JS反爬绕过思路之--谷歌学术镜像网链接抓取
首先,从问题出发:
在谷歌学术镜像网收集着多个谷歌镜像的链接。我们目标就是要把这些链接拿到手。
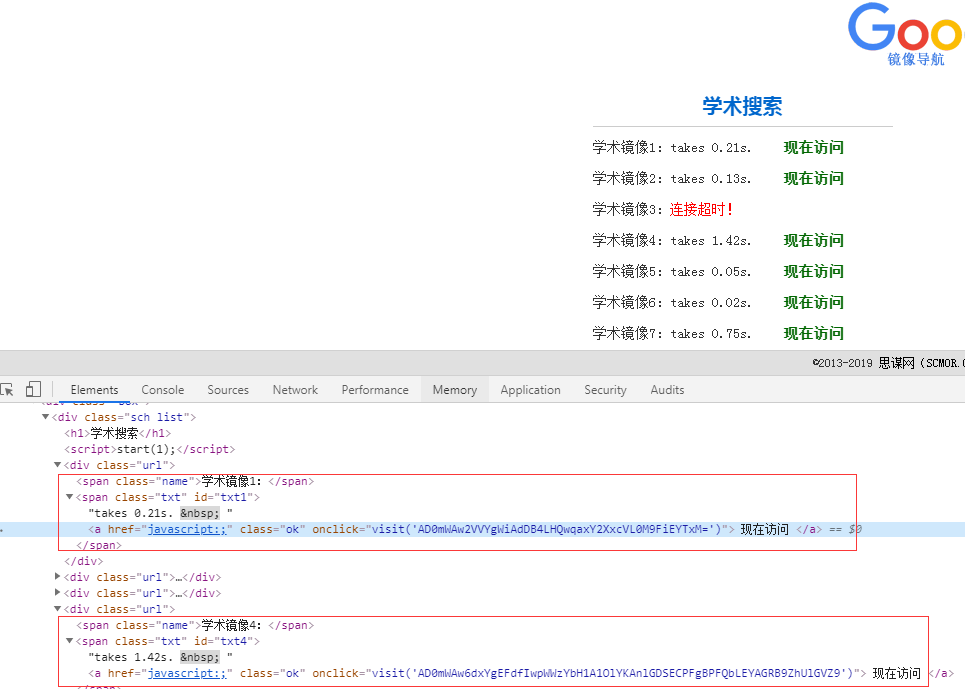
F12查看源码可以发现,对应的a标签并不是我们想要的链接,而是一个js点击函数。
其实在
onclick="visit('AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=')"
上面一段代码里,AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=就是加密后的url链接。
visit函数的作用就是对这一串字符串进行了解密并访问。
通过搜索我们可以清楚visit函数它的源码:
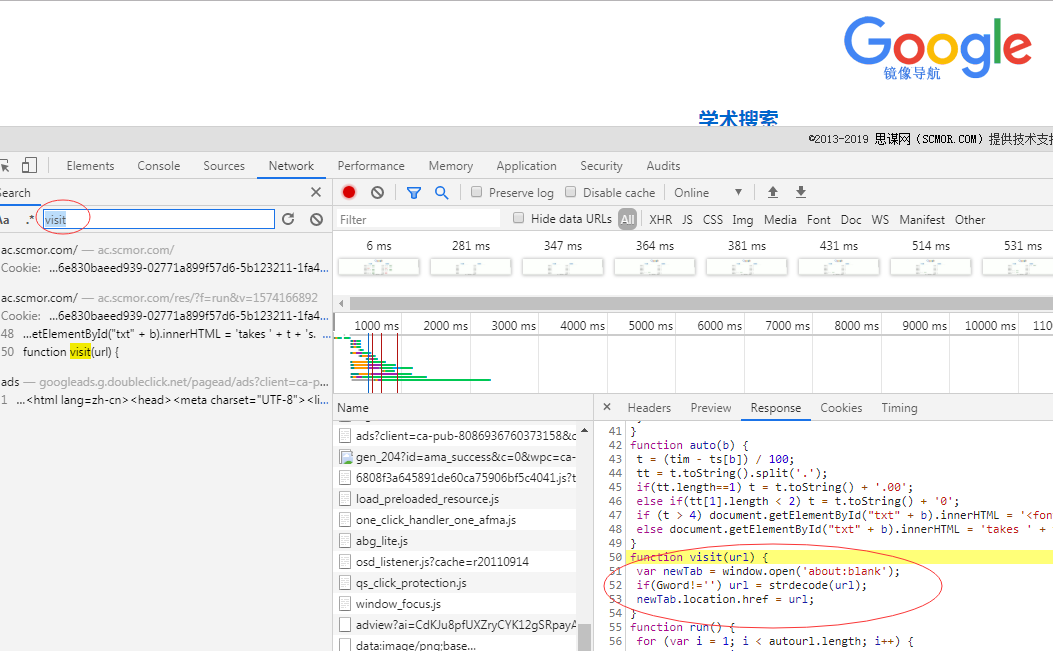
就是这一段:
function visit(url) {
var newTab = window.open('about:blank'); //打开新窗口
if(Gword!='') url = strdecode(url);//解密字符串,将它变成url
newTab.location.href = url;//访问这个url
}
ok,又扯出来一个叫strdecode的函数,我们继续找找看:

function strdecode(string) {
string = base64decode(string);//base64decode函数处理参数
key = Gword + hn;//Gword和hn两个变量可以在网页源码找到
len = key.length;//key的长度
code = '';
for (i = 0; i < string.length; i++) {//这个循环是中间的解密过程
var k = i % len;
code += String.fromCharCode(string.charCodeAt(i) ^ key.charCodeAt(k));
}
return base64decode(code);//再利用base64decode处理一次中间过程产出的code变量,其实这个就是真正的url了
}
其实sredecode的参数string就是类似一开始说的"AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM="
又有一个叫base64decode的函数,那我们再找找看:

ok,好长一段js代码。我都不想去理解它了、、
怎么办?
咱可以利用python的execjs库来执行js代码,只需把js代码保存下来就好。那我们把能用到的js都给保存下来像这样:
execjs安装:pip install PyExecJS
var base64DecodeChars = new Array(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);
function base64decode(str) {
var c1, c2, c3, c4;
var i, len, out;
len = str.length;
i = 0;
out = "";
while (i < len) {
do {
c1 = base64DecodeChars[str.charCodeAt(i++) & 0xff]
} while (i < len && c1 == -1);
if (c1 == -1) break;
do {
c2 = base64DecodeChars[str.charCodeAt(i++) & 0xff]
} while (i < len && c2 == -1);
if (c2 == -1) break;
out += String.fromCharCode((c1 << 2) | ((c2 & 0x30) >> 4));
do {
c3 = str.charCodeAt(i++) & 0xff;
if (c3 == 61) return out;
c3 = base64DecodeChars[c3]
} while (i < len && c3 == -1);
if (c3 == -1) break;
out += String.fromCharCode(((c2 & 0XF) << 4) | ((c3 & 0x3C) >> 2));
do {
c4 = str.charCodeAt(i++) & 0xff;
if (c4 == 61) return out;
c4 = base64DecodeChars[c4]
} while (i < len && c4 == -1);
if (c4 == -1) break;
out += String.fromCharCode(((c3 & 0x03) << 6) | c4)
}
return out
}
function strdecode(string) {
string = base64decode(string);
key = "author: link@scmor.com.ac.scmor.com";
len = key.length;
code = '';
for (i = 0; i < string.length; i++) {
var k = i % len;
code += String.fromCharCode(string.charCodeAt(i) ^ key.charCodeAt(k));
}
return base64decode(code);
}
然后利用python请求网页源码,把AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=这些密文用re匹配出来。
最后利用上面保存的js代码解密:
最终代码(PS:也放在github上面了,博客左上角点击直达):
import requests
from lxml import etree
import re
import execjs with open('scmor.js', 'r', encoding='utf-8') as f:
js = f.read()
ctx = execjs.compile(js)
#编译保存的js def get_html():
#请求html
try:
r = requests.get("http://ac.scmor.com/")
r.encoding = r.apparent_encoding
return r.text
except:
print('产生异常') def parse_html(html):
#解析html,并用re匹配密文
tree = etree.HTML(html)
script_text = tree.xpath('//script/text()')[0]
autourls = re.findall(r'AD0mWAw[a-zA-Z0-9]+=*', script_text)
return autourls def decode(string):
#利用保存的js解密密文
return ctx.call('strdecode', string) if __name__ == '__main__':
html = get_html()
autourls = parse_html(html)
for url in autourls:
print(decode(url))
#print(decode('AD0mWAw2VVYgWiAdDB4LHQwqaxY2XxcVL0M9FiEYTxM=')) #decode将源码中的加密字符串转url
参考文章:https://www.cnblogs.com/happymeng/p/10755244.html
The end~
JS反爬绕过思路之--谷歌学术镜像网链接抓取的更多相关文章
- python爬虫的一个常见简单js反爬
python爬虫的一个常见简单js反爬 我们在写爬虫是遇到最多的应该就是js反爬了,今天分享一个比较常见的js反爬,这个我已经在多个网站上见到过了. 我把js反爬分为参数由js加密生成和js生成coo ...
- js反爬学习(一)谷歌镜像
1. url:https://ac.scmor.com/ 2. target:如下链接 3. 过程分析: 3.1 打开chrome调试,进行元素分析.随便定位一个“现在访问” 3.2 链接不是直接挂在 ...
- js反爬-从入门到精通webdriver
学习JS反爬 地址:http://openlaw.cn/login.jsp 想在指导案例中抓些内容,需要登陆 账号密码发送会以下面方式发送 所以需要找到_csrf和加密后的password,_csrf ...
- k 近邻算法解决字体反爬手段|效果非常好
字体反爬,是一种利用 CSS 特性和浏览器渲染规则实现的反爬虫手段.其高明之处在于,就算借助(Selenium 套件.Puppeteer 和 Splash)等渲染工具也无法拿到真实的文字内容. 这种反 ...
- node.js抓取数据(fake小爬虫)
在node.js中,有了 cheerio 模块.request 模块,抓取特定URL页面的数据已经非常方便. 一个简单的就如下 var request = require('request'); va ...
- 通过JS逆向ProtoBuf 反反爬思路分享
前言 本文意在记录,在爬虫过程中,我首次遇到Protobuf时的一系列问题和解决问题的思路. 文章编写遵循当时工作的思路,优点:非常详细,缺点:文字冗长,描述不准确 protobuf用在前后端传输,在 ...
- 爬虫入门到放弃系列07:js混淆、eval加密、字体加密三大反爬技术
前言 如果再说IP请求次数检测.验证码这种最常见的反爬虫技术,可能大家听得耳朵都出茧子了.当然,也有的同学写了了几天的爬虫,觉得爬虫太简单.没有啥挑战性.所以特地找了三个有一定难度的网站,希望可以有兴 ...
- python爬虫破解带有RSA.js的RSA加密数据的反爬机制
前言 同上一篇的aes加密一样,也是偶然发现这个rsa加密的,目标网站我就不说了,保密. 当我发现这个网站是ajax加载时: 我已经习以为常,正在进行爬取时,发现返回为空,我开始用findler抓包, ...
- 使用Selenium从IEEE与谷歌学术批量爬取BibTex文献引用
搞科研的小伙伴总是会被期刊严苛的引用文献格式搞的很头疼.虽然常用的文献软件可以一键导出BibTex,但由于很多论文在投稿之前都会先发上Arxiv占坑,软件就很可能会把文献引出为来自Arxiv.我用的是 ...
随机推荐
- 吴裕雄--天生自然python学习笔记:pandas模块DataFrame 数据的修改及排序
import pandas as pd datas = [[65,92,78,83,70], [90,72,76,93,56], [81,85,91,89,77], [79,53,47,94,80]] ...
- spring-boot jpa mysql emoji utfmb4 异常处理
spring-boot jpa mysql utf8mb4 emoji 写入失败 mysql database,table,column 默认为utf8mb4 Caused by: java.sql. ...
- Java开发面试常见问题合集
次面试事故 面试官:你看过哪些源码?我:都挺熟悉的面试官:对hashMap了解程度怎么样?面试官:那你能讲讲 HashMap的实现原理吗?面试官:HashMap什么时候会进行 rehash?面试官:结 ...
- C# SerialPort 读写三菱FX系列PLC
1:串口初始化 com = , Parity.Even, , StopBits.One); 2:打开关闭串口 if (com.IsOpen) { com.Close();//关闭 } com.Open ...
- Ajax如何提交数据到springMVC后台
现在好多web项目实现前段和后端分离,实现前端和后端技术人员,使他们加快开发,减少沟通上的问题,后台只需要提供访问接口,而前天只需要调用提供的接口即可.减少前后端的沟通上的成本 本项目是开发中发现aj ...
- <JZOJ5941>乘
emmm还挺妙 不过我没想到qwq 考场上瞎写的还mle了心碎 把b分两..预处理下 O1询问qwq #include<cstdio> #include<iostream> # ...
- php--判断是否是手机端
function is_mobile_request(){ $_SERVER['ALL_HTTP'] = isset($_SERVER['ALL_HTTP']) ? $_SERVER['ALL_HTT ...
- Zabbix-3.0.3实现微信(WeChat)报警
转自:http://blog.sina.com.cn/s/blog_87113ac20102w7hp.html Zabbix可以通过多种方式把告警信息发送到指定人,常用的有邮件,短信报警方式,但是越来 ...
- 分布式文件系统与HDFS
HDFS,它是一个虚拟文件系统,用于存储文件,通过目录树来定位文件:其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色. HDFS 的设计适合一次写入,多次读出的场景,且不 ...
- 前端自动化构建工具gulp
1.gulp的安装 首先确保你已经正确安装了nodejs环境.然后以全局方式安装gulp: npm install -g gulp 全局安装gulp后,还需要在每个要使用gulp的项目中都单独安装一次 ...