mysql大表在不停机的情况下增加字段该怎么处理
MySQL中给一张千万甚至更大量级的表添加字段一直是比较头疼的问题,遇到此情况通常该如果处理?本文通过常见的三种场景进行案例说明。
1、 环境准备
数据库版本: 5.7.25-28(Percona 分支)
服务器配置: 3台centos 7虚拟机,配置均为2CPU 2G内存
数据库架构: 1主2从的MHA架构(为了方便主从切换场景的演示,如开启GTID,则两节点即可),关于MHA搭建可参考此文 MySQL高可用之MHA集群部署
准备测试表: 创建一张2kw记录的表,快速创建的方法可以参考快速创建连续数
本次对存储过程稍作修改,多添加几个字段,存储过程如下:
DELIMITER $$
CREATE PROCEDURE `sp_createNum`(cnt INT )
BEGIN
DECLARE i INT DEFAULT 1;
DROP TABLE if exists tb_add_columns;
CREATE TABLE if not exists tb_add_columns(id int primary key,col1 int,col2 varchar(32));
INSERT INTO tb_add_columns(id,col1,col2) SELECT i as id ,i%7 as col1,md5(i) as col2; WHILE i < cnt DO
BEGIN
INSERT INTO tb_add_columns(id,col1,col2) SELECT id + i as id ,( id + i) %7 as col1,md5( id + i) as col2 FROM tb_add_columns WHERE id <=cnt - i ;
SET i = i*2;
END;
END WHILE;
END$$
DELIMITER ;
调用存储过程,完成测试表及测试数据的创建。
mysql> call sp_createNum(20000000);
2. 直接添加字段
使用场景: 在系统不繁忙或者该表访问不多的情况下,如符合ONLINE DDL的情况下,可以直接添加。
模拟场景: 创建一个测试脚本,每10s访问该表随机一条记录,然后给该表添加字段
访问脚本如下:
#!/bin/bash
# gjc for i in {..} # 访问次数1000000000,按需调整即可
do
id=$RANDOM #生成随机数
mysql -uroot -p'' --socket=/data/mysql3306/tmp/mysql.sock -e "select a.*,now() from testdb.tb_add_columns a where id = "$id # 访问数据
sleep # 暂停10s
done
运行脚本
sh test.sh
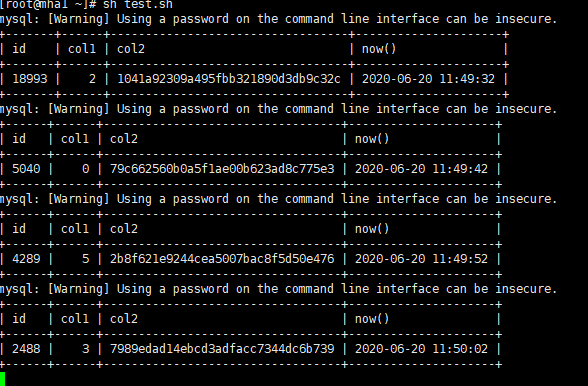
给表添加字段
mysql> alter table testdb.tb_add_columns add col3 int;

此时,访问正常。
附ONLINE DDL的场景如下,建议DBA们必须弄清楚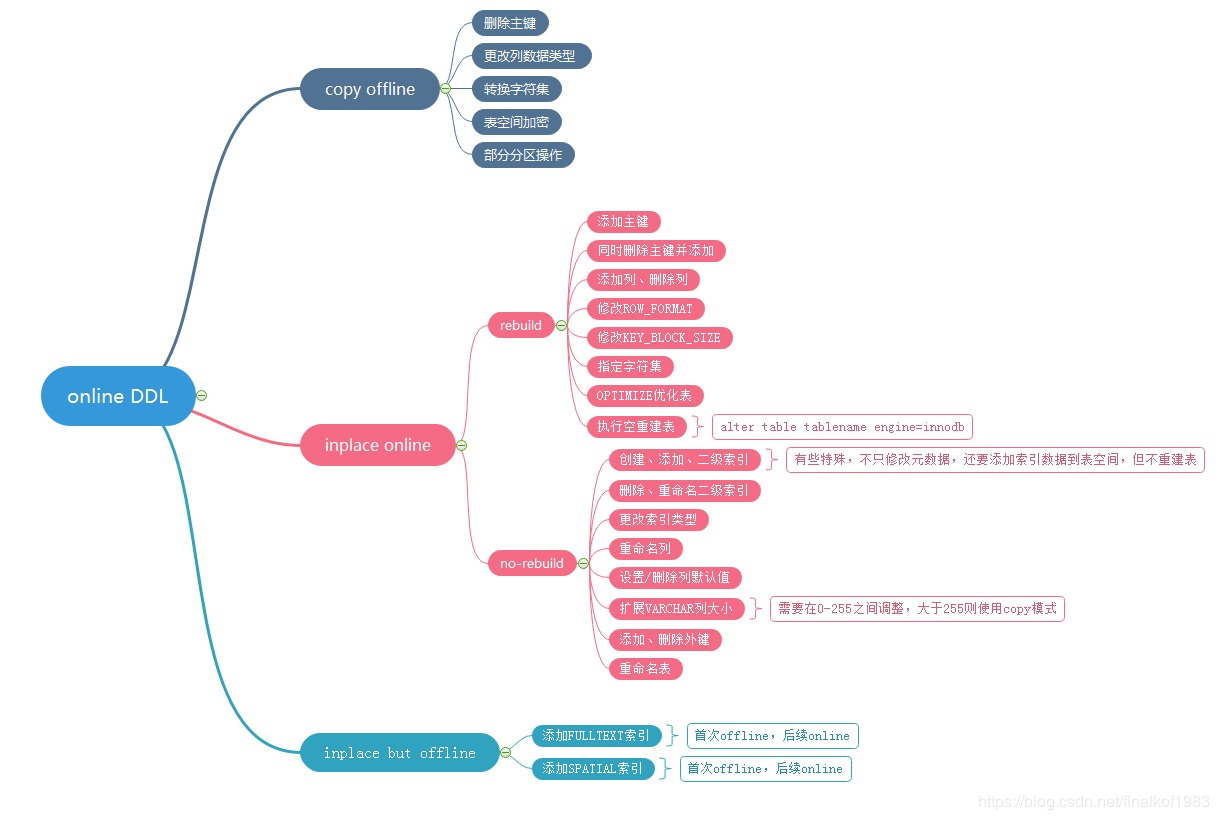
(图片转载于https://blog.csdn.net/finalkof1983/article/details/88355314)
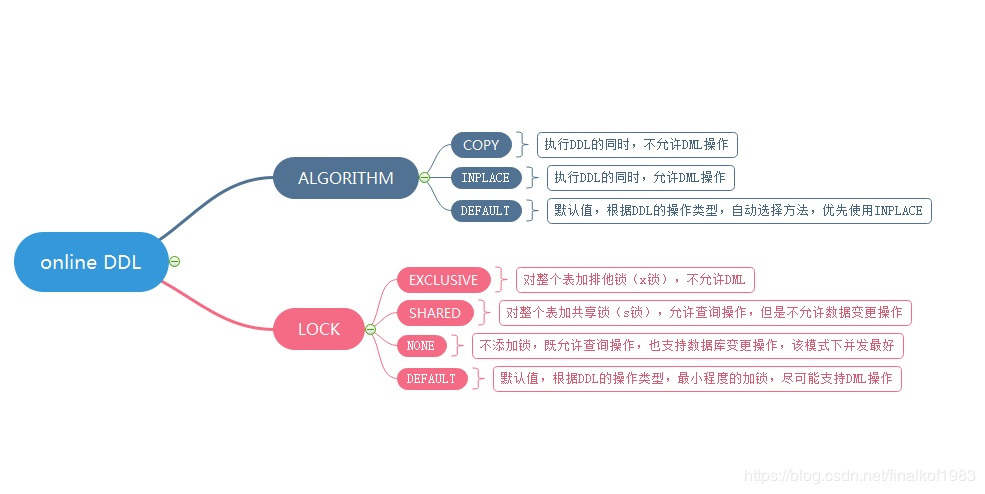
(图片转载于https://blog.csdn.net/finalkof1983/article/details/88355314)
3. 使用工具在线添加
虽然Online DDL添加字段时,表依旧可以读写,但是生产环境使用场景中对大表操作使用最多的还是使用工具pt-osc或gh-ost添加。
本文主要介绍 pt-osc(pt-online-schema-change) 来添加字段,该命令是Percona Toolkit工具中的使用频率最高的一种
关于Percona Toolkit的安装及主要使用可以参考 五分钟学会Percona Toolkit 安装及使用
添加字段
root@mha1 ~]# pt-online-schema-change --alter "ADD COLUMN col4 int" h=localhost,P=,p=,u=root,D=testdb,t=tb_add_columns,S=/data/mysql3306/tmp/mysql.sock --charset=utf8mb4 --execute
主要过程如下:
> Cannot connect to A=utf8mb4,P=,S=/data/mysql3306/tmp/mysql.sock,h=192.168.28.132,p=...,u=root
> Cannot connect to A=utf8mb4,P=,S=/data/mysql3306/tmp/mysql.sock,h=192.168.28.131,p=...,u=root
No slaves found. See --recursion-method if host mha1 has slaves. # 因为使用的是socket方式连接数据库 且未配置root远程连接账号,所以会有此提示 # A software update is available:
Operation, tries, wait:
analyze_table, , 1
copy_rows, , 0.25
create_triggers, , 1
drop_triggers, ,
swap_tables, ,
update_foreign_keys, ,
Altering `testdb`.`tb_add_columns`...
Creating new table... # 创建中间表,表名为"_原表名_new"
Created new table testdb._tb_add_columns_new OK.
Altering new table... # 修改表,也就是在新表上添加字段,因新表无数据,因此很快加完
Altered `testdb`.`_tb_add_columns_new` OK.
--20T12:: Creating triggers... # 创建触发器,用于在原表拷贝到新表的过程中原表有数据的变动(新增、修改、删除)时,也会自动同步至新表中
--20T12:: Created triggers OK.
--20T12:: Copying approximately rows... # 拷贝数据,数据库量是统计信息里的,不准确
Copying `testdb`.`tb_add_columns`: % : remain # 分批拷贝数据(根据表的size切分每批拷贝多少数据),拷贝过程中可以用show processlist看到对应的sql
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
Copying `testdb`.`tb_add_columns`: % : remain
--20T12:: Copied rows OK. # 拷贝数据完成
--20T12:: Analyzing new table... # 优化新表
--20T12:: Swapping tables... # 交换表名,将原表改为"_原表名_old",然后把新表表名改为原表名
--20T12:: Swapped original and new tables OK.
--20T12:: Dropping old table... # 删除旧表(也可以添加参数不删除旧表)
--20T12:: Dropped old table `testdb`.`_tb_add_columns_old` OK.
--20T12:: Dropping triggers... # 删除触发器
--20T12:: Dropped triggers OK.
Successfully altered `testdb`.`tb_add_columns`. # 完成
修改过程中,读写均不受影响,大家可以写个程序包含读写的
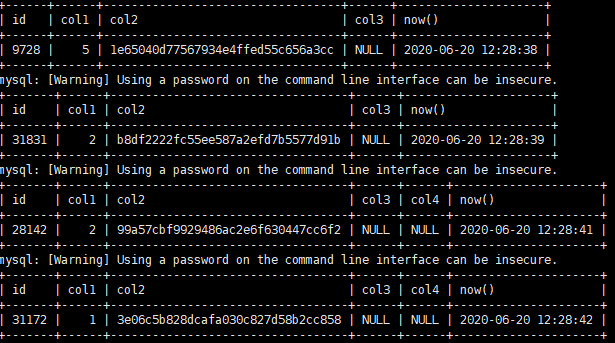
注: 无论是直接添加字段还是用pt-osc添加字段,首先都得拿到该表的元数据锁,然后才能添加(包括pt-osc在创建触发器和最后交换表名时都涉及),因此,如果一张表是热表,读写特别频繁或者添加时被其他会话占用,则无法添加。
例如: 锁住一条记录
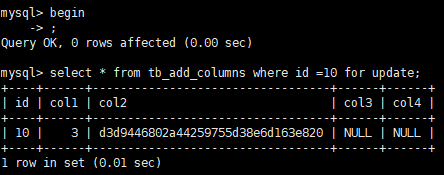
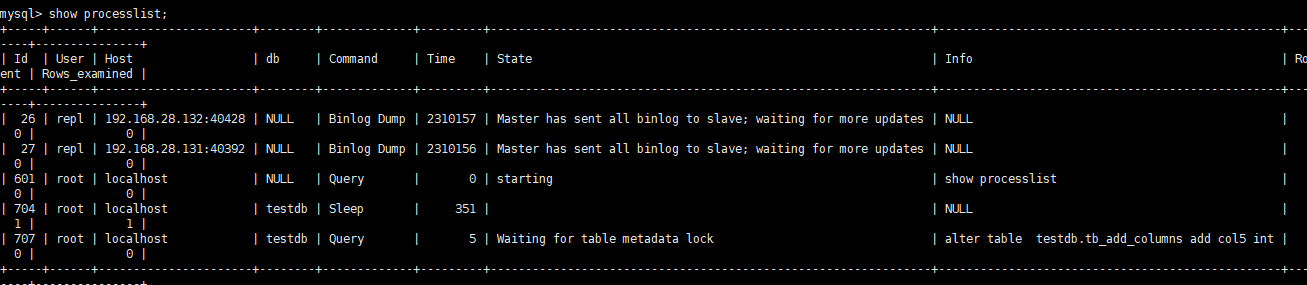
用pt-osc添加字段,会发现一直卡在创建触发器那一步

此时查看对应的SQL正在等待获取元数据锁
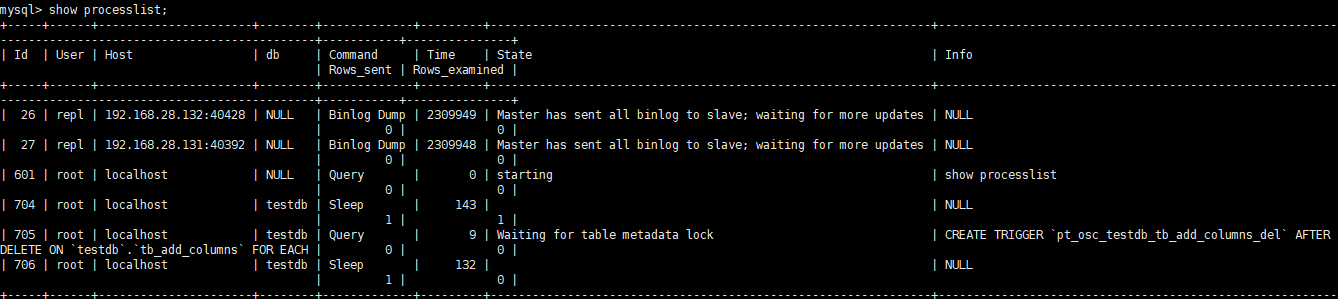
换成直接添加也一样,例如
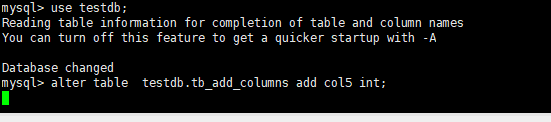
当达到锁等待后将会报错放弃添加字段
mysql> alter table testdb.tb_add_columns add col5 int;
ERROR 1205 (HY000): Lock wait timeout exceeded; try restarting transaction
对于此情况,需等待系统不繁忙情况下添加,或者使用后续的在从库创建再进行主从切换
4 先在从库修改,再进行主从切换
使用场景: 如果遇到上例中一张表数据量大且是热表(读写特别频繁),则可以考虑先在从库添加,再进行主从切换,切换后再将其他几个节点上添加字段。
先在从库添加(本文在备选节点添加)
mysql> alter table testdb.tb_add_columns add col5 int;
Query OK, 0 rows affected (1 min 1.91 sec)
Records: 0 Duplicates: 0 Warnings: 0
进行主从切换
使用MHA脚本进行在线切换
masterha_master_switch --conf=/etc/masterha/app1.conf --master_state=alive --orig_master_is_new_slave --new_master_host=192.168.28.131 --new_master_port=
切换完成后再对其他节点添加字段
/* 原主库上添加192.168.28.128 */
mysql> alter table testdb.tb_add_columns add col5 int;
Query OK, 0 rows affected (1 min 8.36 sec)
Records: 0 Duplicates: 0 Warnings: 0 /* 另一个从库上添加192.168.28.132 */
mysql> alter table testdb.tb_add_columns add col5 int;
Query OK, 0 rows affected (1 min 8.64 sec)
Records: 0 Duplicates: 0 Warnings: 0
这样就完成了字段添加。
5. 小结
生产环境MySQL添加或修改字段主要通过如下三种方式进行,实际使用中还有很多注意事项,大家要多多总结。
- 直接添加
如果该表读写不频繁,数据量较小(通常1G以内或百万以内),直接添加即可(可以了解一下online ddl的知识)
- 使用pt_osc添加
如果表较大 但是读写不是太大,且想尽量不影响原表的读写,可以用percona tools进行添加,相当于新建一张添加了字段的新表,再降原表的数据复制到新表中,复制历史数据期间的数据也会同步至新表,最后删除原表,将新表重命名为原表表名,实现字段添加
- 先在从库添加 再进行主从切换
如果一张表数据量大且是热表(读写特别频繁),则可以考虑先在从库添加,再进行主从切换,切换后再将其他几个节点上添加字段
mysql大表在不停机的情况下增加字段该怎么处理的更多相关文章
- [记录]一则清理MySQL大表以释放磁盘空间的案例
一则清理MySQL大表以释放磁盘空间的案例 一.基本情况: 1.dbtest库554G,先清理st_online_time_away_ds(37G)表的数据,保留半年的数据: 1)删除的数据:sele ...
- 优秀后端架构师必会知识:史上最全MySQL大表优化方案总结
本文原作者“ manong”,原创发表于segmentfault,原文链接:segmentfault.com/a/1190000006158186 1.引言 MySQL作为开源技术的代表作之一,是 ...
- MySQL 大表优化方案(长文)
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- 从云数据迁移服务看MySQL大表抽取模式
摘要:MySQL JDBC抽取到底应该采用什么样的方式,且听小编给你娓娓道来. 小编最近在云上的一个迁移项目中被MySQL抽取模式折磨的很惨.一开始爆内存被客户怼,再后来迁移效率低下再被怼.MySQL ...
- mysql大表如何优化
作者:哈哈链接:http://www.zhihu.com/question/19719997/answer/81930332来源:知乎著作权归作者所有.商业转载请联系作者获得授权,非商业转载请注明出处 ...
- 详解MySQL大表优化方案( 转)
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- MySQL 大表优化方案探讨
当MySQL单表记录数过大时,增删改查性能都会急剧下降,可以参考以下步骤来优化: 单表优化 除非单表数据未来会一直不断上涨,否则不要一开始就考虑拆分,拆分会带来逻辑.部署.运维的各种复杂度,一般以整型 ...
- Mysql大表查询优化技巧总结及案例分析
http://www.169it.com/article/3219955334.html sql语句使用基本原则:1.对查询进行优化,应尽量避免全表扫描,首先应考虑在 where 及 orde ...
- MySQL大表优化方案
转:https://segmentfault.com/a/1190000006158186?hmsr=toutiao.io&utm_medium=toutiao.io&utm_sour ...
随机推荐
- jQuery基础总计
框架概述 框架(Framework)是整个或部分系统的可重用设计,表现为一组抽象构件及构件实例间交互的方法.框架是完成某种功能的半成品,框架是将我们日常的繁琐的代码进行抽取,并提供出更加简洁,功能更加 ...
- [C# WPF] 根据按钮动态跳转窗体
WPF 根据按钮动态跳转窗体 XMAL文件中,用Tag保存要跳的页面 <Button Name="btnWindow01" Content="ClickMe&quo ...
- 设计带构造函数的Dog类 代码参考
#include <iostream> #include <string> using namespace std; class Dog { private: string n ...
- R语言入门一
一.数据分析相关概念 数据:是指对事物或对象各方面进行描述的符号,包括事物的基本属性.特征.性质.状态.相互关系等:比如描述人的数据有:身高.年龄.性别.兴趣.性格.婚姻状态等等. 分析:是指把事物或 ...
- C#线程 基本同步
第二部分: 基本同步 同步要点 到目前为止,我们已经描述了如何在线程上启动任务,配置线程以及双向传递数据.我们还描述了局部变量如何专用于线程,以及如何在线程之间共享引用,从而允许它们通过公共字段进行 ...
- php序列化和反序列化学习
1.什么是序列化 序列化说通俗点就是把一个对象变成可以传输的字符串. 1.举个例子,不知道大家知不知道json格式,这就是一种序列化,有可能就是通过array序列化而来的.而反序列化就是把那串可以传输 ...
- VNC远程控制,如何使用VNC远程控制来管理公司?
VNC是功能强大的远程操作软件,可以实现日常的远程连接操作:如果稍加利用,可以实现公司的日常管理:既能够节省自身的时间,还可高效的完成这个功能! 我们可以使用:服务器管理工具来进行相关的操作 一.首先 ...
- JS遍历对象修改属性名
根据接口返回数据中number属性值,对数据进行截取,并改变属性名.直接上码: 下面是需要处理的数据 let data={"minValue":7400, "maxVal ...
- Java实现 LeetCode 605 种花问题(边界问题)
605. 种花问题 假设你有一个很长的花坛,一部分地块种植了花,另一部分却没有.可是,花卉不能种植在相邻的地块上,它们会争夺水源,两者都会死去. 给定一个花坛(表示为一个数组包含0和1,其中0表示没种 ...
- Java实现 LeetCode 238 除自身以外数组的乘积
238. 除自身以外数组的乘积 给定长度为 n 的整数数组 nums,其中 n > 1,返回输出数组 output ,其中 output[i] 等于 nums 中除 nums[i] 之外其余各元 ...