利用机器学习检测HTTP恶意外连流量
本文通过使用机器学习算法来检测HTTP的恶意外连流量,算法通过学习恶意样本间的相似性将各个恶意家族的恶意流量聚类为不同的模板。并可以通过模板发现未知的恶意流量。实验显示算法有较好的检测率和泛化能力。
0×00背景
攻击者为控制远程的受害主机,必定有一个和被控主机的连接过程,一般是通过在被控主机中植入后门等手段,由受控主机主动发出连接请求。该连接产生的流量就是恶意外连流量,如图1.1所示。目前检测恶意外连流量的主要方式有两种,一种是基于黑名单过滤恶意域名,另一种是使用规则匹配恶意外连流量。这两种方案都有一定的局限性,基于黑名单过滤的方案,只能识别连接已知恶意网站时的恶意外连流量,对于域名变化没有任何感知。而基于特征检测的方案,需要安全从业人员逐一分析样本,会消耗较大的人力,并且难以检测变种的恶意外连流量。
作为已有技术的补充,可以通过机器学习来检测恶意流量。利用机器学习来发现恶意流量间的共性,并以此为依据检测恶意流量,一个好的算法可以大大减少安全从业人员的工作量。
现在已经有不少关于采用机器学习检测恶意流量的文献资料,思路也各有千秋,如有根据流量内容进行检测的,还有根据流量变化来进行检测的。本文主要受ExecScent这篇论文的启发。
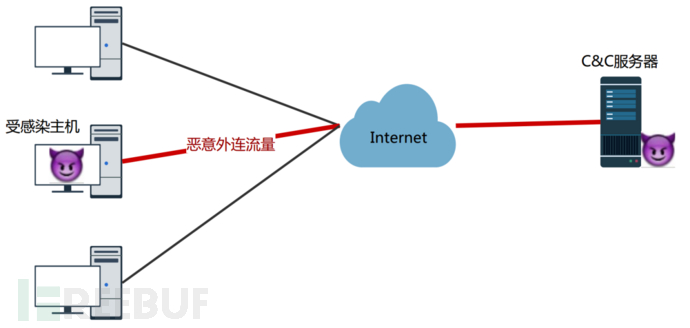
图1.1 恶意外连流量示意图
0×01数据收集
实验室目前积累了大量的恶意样本,部分如图2.1所示。通过在沙箱中运行恶意样本收集产生的外连HTTP流量。这些外连流量中只有部分是恶意的,中间仍掺杂着不少白流量。通过人工分析确认,将产生的外连流量分为恶意流量和白流量。最后利用已积累的威胁情报信息将恶意流量打上恶意家族信息。最终用于训练的数据如图2.2所示。
图2.1 恶意样本示意图
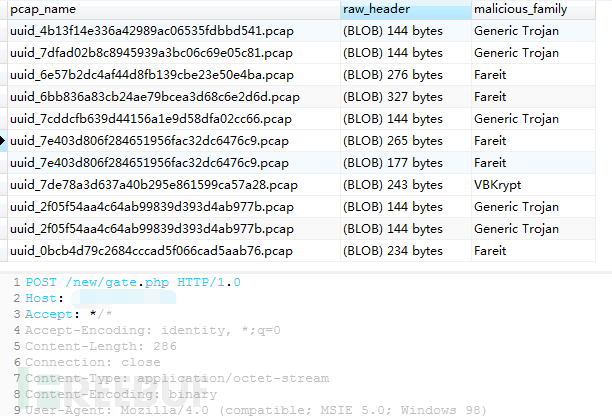
图2.2 用于训练的数据信息
0×02数据分析
通过分析采集到的恶意外连流量信息,发现来自同一家族的恶意外连流量间具有明显的相似性。如图3.1是通过两个不同的恶意样本产生的恶意外连信息,经过人工分析,判定两个恶意流量均是来自LokiBot恶意家族。可以看到两个流量间的相似性极高。图3.2则是两个来自Generic Trojan家族的恶意外连流量,同样有极高的结构相似性。
分析同一家族恶意流量,发现同一家族的恶意流量有以下特点①其url路径结构一致,具体路径信息尽管不同,但是都具有相同的数据类型。比如图3.1中url路径中的bugs和job都是字符串,图3.2url中1b50500dad和106042bd2e都是16进制小写类型;②url的参数相似;③请求头字段基本相同,且内容高度重合。
由于同一家族的恶意外连流量具有上述的相似性,因此可以使用聚类算法将同一家族的恶意流量聚为一类,提取它们的共性模板,最后利用模板检测新的恶意外连流量。

图3.1 LokiBot家族恶意外连流量

图3.2 GenericTrojan家族恶意外连流量
0×03算法实现
算法主要包括恶意http外连流量模板生成和未知http流量检测两个部分,两个部分的流程分别见图4.1和图4.6。下面分别介绍这两个部分。
1 模板生成
模板生成流程包括请求头字段提取,泛化,相似性计算,层次聚类,生成恶意外连流量模板5个步骤,如图4.1所示。
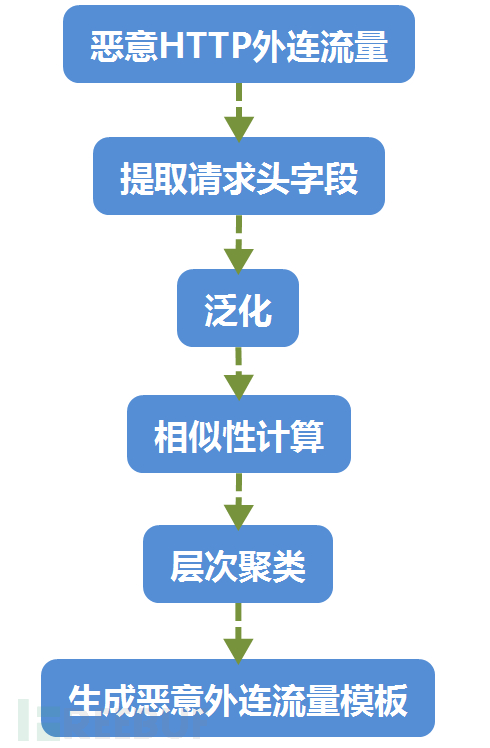
图4.1模板生成流程
1.1 提取请求头字段
将http流量划分为url、url参数,user-agent、host、content-length等结构化字段。方便后续处理。
1.2 泛化
同一家族的恶意流量结构一致,但是有部分具体细节不同。将http流量中的数字部分、字母部分、字母数字混合部分、十六进制部分、base64部分分别用特殊字符替换,取消它们的差异性部分。比如对图3.2中流量的url部分泛化,将字母转换为*,十六进制部分转换为@,数字部分转换为$,泛化后的效果如图4.2,可以看,通过泛化,两个url的结构特征得以保留,而具体内容的差异则被忽略了。

图4.2 泛化效果
1.3 相似度计算
为聚类恶意流量,需要计算流量间的相似度,便于后续提取恶意流量模板。在计算相似度的过程中,恶意流量中不同字段的重要性是不同的。如图3.2中所示的恶意流量,明显url部分更加特别,不易与白流量中的url重叠。而Accept, User-Agent等字段内容则是常见值,无论是否是恶意流量都有可能出现。因此,在计算图3.2所示流量的相似度时,url应该有更大的权重,即url相似时表明它们更有可能来自同一恶意家族。而Accept,User-Agent等字段则应该分配较小的权重,因为难以通过这些字段内容区分恶意流量和白流量。
为了更好的决定各个字段在相似度中应该占有的权重,需评估每个字段的特异性,字段内容特异性越高,则其恶意特征越明显,相应的就应该赋予更高权重。图4.3给出了相似度计算的具体过程。

图4.3 相似度计算
各个字段的特异性权重计算包括以下几个方面:
l Url路径特异性:根据url路径复杂度定义,如图4.4所示。恶意流量中的url路径越复杂越难以与白流量重叠。
l Url参数特异性:根据参数数量定义,如图4.4所示。恶意流量中的参数数量越多,特征越明显。
l 其他常见请求字段特异性:如User-Agent,Connection, Cache-Control等字段。统计所有恶意流量和白流量中出现过的字段信息集合以及对应的出现次数。如果字段内容出现频率低,则认为特异性高。
l 特殊字段特异性:如图3.1流量中的Content-Key字段。统计所有流量中出现过的字段信息。将出现频率低的字段标记为特殊字段。对于有特殊字段的流量,认为其特异性高。
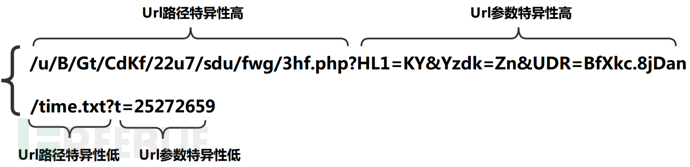
图4.4 Url路径和参数特异性
1.4 层次聚类
根据步骤3计算的相似度矩阵,利用层次聚类算法将请求头划分为若干类。每一类中的请求头都具有相似的结构,用于后续生产恶意流量模板。图4.5是采用10%的样本用于训练时生成的层次聚类图。
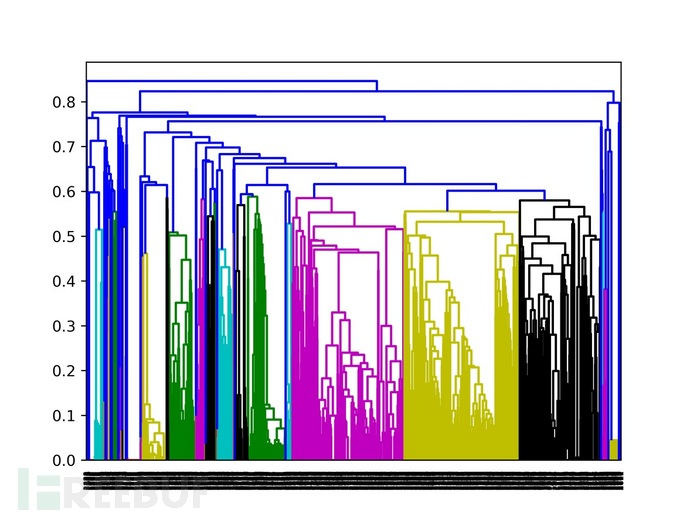
图4.5 恶意流量层次聚类图
1.5 生成恶意流量模板
对聚类后的每一类,都是结构和内容相似的恶意流量。对其中的每一个请求头字段,获取聚类中该字段内容的并集作为该字段在模板中的值。相当于把训练集中重复的部分做了去重处理。
2 未知流量检测
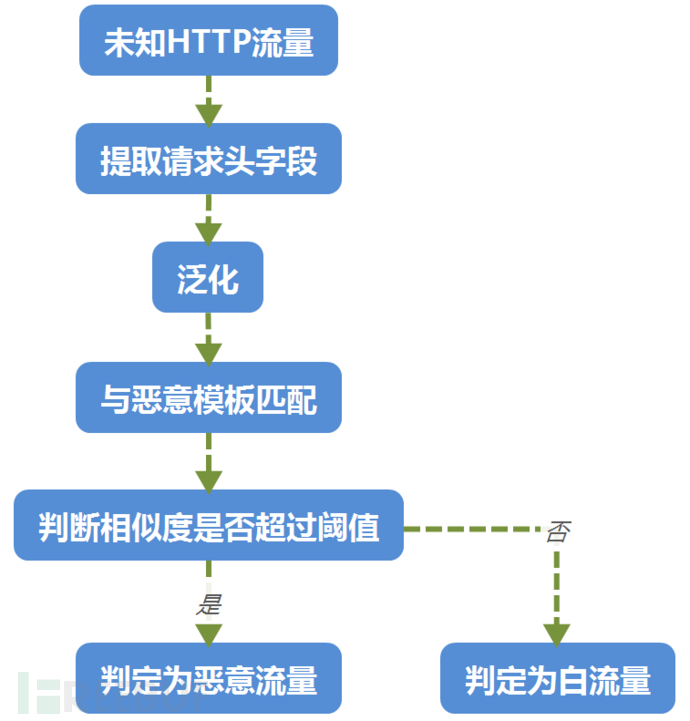
图4.6未知http流量检测
如图4.6所示,模板匹配过程主要包括包括待测流量请求头字段提取,泛化,模板匹配,判别流量性质四个部分。
其中字段提取,泛化过程和4.1节中完全相同。模板匹配过程也是计算待检测请求头与恶意外连流量模板的相似度,最后加权平均的相似度即为待测流量与模板匹配的相似度。具体相似度的计算与模板生成过程中4.1.3基本一致,唯一的区别是,模板中同一个请求头字段可以有多个值,在计算时取其中相似度最高的值。最终,如果未知流量与模板的相似度大于预设值,则认为未知流量为恶意外连流量。
0×04算法效果
采用80%的黑样本作为训练集,20%的黑样本及全部白样本作为测试集,测试算法效果,绘制匹配阈值的PRC曲线如图5.1。可以看到随着召回率的提升,算法一直保持着较高的精度。最终选择了0.8作为匹配阈值,此时算法精度为93.56%,召回率为97.14%,F-值为0.9532。
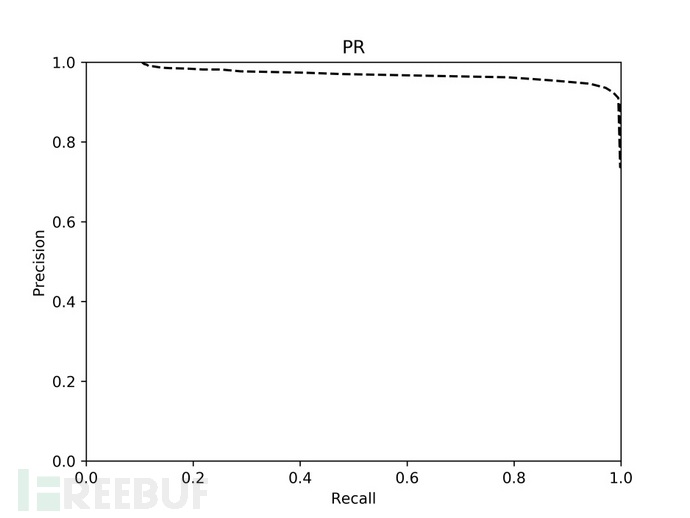
图5.1 PRC曲线
此外,分别用10%,20%,30%…, 90%的黑样本作为训练集,匹配阈值采用0.8测试其他样本数据,分别统计检测的恶意流量正确率,白流量正确率以及误报率,结果如图5.2。可以看到算法对白样本的检测正确率一直维持在99%以上。而对于黑样本,其检测正确率是建立在模型多样性的基础上的。在训练集只有10%,模型数据不足的情况下,算法仍检测出了77.65%的黑样本,说明算法对于恶意流量的变种有较好的泛化能力。
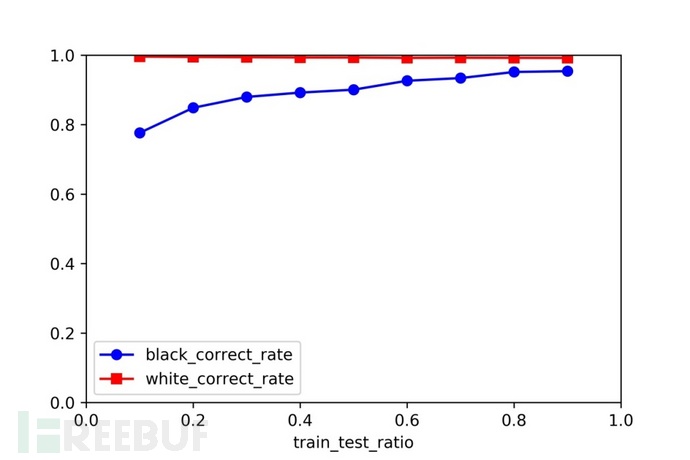
图5.2 训练集占比对黑白测试样本检出率影响
表5.1给出了不同训练集占比下,检出率和误报率的具体数值。可以看到,随着训练集占比的提高,检出率大幅度上升,这是由于算法是建立在模型基础上的。当训练集少时,样本的多样性不足,获取到的模板少,从而检出率较低。随着训练样本的增加,更多的模板特征被获取,检测率也逐渐提高。而误报率随着训练集的扩大而略有上升,这是由于随着模板的增多,白流量匹配到模板的概率也逐渐变大了。但整体误报率的增加并不多,仍在可接受范围。
| 训练集占比 | 检出率 | 误报率 |
|---|---|---|
| 10% | 77.650% | 0.392% |
| 20% | 84.856% | 0.500% |
| 30% | 87.980% | 0.567% |
| 40% | 89.234% | 0.648% |
| 50% | 90.069% | 0.662% |
| 60% | 92.644% | 0.710% |
| 70% | 93.410% | 0.729% |
| 80% | 95.172% | 0.756% |
| 90% | 95.402% | 0.783% |
表5.1 不同训练集占比下的检出率和误报率
目前还实现了一个简易的测试页面,可以通过上传pcap来检测其中是否包含恶意流量,效果如图5.3和5.4所示。该页面后续将开放。
图5.3 检测恶意流量页面
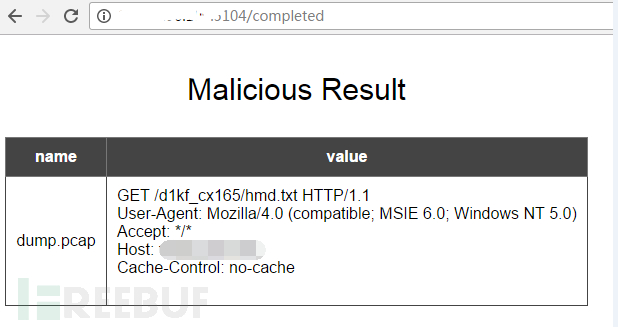
图5.4检测结果页面
0×05参考文献
Mining for New C&C Domains in Live Networks with AdaptiveControl Protocol Templates
A survey on automated dynamic malware-analysis techniques and tools
Botnet detection based on traffic behavior analysis and flowintervals
利用机器学习检测HTTP恶意外连流量的更多相关文章
- 使用机器学习检测TLS 恶意加密流——业界调研***有开源的数据集,包括恶意证书的,以及恶意tls pcap报文***
2018 年的文章, Using deep neural networks to hunt malicious TLS certificates from:https://techxplore.com ...
- 利用机器学习进行DNS隐蔽通道检测——数据收集,利用iodine进行DNS隐蔽通道样本收集
我们在使用机器学习做DNS隐蔽通道检测的过程中,不得不面临样本收集的问题,没办法,机器学习没有样本真是“巧妇难为无米之炊”啊! 本文简单介绍了DNS隐蔽通道传输工具iodine,并介绍如何从iodin ...
- Python 3 利用机器学习模型 进行手写体数字检测
0.引言 介绍了如何生成手写体数字的数据,提取特征,借助 sklearn 机器学习模型建模,进行识别手写体数字 1-9 模型的建立和测试. 用到的几种模型: 1. LR,Logistic Regres ...
- Python 3 利用机器学习模型 进行手写体数字识别
0.引言 介绍了如何生成数据,提取特征,利用sklearn的几种机器学习模型建模,进行手写体数字1-9识别. 用到的四种模型: 1. LR回归模型,Logistic Regression 2. SGD ...
- 利用Python编写Windows恶意代码!自娱自乐!勿用于非法用途!
本文主要展示的是通过使用python和PyInstaller来构建恶意软件的一些poc. 利用Python编写Windows恶意代码!自娱自乐!勿用于非法用途!众所周知的,恶意软件如果影响到了他人的生 ...
- RIG exploit kit:恶意活动分析报告——像大多数exploit kit一样,RIG会用被黑的网站和恶意广告进行流量分发
RIG exploit kit:恶意活动分析报告 from:https://www.freebuf.com/articles/web/110835.html 在过去的几周里,我们曾撰文讨论过Neutr ...
- xss利用和检测平台
xssing 是安全研究者Yaseng发起的一个基于 php+mysql的 网站 xss 利用与检测开源项目,可以对你的产品进行黑盒xss安全测试,可以兼容获取各种浏览器客户端的网站url,cooki ...
- 利用WMI检测电脑硬件信息,没办法显示cpu的信息
但你要给某些系统或软件加密时,需要了解到服务器的硬件信息时,系统和软件会利用WMI检测硬件信息, 而有时我们会遇到检测不到CPU的型号信息,如图 此时的解决方法: 1.确定“服务”里启动了WMI 2. ...
- 通过Kubernetes监控探索应用架构,发现预期外的流量
大家好,我是阿里云云原生应用平台的炎寻,很高兴能和大家一起在 Kubernetes 监控系列公开课上进行交流.本次公开课期望能够给大家在 Kubernetes 容器化环境中快速发现和定位问题带来新的解 ...
随机推荐
- 大数据学习——MapReduce学习——字符统计WordCount
操作背景 jdk的版本为1.8以上 ubuntu12 hadoop2.5伪分布 安装 Hadoop-Eclipse-Plugin 要在 Eclipse 上编译和运行 MapReduce 程序,需要安装 ...
- springboot集成websocket实现大文件分块上传
遇到一个上传文件的问题,老大说使用http太慢了,因为http包含大量的请求头,刚好项目本身又集成了websocket,想着就用websocket来做文件上传. 相关技术 springboot web ...
- 吴裕雄--天生自然python Google深度学习框架:TensorFlow实现神经网络
http://playground.tensorflow.org/
- Springmvc多视图
Springmvc多视图 多视图是一个方法可以返回json/xml等格式的数据 第一步:导入xml格式支持的jar包 spring-oxm-3.2.0.RC2.jar 第二步:配置支持多视图 < ...
- 结构体struct,类class
1.struct,值类型,结构体会自动生成初始化方法,class是引用类型 struct Person { var name : String var age : Int func simpleDes ...
- rxjava2 dependency
<dependency> <groupId>io.reactivex.rxjava2</groupId> <artifactId>rxjava</ ...
- Xming+SecureCRT的安装与使用
博主本人平和谦逊,热爱学习,读者阅读过程中发现错误的地方,请帮忙指出,感激不尽 Xming下载地址:https://xming.en.softonic.com/ 安装完后打开文件位置: 一.Xming ...
- JarvisOJ level3_x64
这一题是和前面x86的差不多,都是利用了同一个知识点,唯一的区别就是使用的堆栈地址不同,x86是直接使用堆栈来传递参数的,而x64不同 x64的函数调用时整数和指针参数按照从左到右的顺序依次保存在寄存 ...
- 再举个webstrom 正则应用例子。
要将 "_behavior_chineseobj":{ "场所内网IP地址":"IP_ADDRESS", "源外网IPv4地址&q ...
- 探索真实事物的虚拟再现——微软亚洲研究院SIGGRAPH Asia 2014精彩入选论文赏析
Asia 2014精彩入选论文赏析" title="探索真实事物的虚拟再现--微软亚洲研究院SIGGRAPH Asia 2014精彩入选论文赏析"> SIGGRAP ...