Java并发编程:线程池ThreadPoolExecutor
多线程的程序的确能发挥多核处理器的性能。虽然与进程相比,线程轻量化了很多,但是其创建和关闭同样需要花费时间。而且线程多了以后,也会抢占内存资源。如果不对线程加以管理的话,是一个非常大的隐患。而线程池的目的就是管理线程。当你需要一个线程时,你就可以拿一个空闲线程去执行任务,当任务执行完后,线程又会归还到线程池。这样就有效的避免了重复创建、关闭线程和线程数量过多带来的问题。
Java并发包提供的线程池
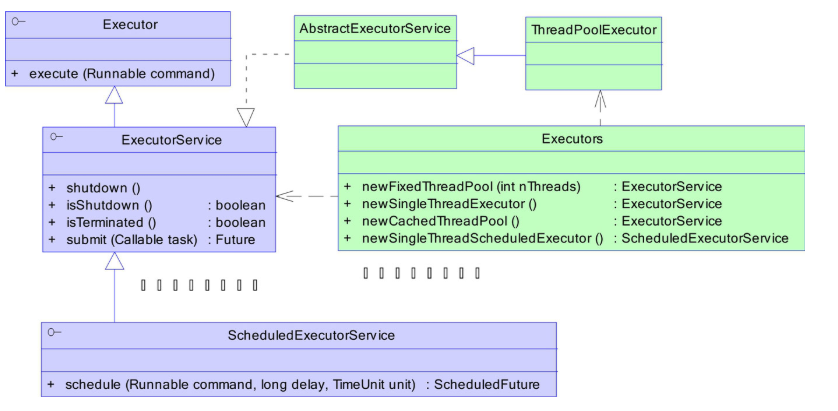
注:摘自《实战Java高并发程序设计》
如图是Java并发包下提供的线程池功能。其中ExecutorService接口提供一些操作线程池的方法。而Executors相当于一个线程池工厂类,它里面有几种现成的具备某种特定功能的线程池工厂方法。看到这些应该不陌生,举个我们平时最常使用的例子:
//创建一个大小为10的固定线程池
ExecutorService threadpool= Executors.newScheduledThreadPool(10);
下面简单介绍一下这些工厂方法:
newFixedThreadPool()方法:固定线程数量线程池。传入的数字就是线程的数量,如果有空闲线程就去执行任务,如果没有空闲线程就会把任务放到一个任务队列,等到有线程空闲时便去处理队列中的任务。
newSingleThreadExecutor()方法:只有一个线程的线程池。同样,超出的任务会被放到任务队列,等这个线程空闲时就会去按顺序处理。
newCachedThreadPool()方法:可以根据实际情况拓展的线程池。当没有空闲线程去执行新任务时,就会再创建新的线程去执行任务,执行完后新建的线程也会返回线程池进行复用。
newSingleThreadScheduledExecutor()方法:返回的是ScheduledExecutorService对象。ScheduledExecutorService是继承于ExecutorService的,有一些拓展方法,如指定执行时间。这个线程池大小为1,在指定时间执行任务。关于指定时间的几个方法:schedule()是在指定时间后执行一次任务。scheduleAtFixedRate()和方法scheduleWithFixedDelay()方法,两者都是周期性的执行任务,但是前者是以上一次任务开始为周期起点,后者是以上一次任务结束为周期起点。具体的参数大家可以在IDE里面查看。
newScheduledThreadPool()方法:和上面一个方法一样,但是可以指定线程池大小,其实上面那个方法也是调用这个方法的,只是传入的参数是1。
线程池核心类
上面简单的对Java并发包下线程池的结构和API进行简单的介绍,下面开始深入了解一下线程池。如果大家在IDE上追踪一下上面几个工厂方法就会发现,其中最后都会调用一个方法,通过上图其实也可以发现。那就是ThreadPoolExecutor的构造方法,工厂方法只是帮我们传入不同的参数,从而实现不同的效果,所以如果你想更自由的控制自己的线程池,推荐直接使用ThreadPoolExecutor创建线程池。下面给出这个构造函数的参数列表:
public ThreadPoolExecutor(int corePoolSize,
int maximumPoolSize,
long keepAliveTime,
TimeUnit unit,
BlockingQueue<Runnable> workQueue,
ThreadFactory threadFactory,
RejectedExecutionHandler handler)
参数从上到下,作用依次为:
1.指定线程池种线程的数量。
2.线程池种最大的线程数量,也就是最大能拓展到多少。
3.当线程数量超过corePoolSize,多余的空闲线程多久会被销毁。
4.keepAliveTime的单位。
5.任务队列,当空闲线程不够,也不能再新建线程时,新提交的任务就会被放到任务队列种。
6.线程工厂,用于创建线程,默认的即可。
7.拒绝策略。当任务太多,达到最大线程数量、任务队列也满了,该如何拒绝新提交的任务。
任务队列
任务队列是一个BlockingQueue接口,在ThreadPoolExecutor一共有如下几种实现类实现了BlockingQueue接口。
SynchronousQueue:直接提交队列。这种队列其实不会真正的去保存任务,每提交一个任务就直接让空闲线程执行,如果没有空闲线程就去新建,当达到最大线程数时,就会执行拒绝策略。所以使用这种任务队列时,一般会设置很大的maximumPoolSize,不然很容易就执行了拒绝策略。newCachedThreadPool线程池的corePoolSize为0,maximumPoolSize无限大,它用的就是直接提交队列。
ArrayBlockingQueue:有界任务队列,其构造函数必须带一个容量参数,表示任务队列的大小。当线程数量小于corePoolSize时,有任务进来优先创建线程。当线程数等于corePoolSize时,新任务就会进入任务队列,当任务队列满了,才会创建新线程,线程数达到maximumPoolSize时执行拒绝策略。
LinkedBlockingQueue:无界任务队列,通过它的名字也应该知道了,它是个链表,除非没有空间了,不然不会出现任务队列满了的情况,但是非常耗费系统资源。和有界任务队列一样,线程数若小于corePoolSize,新任务进来时没有空闲线程的话就会创建新线程,当达到corePoolSize时,就会进入任务队列。会发现没有maximumPoolSize什么事,newFixedThreadPool固定大小线程池就是用的这个任务队列,它的corePoolSize和maximumPoolSize相等。
PriorityBlockingQueue:优先任务队列,它是一个特殊的无界队列,因为它总能保证高优先级的任务先执行。
拒绝策略
JDK提供了四种拒绝策略。
AbortPolicy:直接抛出异常,阻止系统正常工作。
CallerRunsPolicy:如果线程池未关闭,则在调用者线程里面执行被丢弃的任务,这个策略不是真正的拒绝任务。比如我们在T1线程中提交的任务,那么该拒绝策略就会把多余的任务放到T1线程执行,会影响到提交者线程的性能。
DiscardOldestPolicy:该策略会丢弃一个最老的任务,也就是即将被执行的任务,然后再次尝试提交该任务。
DiscardPolicy:直接丢弃多余的任务,不做任何处理,如果允许丢弃任务,这个策略是最好的。
以上内置的拒绝策略都实现了RejectedExecutionHandler接口,所以上面的拒绝策略无法满足你的要求,可以自定义一个:继承RejectedExecutionHandler并实现rejectedExecution方法。
线程工厂
线程池中的线程是由ThreadFactory负责创建的,一般情况下默认就行,如果有一些其他的需求,比如自定义线程的名称、优先级等,我们也可以利用ThreadFactory接口来自定义自己的线程工厂:继承ThreadFactory并实现newThread方法。
线程池的拓展
在ThreadPoolExecutor中有三个扩展方法:分别会在任务执行前beforeExecute、执行完成afterExecute、线程池退出时执行terminated。
这几个方法在哪调用的?在ThreadPoolExecutor中有一个内部类:Worker,每个线程的任务其实都是由这个类里面的run方法执行的,贴一下这个类的源码:
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L; /** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks;
//....省略 /** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this);
}
//....省略
}
接着进入这个runWorker方法:
final void runWorker(Worker w) {
//...省略
try {
//任务执行前
beforeExecute(wt, task);
Throwable thrown = null;
try {
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
//任务执行完
afterExecute(task, thrown);
}
}
//....省略
}
还有一个线程池退出时执行的方法是在何处执行的?这个方法被调用的地方就不止一处了,像线程池的shutdown方法就会调用
public void shutdown() {
//....省略。这个方法里面就会调用terminated
tryTerminate();
}
ThreadPoolExecutor中这三个方法默认是没有任何内容的,所以我们要自定义它也很简单,直接重写它们就行了:
ExecutorService threadpool= new ThreadPoolExecutor(5,5,0L,TimeUnit.SECONDS,new LinkedBlockingDeque<>()){
@Override
protected void beforeExecute(Thread t, Runnable r) {
//执行任务前
}
@Override
protected void afterExecute(Runnable r, Throwable t) {
//执行任务后
}
@Override
protected void terminated() {
//线程退出
}
};
Java并发编程:线程池ThreadPoolExecutor的更多相关文章
- Java 并发编程 | 线程池详解
原文: https://chenmingyu.top/concurrent-threadpool/ 线程池 线程池用来处理异步任务或者并发执行的任务 优点: 重复利用已创建的线程,减少创建和销毁线程造 ...
- Java并发编程——线程池的使用
在前面的文章中,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统 ...
- Java并发编程——线程池
本文的目录大纲: 一.Java中的ThreadPoolExecutor类 二.深入剖析线程池实现原理 三.使用示例 四.如何合理配置线程池的大小 一.Java中的ThreadPoolExecutor类 ...
- Java并发编程--线程池
1.ThreadPoolExecutor类 java.uitl.concurrent.ThreadPoolExecutor类是线程池中最核心的一个类,下面我们来看一下ThreadPoolExecuto ...
- java并发编程-线程池的使用
参考文章:http://www.cnblogs.com/dolphin0520/p/3932921.html 深入剖析线程池实现原理 将从下面几个方面讲解: 1.线程池状态 2.任务的执行 3.线程池 ...
- JAVA 并发编程-线程池(七)
线程池的作用: 线程池作用就是限制系统中运行线程的数量. 依据系统的环境情况.能够自己主动或手动设置线程数量,达到运行的最佳效果:少了浪费了系统资源,多了造成系统拥挤效率不高.用线程池控制线程数量,其 ...
- Java编发编程 - 线程池的认识(一)
每逢面试都会询问道线程池的概念和使用,但是工作中真正的又有多少场景使用呢?相信大家都会有这样的疑问:面试选拔造汽车,实际进公司就是拧螺丝!但是真正要把这颗螺丝拧紧,拧牢,没有这些最底层的知识做铺垫你可 ...
- java并发编程 线程基础
java并发编程 线程基础 1. java中的多线程 java是天生多线程的,可以通过启动一个main方法,查看main方法启动的同时有多少线程同时启动 public class OnlyMain { ...
- Java高性能并发编程——线程池
在通常情况下,我们使用线程的时候就去创建一个线程,这样实现起来非常简便,但是就会有一个问题: 如果并发的线程数量很多,并且每个线程都是执行一个时间很短的任务就结束了,这样频繁创建线程就会大大降低系统的 ...
- 《java学习三》并发编程 -------线程池原理剖析
阻塞队列与非阻塞队 阻塞队列与普通队列的区别在于,当队列是空的时,从队列中获取元素的操作将会被阻塞,或者当队列是满时,往队列里添加元素的操作会被阻塞.试图从空的阻塞队列中获取元素的线程将会被阻塞,直到 ...
随机推荐
- wx.request出现400 bad request的问题
wx.request({ url: 'test.php', //仅为示例,并非真实的接口地址 data: { x: '' , y: '' }, header: { 'content-type': 'a ...
- wait,waitpid的学习使用
man wait man waitpid 从中可知 函数原型 pid_t wait(int* status); pid_t waitpid(pid_t pid, int* status, int op ...
- [Windows] Socket Server Failed to bind, error 10048
Address already in use. Typically, only one usage of each socket address (protocol/IP address/port) ...
- Python不同版本打包程序为.exe文件
安装pyinstaller 测试用的python环境是3.6.2版本 下载地址 https://github.com/pyinstaller/pyinstaller/ 1.打开cmd,切到pyinst ...
- scala教程之:可见性规则
文章目录 public Protected private scoped private 和 scoped protected 和java很类似,scala也有自己的可见性规则,不同的是scala只有 ...
- javaScript常用到的方法
判断一个对象是否为空对象,不为null,仅仅是{};可以使用如下方法判断: if (JSON.stringify(object) === '{}') { //.. } //也可以 if (Object ...
- Math.Round和四舍五入
Math.Round方法并不是像想象中的四舍五入, 可以从下面的输出结果看出来: Math.Round(3.44, 1); //Returns 3.4. Math.Round(3.45, 1); // ...
- 网课应该这么刷(油猴Tampermonkey脚本自动刷课)
懒人福利 首先有些人不想学怎么用脚本,满足你们,压缩包解压之后直接登录即可.戳我下载 脚本已经集成好了,登录即可刷课.章节测试还会自动答题呦,正确率高达97%呦. 油猴及脚本安装 油猴的脚本不知可以刷 ...
- 数学--数论--Miller_Rabin判断素数
ACM常用模板合集 #include<iostream> #include<algorithm> #include<cstring> #include<cst ...
- Docker docker-compose 配置lnmp开发环境
1.安装docker yum -y install dockersystemctl start dockersystemctl enable docker 安装docker-compose https ...