妹要和大家分享一个开源项目,这个项目汇集了各种开发的api,涵盖了音乐.新闻.书籍.日历等,无论你是从事W ...
- ES6中对数组的扩展
hello,大家好,我又来了. 前面讲了字符串和数值的扩展,今天要讲的是:数组的扩展.不知道大家能否跟得上这个节奏,你们在阅读中对讲解有存在疑惑,记得留言提出来,要真正地理解,否则白白 ...
- javascript-数组简单的认识
一起组团(什么是数组) 我们知道变量用来存储数据,一个变量只能存储一个内容.假设你想存储10个人的姓名或者存储20个人的数学成绩,就需要10个或20个变量来存储,如果需要存储更多数据,那就会变的更麻烦 ...
- umditor删除域名,配置为绝对路径
getAllPic: function (sel, $w, editor) { var me = this, arr = [], $imgs = $(sel, $w); $.each($imgs, f ...
- [函数] PHP取二进制文件头快速判断文件类型
一般我们都是按照文件扩展名来判断文件类型,但其实不太靠谱,因为可以通过修改扩展名来伪装文件类型.其实我们可以通过读取文件信息来识别,比如 PHP扩展中提供了类似 exif_imagetype 这样的函 ...
- nginx 配置大吞吐量
ng做反向代理服务是如果没有这两行配置吞吐量到8000-10000就上不去. proxy_http_version 1.1; # 后端配置支持HTTP1.1,必须配 proxy_set_header ...
- Inno Setup, Pascal 字符串带双引号如何写
Windows 的路径中如果有空格,就需要用双引号括起来.只能填 ASCII-Code-Number (decimal),不能用一般的 escape 方法. # + path + # 查询这个表的第一 ...
- BareTail 观看文件增加的工具