TensorFlow系列专题(六):实战项目Mnist手写数据集识别
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习、深度学习的知识!
目录:
- 导读
- MNIST数据集
- 数据处理
- 单层隐藏层神经网络的实现
- 多层隐藏层神经网络的实现
- 导读
就像我们在学习一门编程语言时总喜欢把“Hello World!”作为入门的示例代码一样,MNIST手写数字识别问题就像是深度学习的“Hello World!”。通过这个例子,我们将了解如何将数据转化为神经网络所需要的数据格式,以及如何使用TensorFlow搭建简单的单层和多层的神经网络。
- MNIST数据集
MNIST数据集可以从网站http://yann.lecun.com/exdb/mnist/上下载,需要下载的数据集总共有4个文件,其中“train-images-idx3-ubyte.gz”是训练集的图片,总共有60000张,“train-labels-idx1-ubyte.gz”是训练集图片对应的类标(0~9)。“t10k-images-idx3-ubyte.gz”是测试集的图片,总共有10000张,“t10k-labels-idx1-ubyte.gz”是测试集图片对应的类标(0~9)。TensorFlow的示例代码中已经对MNIST数据集的处理进行了封装,但是作为第一个程序,我们希望带着读者从数据处理开始做,数据处理在整个机器学习项目中是很关键的一个环节,因此有必要在第一个项目中就让读者体会到它的重要性。
我们将下载的压缩文件解压后会发现数据都是以二进制文件的形式存储的,以训练集的图像数据为例:
表1 训练集图像数据的文件格式
| [offset] | [type] | [value] | [description] |
| 0000 | 32 bit integer | 0x00000803(2051) | magic number |
| 0004 | 32 bit integer | 60000 | number of images |
| 0008 | 32 bit integer | 28 | number of rows |
| 0012 | 32 bit integer | 28 | number of columns |
| 0016 | unsigned byte | ?? | pixel |
| 017 | unsigned byte | ?? | pixel |
| …… | |||
| xxxx | unsigned byte | ?? | pixel |
如表3-1所示,解压后的训练集图像数据“train-images-idx3-ubyte”文件,其前16个字节的内容是文件的基本信息,分别是magic number(又称为幻数,用来标记文件的格式)、图像样本的数量(60000)、每张图像的行数以及每张图像的列数。由于每张图像的大小是28*28,所以我们从编号0016的字节开始,每次读取28*28=784个字节,即读取了一张完整的图像。我们读取的每一个字节代表一个像素,取值范围是[0,255],像素值越接近0,颜色越接近白色,像素值越接近255,颜色越接近黑色。
训练集类标文件的格式如下:
表2 训练集类标数据的文件格式
| [offset] | [type] | [value] | [description] |
| 0000 | 32 bit integer | 0x00000801(2049) | magic number(MSB first) |
| 0004 | 32 bit integer | 60000 | number of items |
| 0008 | unsigned byte | ?? | label |
| 0009 | unsigned byte | ?? | label |
| …… | |||
| xxxx | unsigned byte | ?? | label |
如上表所示,训练集类标数据文件的前8个字节记录了文件的基本信息,包括magic number和类标项的数量(60000)。从编号0008的字节开始,每一个字节就是一个类标,类标的取值范围是[0,9],类标直接标明了对应的图像样本的真实数值。如图1所示,我们将部分数据进行了可视化。测试集的图像数据和类标数据的文件格式与训练集一样。

图1 训练集图像数据可视化效果
- 数据处理
在开始实现神经网络之前,我们要先准备好数据。虽然MNIST数据集本身就已经处理过了,但是我们还是需要做一些封装以及简单的特征工程。我们定义一个MnistData类用来管理数据:
1 import numpy as np
2 import struct
3 import random
4
5 class MnistData:
6 def __init__(self, train_image_path, train_label_path,
7 test_image_path, test_label_path):
8 # 训练集和测试集的文件路径
9 self.train_image_path = train_image_path
10 self.train_label_path = train_label_path
11 self.test_image_path = test_image_path
12 self.test_label_path = test_label_path
13
14 # 获取训练集和测试集数据
15 # get_data()方法,参数为0获取训练集数据,参数为1获取测试集
16 self.train_images, self.train_labels = self.get_data(0)
17 self.test_images, self.test_labels = self.get_data(1)
18
19 # 定义两个辅助变量,用来判断一个回合的训练是否完成
20 self.num_of_batch = 0
21 self.got_batch = 0
在“init”方法中初始化了“MnistData”类相关的一些参数,其中“train_image_path”和“train_label_path”分别是训练集数据和类标的文件路径,“test_image_path”和“test_label_path”分别是测试集数据和类标的文件路径。
接下来我们要实现“MnistData”类的另一个方法“get_data”,该方法实现了Mnist数据集的读取以及数据的预处理。
22 def get_data(self, data_type):
23 if data_type == 0: # 获取训练集数据
24 image_path = self.train_image_path
25 label_path = self.train_label_path
26 else: # 获取测试集数据
27 image_path = self.test_image_path
28 label_path = self.test_label_path
29
30 with open(image_path, 'rb') as file1:
31 image_file = file1.read()
32 with open(label_path, 'rb') as file2:
33 label_file = file2.read()
34
35 label_index = 0
36 image_index = 0
37 labels = []
38 images = []
39
40 # 读取训练集图像数据文件的文件信息
41 magic, num_of_datasets, rows, columns =\
42 struct.unpack_from('>IIII', image_file, image_index)
43 image_index += struct.calcsize('>IIII')
44
45 for i in range(num_of_datasets):
46 # 读取784个unsigned byte,即一副图像的所有像素值
47 temp = struct.unpack_from('>784B', image_file, image_index)
48 # 将读取的像素数据转换成28*28的矩阵
49 temp = np.reshape(temp, (28, 28))
50 # 归一化处理
51 temp = temp / 255
52 images.append(temp)
53 image_index += struct.calcsize('>784B') # 每次增加784B
54
55 # 跳过描述信息
56 label_index += struct.calcsize('>II')
57 labels = struct.unpack_from('>' + str(num_of_datasets)
58 + 'B', label_file, label_index)
59
60 # one-hot
61 labels = np.eye(10)[np.array(labels)]
62
63 return images, labels
由于Mnist数据是以二进制文件的形式存储,所以我们需要用到struct模块来处理文件,uppack_from函数用来解包二进制文件,第42行代码中,参数“>IIII”指定读取16个字节的内容,这正好是文件的基本信息部分。其中“>”代表二进制文件是以大端法存储,“IIII”代表四个int类型的长度,这里一个int类型占4个字节。参数“image_file”是尧都区的文件,“image_index”是偏移量。如果要连续的读取文件内容,每读取一部分数据后就要增加相应的偏移量。
第51行代码中,我们对数据进行了归一化处理,关于归一化我们在第一章中有介绍。在后面两节实现神经网络模型的时候,读者可以尝试注释掉归一化的这行代码,比较一下做了归一化和不做归一化,模型的效果有什么差别。
最后,我们要实现一个“get_batch”方法。在训练模型的时候,我们通常会用训练集数据训练多个回合(epoch),每个回合都会用且只用一次训练集中的每一条数据。因为我们使用随机梯度下降的方式来更新参数,所以每个回合中,我们会把训练集数据分为多个批次(batch)送进模型中去训练,每次送进模型的数据量的大小为“batch_size”。因此,我们需要将数据按“batch_size”进行划分。
64 def get_batch(self, batch_size):
65 # 刚开始训练或当一轮训练结束之后,打乱数据集数据的顺序
66 if self.got_batch == self.num_of_batch:
67 train_list = list(zip(self.train_images, self.train_labels))
68 random.shuffle(train_list)
69 self.train_images, self.train_labels = zip(*train_list)
70
71 # 重置两个辅助变量
72 self.num_of_batch = 60000 / batch_size
73 self.got_batch = 0
74
75 # 获取一个batch size的训练数据
76 train_images = self.train_images[
77 self.got_batch*batch_size:(self.got_batch+1)*batch_size]
78 train_labels = self.train_labels[
79 self.got_batch*batch_size:(self.got_batch+1)*batch_size]
80 self.got_batch += 1
81
82 return train_images, train_labels
在第68行代码中,我们使用了“random”模块的“shuffle”方法对数据进行了“洗牌”,即打乱了数据原来的顺序,“shuffle”操作的目的是为了让各类样本数据尽可能混合在一起,从而在模型训练的过程中,各类样本都可以对模型的参数变化产生影响。不过需要记住的是,“shuffle”操作并不总是必须的,而且是否可以使用“shuffle”操作也要看具体的数据来定。
到这里我们已经实现了Mnist数据的读取和预处理,在后面两小节的内容里,我们会分别实现一个单层的神经网络和一个多层的前馈神经网络模型,实现Mnist手写数字的识别问题。
四、单层隐藏层神经网络的实现
介绍完MNIST数据集之后,我们现在可以开始动手实现一个神经网络来解决手写数字识别的问题了,我们先从一个简单的两层(一层隐藏层)神经网络开始。
本小节所实现的单层神经网络结构如图3-16所示。每张图片的大小为,我们将其转为长度为784的向量作为网络的输入。隐藏层有10个神经元,在这个简单的神经网络中我们没有在隐藏层中使用激活函数。在隐藏层后面我们加了一个Softmax层,用来将隐藏层的输出直接转化为模型的预测结果。
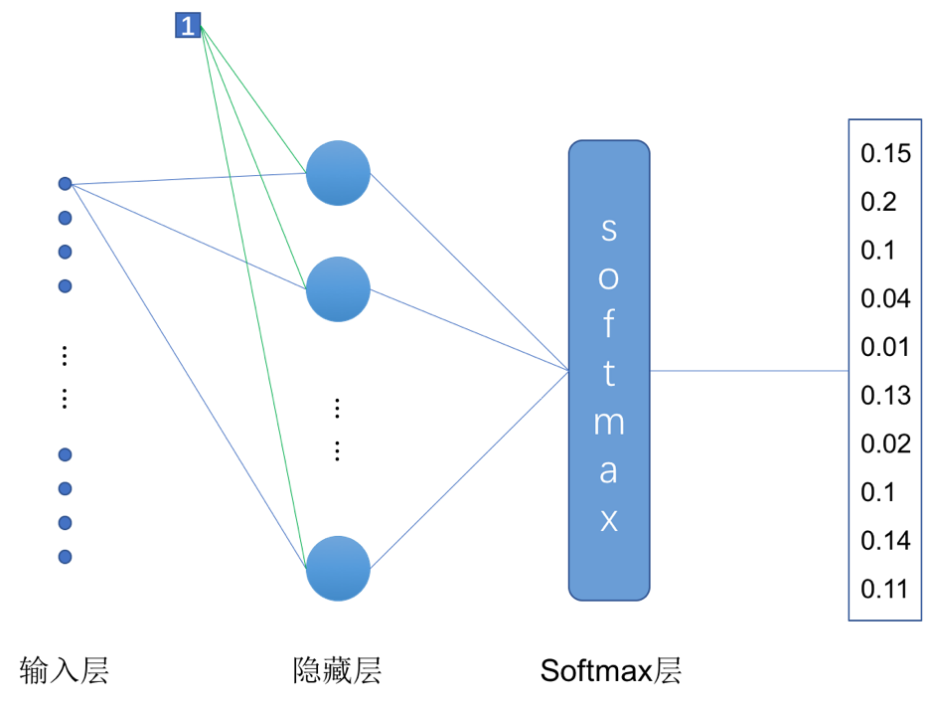
图2 实现Mnist手写数字识别的两层神经网络结构
接下来我们实现具体的代码,首先导入上一小节中我们实现的数据处理的类以及TensorFlow的包:
1 from mnist_data import MnistData
2 import tensorflow as tf
创建一个Session会话,并定义好相关的变量:
3 # 创建Session会话
4 sess = tf.InteractiveSession()
5
6 # 训练集、测试集的文件路径
7 train_image_path = './data/train-images-idx3-ubyte'
8 train_label_path = './data/train-labels-idx1-ubyte'
9 test_image_path = './data/t10k-images-idx3-ubyte'
10 test_label_path = './data/t10k-labels-idx1-ubyte'
11
12 epochs = 10 # 训练的总轮数
13 batch_size = 100 # 每个batch的大小
14 learning_rate = 0.2 # 学习率
“epochs”是我们想要训练的总轮数,每一轮都会使用训练集的所有数据去训练一遍模型。由于我们使用随机梯度下降方法更新参数,所以不会一次把所有的数据送进模型去训练,而是按批次训练,“batch_size”是我们定义的一个批次的数据量的大小,这里我们设定了100,那么每个“batch”就会送100个样本到模型中去训练,一轮训练的“batch”数等于总的训练集数量除以“batch_size”。“learning_rate”是我们定义的学习率,即模型参数更新的速率。
接下来我们定义模型的参数:
15 # 创建样本数据的placeholder
16 x = tf.placeholder(tf.float32, [None, 28, 28])
17 # 定义权重矩阵和偏置项
18 W = tf.Variable(tf.zeros([28*28, 10]))
19 b = tf.Variable(tf.zeros([10]))
20
21 # 样本的真实标签
22 y_ = tf.placeholder(tf.float32, [None, 10])
23 # 使用softmax函数将单层网络的输出转换为预测结果
24 y = tf.nn.softmax(tf.matmul(tf.reshape(x, [-1, 28*28]), W) + b)
第16行代码定义了输入样本的placeholder,第18和第19行代码定义了该单层神经网络隐藏层的权重矩阵和偏置项。根据图3-16所示的网络结构,输入向量长度为784,隐藏层有10个神经元,因此我们定义权重矩阵的大小为784行10列,偏置项的向量长度为10。在第24行代码中,我们先将输入的样本数据转换为一维的向量,然后进行的运算,计算的结果再经由Softmax计算得到最终的预测结果。
定义完网络的参数后我们还需要定义损失函数和优化器:
25 # 损失函数和优化器
26 # -tf.reduce_sum(y_ * tf.log(y) 计算这个batch中每个样本的交叉熵
27 # reduce_mean方法对一个batch的样本的交叉熵求平均值,作为最终的loss
28 cross_entropy = tf.reduce_mean(-tf.reduce_sum(y_ * tf.log(y), axis=1))
29 train_step = \
30 tf.train.GradientDescentOptimizer(learning_rate).minimize(cross_entropy)
第28行我们定义了交叉熵损失函数,关于交叉熵损失函数在本章第三小节中我们已经做了介绍,“”计算的是一个“batch”的训练样本数据的交叉熵,每个样本数据都有一个值,TensorFlow的“reduce_mean”方法将这个“batch”的数据的交叉熵求了平均值,作为这个“batch”最终的交叉熵损失值。
第29和30行代码中,我们定义了一个梯度下降优化器“GradientDescentOptimizer”,并设定了学习率为“learning_rate”以及优化目标为“cross_entropy”。
接下来我们还需要实现模型的评估:
31 # 比较预测结果和真实类标
32 correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(y_, 1))
33 # 计算准确率
34 accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
“tf.equal()”方法用于比较两个矩阵或向量相应位置的元素是否相等,相等为“True”,不等为“False”。“tf.cast”用于将“True”和“False”转换为“1”和“0”,“tf.reduce_mean”对转换后的数据求平均值,该值即为模型在测试集上预测结果的准确率。最后,我们实现模型的训练和预测:
35 # 初始化MnistData类
36 data = MnistData(train_image_path, train_label_path,
37 test_image_path, test_label_path)
38 # 初始化模型参数
39 init = tf.global_variables_initializer().run()
40
41 # 开始训练
42 for i in range(epochs):
43 for j in range(600):
44 # 获取一个batch的数据
45 batch_x, batch_y = data.get_batch(batch_size)
46 # 优化参数
47 train_step.run({x: batch_x, y_: batch_y})
48
49 # 对测试集进行预测并计算准确率
50 print(accuracy.eval({x: data.test_images, y_: data.test_labels}))
因为我们的“batch_size”设置为100,Mnist数据集的训练数据有60000条,因此我们训练600个“batch”正好是一轮。第50行代码中,我们训练完的模型对测试集数据进行了预测,并输出了预测的准确率,结果为0.9228。
- 多层神经网络的实现
多层神经网络的实现也很简单,我们只需要在上一小节的代码基础上对网络的结构稍作修改即可,我们先来看一下这一小节里要实现的多层(两层隐藏层)神经网络的结构:
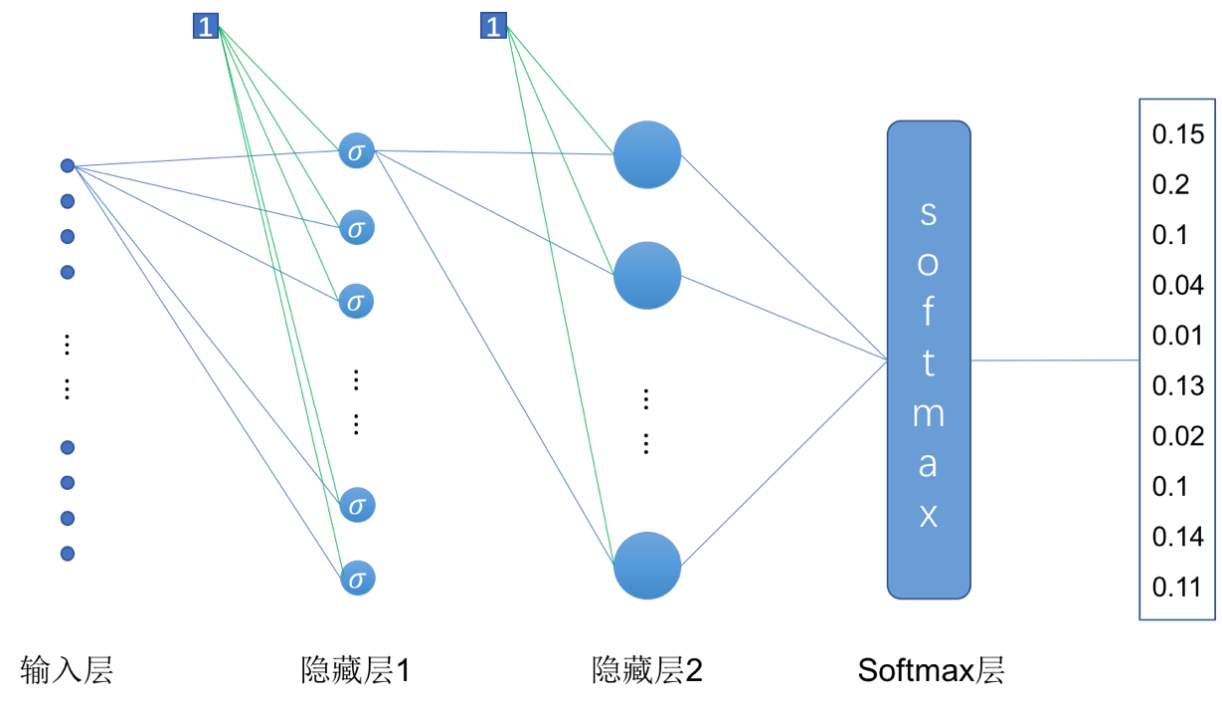
图3 实现Mnist手写数字识别的多层神经网络结构
如上图所示,这里我们增加了一层隐藏层,实现的是一个三层神经网络。与上一小节的两层神经网络不同的是,除了增加了一层隐藏层,在第一层隐藏层中我们还是用了“Sigmoid”激活函数。
实现三层神经网络我们只需要在上一小节的代码基础上对网络的参数做一些修改:
1 # 定义权重矩阵和偏置项
2 w_1 = tf.Variable(tf.truncated_normal([28*28, 200], stddev=0.1))
3 b_1 = tf.Variable(tf.zeros([200]))
4 w_2 = tf.Variable(tf.truncated_normal([200, 10], stddev=0.1))
5 b_2 = tf.Variable(tf.zeros([10]))
因为网络中有两层隐藏层,所以我们要为每一层隐藏层都定义一个权重矩阵和偏置项,我们设置第一层隐藏层的神经元数量为200,第二次隐藏层的神经元数量为10。这里我们初始化权重矩阵的时候没有像之前那样直接赋值为0,而是使用“tf.truncated_normal”函数为其赋初值,当然全都赋值为0也可以,不过需要训练较多轮,模型的参数才会慢慢接近较优的值。为参数初始化一个非零值,在网络层数较深,模型较复杂的时候,可以加快参数收敛的速度。
定义好模型参数之后,就可以实现网络的具体结构了:
1 # 定义一个两层神经网络模型
2 y_1 = tf.nn.sigmoid(tf.matmul(tf.reshape(x, [-1, 28*28]), w_1) + b_1)
3 y = tf.nn.softmax(tf.matmul(y_1, w_2) + b_2)
这里具体的计算和上一节内容一样,不过因为有两层隐藏层,因此我们需要将第一层隐藏层的输出再作为第二层隐藏层的输入,并且第一层隐藏层使用了“Sigmoid”激活函数。第二层隐藏层的输出经过“Softmax”层计算后,直接输出预测的结果。最终在测试集上的准确率为0.9664。
到这里我们已经介绍完基本的前馈神经网络的内容了,这一章的内容是深度神经网络的基础,理解本章的内容对于后续内容的学习会很有帮助。从下一章开始,我们要正式开始深度神经网络的学习了。
欢迎大家关注我们的网站和系列教程:http://panchuang.net/ ,学习更多的机器学习、深度学习的知识!
TensorFlow系列专题(六):实战项目Mnist手写数据集识别的更多相关文章
- TensorFlow实战第五课(MNIST手写数据集识别)
Tensorflow实现softmax regression识别手写数字 MNIST手写数字识别可以形象的描述为机器学习领域中的hello world. MNIST是一个非常简单的机器视觉数据集.它由 ...
- 吴裕雄 python 神经网络——TensorFlow实现回归模型训练预测MNIST手写数据集
import tensorflow as tf from tensorflow.examples.tutorials.mnist import input_data mnist = input_dat ...
- tensorflow笔记(四)之MNIST手写识别系列一
tensorflow笔记(四)之MNIST手写识别系列一 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7436310.html ...
- tensorflow笔记(五)之MNIST手写识别系列二
tensorflow笔记(五)之MNIST手写识别系列二 版权声明:本文为博主原创文章,转载请指明转载地址 http://www.cnblogs.com/fydeblog/p/7455233.html ...
- mnist手写数字识别——深度学习入门项目(tensorflow+keras+Sequential模型)
前言 今天记录一下深度学习的另外一个入门项目——<mnist数据集手写数字识别>,这是一个入门必备的学习案例,主要使用了tensorflow下的keras网络结构的Sequential模型 ...
- 基于tensorflow的MNIST手写数字识别(二)--入门篇
http://www.jianshu.com/p/4195577585e6 基于tensorflow的MNIST手写字识别(一)--白话卷积神经网络模型 基于tensorflow的MNIST手写数字识 ...
- Android+TensorFlow+CNN+MNIST 手写数字识别实现
Android+TensorFlow+CNN+MNIST 手写数字识别实现 SkySeraph 2018 Email:skyseraph00#163.com 更多精彩请直接访问SkySeraph个人站 ...
- 利用sklearn对MNIST手写数据集开始一个简单的二分类判别器项目(在这个过程中学习关于模型性能的评价指标,如accuracy,precision,recall,混淆矩阵)
.caret, .dropup > .btn > .caret { border-top-color: #000 !important; } .label { border: 1px so ...
- Tensorflow之MNIST手写数字识别:分类问题(1)
一.MNIST数据集读取 one hot 独热编码独热编码是一种稀疏向量,其中:一个向量设为1,其他元素均设为0.独热编码常用于表示拥有有限个可能值的字符串或标识符优点: 1.将离散特征的取值扩展 ...
随机推荐
- SpringBoot 全局异常处理 @RestControllerAdvice +@ExceptionHandler 请求参数校验
ControllerAdvice 指示带注释的类辅助“控制器”. 作为的特殊化@Component,允许通过类路径扫描自动检测实现类. 通常用于定义@ExceptionHandler, @InitBi ...
- 通过HTML及CSS模拟报纸排版总结
任务目的 深入掌握CSS中的字体.背景.颜色等属性的设置 进一步练习CSS布局 任务描述 参考 PDS设计稿(点击下载),实现页面开发,要求实现效果与 样例(点击查看) 基本一致 页面中的各字体大小, ...
- Python 解密JWT验证苹果登录
验证苹果登录,官方提供两种验证方法,一种是token,另一个种是code.这里使用的是token 登录流程: 苹果客户端调用苹果API,获取到用户的信息,包括: user_id 昵称 identity ...
- ZXingObjC二维码扫描
#import "QRScanViewController.h" #import "AppDelegate.h" @interface QRScanViewCo ...
- aosp Pixel 修改 SIM 卡支持及解决网络带x问题
去除网络X的方法 adb shell settings put global captive_portal_https_url http://g.cn/generate_204 自己用 php 做一个 ...
- 【图文+视频新手也友好】Java一维数组详细讲解(内含练习题答案+详解彩蛋喔~)
目录 视频讲解: 一.数组的概述 二.一维数组的使用 三.Arrays工具类中的sort方法(sort方法用的多,我们具体讲一下) 四.数组中的常见异常 五.一维数组练习题 六.彩蛋(本期视频使用的P ...
- MySQL字符集不一致导致性能下降25%,你敢信?
故事是这样的: 我在对MySQL进行性能测试时,发现CPU使用率接近100%,其中80%us, 16%sys,3%wa,iostat发现磁盘iops2000以下,avgqu-sz不超过3,%util最 ...
- 普通索引和唯一索引如何选择(谈谈change buffer)
假设有一张市民表(本篇只需要用其中的name和id_card字段,有兴趣的可以翻看“索引”篇,里面有建表语句) 每个人都有一个唯一的身份证号,且业务代码已经保证不会重复. 由于业务需求,市民需要按身份 ...
- Asp.net textbox 控件 的 onTextChange 事件
<asp:TextBox ID="txt_MailType" runat="server" OnTextChanged="exitMailTyp ...
- Java-迭代器(新手)
//导入的包.import java.util.ArrayList;import java.util.Collection;import java.util.Iterator;//创建的一个类.pub ...