【WEB自动化】【第一节】【Xpath和CSS元素定位】
目前自动化测试开始投入WEB测试,使用RF及其selenium库,模拟对WEB页面进行操作,此过程中首先面对的问题就是对WEB页面元素的定位,几乎所有的关键字都需要传入特定的WEB页面元素,因此掌握常用的WEB元素定位方法是WEB测试人员最基本的技能。本文主要结合个人在实践中的应用,将常用的XPATH和CSS的元素定位方法进行汇总和总结,以便于引导WEB测试人员快速入门。
1. HTML基础知识
前端页面主要使用HTML进行元素排版,使用CSS进行样式设计,使用JS实现交互。在WEB测试中,熟悉HTML文档基本架构对后续的元素定位是不可或缺的。
一张图展示HTML基本架构:
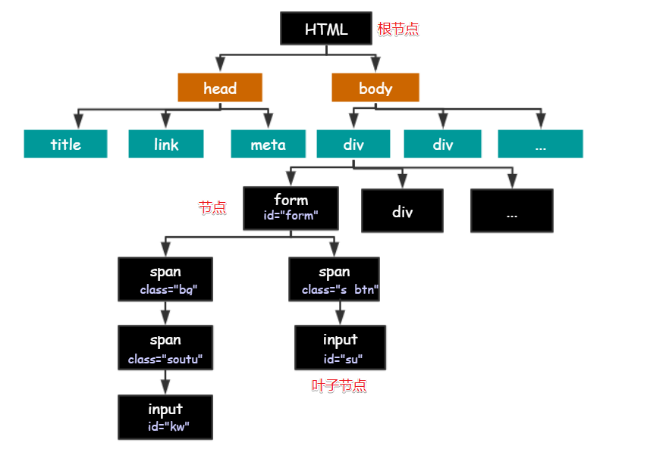
HTML 的结构就是树形结构,HTML 是根节点,所有的其他元素节点都是从根节点发出的。其他的元素都是这棵树上的节点Node,每个节点还可能有属性和文本。而路径就是指某个节点到另一个节点的路线。
节点之间存在各种关系:
- 父节点(Parent): HTML 是 body 和 head 节点的父节点;
- 子节点(Child):head 和 body 是 HTML 的子节点;
- 兄弟节点(Sibling):拥有相同的父节点,head 和 body 就是兄弟节点。title 和 div 不是兄弟,因为他们不是同一个父节点。
- 祖先节点(Ancestor):body 是 form 的祖先节点,爷爷辈及以上;
- 后代节点(Descendant):form 是 HTML 的后代节点,孙子辈及以下。
更多的HTML知识需要查阅相关资料和书籍。
2. XPATH方式进行WEB元素定位
2.1 XPATH基本定位语法
定位语法主要依赖于以下特殊符号:
|
表达式 |
说明 |
举例 |
|
/ |
从根节点开始选取 |
/html/div/span |
|
// |
从任意节点开始选取 |
//input |
|
. |
选取当前节点 |
|
|
.. |
选取当前节点的父节点 |
//input/.. 会选取 input 的父节点 |
|
@ |
选取属性,或者根据属性选取 |
//input[@data] 选取具备 data 属性的 input 元素 |
|
* |
通配符,表示任意节点或任意属性 |
2.2 绝对路径:
Xpath 中最直观的定位策略就是绝对路径。可以通过浏览器的开发者工具copy到WEB元素的绝对路径,绝对路径是从根节点/html开始往下,一层层的表示出来,直到需要的节点为止。以监控平台的WEB首页的登录按钮为例:
/html/body/div[2]/div/div[2]/form/div[5]/a[2]/span
这就是一个绝对路径。
2.3 相对路径:
除了绝对路径,Xpath 中更常用的方式是相对路径定位方法,以“//”开头。相对路径可以从任意节点开始,一般我们会选取一个可以唯一定位到的元素开始写,可以增加查找的准确性。
//a[@onclick="doLogin();return false;"]/span
2.4 元素属性定位
属性定位是通过 @ 符号指定需要使用的属性。
①根据元素是否具备某个属性查找元素://a[@onclick]
②根据属性是否等于某值查找元素://a[@onclick="doLogin();return false;"]
注意,属性值必须要加引号,单双引号都可以。
实践中最为常用的属性当属id、name、class了,且前两个属性一般作为元素的唯一标示符使用,因此通过id和name属性进行元素定位,通常表示式简单且运行速度快。
例如定位WEB首页中的用户名输入框和密码输入框,可用id进行定位:
//input[@id="loginname"]
//input[@id="loginpsw"]
2.5 层级属性结合定位
遇到某些元素无法精确定位的时候,可以查找其父级及其祖先节点,找到有确定的祖先节点后通过层级依次向下定位。
①根据层级向下找://div/a[@onclick="doLogin();return false;"]/span
②查找某元素内部的所有元素://div//a[@onclick]
第二个双斜杠,表示选取内部所有的满足条件的a,不关心层级关系。
③使用星号找不特定的元素://*[@*="doLogin();return false;"],这里会找到登录按钮。
④使用..从下往上找,根据子节点查找其父节点://span[text()="Login"]/..
注意最后的两个点,找到 span 节点的上级节点,如果还要再往上再加 /..
⑤找同级节点://span[text()="Login"]/../../a
树形结构中,兄弟节点之间的关系是通过父节点建立起来的。所以可以先找到父节点,再通过父节点找同级节点。
2.6 使用谓语定位
谓语是 Xpath 中用于描述元素位置的语句。主要有数字下标、最后一个子元素last()、元素下标函数position()。
①使用下标的方式:此处有坑,见疑难问题解决。
注意:Xpath 中的下标从 1 开始。
②查找最后一个子元素://form/div[last()]
③查找倒数第2个子元素://form/div[last()-1]
④使用 position() 函数,选取 from 下第2个 div://form/div[position()=2]
⑤使用 position() 函数,选取form下下标大于2的div://form/div[position()>2]或//form/div[position()>=3]
2.7 使用逻辑运算符
如果元素的某个属性无法精确定位到这个元素,我们还可以用逻辑运算符 and 和 or 连接多个属性进行定位,也可以用 | 连接多个路径。
①使用 and ://input[@id="loginname" and @type="text"]
②使用 or ://span[text()="Login" or text()="登录"]
③使用 | ://input[@id="loginname"] | //input[@id="loginpsw"]
2.8 使用文本定位
使用文本定位,是 Xpath 中的一大特色。在自动化测试中,为了让代码的可读性更高,可以使用文本的方式,需要用到 Xpath 中的函数 text() 或 string() ,注意是函数,所以括号不能少。
text():当前元素节点包含的文本内容,而不会包含节点元素的文本内容;
string():当前元素节点内部所有节点元素的文本内容,如有多个节点元素包含多个文本内容,则按层级顺序将各节点元素的文本内容进行拼接后返回。
例如,我们的WEB首页中,登录按钮元素周围的HTML代码如下:
|
<a href="#" onclick="doLogin();return false;" style="float: right;color: white;"> <span>Login</span> <i class="icon-circle-arrow-right"></i> </a> |
用text()方法://span[text()="Login"]能定位到按钮区域,//a[text()="Login"]则不能;
用string()方法://span[string()="Login"]和//a[string()="Login"]均能定位到按钮区域。
2.9 使用部分匹配函数
Xpath中提供了几个函数,用来进行部分匹配。
|
函数 |
说明 |
举例 |
|
contains |
选取属性或者文本包含某些字符 |
//div[contains(@id, 'data')] 选取 id 属性包含 data 的 div 元素 |
|
starts-with |
选取属性或者文本以某些字符开头 |
//div[starts-with(@id, 'data')] 选取 id 属性以 data 开头的 div 元素 |
|
ends-with |
选取属性或者文本以某些字符开头 |
//div[ends-with(@id, 'require')] 选取 id 属性以 require 结尾的 div 元素 |
其中,ends-with()仅在xpath2.0中支持,而目前RF的selenium库、chrome浏览器都只支持xpath1.0,以查找WEB首页的密码输入框元素(包含id为"loginpsw")为例:
//*[contains(@id, "loginpsw")] 能匹配到
//*[starts-with(@id, "loginpsw")] 能匹配到
//*[ends-with(@id, "loginpsw")] 不能匹配到
//*[substring(@id, string-length(@id) - string-length('loginpsw') +1) = 'loginpsw'] 能匹配到,实现了ends-with功能
2.10 实践中疑难问题解决:
①通过Xpath查找某个节点下某一级下的子节点,而不关注具体层级:
//div[@id="hisevent"]//button[@id="event_searchBT"] 查找指定div下任一子级的特定button(使用//)
②通过Xpath如何获取文档中第几个匹配节点://name[3]表示所有位置3的name,(//name)[3]才是你要的,所有name的第3个。
(//div[@id="hisevent"]//input)[2]
//div[@id="hisevent"]//input[position()=2]
需要在所有匹配中定位时,先用()括起来,或使用postion()函数。
③通过xpath由子节点元素查找父节点元素或祖先节点:
//a[span[text()="Login"]]
//div[@id="hisevent"]//table[tbody[contains(@id, "list")]]
参考:https://www.jianshu.com/p/6a0dbb4e246a
https://www.cnblogs.com/hanmk/p/8997786.html
3. CSS方式进行WEB元素定位
3.1 CSS选择器基础知识
CSS选择器分4大类:基本选择器、属性选择器、伪类选择器、伪元素选择器。
注意:选择器总是从左至右解析,不要私自添加()优先运算。
其中基本选择器主要包括以下四类符号:
1) 标签选择器:使用标签名称进行标识,如div、a、p等;
2) ID选择器:使用#进行标识;
3) 类选择器:使用.进行标识;
4) 通配符选择器:使用*进行标识。
其余属性选择器、伪类选择器、伪元素选择器都可归为扩展选择器。
|
选择器 |
例子 |
例子描述 |
CSS版本 |
选择器分类 |
|
.intro |
选择 class="intro" 的所有元素。 |
1 |
基本选择器 |
|
|
#firstname |
选择 id="firstname" 的所有元素。 |
1 |
基本选择器 |
|
|
* |
选择所有元素。 |
2 |
基本选择器 |
|
|
p |
选择所有 <p> 元素。 |
1 |
基本选择器 |
|
|
div,p |
选择所有 <div> 元素和所有 <p> 元素。 |
1 |
基本选择器 |
|
|
div p |
选择 <div> 元素内部的所有 <p> 元素。 |
1 |
基本选择器 |
|
|
div>p |
选择父元素为 <div> 元素的所有 <p> 元素。 |
2 |
基本选择器 |
|
|
div+p |
选择紧接在 <div> 元素之后的所有 <p> 元素。 |
2 |
基本选择器 |
|
|
[target] |
选择带有 target 属性所有元素。 |
2 |
属性选择器 |
|
|
[target=_blank] |
选择 target="_blank" 的所有元素。 |
2 |
属性选择器 |
|
|
[title~=flower] |
选择 title 属性包含单词 "flower" 的所有元素。 |
2 |
属性选择器 |
|
|
[lang|=en] |
选择 lang 属性值以 "en" 开头的所有元素。 |
2 |
属性选择器 |
|
|
a:link |
选择所有未被访问的链接。 |
1 |
伪类选择器 |
|
|
a:visited |
选择所有已被访问的链接。 |
1 |
伪类选择器 |
|
|
a:active |
选择活动链接。 |
1 |
伪类选择器 |
|
|
a:hover |
选择鼠标指针位于其上的链接。 |
1 |
伪类选择器 |
|
|
input:focus |
选择获得焦点的 input 元素。 |
2 |
伪类选择器 |
|
|
p:first-letter |
选择每个 <p> 元素的首字母。 |
1 |
伪元素选择器 |
|
|
p:first-line |
选择每个 <p> 元素的首行。 |
1 |
伪元素选择器 |
|
|
p:first-child |
选择属于父元素的第一个子元素的每个 <p> 元素。 |
2 |
伪元素选择器 |
|
|
p:before |
在每个 <p> 元素的内容之前插入内容。 |
2 |
伪元素选择器 |
|
|
p:after |
在每个 <p> 元素的内容之后插入内容。 |
2 |
伪元素选择器 |
|
|
p:lang(it) |
选择带有以 "it" 开头的 lang 属性值的每个 <p> 元素。 |
2 |
伪元素选择器 |
|
|
p~ul |
选择前面有 <p> 元素的每个 <ul> 元素。 |
3 |
基本选择器 |
|
|
a[src^="https"] |
选择其 src 属性值以 "https" 开头的每个 <a> 元素。 |
3 |
属性选择器 |
|
|
a[src$=".pdf"] |
选择其 src 属性以 ".pdf" 结尾的所有 <a> 元素。 |
3 |
属性选择器 |
|
|
a[src*="abc"] |
选择其 src 属性中包含 "abc" 子串的每个 <a> 元素。 |
3 |
属性选择器 |
|
|
p:first-of-type |
选择属于其父元素的首个 <p> 元素的每个 <p> 元素。 |
3 |
伪元素选择器 |
|
|
p:last-of-type |
选择属于其父元素的最后 <p> 元素的每个 <p> 元素。 |
3 |
伪元素选择器 |
|
|
p:only-of-type |
选择属于其父元素唯一的 <p> 元素的每个 <p> 元素。 |
3 |
伪元素选择器 |
|
|
p:only-child |
选择属于其父元素的唯一子元素的每个 <p> 元素。 |
3 |
伪元素选择器 |
|
|
p:nth-child(2) |
选择属于其父元素的第二个子元素的每个 <p> 元素。 |
3 |
伪元素选择器 |
|
|
p:nth-last-child(2) |
同上,从最后一个子元素开始计数。 |
3 |
伪元素选择器 |
|
|
p:nth-of-type(2) |
选择属于其父元素第二个 <p> 元素的每个 <p> 元素。 |
3 |
伪元素选择器 |
|
|
p:nth-last-of-type(2) |
同上,但是从最后一个子元素开始计数。 |
3 |
伪元素选择器 |
|
|
p:last-child |
选择属于其父元素最后一个子元素每个 <p> 元素。 |
3 |
伪元素选择器 |
|
|
:root |
选择文档的根元素。 |
3 |
伪类选择器 |
|
|
p:empty |
选择没有子元素的每个 <p> 元素(包括文本节点)。 |
3 |
伪类选择器 |
|
|
#news:target |
选择当前活动的 #news 元素。 |
3 |
伪类选择器 |
|
|
input:enabled |
选择每个启用的 <input> 元素。 |
3 |
伪类选择器 |
|
|
input:disabled |
选择每个禁用的 <input> 元素 |
3 |
伪类选择器 |
|
|
input:checked |
选择每个被选中的 <input> 元素。 |
3 |
伪类选择器 |
|
|
:not(p) |
选择非 <p> 元素的每个元素。 |
3 |
伪类选择器 |
|
|
::selection |
选择被用户选取的元素部分。 |
3 |
伪类选择器 |
参考:https://www.w3school.com.cn/cssref/css_selectors.ASP
https://blog.csdn.net/luanpeng825485697/article/details/76935715
https://blog.csdn.net/DYD850804/article/details/80997251
3.2 CSS选择器实战
下面以WEB的历史操作记录页面为例进行实践。
直接给出查找此页面中结束时间选框的定位语句,再进行分析:
div#hisevent input.form-control.input-medium[type="text"][onfocus*="WdatePicker"]:nth-child(2)
(可在文本编辑器放大查看)
①先从任意div标签的元素出发查找,直到其具备id属性(#)值为hisevent;
②查找①的div元素内部的input标签元素,使用空格进行隔离。此处需要注意,关于标签层级,CSS有两个最基本的查找语法:ele1>ele2和ele1 ele2,类似于Xpath的/和//,前者代表ele1和ele2为父子节点关系,后者代表ele1内部包含ele2,而不在乎具体层级;
③查找的input元素须包含值为"form-control input-medium"的类(class)属性,使用圆点进行标识。这里注意,该元素的class的值中包含一个空格,在选择器表达式里,空格已经有了具体含义;在书写包含空格的class属性时,直接将空格替换为圆点即可。事实上class属性值中的空格表示此元素能匹配多个class样式表,即样式复用,同时具有先后关系。参考:
https://blog.csdn.net/liuhehe123/article/details/81608225
https://www.cnblogs.com/guxin/p/css-multi-class-selector.html
④在找到包含指定类的input标签元素后,进一步通过属性进行筛选,最基础的表达式为[name=value],实践中发现value用不用引号包围均可;如果想通过多个属性(“与”的关系)来精确定位元素,可以直接连接多个属性表达式,如[type="text"][onfocus*="WdatePicker"]。参考:
https://cloud.tencent.com/developer/ask/27977
⑤通过以上一番操作,定位到的元素仍然有两个,分别是起始时间框和结束时间框,二者位于同一级,是兄弟节点关系,要定位到第二个节点,使用:nth-child(2)即可,其原意为归属于父节点的第n个子节点。对同级节点定位方法参考:
https://blog.csdn.net/hcwbr123/article/details/80846862
3.3 实践中疑难问题解决:
①属性选择器部分匹配:~= 、|= 、*= 、^= 、$= 的区别:
~= 、|= 按完整单词进行匹配,完整单词指整个的单词、以空格或-分隔的单词;
*= 、^= 、$= 按字符串进行匹配,显然此类方法更易用且更常用。举例
div#hisevent button[onclick^='do'][onclick$='()'][onclick*='Eventsearch']
此句意为:包含属性onclick的值以do开头、以()结尾、含Eventsearch子串的button。
②通过ele1,ele2可以“或”方式获取多个元素,如何以“或”方式进行多个属性的模糊匹配?如在①中,想以“或”方式匹配多个属性语句?
③通过元素文本定位元素:此路不通!Content selectors were deprecated! No more content selectors since CSS3. :contains() was dropped.
④通过子元素找父元素:目前似乎还不支持!有一个CSS伪类 :has() 支持这个功能,但还处于草案阶段。
4. 实践验证
验证Xpath和CSS元素定位语句,可使用浏览器的开发者工具辅助:
①在开发者工具的Elements中按Ctrl + F,在搜索框中输入Xpath或CSS语句;
②在开发者工具的Console中使用 $x()和$(),$x()传入Xpath语句,$()传入CSS语句,注意,元素定位(或称查找、选择器)语句需要使用单引号或双引号包围。
【WEB自动化】【第一节】【Xpath和CSS元素定位】的更多相关文章
- Selenium自动化-CSS元素定位
接下来,开始讲解 CSS元素定位. CSS定位速度快,功能多,但是不能向上查找,比 xpath好用,是本人认为最好用的定位方式 大致用法总结: 具体使用仿上篇博客.http://www.cnblo ...
- 复习-css元素定位
css元素定位 <style type="text/css"> body{ margin: 15px; font-family: "Adobe 宋体 Std ...
- Web自动化基础(一)使用Selenium定位元素
什么是元素?我们知道网页上有什么内容显示出来,比如一个按钮,一个输入框,一张图片,都可以理解成元素,这些元素是由html代码构成的,比如图片可以用<img>标签来展示,一个输入框可以用&l ...
- selenium用css、xpath表达式进行元素定位
绝对路径选择 从根节点开始的,到某个节点,每层都依次写下来,每层之间用 / 分隔的表达式,就是某元素的 绝对路径 Xpath : /html/body/div CSS : html>body&g ...
- CSS元素定位6-10课
<精通CSS.DIV网页样式与布局>视频6-10课总结图: 元素定位 (1)float:left/right; 左浮动:脱离普通文档流向左浮动(即向左对齐):float属性必须应用在块级元 ...
- Selenium2学习-009-WebUI自动化实战实例-007-Selenium 8种元素定位实战实例源代码(百度首页搜索录入框及登录链接)
此 文主要讲述用 Java 编写 Selenium 自动化测试脚本编写过程中,通过 ID.name.xpath.cssSelector.linkText.className.partialLinkTe ...
- CSS元素定位
使用 CSS 选择器定位元素 CSS可以通过元素的id.class.标签(input)这三个常规属性直接定位到,而这三种编写方式,在HTML中编写style的时候,可以进行标识如: #su ...
- Appium自动化(10) - appium高级元素定位方式之 UI Automator API 的详解
如果你还想从头学起Appium,可以看看这个系列的文章哦! https://www.cnblogs.com/poloyy/category/1693896.html 前言 前面介绍过根据id,clas ...
- css元素定位样式
曾经写网页,学css整体上不难,但就是元素定位,始终一知半解,直到今天,本着实践出真知的理念,经过认真测试,总结出了如下结论. css 定位: positionstatic : 默认静止定位,元素在正 ...
随机推荐
- 白话理解https
为什么需要加密? 因为http的内容是明文传输的,传输过程有可能被劫持或被篡改(中间人攻击),如何解决? 当然是加密.最简单的方式就是对称加密(快). 对称机密 就是一个密钥,可以理解为一把钥匙,我们 ...
- Jenkins(3)- 安装Jenkins过程中遇到问题的排查思路
如果想从头学起Jenkins的话,可以看看这一系列的文章哦 https://www.cnblogs.com/poloyy/category/1645399.html 安装Jenkins过程中,可能会遇 ...
- Python学习16之input函数
'''''''''Input函数:作用:接受一个标准输入数据返回值:返回为 string 类型使用:input()'''a=input("请输入一个整数")print(a)prin ...
- python学习09元组
'''元组''''''元组Tuple:1.不可变的序列:元祖不能对元素进行变动(字符串也不可以,但是列表可以) 2.元组用小括号()表示(列表是中括号[],字符串是“”) 3.可以存储各种数据类型 4 ...
- Linux磁盘修复命令----fsck
使用fsck命令修复磁盘时 一定要进入单用户模式去修复 语 法fsck.ext4[必要参数][选择参数][设备代号] 功 能fsck.ext4 命令: 针对ext4型文件系统进行检测 参数 -a 非 ...
- QML-密码管理器
Intro 年初刚学Qml时写的密码管理器.用到Socket通信.AES加密等.UI采用Material Design,并实现了Android App的一些常见基本功能,如下拉刷新.弹出提示.再按一次 ...
- Linux系统目录结构:目录层次标准、常用目录和文件
1. 目录层次标准FHS FHS(Filesystem Hierarchy Standard)目录层次标准,是Linux的目录规范标准. FHS定义了两层规范: 第一层:是"/" ...
- Android Studio SVN配置忽略文件
1.用Android Studio创建一个项目,会在根目录和Module目录下自动生成.gitignore文件,貌似是Git的配置文件,和SVN没有关系. 2.打开Setting-Version Co ...
- 墨仓式进入2.0时代?爱普生商用墨仓式L4158试用
提起"墨仓式"打印机,相信现在已经没有人需要过多的解释,墨仓式打印机在打印市场占有率不断提高就是最佳佐证.为什么用户对于墨仓式这么认可,想必是墨仓式真正洞悉了他们的需求,解决了打印 ...
- 数学--数论--HDU 2802 F(N) 公式推导或矩阵快速幂
Giving the N, can you tell me the answer of F(N)? Input Each test case contains a single integer N(1 ...