cmdb简介
目录:
1.为啥要做cmdb
2.开发cmdb的思路和大概做法
3.cmdb的四套方案
一、为啥要做CMDB
a.项目发开和上线场景
流程:
产品经理调研需求 ===》定一个时间开发 ===》测试 ===》产品项目上线(运维)
传统做法:
运维解压文件(以邮件的形式发给运维),将代码部署到相对应的服务器目录下面。如果是由100等的话就是写shell脚本,后面跟着一串服务器的列表,然后把项目代码部署分发到每个服务器上,然后再用一个命令进行解压
存在问题:
--效率不高
--不能实现覆盖Bug的代码(代码需要完bug之后就要重新走一套流程,效率极低)
解决方法:
代码上线系统:
前端展示给用户页面,用户可选择要上传的代码,页面还展示了公司所有的服务器和对应的ip地址可以进行勾选,然后点击上传即可。
这样就不需要交给运维人员了,运维只要告诉你有什么权限,然后分配了哪几台机器,再去选择需要发布的服务器,上传交给后端(使用django去改写shell脚本的那一套)
如果需要修改代码的话,也是直接发布提交,然后后台会自动的进行代码之间的比较
-------------------必要的条件:服务器的IP地址,硬盘空间,CPU的使用率,内存等
b.监控服务器
(监控服务器的报警信息:公司的服务器运行好多程序,会有好多的图表,就是监控这个服务|应用|网址的状态码等的一些变化信息)
传统做法:
shell脚本执行命令
问题:
--不能实时
--不能自动化
现在做法:
后台用python去做,收集一下服务的元信息(IP地址,硬盘大小,内存)
前台配合kibana
c.装机服务
(服务器操作系统(centos):将服务器格式化之后装成我们自己想要的系统并且还需要装公司定制的服务)
做法:
自动装机服务(将网线插入,然后输入指令就会自动装机,而且是并发的执行)
必要条件:
服务器的元信息,IP地址
d.年底统计
之前的做法:
使用excel统计服务器(ip地址,内存,硬盘大小等等)
存在问题:
--不能实时,需要对变更进行记录(哪台服务器哪一天由谁操作从250G变成了50G)
现在的做法:
统计资产的系统
必要条件:
服务器的各种信息,需要实时的汇报变更记录
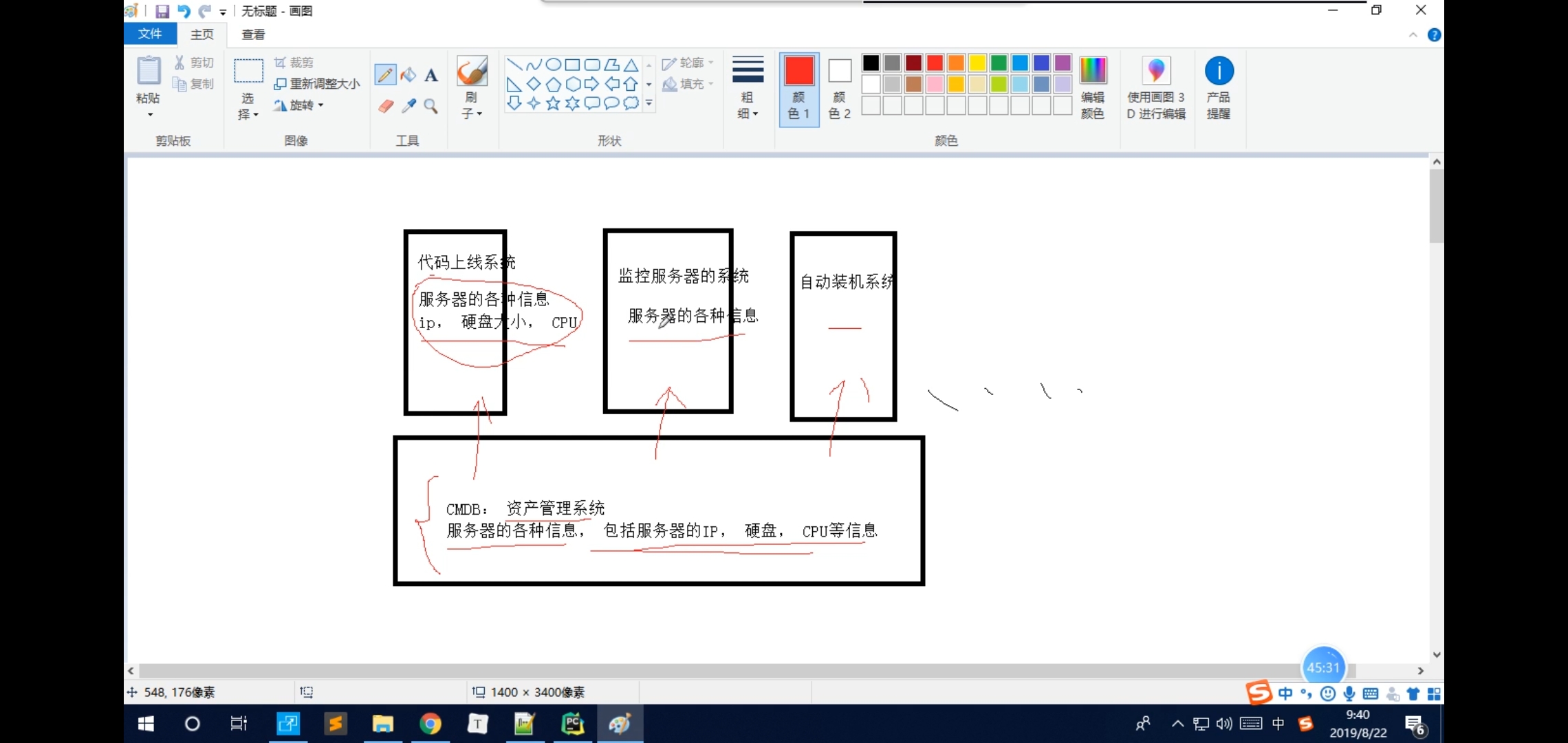
cmdb:
资产管理系统(以上的所有的系统都需要smdb作为前提,包括服务器的ip,硬盘,cpu等等,以上的系统可以向cmdb要数据,也就是cmdb写接口,然后其他系统可以调用cmdb使用,cmdb管理服务器各种信息包括变更记录也是实时汇报)
业界方案都差不多
本质上就是:收集服务器的各种信息
总:
-实现运维自动化,而CMDB是实现运维自动化的基石
-之前公司统计资产的时候,使用Excel来统计,为了年底资产审计方便,因此需要做CMDB
二、开发cmdb的思路和大概做法
--使用python代码执行linux的命令,并且获取服务器上的对应信息
--使用Http协议发送执行好的数据
三、cmdb的四套方案
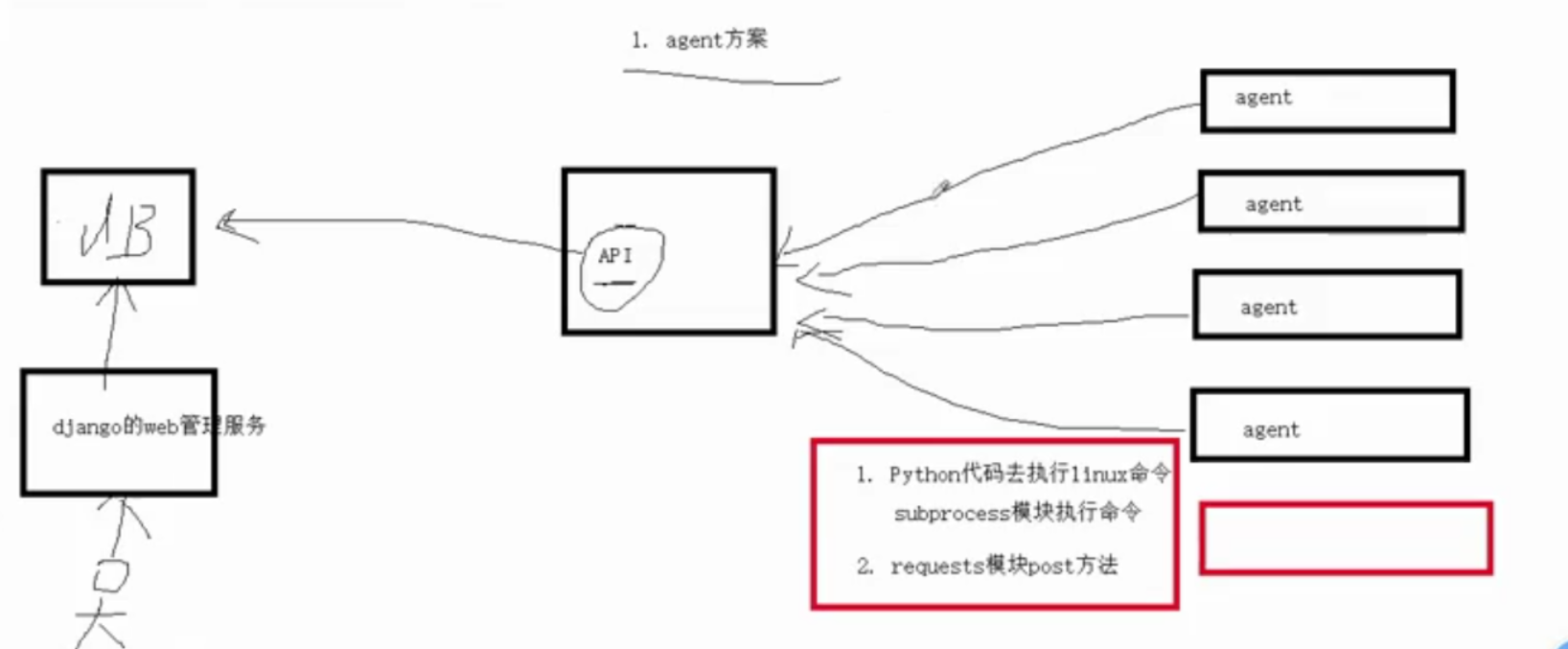
---agent模式
采集的服务器们(客户端)都是gent,然后我们需要在每一台服务器上去部署这个采集的脚本,把采集的脚本叫agent脚本,agent脚本主要是写python代码的
python就是执行linux命令的,使用的是subprocess 模块执行命令,接下来就是将执行的结果传给(使用requests模块post方法)服务端API,
API拿到结果之后,都需要进行二次分析,将分析好的数据传给db数据,然后我可以起一个django的web服务去db中取数据 创建django项目中test文件进行测试:
# 1.agent方案
import json #导模块快捷键,按alt+enter,再按enter
import subprocess res=subprocess.getoutput('ipconfig') #采集windows这台机器的ip地址
print(res[30-40]) #这台服务器的信息,res最终类型就是字符串,使用字符串的一些方法将其获取
data = json.dumps(res[30-40]) import requests ret = requests.post('http://127.0.0.1/8000',data=data)
优点:速度快 缺点:每次都需要部署 适用的场景:
服务器数量特别多的情况
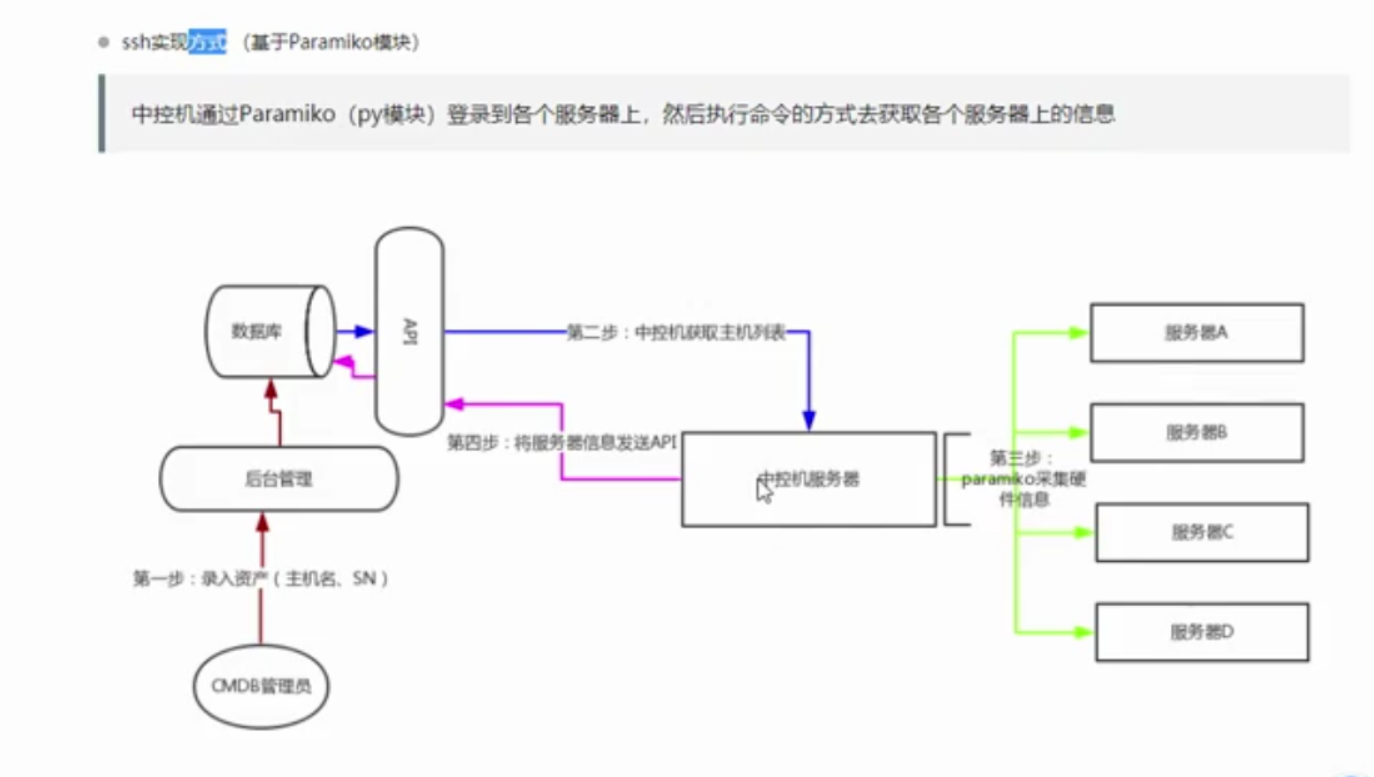
---ssh类模式
中控机的paramiko ,本质就是采用ssh协议22端口逐个的去连到采集的服务器上,就会执行命令,然后将结果返回给中控机,中控机还是通过request中的post
将数据交给API,API拿到数据之后再进行一个处理,然后将数据存到db里面,起django服务连接db
创建django项目中test文件进行测试:
#2.ssh类方案
import paramiko
# 创建SSH对象
ssh = paramiko.SSHClient()
# 允许连接不在know_hosts文件中的主机
ssh.set_missing_host_key_policy(paramiko.AutoAddPolicy())
# 连接服务器
ssh.connect(hostname='47.102.110.185', port=22, username='root', password='yayayaya20.')
# 执行命令
stdin, stdout, stderr = ssh.exec_command('df') #stdin 是当xshell连接到服务器后安装软件yum ...会问你是否要安装也就是y/n,而stdin就是接受这个结果的
# 获取命令结果
result = stdout.read()
print(result) # 关闭连接
ssh.close()
import requests ret = requests.post("http://127.0.0.1/8000", data=data)
缺点:使用paramiko登录服务器的话, 速度比较慢 优点: 不需要部署agent脚本 适用场景:
服务器比较少 (100)
---比较以上两套方案的优缺点
第一套方案:
-agent模式:
优点:速度快
缺点:每次都需要部署
适用的场景:服务器数量特别多的情况
-ssh类模式:
缺点:使用paramiko登录服务器的话,速度比较慢
优点:不需要部署agent脚本
适用场景:服务器比较少
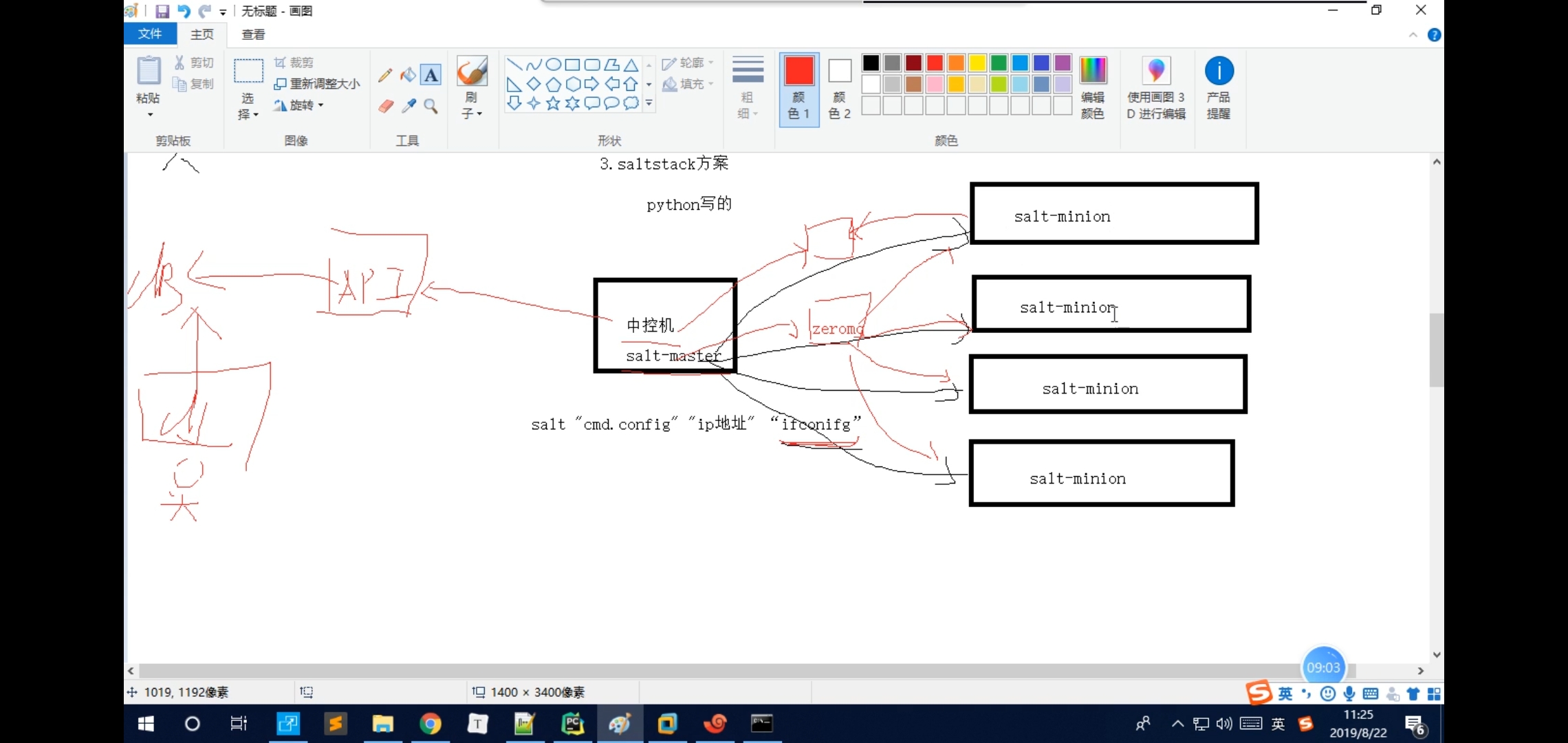
---saltstack模式
(也是一个采集的架构,中控机上装着一个软件saltstack,是用python写的,然后也是需要saltstack里面装着saltack-master.
需要在待采集的多台服务器上装一个软件salt-minion
中控机是这样采集的salt'cmd.config'ip地址'‘ifconfig’
本质就是,中控机先连上这些服务器去发linux相关的命令,发完之后,多台服务器会将结果返回给中控机,然后中控机拿到这些消息之后,
post给API,然后API去连一下DB数据库,然后django起一个web服务去连接db数据,然后管理员就可以看到了)
原理:
中控机底层原理,将命令放到一个队列里面,叫zeromq,然后连上的服务端从zeromq里面取服务器要执行的而命令,然后又起了一个zeromq这样的队列,将结果放到新的zeromq里面,
然后中控机去这里面取它的结果, 优点:
不用写python代码
使用场景:
-服务器上已经部署了salt-stack或想要使用salt-stack 使用:
sudo apt-get remove sudo apt-get remove salt-master
ubuntu的配置文件怎么删除
dpkg -l |grep ^rc|awk '{print $2}' |sudo xargs dpkg -P 软件
apt autoremove 连接服务器,创建一个会话,我的是阿里云ubuntu ,然后部署salt-master
先下载apt-get install salt-master
编辑vim /etc/salt/master
然后启动服务service salt-master start 重启的话是service salt-master restart
查看 service salt-master status
再下载apt-get install salt-minion
启动service salt-minion start
编辑vim /etc/salt/minion
查看 ps aux | grep salt
salt-key -L
salt-key -A (授权给中控机)
salt-key -L (再次查看)
salt "*"cmd.run 'ifconfig' (执行命令)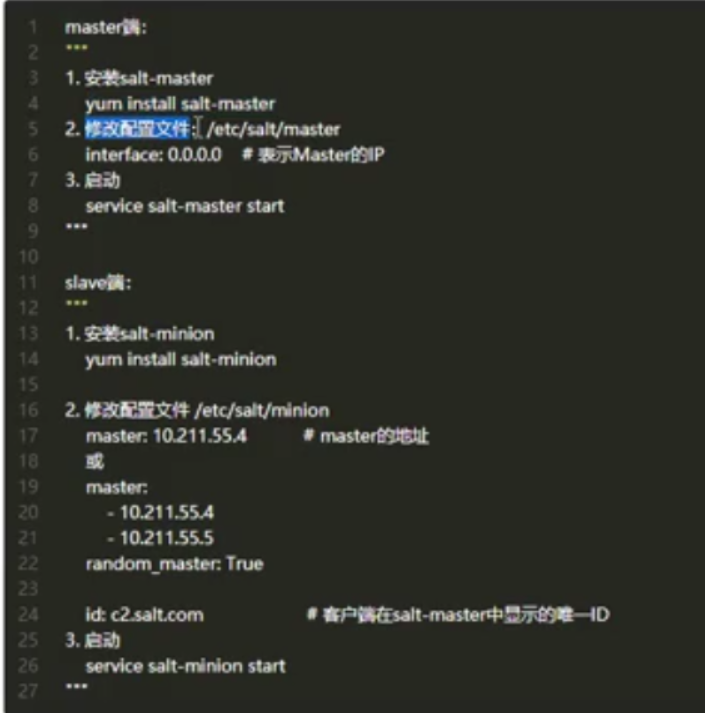
开发的时候选择哪套方案
三套方案都实现
将三套方案集成一份代码里面,只需要在配置文件中修改配置就可以换方案,三套方案不一样的地方就是数据采集这里
https://lupython.gitee.io/2018/05/05/CMDB介绍/
---puppet模式(比较传统,不常用)
ruby on rails
puppet每隔30分钟会定时执行任务,跟方案都是一样的 自动化运维的目的和愿景:
将之前人工介入的所有的操作,全部变成各类系统
降低人力成本
小总结:
1. 为什么要做CMDB? - 实现运维自动化, 而CMDB是实现运维自动化的基石
- 之前公司统计资产的时候,使用Excel来统计, 为了年底资产审计方便,因此需要做CMDB 2. CMDB的架构方案是什么?
- 调研的几套方案
- agent
- ssh类
- saltstack 3. 你们公司选用的是第几套方案? 根据公司的规模来去说 小公司的话, 第二套或者第三套
大公司的话, 第一套方案
cmdb简介的更多相关文章
- Ansible - 简介和应用自动化基础实践
installAnsible简介和应用自动化基础实践 一.引入: 1.1 如官方定义,Ansible is The simplest way to automate apps and IT infr ...
- Python学习之路【第一篇】-Python简介和基础入门
1.Python简介 1.1 Python是什么 相信混迹IT界的很多朋友都知道,Python是近年来最火的一个热点,没有之一.从性质上来讲它和我们熟知的C.java.php等没有什么本质的区别,也是 ...
- 巧用Salt,实现CMDB配置自动发现
随着互联网+新形势的发展,越来越多的企业步入双态(稳敏双态)IT时代,信息化环境越来越复杂,既有IOE三层架构,也有VCE.Openstack等云虚拟化架构和互联网化的分布式大数据架构.所以,企业急需 ...
- 双态运维分享之:业务场景驱动的服务型CMDB
最近这几年,国内外CMDB失败的案例比比皆是,成功的寥寥可数,有人质疑CMDB is dead?但各种业务场景表明,当下数据中心运维,CMDB依然是不可或缺的一部分,它承载着运维的基础,掌握运维的命脉 ...
- 双态运维分享之二: 服务型CMDB的消费场景
近年来,CMDB在IT运维管理中的价值逐步得到认可,使用CMDB的期望值也日益增长.然而,CMDB实施和维护的高成本却一直是建设者们的痛点.那么今天,我们来探讨一下如何通过消费来持续驱动CMDB的逐步 ...
- CMDB经验分享之 – 剖析CMDB的设计过程
作为IT管理的核心,CMDB逐渐成为系统管理项目实施的热点.在很多的案例中,由于忽视了CMDB的因素,ITIL的深入应用受到了极大的挑战.同时,由于CMDB是IT管理信息的集中,CMDB也是一个重要的 ...
- 最大开源代码sourceforge 简介 及视音频方面常用的开源代码
所有的音视频凯源代码在这里:http://sourceforge.net/directory/audio-video/os:windows/,你可以下载分析,视频不懂请发邮件给我,帮你分析. 0.视频 ...
- Ansible CMDB
Ansible CMDB CMDBAnsible-CMDB CMDB 文章目录 1. 简介 2. 安装 2.1. 1. 安装 ansible 2.2. 2. 下载并安装 ansible-cmdb 3. ...
- python简介及详细安装方法
1.Python简介 1.1 Python是什么 相信混迹IT界的很多朋友都知道,Python是近年来最火的一个热点,没有之一.从性质上来讲它和我们熟知的C.java.php等没有什么本质的区别,也是 ...
随机推荐
- 添砖加瓦:MySQL分布式部署
1.集群环境 管理节点(MGM):这类节点的作用是管理MySQLCluster内的其他节点,如提供配置数据,并停止节点,运行备份等.由于这类节点负责管理其他节点的配置,应该在启动其他节点之前启动这类 ...
- Atom配置(VIM党) · iuunhao
为什么说是Vim党呢?首先我是一个深度的Vim用户,自己的电脑上基本上可以兼容Vim的插件都有,所有浏览器,所有编辑器都是Vim的操作方式,当然包括我现在书写的markdown的软件EME也是兼容的V ...
- 重大改革!Python将被加入高考科目!
未来大学生将分为两种:一种是编程好的人,另一种是编程超好的人. Python 将被纳入高考科目 近期,浙江省信息技术课程改革方案出台,Python 确定进入浙江省信息技术高考,从2018年起浙江省信息 ...
- Git 常用资源
库管理 克隆库 git clone https://github.com/php/php-src.git git clone --depth=1 https://github.com/php/php- ...
- 美团CodeM 资格赛第一题
美团外卖的品牌代言人袋鼠先生最近正在进行音乐研究.他有两段音频,每段音频是一个表示音高的序列.现在袋鼠先生想要在第二段音频中找出与第一段音频最相近的部分. 具体地说,就是在第二段音频中找到一个长度和第 ...
- C++与引用2
*/ * Copyright (c) 2016,烟台大学计算机与控制工程学院 * All rights reserved. * 文件名:text.cpp * 作者:常轩 * 微信公众号:Worldhe ...
- 【Eclipse】eclipse设置,为了更简单快捷的开发
保存时自动导包 Windows->Perferences->Java->Editor->Save Actions
- 从零认识 DOM (一): 对象及继承关系
先上图为敬! 说明: 图中包括了大部分 DOM 接口及对象, 其中: 青色背景为接口, 蓝色背景为类, 灰色背景表示为 ECMAScript 中的对象 忽略了一部分对象, 包括: HTML/SVG 的 ...
- 使用HBuilder开发移动APP:开发环境准备(转)
一直想开发个APP玩玩的,但是作为一个PHP码农,需要新学习JAVA或者Object C,这也是一直没能实现这个目标的原因.但是现在HTML5+.APPCAN.apicloud很多工具利用前端技术就能 ...
- html/css系列-图片上下居中
本文详情:http://www.zymseo.com/276.html图片上下居中的问题常用的几种方法:图片已知大小和未知大小,自行理解 .main{ width: 400px;height: 400 ...