App的数据如何用python抓取
- 使用抓包工具
- 手机使用代理,app所有请求通过抓包工具
- 获得接口,分析接口
- 反编译apk获取key
- 突破反爬限制
- 夜神模拟器
- Fiddler
- Pycharm

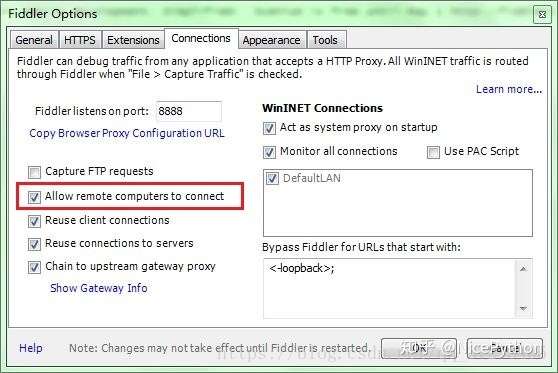
- 夜神模拟器下载完成之后,傻瓜式的安装一下!
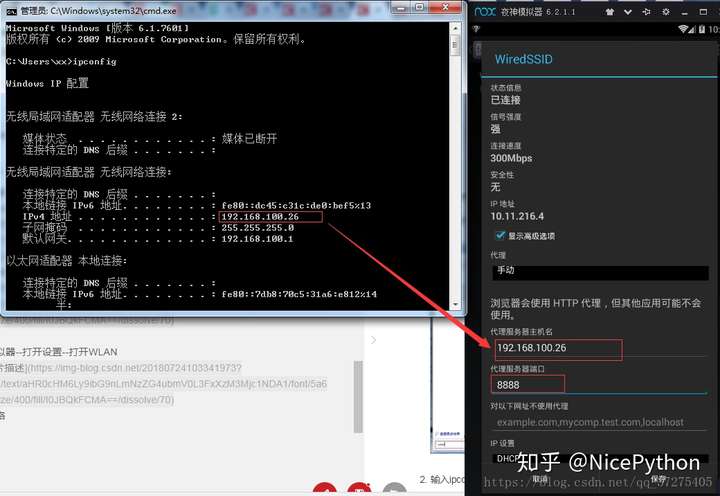
- 首先将当前手机网络桥接到本电脑网络 实现互通
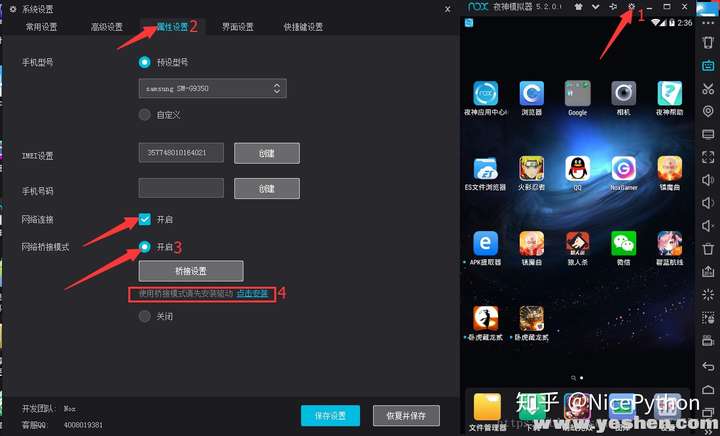
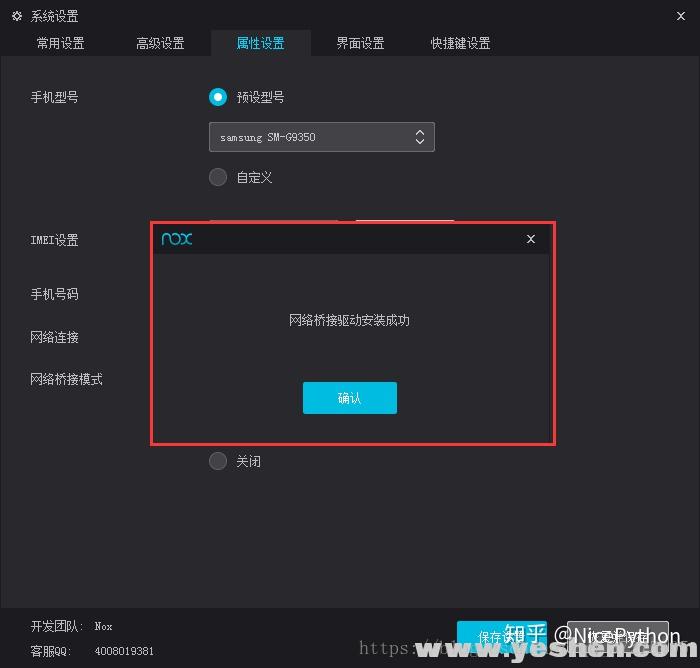
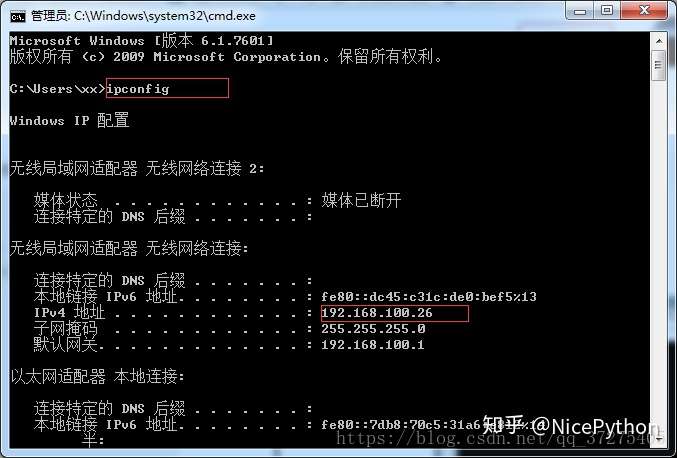
- 打开主机cmd


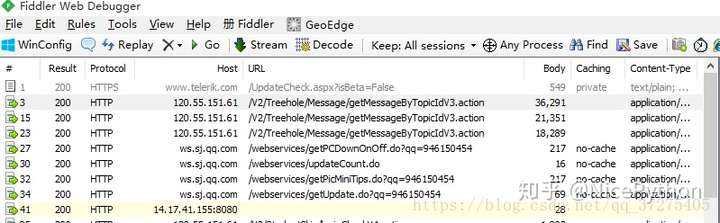
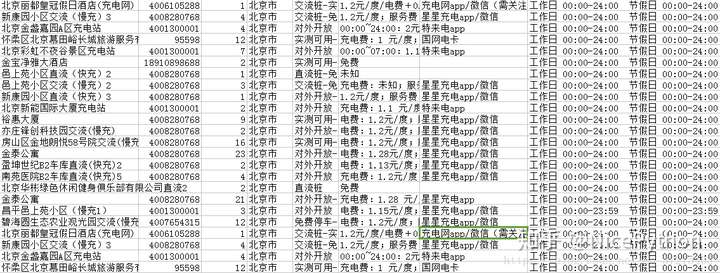
部分python代码分享:
import requestsimport cityimport jsonimport jsonpathimport recity_list = city.jsonstags_list = city.Tagdef city_func(city_id):try:city = jsonpath.jsonpath(city_list, '$..sub[?(@.code=={})]'.format(int(city_id)))[0]["name"]except:city = jsonpath.jsonpath(city_list, '$[?(@.code=={})]'.format(int(city_id)))[0]["name"]return citydef tags_func(tags_id):tags_join = []if tags_id:for tags in tags_id:t = jsonpath.jsonpath(tags_list,'$..spotFilterTags[?(@.id=={})]'.format(int(tags)))tags_join.append(t[0]["title"])return ('-'.join(tags_join))def split_n(ags):return re.sub('\n',' ',ags)def request(page):print('开始下载第%d页'%page)url = 'https://app-api.chargerlink.com/spot/searchSpot'two_url = "https://app-api.chargerlink.com/spot/getSpotDetail?spotId={d}"head = {"device": "client=android&cityName=%E5%8C%97%E4%BA%AC%E5%B8%82&cityCode=110106&lng=116.32154281224254&device_id=8A261C9D60ACEBDED7CD3706C92DD68E&ver=3.7.7&lat=39.895024107858724&network=WIFI&os_version=19","appId": "20171010","timestamp": "1532342711477","signature": "36daaa33e7b0d5d29ac9c64a2ce6c4cf","forcecheck": "1","Content-Type": "application/x-www-form-urlencoded","Content-Length": "68","Host": "app-api.chargerlink.com","Connection": "Keep-Alive","User-Agent": "okhttp/3.2.0"}data = {"userFilter[operateType]": 2,"cityCode": 110000,"sort": 1,"page": page,"limit": 10,}response = requests.post(url,data=data,headers=head)#获取数据data = response.json()for i in data['data']:c = []id = i['id']name = i["name"] #充电桩名phone = i["phone"] #手机号num = i['quantity'] #有几个充电桩city = city_func(i["provinceCode"]) #城市tags =tags_func(i["tags"].split(','))#标签message = c + [id,name,phone,num,city,tags]parse_info(two_url.format(d=id),message)def parse_info(url,message):#打开文件with open('car.csv','a',encoding='utf-8')as c:head = {"device": "client=android&cityName=&cityCode=&lng=116.32154281224254&device_id=8A261C9D60ACEBDED7CD3706C92DD68E&ver=3.7.7&lat=39.895024107858724&network=WIFI&os_version=19","TOKEN": "036c8e24266c9089db50899287a99e65dc3bf95f","appId": "20171010","timestamp": "1532357165598","signature": "734ecec249f86193d6e54449ec5e8ff6","forcecheck": "1","Host": "app-api.chargerlink.com","Connection": "Keep-Alive","User-Agent": "okhttp/3.2.0",}#发起详情请求res = requests.get(url,headers=head)price = split_n(jsonpath.jsonpath(json.loads(res.text),'$..chargingFeeDesc')[0]) #价钱payType = jsonpath.jsonpath(json.loads(res.text),'$..payTypeDesc')[0] #支付方式businessTime =split_n(jsonpath.jsonpath(json.loads(res.text),'$..businessTime')[0]) #营业时间result = (message + [price,payType,businessTime])r = ','.join([str(i) for i in result])+',\n'c.write(r)def get_page():url = 'https://app-api.chargerlink.com/spot/searchSpot'head = {"device": "client=android&cityName=%E5%8C%97%E4%BA%AC%E5%B8%82&cityCode=110106&lng=116.32154281224254&device_id=8A261C9D60ACEBDED7CD3706C92DD68E&ver=3.7.7&lat=39.895024107858724&network=WIFI&os_version=19","appId": "20171010","timestamp": "1532342711477","signature": "36daaa33e7b0d5d29ac9c64a2ce6c4cf","forcecheck": "1","Content-Type": "application/x-www-form-urlencoded","Content-Length": "68","Host": "app-api.chargerlink.com","Connection": "Keep-Alive","User-Agent": "okhttp/3.2.0"}data = {"userFilter[operateType]": 2,"cityCode": 110000,"sort": 1,"page": 1,"limit": 10,}response = requests.post(url, data=data, headers=head)# 获取数据data = response.json()total = (data["pager"]["total"])page_Size = (data["pager"]["pageSize"])totalPage = (data['pager']["totalPage"])print('当前共有{total}个充电桩,每页展示{page_Size}个,共{totalPage}页'.format(total=total,page_Size=page_Size,totalPage=totalPage))if __name__ == '__main__':get_page()start = int(input("亲,请输入您要获取的开始页:"))end = int(input("亲,请输入您要获取的结束页:"))for i in range(start,end+1):request(i)


App的数据如何用python抓取的更多相关文章
- 如何用python抓取js生成的数据 - SegmentFault
如何用python抓取js生成的数据 - SegmentFault 如何用python抓取js生成的数据 1赞 踩 收藏 想写一个爬虫,但是需要抓去的的数据是js生成的,在源代码里看不到,要怎么才能抓 ...
- (转)如何用python抓取网页并提取数据
最近一直在学这部分,今日发现一篇好文,虽然不详细,但是轮廓是出来了: 来自crifan:http://www.crifan.com/crawl_website_html_and_extract_inf ...
- 使用 Python 抓取欧洲足球联赛数据
Web Scraping在大数据时代,一切都要用数据来说话,大数据处理的过程一般需要经过以下的几个步骤 数据的采集和获取 数据的清洗,抽取,变形和装载 数据的分析,探索和预测 ...
- 关于python抓取google搜索结果的若干问题
关于python抓取google搜索结果的若干问题 前一段时间一直在研究如何用python抓取搜索引擎结果,在实现的过程中遇到了很多的问题,我把我遇到的问题都记录下来,希望以后遇到同样问题的童 ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
- 使用python抓取并分析数据—链家网(requests+BeautifulSoup)(转)
本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取.通过使用requests库对链家网二手房列表页进行抓取,通过Beautifu ...
- 使用Python抓取猫眼近10万条评论并分析
<一出好戏>讲述人性,使用Python抓取猫眼近10万条评论并分析,一起揭秘“这出好戏”到底如何? 黄渤首次导演的电影<一出好戏>自8月10日在全国上映,至今已有10天,其主演 ...
- python抓取网页例子
python抓取网页例子 最近在学习python,刚刚完成了一个网页抓取的例子,通过python抓取全世界所有的学校以及学院的数据,并存为xml文件.数据源是人人网. 因为刚学习python,写的代码 ...
- Python抓取页面中超链接(URL)的三中方法比较(HTMLParser、pyquery、正则表达式) <转>
Python抓取页面中超链接(URL)的3中方法比较(HTMLParser.pyquery.正则表达式) HTMLParser版: #!/usr/bin/python # -*- coding: UT ...
随机推荐
- Scapy编写ICMP扫描脚本
使用Scapy模块编写ICMP扫描脚本: from scapy.all import * import optparse import threading import os def scan(ipt ...
- vue2源码分析:patch函数
目录 1.patch函数的脉络 2.类vnode的设计 3.createPatch函数中的辅助函数和patch函数 4.源码运行展示(DEMO) 一.patch函数的脉络 首先梳理一下patch函数的 ...
- 关于Anaconda安装以后使用Jupyter Notebook无法直接打开浏览器的解决方法
关于Anaconda安装以后使用Jupyter Notebook无法直接打开浏览器的解决方法 1.首先打开Anoconda Prompt,输入命令 jupyter notebook --generat ...
- innobackupex备份过程(有图有真相)
innobackupex命令构成: 1. Innobackupex内部封装了xtrabackup和mysqldump命令: 2. Xtrabackup是用来备份innoDB表的,内部实现对innoDB ...
- 【深度学习】Neural networks(神经网络)(一)
神经网络的图解 感知机,是人工设置权重.让它的输出值符合预期. 而神经网络的一个重要性质是它可以自动地从数据中学习到合适的权重参数. 如果用图来表示神经网络,最左边的一列称为输入层,最右边的一列称为输 ...
- Java——类的定义
对象和类的关系:有一个学生 ,需要在表格上填写自己的信息 ,那么这个打印机就像一个类 ,打印出的表格就是一个对象,用类创建对象,学生填的信息 ,就是我所初始化的信息. 类的组成:由 属性(也叫成员变量 ...
- Codeforces 1322C - Instant Noodles(数学)
题目链接 题意 给出一个二分图, 两边各 n 个点, 共 m 条边, n, m ≤ 5e5. 右边的点具有权值 \(c_i\), 对于一个只包含左边的点的点集 S, 定义 N(S) 为所有与这个点集相 ...
- 封装属于自己的Python包
将自己的程序打包为whl/tar.gz文件 有时候自己写了一个开发基本类,我们把这个类打包为whl或者tar.gz文件,这样的话同事也可以使用自己开发的基本类了 安装setuptools pip in ...
- vi文本编辑器的学习
vi文本编辑器的启动与退出 启动:快捷键Ctrl+Alt+t进入终端, 在系统提示符($或#)的提示下,输入vi <文件名称>,可以自动载入你要编辑的文件或者新建一个文件. 退出:在指令模 ...
- ANTLR随笔(二)
安装ANTLR 作者的电脑是MAC的操作系统macOS Catalina 10.15.2. 安装步骤后linux操作的系统的一样, Windows系统大致步骤一样,但是环境变量等配置有差别,作者很久没 ...