python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)
上一卷中我们抓取了网页的所有内容,现在我们抓取下网页的图片名称以及连接
现在我再新建个爬虫文件,名称设置为crawler2
做爬虫的朋友应该知道,网页里的数据都是用文本或者块级标签包裹着的,scrapy框架里自带标签选择器HtmlXPathSelector,具体的使用规则可以查阅一下我就不介绍了
我们现在要爬取的内容是 网页的图片标题,以及网页的图片链接,所以我们需要在网站浏览器的控制台上查看标签内容属性
在控制台上我们发现:
我们所要抓取的内容在类名为showlist的div下的li标签下
所以我们先获取下页面的指定LI标签
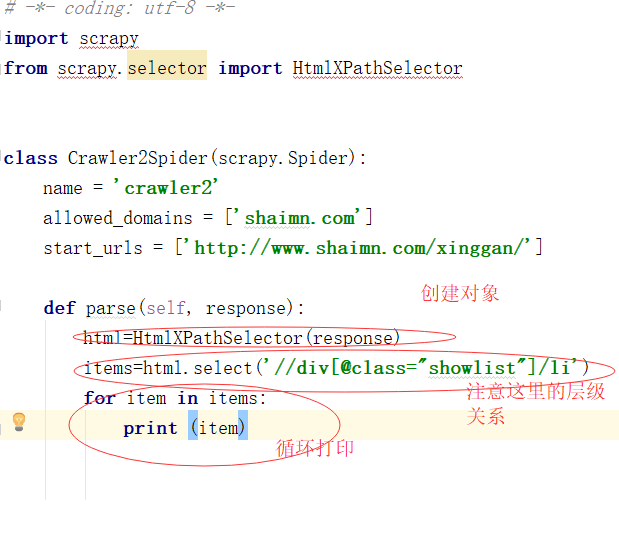
先看下打印结果:
内容哪去了 不要慌这个选择器打印的结果没问题
下面进行下代码修改,获取LI里的内容,实现由父找子的过程

这个extract()函数是我一般用来获取标签
看下结果

一组LI里有好多内容,并不是一一对应看起来不方便,由此可见个做网站的前端是直接一个LI里封装多个图片的块级元素
看的不舒服 来修改下代码 ,一个LI里有七个 为了保证数据的准确性 每一个父级LI元素我都设定一个编号
看下代码
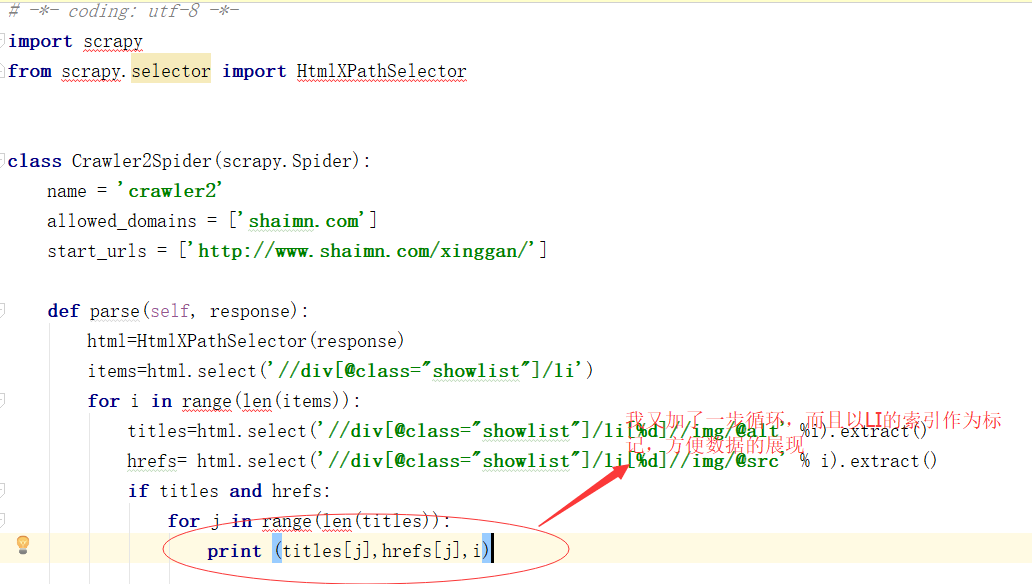
来看下结果:
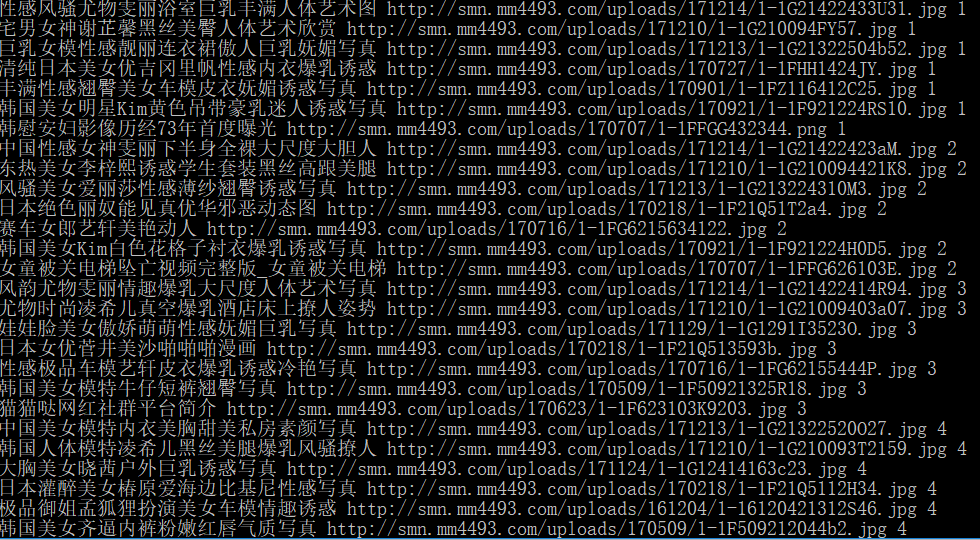
纵然文字不健康,但是数据的展现依旧清晰可见
现在图片的连接有了 我们可以根据链接来下载图片 那么我们使用urlretrieve函数,我们在当前爬虫的文件夹中与SPIDER文件同级建立一个IMG文件夹
来看下代码:
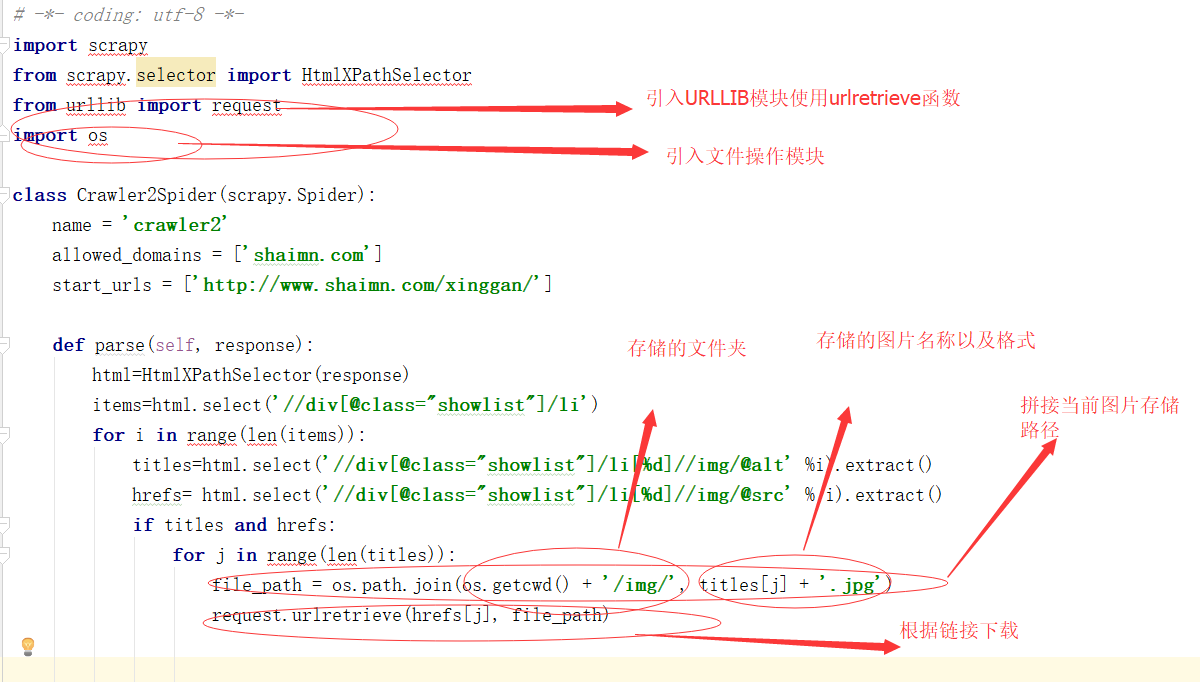
其实就像个公式一样 读取公式+存储公式就能完成图片的下载:来现在看一下结果:

真的是豪无节操的网站 我以后不会再爬取它了
python3下scrapy爬虫(第三卷:初步抓取网页内容之抓取网页里的指定数据)的更多相关文章
- python3下scrapy爬虫(第五卷:初步抓取网页内容之scrapy全面应用)
现在爬取http://category.dangdang.com/pg1-cid4008149.html网址上的商品价格,名称,评价数量 先准备下下数据:商品名,商品链接,评价数量 第一步:在item ...
- python3下scrapy爬虫(第十一卷:scrapy数据存储进mongodb)
说起python爬虫数据存储就不得不说到mongodb,现在我们来试一下scrapy操作mongodb 首先开启mongodb mongod --dbpath=D:\mongodb\db 开启服务后就 ...
- python3下scrapy爬虫(第七卷:编辑器内执行scrapy)
之前我们都是在终端切入到scrapy的路境内执行爬虫的,你要多敲多少行的字节,所以这次我们谈谈如何在编辑器里执行,这个你可以用在爬虫中,当你使用PYTHONWEB开发时尽量不要在编辑器内启动端口服务那 ...
- python3下scrapy爬虫(第十三卷:scrapy+scrapy_redis+scrapyd打造分布式爬虫之配置)
之前我们的爬虫都是单机爬取,也是单机维护REQUEST队列, 看一下单机的流程图: 一台主机控制一个队列,现在我要把它放在多机执行,会产生一个事情就是做重复的爬取,毫无意义,所以分布式爬虫的第一个难点 ...
- python3下scrapy爬虫(第十卷:scrapy数据存储进mysql)
上一卷中我将爬取的数据文件直接写入文本文件中,现在我将数据存储到mysql中,我依然用的是pymysql,这个很麻烦建表需要在外面建 这次代码只需要改变pipyline就行 来 现在看下结果: 对比发 ...
- python3下scrapy爬虫(第六卷:利用cookie模拟登陆抓取个人中心页面)
之前我们爬取的都是那些无需登录就要可以使用的网站但是当我们想爬取自己或他人的个人中心时就需要做登录,一般进入登录页面有两种 ,一个是独立页面登陆,另一个是弹窗,我们先不管验证码登陆的问题 ,现在试一下 ...
- python3下scrapy爬虫(第八卷:循环爬取网页多页数据)
之前我们做的数据爬取都是单页的现在我们来讲讲多页的 一般方式有两种目标URL循环抓取 另一种在主页连接上找规律,现在我用的案例网址就是 通过点击下一页的方式获取多页资源 话不多说全在代码里(因为刚才写 ...
- python3下应用pymysql(第三卷)(数据自增-用于爬虫)
在上卷中我说出两种方法进行数据去重自增,第一种就是在数据库的字段中设置唯一字段,二是在脚本语言中设置重复判断再添加(建议,二者同时使用,真正开发中就会用到) 话不多说先上代码 第一步: 确定那一字段的 ...
- python3下scrapy爬虫(第一卷:安装问题)
一般爬虫都是用urllib包,requests包 配合正则.beautifulsoup等包混合使用,达到爬虫效果,不过有框架谁还用原生啊,现在我们来谈谈SCRAPY框架爬虫, 现在python3的兼容 ...
随机推荐
- h5-自定义视屏播放器
1.html代码 <h3 class="playerTitle">视屏播放器</h3> <div class="player"&g ...
- JVM探秘:jmap生成内存堆转储快照
本系列笔记主要基于<深入理解Java虚拟机:JVM高级特性与最佳实践 第2版>,是这本书的读书笔记. jmap 命令用来生成内存堆转储快照,一般称为heapdump或dump文件. 除了使 ...
- PAT Advanced 1041 Be Unique (20) [Hash散列]
题目 Being unique is so important to people on Mars that even their lottery is designed in a unique wa ...
- Ubuntu python多个版本管理
1.查看python有哪些版本使用命令 whereis python 如图: 2.这么多版本如何切换呢 使用 sudo update-alternatives --install <link&g ...
- UML-领域模型-定义
领域模型是OO分析中最重要和经典的模型(用例是重要的需求分析制品,但不是面向对象的).领域模型也是重点. 1.关系 2.例子 3.定义 领域模型没有定义方法的类图.只包括: 1).领域对象或概念类 2 ...
- App 性能测试
app常见性能测试点: https://blog.csdn.net/xiaomaoxiao336368/article/details/83547318
- php安装swoole2.1.2
准备环境: cos7.2 & php 7.1.7 1.www.swoole.com找到对应版本2.使用git clone或则 wget 命令(下载后需解压)进行下载3.在swoole目录 ...
- list循环 字典循环 字符串常用方法
list = ['xiaoli','xiaohua','huali']user = {'zhang':'123','lin':'321','chen':'222'}#list循环for stu in ...
- Java依据集合元素的属性,集合相减
两种方法:1.集合相减可以使用阿帕奇的一个ListUtils.subtract(list1,list2)方法,这种方法实现必须重写集合中对象的属性的hashCode和equals方法,集合相减判断的会 ...
- TPO6-1Powering the Industrial Revolution
The source had long been known but not exploited. Early in the eighteenth century, a pump had come i ...