SQL SERVER中用户定义标量函数(scalar user defined function)的性能问题
用户定义函数(UDF)分类
SQL SERVER中的用户定义函数(User Defined Functions 简称UDF)分为标量函数(Scalar-Valued Function)和表值函数(Table-Valued Function)。其中表值函数又分为Inline table-valued functions和Multistatement table-valued functions。
用户定义函数(UDF)在 SQL Server 中发挥重要的作用。用户定义函数可以用于执行复杂的逻辑,可以接受参数并返回数据。很多时候我们需要写复杂的逻辑,不能使用单个查询编写。在这种情况下,用户定义函数(UDF)发挥了重要的作用。关于用户定义函数的优点,可以参考官方文档“用户定义函数”。如下所示:
在 SQL Server 中使用用户定义函数有以下优点:
允许模块化程序设计。
只需创建一次函数并将其存储在数据库中,以后便可以在程序中调用任意次。用户定义函数可以独立于程序源代码进行修改。
执行速度更快。
与存储过程相似,Transact-SQL 用户定义函数通过缓存计划并在重复执行时重用它来降低 Transact-SQL 代码的编译开销。这意味着每次使用用户定义函数时均无需重新解析和重新优化,从而缩短了执行时间。
和用于计算任务、字符串操作和业务逻辑的 Transact-SQL 函数相比,CLR 函数具有显著的性能优势。Transact-SQL 函数更适用于数据访问密集型逻辑。
减少网络流量。
基于某种无法用单一标量的表达式表示的复杂约束来过滤数据的操作,可以表示为函数。然后,此函数便可以在 WHERE 子句中调用,以减少发送至客户端的数字或行数。
UDF标量函数(Scalar-Valued Function)影响性能案例
官方文档说用户定义函数(UDF)的执行速度更快,意思是性能非常好,如果你对此深信不疑的话,那么我只能呵呵了,其实关于用户定义函数,尤其是标量函数,需要合理使用。有些场景使用不当,则有可能造成性能问题。关于UDF的标量函数会引起性能的问题,下面我们先看一个我构造的例子吧(AdventureWorks2014),我们需要查询某个产品有多少订单(其实也是优化过程中遇到,然后我在此处构造类似这样的一个案例)
USE AdventureWorks2014;
GO
CREATE FUNCTION Sales.FetchProductOrderNum
(
@ProuctID INT
) RETURNS INT
BEGIN
DECLARE @SaleOrderNum INT;
SELECT @SaleOrderNum=COUNT(SalesOrderID) FROM Sales.SalesOrderDetail
WHERE ProductID=@ProuctID
GROUP BY ProductID;
RETURN @SaleOrderNum;
END
GO

我们知道Sales.SalesOrderDetail表里面ProductID=870的订单数量有4688,而ProductID=897的订单数量只有2条记录。那么执行下面语句时,性能会有什么差异呢?
SET STATISTICS TIME ON;
SELECT DISTINCT ProductID, Sales.FetchProductOrderNum(ProductID) FROM Sales.SalesOrderDetail
WHERE ProductID=870
SELECT DISTINCT ProductID, Sales.FetchProductOrderNum(ProductID) FROM Sales.SalesOrderDetail
WHERE ProductID=897
SET STATISTICS TIME OFF;

为什么会有这种情况,这是因为SQL语句里面调用用户定义标量函数(UDF Scalar Function),都是逐行调用用户定义函数,这样需要为每行去提取用户定义函数的定义,然后去执行这些定义,从而导致了性能问题;更深层次的原因是因为函数采用了过程式的处理方法,而SQL Server查询数据则是基于数据集合的,这样在采用过程式的逐行处理时,SQL Server性能就会显著降低。
那么我来分析看看这两个SQL的实际执行计划:从下面实际执行计划,我们可以看到第一个SQL语句执行计划从Index Seek 到Compute Scalar的数据流变粗了。这个表示第一个SQL语句的Index Seek返回的数据要多。
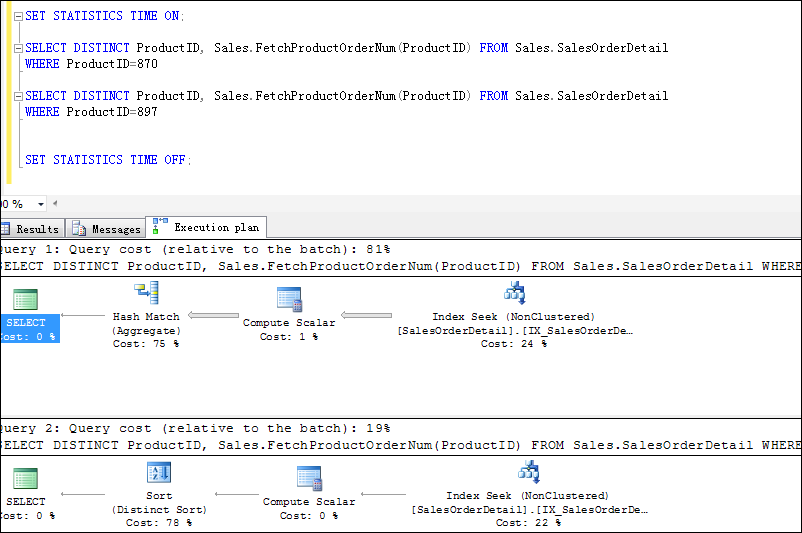
接下来,我们从Compute Scalar(进行一个标量计算并返回计算值)里面可以看到Actual Number of Rows 的值为4688 和2 。
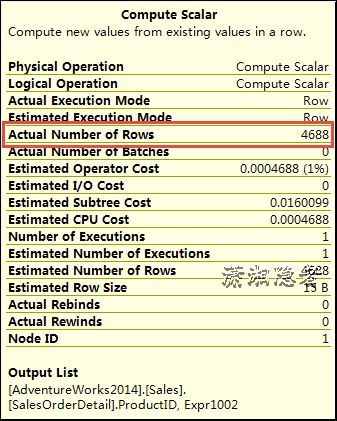

而Compute Scalar在此处就是调用标量函数,而标量函数调用总是需要资源开销和时间的,当调用次数从2次变为4688次时,elapsed time 和CPU time当然会翻了好多倍。实际环境中,用户定义标量函数的逻辑比上面简单的案例更复杂,资源开销更大,所以有时候你会看到性能差距非常悬殊的SQL案例,在工作中我就发现过这样的情况,有些开发人员对自定义标量函数使用不当影响性能不甚了解。甚至是完全不知情。他们对此振振有词:你看我SQL语句是一样的,只是参数不同,效率差别这么大。肯定是数据库出现了阻塞或性能问题。要么是服务器的性能问题,反正我SQL是没有问题的,你看这一条语句执行才一秒,换个参数就要一分多钟,这不是你数据库性能问题,那是什么? 这样的一个伪逻辑让我很无语。(习惯性就让我和数据库、服务器背了一个大黑锅)。
回到正题,上面两个SQL语句的实际执行计划的Cost比值为81%:19%;Compute Scalar(进行一个标量计算并返回计算值)的Number of Executions都是1次。但是实际的CPU time &elapsed time的比值比这个大了好多。另外第一个SQL的Compute Scalar的代价比值居然只有1%。为什么会这样呢?我们是不是很迷惑?

关于这个大家疑惑的地方,T-SQL User-Defined Functions: the good, the bad, and the ugly (part 1)里面给了我们一个阐述,截取文章中两段在此(翻译如有不当,请参考原文):
英文:
However, you may not be aware that the “Actual Execution Plan” is a dirty rotten liar. Or maybe I should say that the terms “Actual Execution Plan” and “Estimated Execution Plan” are misleading. There is only one execution plan, it gets created when the queries are compiled, and then the queries are executed. The only difference between the “Actual” and the “Estimated” execution plan is that the estimated plan only tells you the estimates for how many rows flow between iterators and how often iterators are executed, and the actual plan adds the actual data for that. But no “actual operator cost” or “actual subtree cost” is added to the corresponding estimated values – and since those costs are the values that the percentages are based on, the percentages displayed in an actual execution plan are still based only on the estimates.
翻译:
然而,你可能不知道“实际执行计划”其实是一个肮脏的烂骗子,或者我应该说“实际执行计划”和“估计执行计划”误导你了。当查询语句编译后,只有一个实际的执行计划。“实际执行计划”与“估计执行计划”的区别就在于“估计执行计划”只告诉你估计了有多少行流向迭代和迭代器执行频率,而实际执行计划将实际数据应用进来。但是“实际操作成本”或“实际子树成本”并没有添加到“实际执行计划”的估计值里面, 因为这些代价都是基于百分比的值,在实际执行计划中显示的百分比仍然基于只估计数。
英文:
But note that, again, the execution plan is lying. First, it implies that the UDF is invoked only once, which is not the case. Second, look at the cost. You may think that the 0% is the effect of rounding down, since a single execution of the function costs so little in relation to the cost of accessing and aggregating 100,000 rows. But if you check the properties of the iterators of the plan for the function, you’ll see that all operator and subtree costs are actually estimated to be exactly 0. This lie is maybe the worst of all – because it’s not just the plan lying to us, it is SQL Server lying to itself. This cost estimate of 0 is actually used by the query optimizer, so all plans it produces are based on the assumption that executing the function is free. As a result, the optimizer will not even consider optimizations it might use if it knew how costly calling a scalar UDF actually is.
翻译:
但是需要再次注意,执行计划在欺骗你,首先,它意味着只调用了UDF一次,其实不是这样。其次,从成本(Cost)来看,你可能会认为0%是向下舍入影响,因为单次执行函数的开销如此之小,以至于执行100,000次的成本也很小。但如果你检查执行计划的功能迭代器的属性,你会发现所有的操作代价和子树代价实际的估计为0,这是一个最糟糕的谎言。 因为它可能不只是为了欺骗我们,而是SQL SERVER为了欺骗它自己。实际上是查询优化器认为调用函数的成本为0,因此它生成的所有执行计划都是基于调用UDF是免费的。其结果是即使调用标量UDF的代价非常昂贵,查询优化器也不会考虑优化它。
如何优化UDF标量函数(Scalar-Valued Function)
如何优化上面SQL语句呢?从原理上来讲就是不用用户定义函数或减少调用次数。 其实我在实际应用中,减少调用次数一般通过下面方法优化:
1:减少用户定义标量函数调用次数(子查询)
SET STATISTICS TIME ON;
SELECT ProductID, Sales.FetchProductOrderNum(ProductID)
FROM(
SELECT DISTINCT ProductID FROM Sales.SalesOrderDetail
WHERE ProductID=870) T
SET STATISTICS TIME OFF;

2:减少用户定义标量函数调用次数(临时表)
SET STATISTICS TIME ON;
SELECT DISTINCT ProductID INTO #SalesOrderDetail FROM Sales.SalesOrderDetail
WHERE ProductID=870;
SELECT ProductID, Sales.FetchProductOrderNum(ProductID)
FROM #SalesOrderDetail
SET STATISTICS TIME OFF;
为什么要用临时表呢?不是子查询就可以解决问题吗?问题是实际应用当中,有些逻辑复杂的地方需要借助临时表解决,有时候子查询反而不是一个好的解决方法。
另外,我们来看看Performance Considerations of User-Defined Functions in SQL Server 2012这篇文章中,测试UDF的性能案例,本想单独翻译这篇文章,不过结合这篇文章,在此实验验证也是个不错的选择。下面案例全部来自这篇博客。我们先准备测试环境:
CREATE FUNCTION dbo.Triple(@Input INT)
RETURNS INT
AS
BEGIN;
DECLARE @Result INT;
SET @Result = @Input * 3;
RETURN @Result;
END;
GO
CREATE TABLE dbo.LargeTable
(KeyVal INT NOT NULL PRIMARY KEY,
DataVal INT NOT NULL CHECK (DataVal BETWEEN 1 AND 10)
);
WITH Digits
AS (SELECT d FROM (VALUES (0),(1),(2),(3),(4),(5),(6),(7),(8),(9)) AS d(d))
INSERT INTO dbo.LargeTable (KeyVal, DataVal)
SELECT 1000000 * sm.d
+ 100000 * ht.d + 10000 * tt.d + 1000 * st.d
+ 100 * h.d + 10 * t.d + s.d + 1,
10 * RAND(CHECKSUM(NEWID())) + 1
FROM Digits AS s, Digits AS t, Digits AS h,
Digits AS st, Digits AS tt, Digits AS ht,
Digits AS sm;
GO
CREATE INDEX NCL_LargeTable_DataVal ON dbo.LargeTable (DataVal);
GO
SET STATISTICS TIME ON;
SELECT MAX(dbo.Triple(DataVal)) AS MaxTriple
FROM dbo.LargeTable AS d;
SELECT MAX(3 * DataVal) AS MaxTriple
FROM dbo.LargeTable AS d;
SET STATISTICS TIME OFF;
如上所示,用户定义的标量函数dbo.Triple,测试用的的一个表dbo.LargeTable ,以及构造了1000000行数据。从下面我们可以看到用户定义标量函数性能确实很糟糕。

下面测试4中写法的性能。相信这个简单的脚本,大家都能看懂,在此不做过多描述、说明:
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
SET NOCOUNT ON;
SET STATISTICS TIME ON;
SELECT MAX(dbo.Triple(DataVal)) AS MaxTriple
FROM dbo.LargeTable AS d;
SET STATISTICS TIME OFF;

DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
SET STATISTICS TIME ON;
SELECT MAX(dbo.Triple(DataVal)) AS MaxTriple
FROM (SELECT DISTINCT DataVal FROM dbo.LargeTable) AS d;
SET STATISTICS TIME OFF;

DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
SET STATISTICS TIME ON;
SELECT MAX(3 * DataVal) AS MaxTriple
FROM (SELECT DISTINCT DataVal FROM dbo.LargeTable) AS d;
SET STATISTICS TIME OFF;

DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
SET STATISTICS TIME ON;
SELECT MAX(3 * DataVal) AS MaxTriple
FROM dbo.LargeTable AS d;
SET STATISTICS TIME OFF;
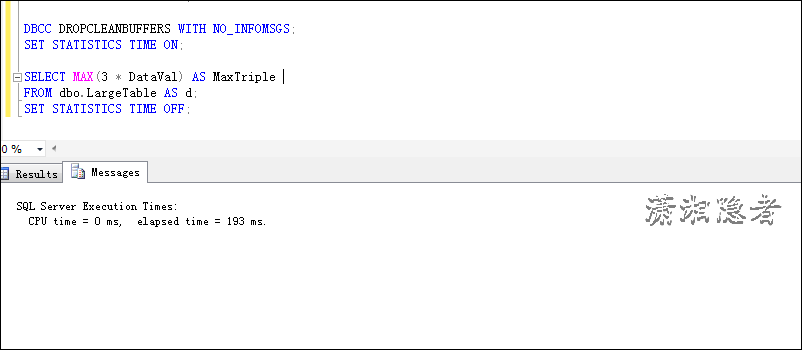
Performance Considerations of User-Defined Functions in SQL Server 2012博客里面统计的数据如下所示
|
T-SQL Syntax |
Avg CPU Time in ms |
Avg Elapsed Time in ms |
|
Function, no distinct subquery |
12925.0 |
14247.8 |
|
Function, subquery |
853.0 |
853.8 |
|
Inline calculation, subquery |
853.2 |
850.4 |
|
Inline calculation, no distinct subquery |
0.0 |
0.0 |
这个跟我测试的数据有所出入(可能跟数据库版本、机器配置有一点关系)。但是大体方向是一致的。Avg CPU Time和Avg Elapsed Time 执行时间依然Function, no distinct subquery > Function, subquery = Inline calculation, subquery > Inline calculation, no distinct subquery
那么接下来,我们先进一个表值函数Triple_tbl,对比表值函数和标量函数的性能。如下所示
CREATE FUNCTION dbo.Triple_tbl (@DataVal INT)
RETURNS TABLE
AS
RETURN
SELECT @DataVal * 3 Triple
GO
DBCC DROPCLEANBUFFERS WITH NO_INFOMSGS;
SET STATISTICS TIME ON;
SELECT MAX(dbo.Triple(DataVal)) AS MaxTriple
FROM (SELECT DISTINCT DataVal FROM dbo.LargeTable) AS d;
SELECT MAX(3 * DataVal) AS MaxTriple
FROM dbo.LargeTable AS d;
SELECT MAX(t.Triple) AS MaxTriple
FROM dbo.LargeTable l
CROSS APPLY dbo.Triple_tbl(l.DataVal) t
SET STATISTICS TIME OFF;
GO
从下可以看出,表值函数比标量函数性能要好很多,所以用表值函数替换标量函数也是一个可以考虑的优化方案。

参考资料:
SQL SERVER中用户定义标量函数(scalar user defined function)的性能问题的更多相关文章
- SQL Server如何定位自定义标量函数被那个SQL调用次数最多浅析
前阵子遇到一个很是棘手的问题,监控系统DPA发现某个自定义标量函数被调用的次数非常高,高到一个离谱的程度.然后在Troubleshooting这个问题的时候,确实遇到了一些问题让我很是纠结,下文是解决 ...
- SQL Server中截取字符串常用函数
SQL Server 中截取字符串常用的函数: .LEFT ( character_expression , integer_expression ) 函数说明:LEFT ( '源字符串' , '要截 ...
- SQL Server中通过设置非聚集索引(Non-Clustered index)来达到性能优化的目的
首先我们一下,在SQL Server 2014 Management Studio中,如何为一张表设置Non-Clustered index 具体可以参考 https://docs.microsof ...
- sql server中的数据类型转换函数
1.cast(字段名 as varchar(40)) 2.convert(varchar(50),字段名) 日期转换: CONVERT(varchar(20), GETDATE(),120)
- SQL Server中建立自定义函数
在SQL Server中用户可以自定义函数,像内置函数一样返回标量值,也可以将结果集用表格变量返回.用户自定义函数的2种类型:1.标量函数:返回一个标量值:2.表格值函数{内联表格值函数.多表格值函数 ...
- Oracle中INSTR函数与SQL Server中CHARINDEX函数
Oracle中INSTR函数与SQL Server中CHARINDEX函数 1.ORACLE中的INSTR INSTR函数格式:INSTR(源字符串, 目标字符串, 起始位置, 匹配序号) 说明:返回 ...
- 在 SQL Server 中使用 Try Catch 处理异常
如何在 SQL Server 中使用 Try Catch 处理错误? 从 SQL Server 2005 开始,我们在TRY 和 CATCH块的帮助下提供了结构错误处理机制.使用TRY-CATCH的语 ...
- 深入浅出SQL Server中的死锁
简介 死锁的本质是一种僵持状态,是多个主体对于资源的争用而导致的.理解死锁首先需要对死锁所涉及的相关观念有一个理解. 一些基础知识 要理解SQL Server中的死锁,更好的方式是通过类比从更大的面理 ...
- SQL Server中时间段查询和数据类型转换
不知道什么时候对数据独有情种,也许是因为所学专业的缘故,也许是在多年的工作中的亲身经历,无数据,很多事情干不了,数据精度不够,也很多事情干不了,有一次跟一个朋友开玩笑说,如果在写论文的时候,能有一份独 ...
随机推荐
- Java 线程池框架核心代码分析--转
原文地址:http://www.codeceo.com/article/java-thread-pool-kernal.html 前言 多线程编程中,为每个任务分配一个线程是不现实的,线程创建的开销和 ...
- C++继承和多态
继承 访问控制 基类的成员函数可以有public.protected.private三种访问属性. 类的继承方式有public.protected.private三种. 公有继承 当类的继承方式为pu ...
- 在IIS EXPRESS下运行一个visual studio 项目,跳转到另一个项目的解决方案。
原因是因为以前有一个项目也是3690端口,然后在3690端口上建立了一个网站,现在的新网站也是用的3690端口,那么会调用以前网站的WEB.CONFIG文件. 解决方法,右键单击网站,然后选择属性.在 ...
- 给ubuntu中的软件设置desktop快捷方式(以android studio为例)
ubuntu的快捷方式都在/usr/share/applications/路径下有很多*.desktop(eclipse的快捷方式也可以类似设置) 下面就建立我们的studio sudo gedit ...
- Redis 对比 Memcached 并在 CentOS 下进行安装配置
了解一下 Redis Redis 是一个开源.支持网络.基于内存.键值对的 Key-Value 数据库,使用 ANSI C 编写,并提供多种语言的 API ,它几乎没有上手难度,只需要几分钟我们就能完 ...
- JavaScript作用域链
之前写过一篇JavaScript 闭包究竟是什么的文章理解闭包,觉得写得很清晰,可以简单理解闭包产生原因,但看评论都在说了解了作用域链和活动对象才能真正理解闭包,起初不以为然,后来在跟公司同事交流的时 ...
- 为你带来灵感的 20 个 HTML5/CSS3 模板
1. Curve 2. Tapestry 3. Aqueous 4. Deliccio 5. Respond 1.5 6. Triangle Responsive 7. Design Company ...
- 做一个会使用PS的前端开发
做前端开发的需不需要PS 记得在之前的老东家做某一个系统开发,当时正在做界面开发,发现界面还需要添加几个图标,于是把这个需求反馈给了项目经理.过了十几分钟,项目经理跑过来告诉我:产品部的UI设计人员( ...
- WinFrom 公共控件 Listview 的使用
Listview绑定数据库数据展示与操作使用 1.拖一个Listview控件到项目中先将视图改为Details 2.编辑列 设置列头 添加columnHeader成员 Text 是显示的名称 3. ...
- C#创建目录,文件名过滤特殊字符串,非法字符
string invalid = new string(Path.GetInvalidFileNameChars()) + new string(Path.GetInvalidPathChars()) ...