详解 stream流
在本人之前的博文中,我们学习了 I/O流、NIO流的相关概念。
那么,在JDK8的更新内容中,提出了一个新的流 —— stream流
那么,现在,本人就来讲解下这个流:
stream流
概述:
是数据渠道,用于操作数据源(集合、数组等)所生成的元素序列。
集合讲的是数据,流讲的是计算!
注意:
- ①Stream 自己不会存储元素;
- ②Stream 不会改变源对象。
相反,他们会返回一个持有结果的新Stream;- ③Stream 操作是延迟执行的。
这意味着他们会等到需要结果的时候才执行
Stream 的操作三个步骤:
- 创建 Stream
一个数据源(如:集合、数组),获取一个流- 中间操作
一个中间操作链,对数据源的数据进行处理- 终止操作(终端操作)
一个终止操作,执行中间操作链,并产生结果
那么,本人现在就来讲解下Stream的三步操作所运用的方法及使用:
首先,本人给出一个用于存储员工信息的Employee类:
package edu.youzg.about_new_features.core.about_jdk8.core;public class Employee {private int id; //员工的idprivate String name; //员工的姓名private int age; //员工的年龄private double salary; //员工的工资private Status status; //员工的状态public Employee() {}public Employee(String name) {this.name = name;}public Employee(String name, int age) {this.name = name;this.age = age;}public Employee(int id, String name, int age, double salary) {this.id = id;this.name = name;this.age = age;this.salary = salary;}public Employee(int id, String name, int age, double salary, Status status) {this.id = id;this.name = name;this.age = age;this.salary = salary;this.status = status;}public Status getStatus() {return status;}public void setStatus(Status status) {this.status = status;}public int getId() {return id;}public void setId(int id) {this.id = id;}public String getName() {return name;}public void setName(String name) {this.name = name;}public int getAge() {return age;}public void setAge(int age) {this.age = age;}public double getSalary() {return salary;}public void setSalary(double salary) {this.salary = salary;}public String show() {return "测试方法引用!";}@Overridepublic int hashCode() {final int prime = 31;int result = 1;result = prime * result + age;result = prime * result + id;result = prime * result + ((name == null) ? 0 : name.hashCode());long temp;temp = Double.doubleToLongBits(salary);result = prime * result + (int) (temp ^ (temp >>> 32));return result;}@Overridepublic boolean equals(Object obj) {if (this == obj) {return true;}if (obj == null) {return false;}if (getClass() != obj.getClass()) {return false;}Employee other = (Employee) obj;if (age != other.age) {return false;}if (id != other.id) {return false;}if (name == null) {if (other.name != null) {return false;}} else if (!name.equals(other.name)) {return false;}if (Double.doubleToLongBits(salary) != Double.doubleToLongBits(other.salary)) {return false;}return true;}@Overridepublic String toString() {return "Employee [id=" + id + ", name=" + name + ", age=" + age + ", salary=" + salary + ", status=" + status + "]";}/* 表示员工状态的枚举 */public enum Status {FREE, //空闲BUSY, //繁忙VOCATION; //休假}}
那么,现在本人来讲解下 stream流的常用API:
常用API:
概述:
Stream 是 Java8 中处理集合的关键抽象概念,
它可以指定你希望对集合进行的操作,
可以执行非常复杂的查找、过滤和映射 数据等操作。
使用Stream API 对集合数据进行操作,就类似于使用 SQL 执行的数据库查询。
也可以使用 Stream API 来并行执行操作。
简而言之,Stream API 提供了一种高效且易于使用的处理数据的方式。
创建Stream的方式:
- Java8 中的 Collection 接口被扩展,提供了两个获取流的方法:
- default Stream< E > stream() :
返回一个顺序流- default Stream< E > parallelStream() :
返回一个并行流
- Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
- static < T > Stream< T > stream(T[] array):
返回一个流
重载形式,能够处理对应基本类型的数组:
- public static IntStream stream(int[] array)
- public static LongStream stream(long[] array)
- public static DoubleStream stream(double[] array)
- 由值创建流:
可以使用静态方法 Stream.of(), 通过显示值创建一个流。
它可以接收任意数量的参数。
public static< T > Stream< T > of(T... values) :
返回一个流
- 由函数创建流:
创建无限流可以使用静态方法 Stream.iterate()和Stream.generate(), 创建无限流。
- public static< T > Stream< T > iterate(final T seed, finalUnaryOperator< T > f) 迭代
- public static< T > Stream< T > generate(Supplier< T > s) 生成
那么,现在本人就来展示下如何 创建Stream:
package edu.youzg.about_new_features.core.about_jdk8.core;import java.util.Arrays;import java.util.List;import java.util.stream.Stream;public class Test {public static void main(String[] args) {/* 如何获取Stream流 *///方式1.集合中的方法 stream():List<Integer> list = Arrays.asList(20, 30, 50);Stream<Integer> stream = list.stream();//方式2:通过Arrays工具类里面的stream()方法,也可以得到Stream流:Integer[] arr={20,30,50,30};Stream<Integer> stream1 = Arrays.stream(arr);//方式3:Stream类 的静态方法of():Stream<Integer> integerStream = Stream.of(30, 30, 20, 69);//方式4:获取无限流iterate():Stream<Integer> iterate = Stream.iterate(1, num -> num + 1).limit(5); //输出从1到5//终止操作(只有到了终止操作,才执行之前的操作)iterate.forEach(System.out::println);//方式5:获取无限流generate():Stream<Double> generate = Stream.generate(Math::random).limit(5); //输出5个随机数//终止操作(只有到了终止操作,才执行之前的操作)generate.forEach(System.out::println);}}
Stream的 中间操作:
概述:
多个中间操作可以连接起来形成一个流水线,
除非流水线上触发终止操作,否则中间操作不会执行任何的处理!
而在终止操作时一次性全部处理,称为“惰性求值”。
- 筛选与切片:
- filter(Predicate p):
过滤 接收 Lambda , 从流中排除某些元素。- distinct():
去重,通过流所生成元素的 hashCode() 和 equals() 去除重复元素- limit(long maxSize):
截断流,使其元素不超过给定数量。- skip(long n):
跳过元素,返回一个扔掉了前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。与 limit(n) 互补
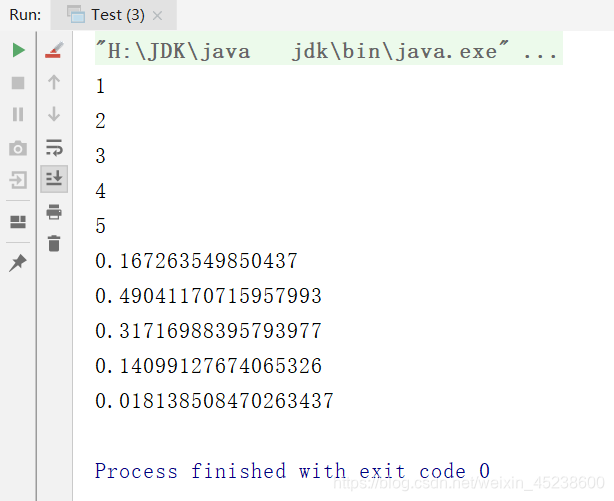
那么,本人现在通过一段代码展示下这些API 的使用:
package edu.youzg.about_new_features.core.about_jdk8.core;import java.util.Arrays;import java.util.List;import java.util.stream.Stream;public class Test {public static void main(String[] args) {/* 如何获取Stream流 *///中间操作//筛选与切片//通过集合获取流List<Employee> emps = Arrays.asList(new Employee(001, "树下渚", 59, 6666.66),new Employee(002, "火中琴美", 18, 9999.99),new Employee(003, "雪中智代", 28, 3333.33),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(005, "雨中杏", 26, 5555.55));//获取一个关联集合的流Stream<Employee> stream = emps.stream();//进行中间环节的操作//把工资大于7000的员工过滤出来Stream<Employee> stream1 = stream.filter(employee -> {return employee.getSalary()>7000; //符合条件的返回true放到新的流中,不符合条件返回false新的流就不要;});//终止操作 遍历//输出持有新结果的流stream1.forEach(System.out::println);System.out.println("=====================");//我要过滤掉“花间汐”Stream<Employee> stream2 = emps.stream();//stream3 就是你过滤完之后,返回的持有新结果的流Stream<Employee> stream3 = stream2.filter(employee -> employee.getName().endsWith("汐"));//终止操作,遍历输出保存新结果的流stream3.forEach(System.out::println);System.out.println("=====================");//我要对集合中元素“去重”Stream<Employee> stream4 = emps.stream();//终止操作,遍历输出保存新结果的流stream4.distinct().forEach(System.out::println);System.out.println("=====================");//skip(2) 跳过前两个元素,取剩下的Stream<Employee> stream5 = emps.stream();//终止操作,遍历输出保存新结果的流stream5.skip(2).forEach(System.out::println);}}
现在,本人来展示下运行结果:
- 映射:
- map(Function f):
接收一个函数作为参数,
该函数会被应用到每个元素上,并将其映射成一个新的元素- flatMap(Function f):
接收一个函数作为参数,
将流中的每个值都换成另一个流,然后把所有流连接成一个流- mapToDouble(ToDoubleFunction f):
接收一个函数作为参数,
该函数会被应用到每个元素上,产生一个新的 DoubleStream- mapToInt(ToIntFunction f):
接收一个函数作为参数,
该函数会被应用到每个元素上,产生一个新的 IntStream- mapToLong(ToLongFunction f):
接收一个函数作为参数,
该函数会被应用到每个元素上,产生一个新的 LongStream
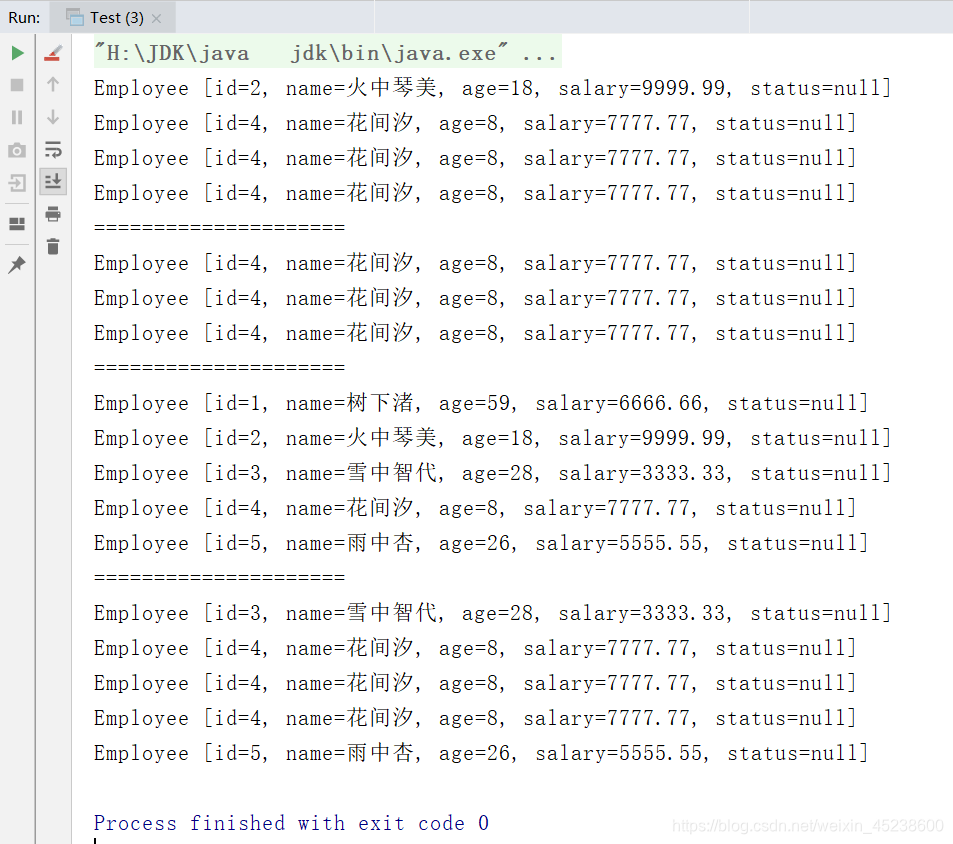
那么,本人现在通过一段代码展示下这些API 的使用:
package edu.youzg.about_new_features.core.about_jdk8.core;import java.util.ArrayList;import java.util.Arrays;import java.util.List;import java.util.function.Function;import java.util.stream.Stream;public class Test {public static void main(String[] args) {/* 中间操作:映射 *///通过集合获取流List<Employee> emps = Arrays.asList(new Employee(001, "树下渚", 59, 6666.66),new Employee(002, "火中琴美", 18, 9999.99),new Employee(003, "雪中智代", 28, 3333.33),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(005, "雨中杏", 26, 5555.55));//获取一个关联集合的流Stream<Employee> stream = emps.stream();//进行中间环节的操作//将存储的信息的姓名获取并输出Stream<String> stream1 = stream.map(employee -> employee.getName());stream1.forEach(System.out::println);System.out.println("===============================");// flatMap(Function f) 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流.List<String> list2 = Arrays.asList("aaa", "bbb", "ccc");Stream<String> stream2 = list2.stream();stream2.flatMap((Function<String, Stream<Character>>) s -> getChar(s)).forEach(character -> System.out.println(character));}private static Stream<Character> getChar(String str) {ArrayList<Character> list = new ArrayList<>();for (char ch : str.toCharArray()) {list.add(ch);}Stream<Character> stream = list.stream();return stream;}}
现在,本人来展示下运行结果:
- 排序:
- sorted():
产生一个新流,其中按自然顺序排序
(元素实现Compareble接口)- sorted(Comparator comp):
产生一个新流,其中按比较器顺序排序
(需传入一个比较器)
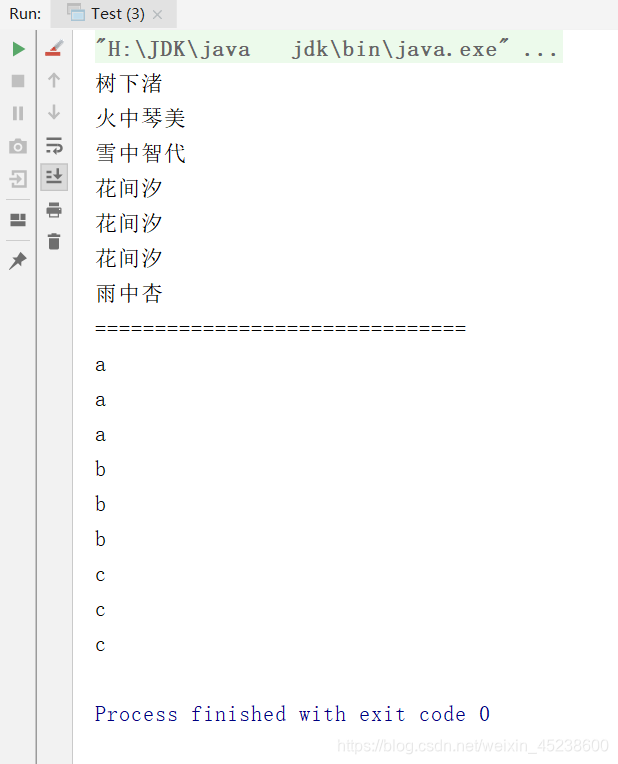
那么,现在,本人来展示下这些API的使用:
package edu.youzg.about_new_features.core.about_jdk8.core;import java.util.Arrays;import java.util.List;import java.util.stream.Stream;public class Test {public static void main(String[] args) {/* 中间操作:排序 *///通过集合获取流List<Employee> emps = Arrays.asList(new Employee(001, "树下渚", 59, 6666.66),new Employee(002, "火中琴美", 18, 9999.99),new Employee(003, "雪中智代", 28, 3333.33),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(005, "雨中杏", 26, 5555.55));//获取一个关联集合的流//按照年龄排序Stream<Employee> stream = emps.stream();Stream<Employee> stream1 = stream.sorted((a, b) -> a.getAge() - b.getAge()); //自然排序stream1.forEach(System.out::println);}}
现在,本人来展示下运行结果:

Stream的 终止操作:
概述:
终端操作会从 流的流水线 生成结果。
不做终止操作,中间环节就不执行,体现的就是延迟加载的思想;
只有用的时候,中间环节再进行。
其结果可以是任何不是流的值
例如:List、Integer,甚至是 void
- 查找与匹配:
- allMatch(Predicate p):
检查是否匹配所有元素
比如判断 所有员工的年龄都是17岁 如果有一个不是,就返回false- anyMatch(Predicate p):
检查是否至少匹配一个元素
比如判断是否有姓王的员工,如果至少有一个就返回true- noneMatch(Predicate p):
检查是否与 所有元素 都不匹配
比如 所有员工的工资都小于3000返回ture ,有任意一个大于3000 返回false- findFirst():
返回第一个元素
比如获取工资最高的人 或者 获取工资最高的值是- findAny():
返回当前流中的任意元素
比如随便获取一个姓王的员工- count() :
返回流中元素总数- max(Comparator c):
返回流中最大值
比如:获取最大年龄值- min(Comparator c):
返回流中最小值
比如:获取最小年龄的值- forEach(Consumer c):
内部迭代
(使用 Collection 接口需要用户去做迭代,称为外部迭代。
相反,Stream API 使用内部迭代——它帮你把迭代做了)
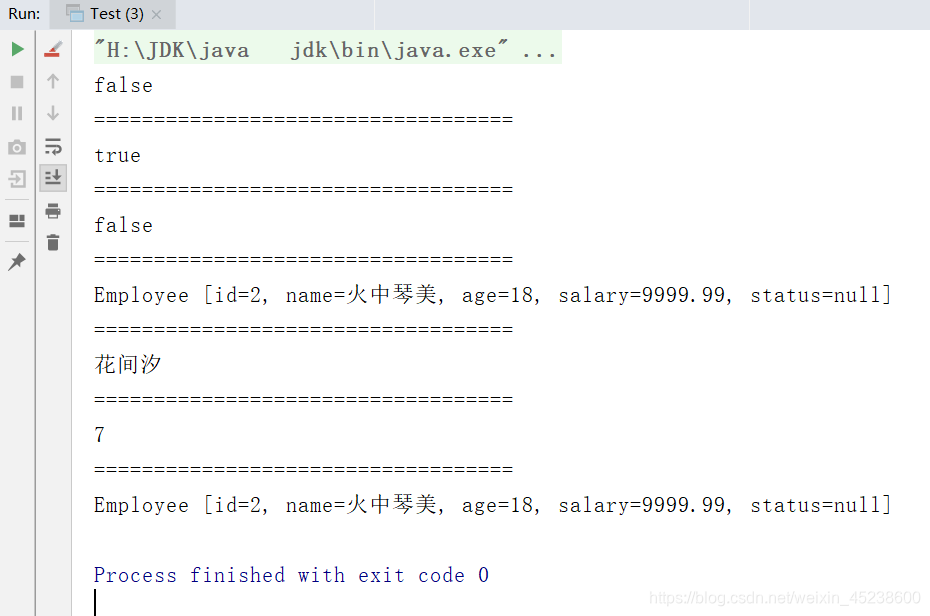
那么,本人来展示下这些API的使用:
package edu.youzg.about_new_features.core.about_jdk8.core;import java.util.Arrays;import java.util.List;import java.util.Optional;import java.util.stream.Stream;public class Test {public static void main(String[] args) {/* 终止操作:查找与匹配 *///通过集合获取流List<Employee> emps = Arrays.asList(new Employee(001, "树下渚", 19, 6666.66),new Employee(002, "火中琴美", 18, 9999.99),new Employee(003, "雪中智代", 16, 3333.33),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(005, "雨中杏", 17, 5555.55));//获取一个关联集合的流Stream<Employee> stream = emps.stream();//如果有一个的年龄不是16, 就返回falseboolean b = stream.allMatch(employee -> employee.getAge()==16);System.out.println(b);System.out.println("===================================");// 比如判断是否有姓王的员工, 如果至少有一个就返回trueStream<Employee> stream1 = emps.stream();boolean b1 = stream1.anyMatch(employee -> employee.getName().endsWith("杏"));System.out.println(b1);System.out.println("===================================");//检查是否所有员工的工资都小于3000,若是返回ture ,若有任意一个大于3000 返回falseStream<Employee> stream2 = emps.stream();boolean b2 = stream2.noneMatch(employee -> employee.getSalary()>3000);System.out.println(b2);System.out.println("===================================");//获取工资最高的员工Stream<Employee> stream3 = emps.stream();Optional<Employee> first = stream3.sorted((e1, e2) -> (int) (e2.getSalary() - e1.getSalary())).findFirst();// Optional 容器,存放的是:你筛选出的结果,该结果使用 get()方法可以取出来Employee employee = first.get();System.out.println(employee);System.out.println("===================================");//随机获取一个员名字// Stream<Employee> stream4 = emps.stream(); //串行流Stream<Employee> stream4 = emps.parallelStream(); //并行流Stream<String> stringStream = stream4.map(employee1 -> employee1.getName());Optional<String> any = stringStream.findAny();String s = any.get();System.out.println(s);System.out.println("===================================");//统计员工的个数long count = emps.stream().count();System.out.println(count);System.out.println("===================================");//获取最高工资Optional<Employee> max = emps.stream().max((e1, e2) -> (int) (e1.getSalary() - e2.getSalary()));System.out.println(max.get());}}
现在,本人来展示下运行结果:
- 归约
- reduce(T iden, BinaryOperator b):
参1 是起始值, 参2 二元运算
用iden的值作为初始值,将集合中的每一个值与之相加
返回 T
比如: 求集合中元素的累加总和- reduce(BinaryOperator b):
这个方法没有起始值
将集合中的每一个值与之相加
返回 Optional< T >
比如你可以算所有员工工资的总和
备注:map 和 reduce 的连接通常称为 map-reduce 模式
因此 Google 用它来进行网络搜索而出名。
那么,本人来展示下这些API的使用:
package edu.youzg.about_new_features.core.about_jdk8.core;import java.util.Arrays;import java.util.List;import java.util.stream.Stream;public class Test {public static void main(String[] args) {/* 终止操作:归约 *///通过集合获取流List<Employee> emps = Arrays.asList(new Employee(001, "树下渚", 19, 6666.66),new Employee(002, "火中琴美", 18, 9999.99),new Employee(003, "雪中智代", 16, 3333.33),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(005, "雨中杏", 17, 5555.55));//获取一个关联集合的流Stream<Employee> stream = emps.stream();Stream<Double> stream1 = stream.map(employee -> employee.getSalary());//参数1 起始值Double reduce = stream1.reduce(6666.66, (a, b) -> a + b);System.out.println(reduce);System.out.println("========================");//求员工的总工资Double aDouble = emps.stream().map(employee -> employee.getSalary()).reduce((double) 0, (a, b) -> a + b);System.out.println(aDouble);}}
现在,本人来展示下运行结果:
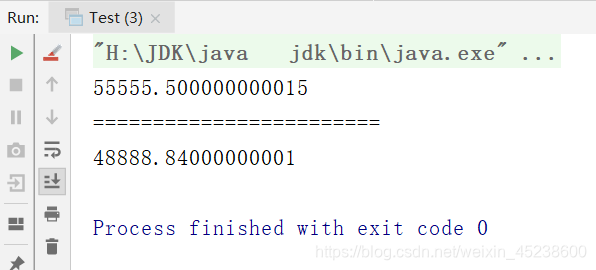
可以看到由于我们第一次reduce()设置的初始值是6666.66,所以比第二种多了6666.66
至于为什么结果不太准确,这就是C语言的知识了:
因为double是双精度浮点数,所以在大量运算之后,可能会有稍许误差
- 收集:
- collect(Collector c):
将流转换为其他形式
接收一个 Collector接口的实现,用于给Stream中元素做汇总的方法
Collector 接口中方法的实现决定了如何对流执行收集操作
(如收集到 List、Set、Map)
但是 Collectors 实用类提供了很多静态方法,可以方便地创建常见收集器实例
那么,本人现在来展示下这个API 的使用:
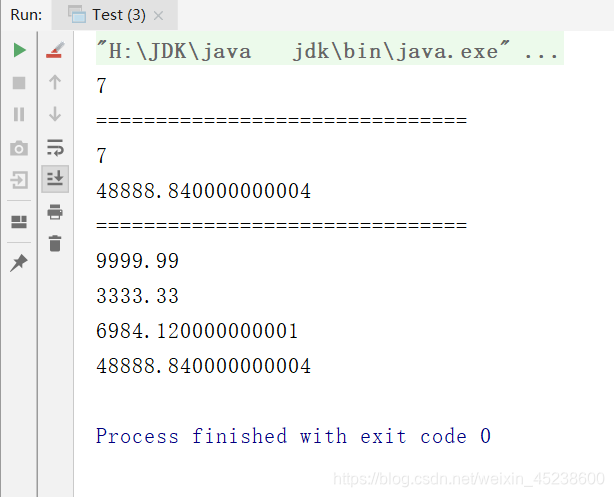
package edu.youzg.about_new_features.core.about_jdk8.core;import java.util.Arrays;import java.util.DoubleSummaryStatistics;import java.util.List;import java.util.stream.Collectors;import java.util.stream.Stream;public class Test {public static void main(String[] args) {/* 终止操作:收集 *///通过集合获取流List<Employee> emps = Arrays.asList(new Employee(001, "树下渚", 19, 6666.66),new Employee(002, "火中琴美", 18, 9999.99),new Employee(003, "雪中智代", 16, 3333.33),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(004, "花间汐", 8, 7777.77),new Employee(005, "雨中杏", 17, 5555.55));//获取一个关联集合的流Stream<Employee> stream = emps.stream();//获取存放入集合的对象总数long count = emps.stream().count();System.out.println(count);System.out.println("===============================");Long collect = emps.stream().collect(Collectors.counting());System.out.println(collect);//计算总工资Double collect1 = emps.stream().collect(Collectors.summingDouble(value -> value.getSalary()));System.out.println(collect1);System.out.println("===============================");// Collectors.summarizingDouble(Employee::getSalary)DoubleSummaryStatistics collect2 = emps.stream().collect(Collectors.summarizingDouble(Employee::getSalary));double average = collect2.getAverage();double max = collect2.getMax();double min = collect2.getMin();double sum = collect2.getSum();System.out.println(max);System.out.println(min);System.out.println(average);System.out.println(sum);}}
现在,本人来展示下运行结果:
- Collectors 中的方法:
- List< T > toList():
把流中元素收集到List
比如把所有员工的名字通过map()方法提取出来之后,在放到List集合中去
例子:List< Employee > emps= list.stream().map(提取名字).collect(Collectors.toList());- Set< T > toSet():
把流中元素收集到Set
比如把所有员工的名字通过map()方法提取出来之后,在放到Set集合中去
例子:Set< Employee > emps= list.stream().collect(Collectors.toSet());- Collection< T > toCollection():
把流中元素收集到创建的集合
比如把所有员工的名字通过map()方法提取出来之后,在放到自己指定的集合中去
例子:Collection< Employee >emps=list.stream().map(提取名字).collect(Collectors.toCollection(ArrayList::new));- Long counting():
计算流中元素的个数
例子:long count = list.stream().collect(Collectors.counting());- Integer summingInt():
对流中元素的整数属性求和
例:inttotal=list.stream().collect(Collectors.summingInt(Employee::getSalary));- Double averagingInt():
计算流中元素Integer属性的平均值
例子:doubleavg= list.stream().collect(Collectors.averagingInt(Employee::getSalary));- IntSummaryStatistics summarizingInt():
收集流中Integer属性的统计值。
例子:DoubleSummaryStatistics dss= list.stream().collect(Collectors.summarizingDouble(Employee::getSalary));
从DoubleSummaryStatistics 中可以获取最大值,平均值等
double average = dss.getAverage();
long count = dss.getCount();
double max = dss.getMax();- String joining():
连接流中每个字符串
比如把所有人的名字提取出来,在通过"-"横杠拼接起来
例子:String str= list.stream().map(Employee::getName).collect(Collectors.joining("-"));- Optional< T > maxBy() 根据比较器选择最大值 比如求最大工资
例子:Optional< Emp >max= list.stream().collect(Collectors.maxBy(comparingInt(Employee::getSalary)));- Optional< T > minBy():
根据比较器选择最小值
比如求最小工资
例子:Optional< Emp > min = list.stream().collect(Collectors.minBy(comparingInt(Employee::getSalary)));
归约产生的类型 reducing() 从一个作为累加器的初始值开始,利用BinaryOperator与流中元素逐个结合,从而归约成单个值
例子:inttotal=list.stream().collect(Collectors.reducing(0, Employee::getSalar, Integer::sum));- collectingAndThen():
转换函数返回的类型
包裹另一个收集器,对其结果转换函数
例子:inthow= list.stream().collect(Collectors.collectingAndThen(Collectors.toList(), List::size));- Map<K, List< T >> groupingBy():
根据某属性值对流分组,属性为K,结果为V
比如按照 状态分组
例子:Map<Emp.Status, List< Emp >> map= list.stream().collect(Collectors.groupingBy(Employee::getStatus));- Map<Boolean, List< T >> partitioningBy():
根据true或false进行分区
比如 工资大于等于6000的一个区,小于6000的一个区
例子:Map<Boolean,List< Emp >>vd= list.stream().collect(Collectors.partitioningBy(Employee::getSalary));
由于上面的API 太多,所以本人就在每一个方法的解释后给出了例子。
在上面的讲解中,本人提到了两个相关名词 —— 并行流与串行流:
并行流 与 串行流:
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
Java 8 中将并行进行了优化,我们可以很容易的对数据进行并行操作。
Stream API 可以声明性地通过 parallel() 与sequential() 在并行流与顺序流之间进行切换。
详解 stream流的更多相关文章
- 详解 NIO流
在观看本篇博文前,建议先观看本人博文 -- <详解 IO流> NIO流: 首先,本人来介绍下什么是NIO流: 概述: Java NIO ( New IO )是从 Java 1.4 版本开始 ...
- 第三天:JS事件详解-事件流
学习来源: F:\新建文件夹 (2)\HTML5开发\HTML5开发\04.JavaScript基础\6.JavaScript事件详解 学习内容: 1)基础概念 2)举例说明: 代码如上,如果用事件 ...
- MySQL系列详解三:MySQL中各类日志详解-技术流ken
前言 日志文件记录了MySQL数据库的各种类型的活动,MySQL数据库中常见的日志文件有 查询日志,慢查询日志,错误日志,二进制日志,中继日志 .下面分别对他们进行介绍. 查询日志 1.查看查询日志变 ...
- iptables实战案例详解-技术流ken
简介 关于iptables的介绍网上有很多的资料,大家可以自己找一些关于iptables的工作原理,以及四表五链的简介,对于学习iptables将会事半功倍.本博文将会例举几个工作中常用的iptabl ...
- cobbler批量安装系统使用详解-技术流ken
前言 cobbler是一个可以实现批量安装系统的Linux应用程序.它有别于pxe+kickstart,cobbler可以实现同个服务器批量安装不同操作系统版本. 系统环境准备及其下载cobbler ...
- 实战!基于lamp安装wordpress详解-技术流ken
简介 LAMP 是Linux Apache MySQL PHP的简写,其实就是把Apache, MySQL以及PHP安装在Linux系统上,组成一个环境来运行动态的脚本文件.现在基于lamp搭建wor ...
- KVM虚拟化使用详解--技术流ken
KVM介绍 Kernel-based Virtual Machine的简称,是一个开源的系统虚拟化模块,自Linux 2.6.20之后集成在Linux的各个主要发行版本中. KVM的虚拟化需要硬件支持 ...
- xshell连接虚拟机详解--技术流ken
xshell连接虚拟机 第一步:网络模式更改为桥接模式 第二步:重启网络 [root@ken1 ~]# systemctl restart network 第三步:获取IP地址 输入命令ip a 第四 ...
- grafana使用详解--技术流ken
grafana简介 Grafana是一个跨平台的开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知.它主要有以下六大特点: 1.展示方式:快速灵活的客户端图表,面板插件有 ...
随机推荐
- 《自拍教程51》Python_adb批量生成App版本表格
案例一:版本在软件研发阶段是很重要的, 不同的版本, 已修复的Bug也不一样, 所实现的功能不一样, Android终端产品正式版本发布前,项目经理除了确保系统版本确定无误外, 还会逐个验证所搭载的所 ...
- python使用matplotlib:subplot绘制多个子图 不规则画图
https://www.cnblogs.com/xiaoboge/p/9683056.html
- 给rm命令加保险
众所周知,脑残可以学习,但是手残没法治.相信每一位喜欢用终端操作电脑的同学都曾手误使用 rm 命令把不该删除的文件删了.然而,使用 rm 删除的文件是不会进去回收站的. 所以,最好的方法就是我们自定义 ...
- python之目录
一.python基础 python之字符串str操作方法 python之int (整型) python之bool (布尔值) python之str (字符型) python之ran ...
- js 中的yield
yield是什么 yield是ES6的新关键字,使生成器函数执行暂停,yield关键字后面的表达式的值返回给生成器的调用者.它可以被认为是一个基于生成器的版本的return关键字. yield关键字实 ...
- Windows系统向Ubuntu传输文件
PuTTY传输: 安装PuTTY,然后将PuTTY安装目录下的pscp.exe文件拷贝到/Windows/System32/目录下,在cmd控制台执行命令: # pscp 要传输的文件路径 ubunt ...
- [codevs2597]团伙<并查集>
题目描述 Description 1920年的芝加哥,出现了一群强盗.如果两个强盗遇上了,那么他们要么是朋友,要么是敌人.而且有一点是肯定的,就是: 我朋友的朋友是我的朋友: 我敌人的敌人也是我的朋友 ...
- RecyclerView 的简单使用
自从 Android 5.0 之后,google 推出了一个 RecyclerView 控件,他是 support-v7 包中的新组件,是一个强大的滑动组件,与经典的 ListView 相比,同样拥有 ...
- 运输问题中产销不平衡问题(表上作业法和LINGO方法)
对于产销不平衡问题有两种情况: 供大于求(产大于销)→增加虚拟销地 供不应求(产小于销)→增加虚拟产地 例如以下例题: 这个题中,总产量为55,总销量为60,故而我们知道这个问题属于供不应求. 1.这 ...
- C 电压
时间限制 : 10000 MS 空间限制 : - KB 评测说明 : 1s,256m 问题描述 JOI社的某个实验室中有着复杂的电路.电路由n个节点和m根细长的电阻组成.节点被标号为1~N ...