Java中的垃圾回收算法详解
一、前言
前段时间大致看了一下《深入理解Java虚拟机》这本书,对相关的基础知识有了一定的了解,准备写一写JVM的系列博客,这是第二篇。这篇博客就来谈一谈JVM中使用到的垃圾回收算法。
二、正文
2.1 什么是垃圾回收
在正式介绍垃圾回收算法前,先来说说什么是垃圾回收。这里所说的垃圾主要指的是已经不会再继续使用的对象,当然也有可能是其他,比如不再使用的类以及常量,但主要还是指对象,所以以下算法将介绍对象的回收。所以垃圾回收的含义就是:将内存中已经不会被使用的对象(或类和常量)清除,释放内存空间。
JVM的内存模型分为五个部分,其中堆内存的唯一目的就是存放对象,对象也基本上都是存放在堆内存中。堆中,为了方便进行垃圾回收,一般会将内存分为两个部分:
- 新生代:用来存放生命周期短的对象。由于这一块内存中的对象存活时间较短,所以频繁发生垃圾回收,而且每次回收一般都能释放大量空间;
- 老年代:用来存放生命周期长的对象。新生代中存活了较长时间的对象会被迁移到这里(当然,对象进入老年代不仅仅只有这一个方法),所以这里存放的对象生命周期一般较长,所以这一块区域发生垃圾回收的频率较低,释放的空间也较少;
下面正式开始讨论JVM中的垃圾回收算法。
2.2 如何识别垃圾
进行垃圾回收的第一步就是找到垃圾(我们这里主要以对象为例),也就是无法被使用的对象。对象在什么情况下无法被使用?很简单,没有引用指向这个对象,我们自然无法使用它,比如看下面这段代码:
public static void main(String[] args) throws InterruptedException {
Object a = new Object();
a = null;
}
上面的代码中,我创建了一个对象,并使用变量a指向这个对象,但是在这之后,我又将null赋给了a,这会出现什么情况?不难发现,我们已经无法使用这个对象了,它已经丢失了,因为我们已经无法通过任何变量去调用这个对象,但是它依然在内存中。此时,这个对象占用着内存就是白白浪费资源,我们希望它被清除。所以,我们可以想到,当一个对象没有引用指向它时,就可以认为他是一个垃圾对象了。
(1)引用计数法
引用计数法就是通过引用来识别无用对象。我们记录每一个对象的引用个数,若有新的变量引用一个对象时,这个对象的引用个数加1;若一个引用失效时,引用的个数减1,而引用个数为0的对象,即可作为垃圾被回收。这里要注意,若这些垃圾对象的成员变量引用了其他对象,则当垃圾对象被释放时,它的这个引用自然就失效了。
这个算法实现简单,效率也高,但是,它并没有被用在主流的Java虚拟机中,因为它有一个很大的缺陷——很难解决循环引用的问题。什么是循环引用,看下面一段代码:
public class Main {
private Object obj;
public static void main(String[] args) {
Main m1 = new Main();
Main m2 = new Main();
// 循环引用
m1.obj = m2;
m2.obj = m1;
m1 = null;
m2 = null;
}
}
上面这段代码中,创建了两个对象m1和m2,它们都有一个属性obj。而m1的obj指向了m2,而m2的obj指向了m1。多个引用形成一个环,这就是循环引用。这对于使用引用计数算法的垃圾回收器来说有一个问题,即上面的代码最后,m1和m2都置为了空,它们指向的两个对象已经无法再使用了,但是由于这两个对象相互引用,导致它们的引用计数并不为0,所以垃圾回收器不会将它们判别为无用对象。正是因为这个问题的存在,Java中的垃圾回收器基本上不使用这个算法。
(2)可达性分析法
可达性分析法是Java垃圾回收中判别无用对象的主要方法。这个方法的步骤是,从根节点对象出发,使用DFS或BFS算法,沿着引用递归遍历,而无法被遍历到的对象,就是无法再被使用的对象,可以被垃圾回收器回收。所谓的根节点,就是我们能够直接使用的引用类型变量,如:
- 方法中的参数或局部变量;
- 类的静态成员或非静态成员;
- 代码中的常量;
这种方法的效率相对于引用计数来说相对复杂,而且效率较低,但是解决了循环引用的问题,是Java垃圾回收中主要使用的方法。
2.3 如何释放垃圾
释放垃圾指的就是清除无用对象,释放它们所占的内存空间,方便继续使用。这里主要介绍三种方法:
- 标记—清除算法;
- 复制算法;
- 标记—整理算法;
这三种算法根据具体情况的不同,搭配使用,才能发挥最好的效果。下面就来一一介绍。
(1)标记—清除算法(Mark-Sweep)
标记—清除是以上上面三种算法中最基础的一种,为什么说它是最基础的,因为它的原理非常简单。故名思意,这个算法分为两个步骤:(1)标记;(2)清除。
- 标记:标记指的就是我们上面所说的可达性分析,采用之前所说的可达性分析算法遍历对象,所有不可达的对象将被标记为垃圾,等待回收;
- 清除:这一步很简单,直接释放垃圾对象所占内存空间;
这个算法有两个的问题:
- 效率较低,标记和清除这两个步骤的效率都比较低,清除的效率低是因为需要扫描整个内存空间,逐个释放对象所占内存;
- 使用这个算法清除垃圾后,将会造成很多内存碎片,所以可能出现剩余内存较多,但是没有较大的连续空间,导致大对象无法被分配空间,而再次触发垃圾回收;
我们通过两张对比图来看看这个算法的效果。通过下面这张图我们可以看到,在垃圾回收后造成了很多的内存碎片。

(2)复制算法(Copying)
为了解决效率较低以及产生内存碎片的问题,有人提出了一个新的算法——复制算法。这个算法的原理是:将内存分为两个相等大小的区域,一块存放对象,一块保留。当存放对象的那块区域无法再分配空间时,将所有仍然存活的对象复制到保留的那块区域中,然后直接释放当前正在使用区域的全部内存。这样一来,仍然存活的对象被放进保留区,而垃圾对象也被释放了。同时,之前被使用的空间被清空后,成了新的保留区,而之前的保留区成了被使用的空间,就这样不断循环使用两个空间。
我们之前提过,堆内存被分为新生代和老年代。在新生代中,每次垃圾回收都可以释放大量的对象,只有少部分存活,所以只有少部分对象要被复制到保留区中,这也意味着复制并不会太耗时。除此之外,直接释放被使用的空间的全部内存,比一段一段释放的效率也要高很多。同时,对象被复制到另外一个区域时,会被整齐地摆放,所以不会出现内存碎片,所以能够更简单地分配空间。所以,复制算法的效率要远远高于标记—清除算法。以下是一张复制算法的演示图:

但是,这里存在一个问题,复制算法将内存区域划分为相等的两部分,这也意味着每次都有一半的空间无法被使用,这未免也太浪费了。所以,对于空间的划分,需要做出一些改进。IBM公司的研究表明,98%的对象存活时间都非常的短暂,所以,完全没有必要保留一半的空间供复制使用。在实际实现中,会将空间划分为三块区域,一块较大的Eden空间,以及两块较小的Survivor空间。在为新对象分配空间时,首先会将其分配到Eden空间中,若Eden空间无法再分配空间时,将会触发垃圾回收,此时,会将Eden空间中的存活对象复制到其中一块Survivor空间中,然后清空Eden空间。当Eden空间再一次因无法分配空间而触发垃圾回收时,则会将Eden空间中的存活对象,以及上一次被复制进Survivor空间中的存活对象,都复制到另一块Survivor空间中,然后将Eden和上一块Survivor清空。也就是说,交替地使用两块Survivor空间,来存放垃圾回收中任然存活的对象。而在具体实现中,这三个空间的比例一搬是8:1:1,即是说只有10%的空间无法被使用。
可以看出,这个算法在大部分对象的生命周期都短时,效率会非常高,但是若大部分对象的生命周期都很长,将不再适用,所以这个算法一般只被用在新生代中。这里我们不得不考虑一个问题,当我们使用了上面说的将内存划分为三块的这种方式时,可能会出现一个问题:如果在某次垃圾回收过后,仍然有大量的对象存活,此时一个Survivor空间不够存放这些对象怎么办?这时候就需要有另一个空间来做担保了,当这种情况发生时,会将这些对象放入另一个空间中,那个空间就叫做担保空间。就像我们去银行贷款,需要有一个担保人,当贷款人不能偿还时,由担保人代为偿还。以上算法是用在新生代中,而所谓的担保空间,实际上就是老年代。老年代为这个算法提供了担保,但是在大部分情况下,Survivor都是能够满足需求的。
(3)标记—整理(Mark-Compact)
由于老年代中的对象一般存活时间都比较长,所以并不适合在老年代使用上面的复制算法进行垃圾回收。而有人根据老年代的特点,提出了标记—整理算法,注意看清楚,这里是整理,而不是第一种算法中的清除。这个算法也分为标记和整理两个步骤,标记这个步骤和第一个算法是一样的,关键是整理步骤。所谓的整理,就是将内存中还存活的对象向一边移动,直至这些对象相互靠拢,整齐排列,然后直接清除不属于这一部分的全部内存。标记—整理的好处是解决内存碎片的问题。以下是这个算法的演示图:
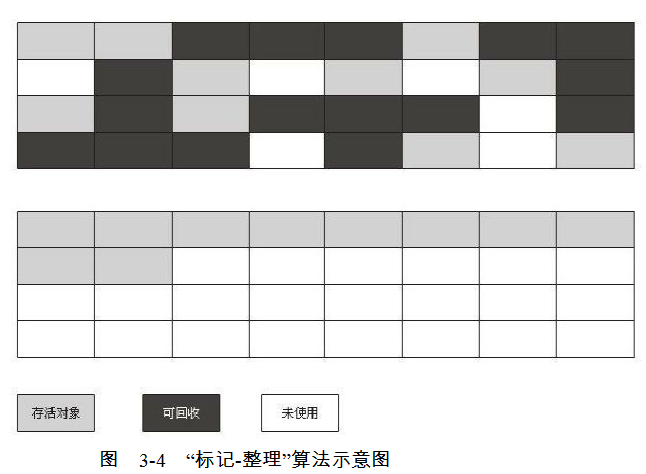
(4)分代收集算法
分代收集算法并不是什么新思想,而是对上面三种算法的综合使用。前面也提过,为方便垃圾回收,一般将堆内存分为新生代和老年代两个部分。
- 对于新生代而言,这一块区域中的对象存活时间短,每一次垃圾回收都能回收大部分内存,所以适合使用复制算法,同时以老年代作为这个算法的担保空间;
- 对于老年代而言,每次垃圾回收只能释放小部分空间,若使用复制算法,每次将需要做大量复制,而且此时
Survivor需要较大的空间,所以不适合使用复制算法,因此在老年代中,一般使用标记—清除或者标记—整理算法;
三、总结
上面对JVM中的垃圾回收算法做了一个比较详细的介绍,相信看完这一篇博客会对这部分内容有更深的理解。但是,归根到底,上面的内容只是理论,接下来我将写一篇博客,来讲讲JVM具体如何分配和释放对象,作为JVM系列博客的第三篇。
四、参考
- 《深入理解Java虚拟机》
Java中的垃圾回收算法详解的更多相关文章
- JVM垃圾回收算法详解
前言 在JVM内存模型中会将堆内存划分新生代.老年代两个区域,两块区域的主要区别在于新生代存放存活时间较短的对象,老年代存放存活时间较久的对象,除了存活时间不同外,还有垃圾回收策略的不同,在JVM中中 ...
- java中的垃圾回收算法与垃圾回收器
常用的垃圾回收算法 标记-清除 标记清除算法是一种非移动式的回收算法,分为标记 清除 2个阶段,简而言之就是先标记出需要回收的对象,标记完成后再回收掉所有标记的内存对象,如下图 可见回收后图中被标记的 ...
- 【java虚拟机】垃圾回收机制详解
作者:平凡希 原文地址:https://www.cnblogs.com/xiaoxi/p/6486852.html 一.为什么需要垃圾回收 如果不进行垃圾回收,内存迟早都会被消耗空,因为我们在不断的分 ...
- 一张图看懂JVM之垃圾回收算法详解
导读 ...
- java面试题之----JVM架构和GC垃圾回收机制详解
JVM架构和GC垃圾回收机制详解 jvm,jre,jdk三者之间的关系 JRE (Java Run Environment):JRE包含了java底层的类库,该类库是由c/c++编写实现的 JDK ( ...
- JVM的垃圾回收机制详解和调优
JVM的垃圾回收机制详解和调优 gc即垃圾收集机制是指jvm用于释放那些不再使用的对象所占用的内存.java语言并不要求jvm有gc,也没有规定gc如何工作.不过常用的jvm都有gc,而且大多数gc都 ...
- GC垃圾回收机制详解
JVM堆相关知识 为什么先说JVM堆? JVM的堆是Java对象的活动空间,程序中的类的对象从中分配空间,其存储着正在运行着的应用程序用到的所有对象.这些对象的建立方式就是那些new一类的操作 ...
- PHP的垃圾回收机制详解
原文:PHP的垃圾回收机制详解 最近由于使用php编写了一个脚本,模拟实现了一个守护进程,因此需要深入理解php中的垃圾回收机制.本文参考了PHP手册. 在理解PHP垃圾回收机制(GC)之前,先了解一 ...
- 【java虚拟机序列】java中的垃圾回收与内存分配策略
在[java虚拟机系列]java虚拟机系列之JVM总述中我们已经详细讲解过java中的内存模型,了解了关于JVM中内存管理的基本知识,接下来本博客将带领大家了解java中的垃圾回收与内存分配策略. 垃 ...
随机推荐
- 网络安全从入门到精通 (第二章-1) Web安全前端基础
本文内容: 前端是什么? 前端代码 HTML CSS JS !!!醋成酒的小墨,促成就的小墨,小墨促成就,!!! 1,前端是什么? 网站一般用两部分组成,前端负责展示,后端负责处理请求. 2,前端代码 ...
- zookeeper基础学习-简介
1.zookeeper的使命 zookeeper可以在分布式系统的协作多个任务(一个任务是指一个包含多个进程的任务),这个任务可以是为了协作或者是为了管理竞争. 协作:多个进程需要一同处理某些事情,一 ...
- 贵州省网络安全知识竞赛个人赛Writeup
首先拖到D盾扫描 可以很明显的看出来确实就是两个后门 0x01 Index.php#一句话木马后门 0x02 About.php#文件包含漏洞 都可以很直观的看出来非常明显的漏洞,第一个直接就是eva ...
- Spring Controller单例与线程安全那些事儿
目录 单例(siingleton)作用域 原型(Prototype)作用域 多个HTTP请求在Spring控制器内部串行还是并行执行方法? 实现单例模式并模拟大量并发请求,验证线程安全 附录:Spri ...
- PMP备考日记(一)
本人在今年1月份就开始有考PMP证的一个想法,结果头脑一热就报名了.本来计划今年3月份就要进行PMP考试,一直都在备考中,结果谁知道来了新冠状病毒,彻底打乱了自己的脚步.PMI也将PMP考试延迟到了今 ...
- UVA129 Krypton Factor 困难的串 dfs回溯【DFS】
Krypton Factor Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 65536/32768 K (Java/Others ...
- 拒绝了对对象 '***' (数据库 'BestSoftDB_P',架构 'sale')的 EXECUTE 权限。
问题描述: 给普通用户授予读写权限,之后研发反映查询语句报错: nested exception is com.microsoft.sqlserver.jdbc.SQLServerException: ...
- LightOj 1197 Help Hanzo 区间素数筛
题意: 给定一个区间a,b,a-b>=100000,1<=a<=b<=231,求出给定a,b区间内的素数的个数 区间素数筛 (a+i-1)/ ii向上取整,当a为 i 的整数倍 ...
- coding++:JS/jQuery获取兄弟姐妹等元素
jQuery获取: jQuery.parent(expr),找父亲节点,可以传入expr进行过滤,比如$("span").parent()或者$("span") ...
- Mybatis多表关联查询字段值覆盖问题
一.错误展示 1.首先向大家展示多表关联查询的返回结果集 <resultMap id="specialdayAndWorktimeMap type="com.hierway. ...