Spring官网阅读(九)Spring中Bean的生命周期(上)
文章目录
在之前的文章中,我们一起学习过了官网上容器扩展点相关的知识,包括
FactoryBean,BeanFactroyPostProcessor,BeanPostProcessor,其中BeanPostProcessor还剩一个很重要的知识点没有介绍,就是相关的BeanPostProcessor中的方法的执行时机。之所以在之前的文章中没有介绍是因为这块内容涉及到Bean的生命周期。在这篇文章中我们开始学习Bean的生命周期相关的知识,整个Bean的生命周期可以分为以下几个阶段:
- 实例化(得到一个还没有经过属性注入跟初始化的对象)
- 属性注入(得到一个经过了属性注入但还没有初始化的对象)
- 初始化(得到一个经过了初始化但还没有经过
AOP的对象,AOP会在后置处理器中执行)- 销毁
在上面几个阶段中,
BeanPostProcessor将会穿插执行。而在初始化跟销毁阶段又分为两部分:
- 生命周期回调方法的执行
- aware相关接口方法的执行
这篇文章中,我们先完成Bean生命周期中,整个初始化阶段的学习,对于官网中的章节为
1.6小结
生命周期回调
1、Bean初始化回调
实现初始化回调方法,有以下三种形式
- 实现
InitializingBean接口
如下:
public class AnotherExampleBean implements InitializingBean {
public void afterPropertiesSet() {
// do some initialization work
}
}
- 使用Bean标签中的
init-method属性
配置如下:
<bean id="exampleInitBean" class="examples.ExampleBean" init-method="init"/>
public class ExampleBean {
public void init() {
// do some initialization work
}
}
- 使用
@PostConstruct注解
配置如下:
public class ExampleBean {
@PostConstruct
public void init() {
// do some initialization work
}
}
2、Bean销毁回调
实现销毁回调方法,有以下三种形式
- 实现
DisposableBean接口
public class AnotherExampleBean implements DisposableBean {
public void destroy() {
// do some destruction work (like releasing pooled connections)
}
}
- 使用Bean标签中的
destroy-method属性
<bean id="exampleInitBean" class="examples.ExampleBean" destroy-method="cleanup"/>
public class ExampleBean {
public void cleanup() {
// do some destruction work (like releasing pooled connections)
}
}
- 使用
@PreDestroy注解
public class ExampleBean {
@PreDestroy
public void cleanup() {
// do some destruction work (like releasing pooled connections)
}
}
3、配置默认的初始化及销毁方法
我们可以通过如下这种配置,为多个Bean同时指定初始化或销毁方法
<beans default-init-method="init" default-destroy-method="destory">
<bean id="blogService" class="com.something.DefaultBlogService">
<property name="blogDao" ref="blogDao" />
</bean>
</beans>
在上面的XML配置中,Spring会将所有处于beans标签下的Bean的初始化方法名默认为init,销毁方法名默认为destory。
但是如果我们同时在bean标签中也指定了init-method属性,那么默认的配置将会被覆盖。
4、执行顺序
如果我们在配置中同时让一个Bean实现了回调接口,又在Bean标签中指定了初始化方法,还进行了
@PostContruct注解的配置的话,那么它们的执行顺序如下:
- 被
@PostConstruct所标记的方法 InitializingBean接口中的afterPropertiesSet()方法- Bean标签中的
init()方法
对于销毁方法执行顺序如下:
- 被
@PreDestroy所标记的方法 destroy()DisposableBean回调接口中的destroy()方法- Bean标签中的
destroy()方法
我们可以总结如下:
注解的优先级 > 实现接口的优先级 > XML配置的优先级
同时我们需要注意的是,官网推荐我们使用注解的形式来定义生命周期回调方法,这是因为相比于实现接口,采用注解这种方式我们的代码跟Spring框架本身的耦合度更加低。
5、容器启动或停止回调
Lifecycle 接口
public interface Lifecycle {
// 当容器启动时调用
void start();
// 当容器停止时调用
void stop();
// 当前组件的运行状态
boolean isRunning();
}
编写一个Demo如下:
public class Main {
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext(LifeCycleConfig.class);
ac.start();
ac.stop();
}
}
@Component
public class LifeCycleService implements Lifecycle {
boolean isRunning;
@Override
public void start() {
isRunning = true;
System.out.println("LifeCycleService start");
}
@Override
public void stop() {
isRunning = false;
System.out.println("LifeCycleService stop");
}
@Override
public boolean isRunning() {
return isRunning;
}
}
运行上面的代码可以发现程序正常打印启动跟停止的日志,在上面的例子中需要注意的时,一定要在start方法执行时将容器的运行状态isRunning置为true,否则stop方法不会调用
在Spring容器中,当接收到start或stop信号时,容器会将这些传递到所有实现了Lifecycle的组件上,在Spring内部是通过LifecycleProcessor接口来完成这一功能的。其接口定义如下:
LifecycleProcessor
public interface LifecycleProcessor extends Lifecycle {
// 容器刷新时执行
void onRefresh();
// 容器关闭时执行
void onClose();
}
从上面的代码中我们可以知道,LifecycleProcessor本身也是Lifecycle接口的扩展,它添加了两个额外的方法在容器刷新跟关闭时执行。
我们需要注意以下几点:
- 当我们实现
Lifecycle接口时,如果我们想要其start或者stop执行,必须显式的调用容器的start()或者stop()方法。 - stop方法不一定能保证在我们之前介绍的销毁方法之前执行
当我们在容器中对多个Bean配置了在容器启动或停止时的调用时,那么这些Bean中start方法跟stop方法调用的顺序就很重要了。如果两个Bean之间有明确的依赖关系,比如我们通过@DepnedsOn注解,或者@AutoWired注解向容器表明了Bean之间的依赖关系,如下:
@Component
@DependsOn("b")
class A{
// @AutoWired
// B b;
}
@Component
class B{
}
这种情况下,b作为被依赖项,其start方法会在a的start方法前调用,stop方法会在a的stop方法后调用
但是,在某些情况下Bean直接并没有直接的依赖关系,可能我们只知道实现了接口一的所有Bean的方法的优先级要高于实现了接口二的Bean。在这种情况下,我们就需要用到SmartLifecycle这个接口了
SmartLifecycle
其继承关系如下:
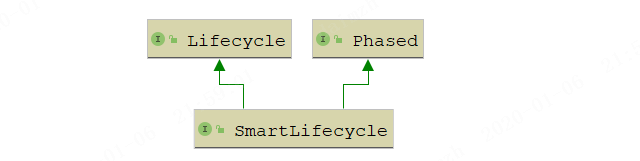
它本身除了继承了Lifecycle接口还继承了一个Phased接口,其接口定义如下:
public interface Phased {
/**
* Return the phase value of this object.
*/
int getPhase();
}
通过上面接口定义的方法,我们可以指定不同Bean方法回调方法执行的优先级。
再来看看SmartLifecycle本身这个接口的定义
public interface SmartLifecycle extends Lifecycle, Phased {
int DEFAULT_PHASE = Integer.MAX_VALUE;
// 不需要显示的调用容器的start方法及stop方法也可以执行Bean的start方法跟stop方法
default boolean isAutoStartup() {
return true;
}
// 容器停止时调用的方法
default void stop(Runnable callback) {
stop();
callback.run();
}
// 优先级,默认最低
@Override
default int getPhase() {
return DEFAULT_PHASE;
}
}
一般情况下,我们并不会复写isAutoStartup以及stop方法,但是为了指定方法执行的优先级,我们通常会覆盖其中的getPhase()方法,默认情况下它的优先级是最低的。我们需要知道的是,当我们启动容器时,如果有Bean实现了SmartLifecycle接口,其getPhase()方法返回的值越小,那么对于的start方法执行的时间就会越早,stop方法执行的时机就会越晚。因此,一个实现SmartLifecycle的对象,它的getPhase()方法返回Integer.MIN_VALUE将是第一个执行start方法的Bean和最后一个执行Stop方法的Bean。
另外我们可以看到
源码分析
源码分析,我们需要分为两个阶段:
启动阶段
整个流程图如下:
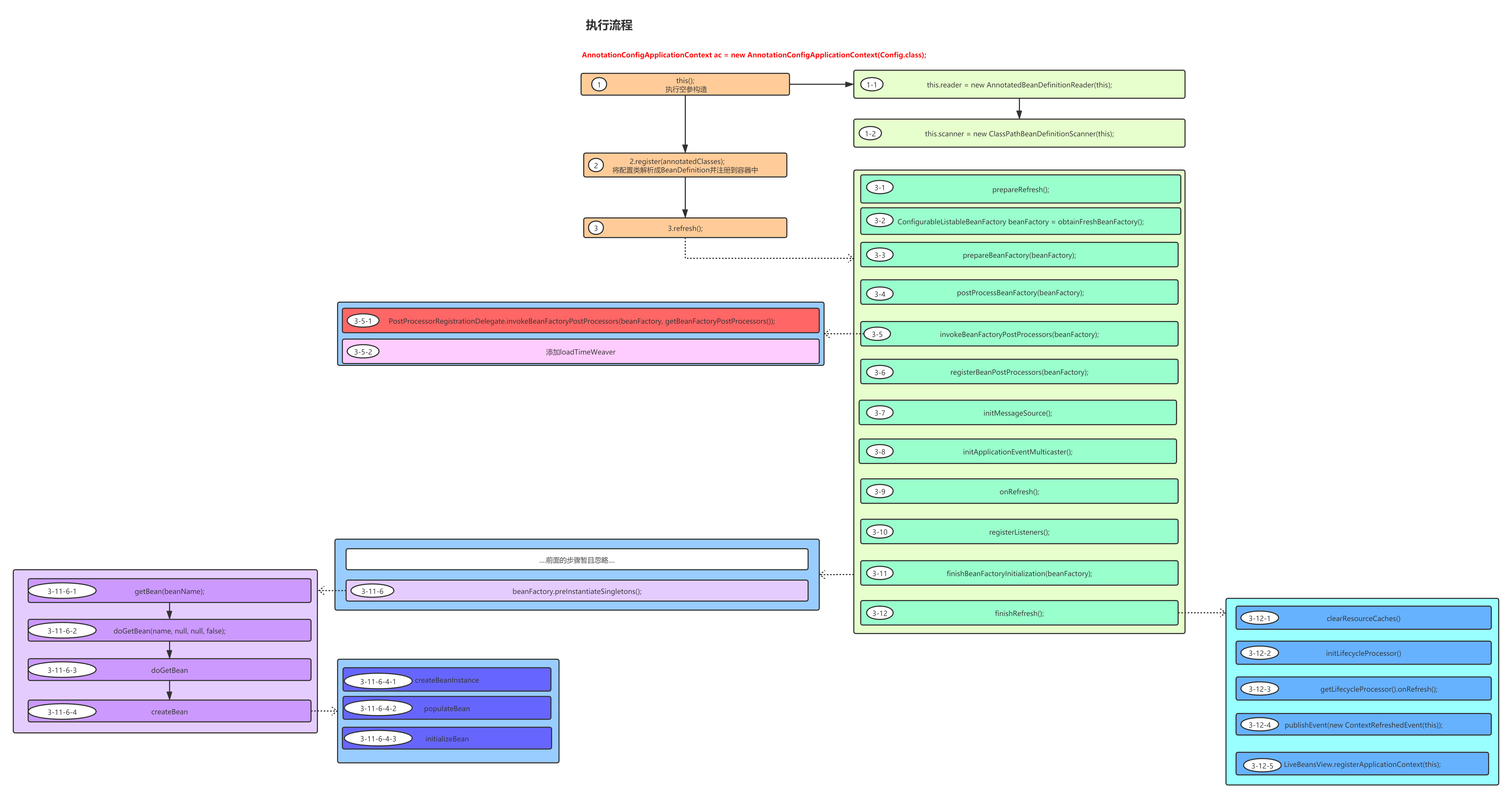
我们主要分析的代码在其中的3-12-2及3-12-3步骤中
3-12-2解析,代码如下:
protected void initLifecycleProcessor() {
ConfigurableListableBeanFactory beanFactory = getBeanFactory();
if (beanFactory.containsLocalBean(LIFECYCLE_PROCESSOR_BEAN_NAME)) {
this.lifecycleProcessor =
beanFactory.getBean(LIFECYCLE_PROCESSOR_BEAN_NAME, LifecycleProcessor.class);
if (logger.isTraceEnabled()) {
logger.trace("Using LifecycleProcessor [" + this.lifecycleProcessor + "]");
}
}
else {
DefaultLifecycleProcessor defaultProcessor = new DefaultLifecycleProcessor();
defaultProcessor.setBeanFactory(beanFactory);
this.lifecycleProcessor = defaultProcessor;
beanFactory.registerSingleton(LIFECYCLE_PROCESSOR_BEAN_NAME, this.lifecycleProcessor);
if (logger.isTraceEnabled()) {
logger.trace("No '" + LIFECYCLE_PROCESSOR_BEAN_NAME + "' bean, using " +
"[" + this.lifecycleProcessor.getClass().getSimpleName() + "]");
}
}
}
这段代码很简单,就是做了一件事:判断当前容器中是否有一个lifecycleProcessor的Bean或者BeanDefinition。如果有的话,采用这个提供的lifecycleProcessor,如果没有的话自己new一个DefaultLifecycleProcessor。这个类主要负载将启动或停止信息传播到具体的Bean当中,我们稍后分析的代码基本都在这个类中。
3-12-3解析:
其中的getLifecycleProcessor(),就是获取我们上一步提供的lifecycleProcessor,然后调用其onRefresh方法,代码如下:
public void onRefresh() {
// 将start信号传递到Bean
startBeans(true);
// 这个类本身也是一个实现了Lifecycle的接口的对象,将其running置为true,标记为运行中
this.running = true;
}
之后调用了startBeans方法
private void startBeans(boolean autoStartupOnly) {
// 获取所有实现了Lifecycle接口的Bean,如果采用了factroyBean的方式配置了一个LifecycleBean,那么factroyBean本身也要实现Lifecycle接口
// 配置为懒加载的LifecycleBean必须实现SmartLifeCycle才能被调用start方法
Map<String, Lifecycle> lifecycleBeans = getLifecycleBeans();
// key:如果实现了SmartLifeCycle,则为其getPhase方法返回的值,如果只是实现了Lifecycle,则返回0
// value:相同phase的Lifecycle的集合,并将其封装到了一个LifecycleGroup中
Map<Integer, LifecycleGroup> phases = new HashMap<>();
// 遍历所有的lifecycleBeans,填充上面申明的map
lifecycleBeans.forEach((beanName, bean) -> {
// 我们可以看到autoStartupOnly这个变量在上层传递过来的
// 这个参数意味着是否只启动“自动”的Bean,这是什么意思呢?就是说,不需要手动调用容器的start方法
// 从这里可以看出,实现了SmartLifecycle接口的类并且其isAutoStartup如果返回true的话,会在容器启动过程中自动调用,而仅仅实现了Lifecycle接口的类并不会被调用。
// 如果我们去阅读容器的start方法的会发现,当调用链到达这个方法时,autoStartupOnly这个变量写死的为false
if (!autoStartupOnly || (bean instanceof SmartLifecycle && ((SmartLifecycle) bean).isAutoStartup())) {
// 获取这个Bean执行的阶段,实际上就是调用SmartLifecycle中的getPhase方法
// 如果没有实现SmartLifecycle,而是单纯的实现了Lifecycle,那么直接返回0
int phase = getPhase(bean);
// 下面就是一个填充Map的操作,有的话add,没有的话直接new一个,比较简单
LifecycleGroup group = phases.get(phase);
if (group == null) {
// LifecycleGroup构造函数需要四个参数
// phase:代表这一组lifecycleBeans的执行阶段
// timeoutPerShutdownPhase:因为lifecycleBean中的stop方法可以在另一个线程中运行,所以为了确保当前阶段的所有lifecycleBean都执行完,Spring使用了CountDownLatch,而为了防止无休止的等待下去,所有这里设置了一个等待的最大时间,默认为30秒
// lifecycleBeans:所有的实现了Lifecycle的Bean
// autoStartupOnly: 手动调用容器的start方法时,为false。容器启动阶段自动调用时为true,详细的含义在上面解释过了
group = new LifecycleGroup(phase, this.timeoutPerShutdownPhase, lifecycleBeans, autoStartupOnly);
phases.put(phase, group);
}
group.add(beanName, bean);
}
});
if (!phases.isEmpty()) {
List<Integer> keys = new ArrayList<>(phases.keySet());
// 升序排序
Collections.sort(keys);
for (Integer key : keys) {
// 获取每个阶段下所有的lifecycleBean,然后调用其start方法
phases.get(key).start();
}
}
}
跟踪代码可以发现,start方法最终调用到了doStart方法,其代码如下
private void doStart(Map<String, ? extends Lifecycle> lifecycleBeans, String beanName, boolean autoStartupOnly) {
Lifecycle bean = lifecycleBeans.remove(beanName);
if (bean != null && bean != this) {
// 获取这个Bean依赖的其它Bean,在启动时先启动其依赖的Bean
String[] dependenciesForBean = getBeanFactory().getDependenciesForBean(beanName);
for (String dependency : dependenciesForBean) {
doStart(lifecycleBeans, dependency, autoStartupOnly);
}
if (!bean.isRunning() &&
(!autoStartupOnly || !(bean instanceof SmartLifecycle) || ((SmartLifecycle) bean).isAutoStartup())) {
try {
bean.start();
}
catch (Throwable ex) {
throw new ApplicationContextException("Failed to start bean '" + beanName + "'", ex);
}
}
}
}
上面的逻辑可以归结为一句话:获取这个Bean依赖的其它Bean,在启动时先启动其依赖的Bean,这也验证了我们从官网上得出的结论。
停止阶段
停止容器有两种办法,一种时显式的调用容器的stop或者close方法,如下:
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(LifeCycleConfig.class);
ac.refresh();
ac.stop();
// ac.close();
}
而另外一个中是注册一个JVM退出时的钩子,如下:
public static void main(String[] args) {
AnnotationConfigApplicationContext ac = new AnnotationConfigApplicationContext();
ac.register(LifeCycleConfig.class);
// 当main函数运行完成后,会调用容器doClose方法
ac.registerShutdownHook();
ac.refresh();
}
不论是上面哪一种方法,最终都会调用到DefaultLifecycleProcessor的onClose方法,代码如下:
public void onClose() {
// 传递所有的停止信号到Bean
stopBeans();
// 跟启动阶段一样,因为它本身是一个实现了Lifecycle接口的Bean,所有需要更改它的运行标志
this.running = false;
}
private void stopBeans() {
// 获取容器中所有的实现了Lifecycle接口的Bean
Map<String, Lifecycle> lifecycleBeans = getLifecycleBeans();
Map<Integer, LifecycleGroup> phases = new HashMap<>();
lifecycleBeans.forEach((beanName, bean) -> {
int shutdownPhase = getPhase(bean);
LifecycleGroup group = phases.get(shutdownPhase);
if (group == null) {
group = new LifecycleGroup(shutdownPhase, this.timeoutPerShutdownPhase, lifecycleBeans, false);
phases.put(shutdownPhase, group);
}
// 同一阶段的Bean放到一起
group.add(beanName, bean);
});
if (!phases.isEmpty()) {
List<Integer> keys = new ArrayList<>(phases.keySet());
// 跟start阶段不同的是,这里采用的是降序
// 也就是阶段越后的Bean,越先stop
keys.sort(Collections.reverseOrder());
for (Integer key : keys) {
phases.get(key).stop();
}
}
}
public void stop() {
if (this.members.isEmpty()) {
return;
}
this.members.sort(Collections.reverseOrder());
// 创建了一个CountDownLatch,需要等待的线程数量为当前阶段的所有ifecycleBean的数量
CountDownLatch latch = new CountDownLatch(this.smartMemberCount);
// stop方法可以异步执行,这里保存的是还没有执行完的lifecycleBean的名称
Set<String> countDownBeanNames = Collections.synchronizedSet(new LinkedHashSet<>());
// 所有lifecycleBeans的名字集合
Set<String> lifecycleBeanNames = new HashSet<>(this.lifecycleBeans.keySet());
for (LifecycleGroupMember member : this.members) {
if (lifecycleBeanNames.contains(member.name)) {
doStop(this.lifecycleBeans, member.name, latch, countDownBeanNames);
}
else if (member.bean instanceof SmartLifecycle) {
// 按理说,这段代码永远不会执行,可能是版本遗留的代码没有进行删除
// 大家可以自行对比4.x的代码跟5.x的代码
latch.countDown();
}
}
try {
// 最大等待时间30s,超时进行日志打印
latch.await(this.timeout, TimeUnit.MILLISECONDS);
if (latch.getCount() > 0 && !countDownBeanNames.isEmpty() && logger.isInfoEnabled()) {
logger.info("Failed to shut down " + countDownBeanNames.size() + " bean" +
(countDownBeanNames.size() > 1 ? "s" : "") + " with phase value " +
this.phase + " within timeout of " + this.timeout + ": " + countDownBeanNames);
}
}
catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
}
}
private void doStop(Map<String, ? extends Lifecycle> lifecycleBeans, final String beanName,
final CountDownLatch latch, final Set<String> countDownBeanNames) {
Lifecycle bean = lifecycleBeans.remove(beanName);
if (bean != null) {
// 获取这个Bean所被依赖的Bean,先对这些Bean进行stop操作
String[] dependentBeans = getBeanFactory().getDependentBeans(beanName);
for (String dependentBean : dependentBeans) {
doStop(lifecycleBeans, dependentBean, latch, countDownBeanNames);
}
try {
if (bean.isRunning()) {
if (bean instanceof SmartLifecycle) {
if (logger.isTraceEnabled()) {
logger.trace("Asking bean '" + beanName + "' of type [" +
bean.getClass().getName() + "] to stop");
}
countDownBeanNames.add(beanName);
// 还记得到SmartLifecycle中的stop方法吗?里面接受了一个Runnable参数
// 就是在这里地方传进去的。主要就是进行一个操作latch.countDown(),标记当前的lifeCycleBean的stop方法执行完成
((SmartLifecycle) bean).stop(() -> {
latch.countDown();
countDownBeanNames.remove(beanName);
if (logger.isDebugEnabled()) {
logger.debug("Bean '" + beanName + "' completed its stop procedure");
}
});
}
else {
if (logger.isTraceEnabled()) {
logger.trace("Stopping bean '" + beanName + "' of type [" +
bean.getClass().getName() + "]");
}
bean.stop();
if (logger.isDebugEnabled()) {
logger.debug("Successfully stopped bean '" + beanName + "'");
}
}
}
else if (bean instanceof SmartLifecycle) {
// Don't wait for beans that aren't running...
latch.countDown();
}
}
catch (Throwable ex) {
if (logger.isWarnEnabled()) {
logger.warn("Failed to stop bean '" + beanName + "'", ex);
}
}
}
}
整个stop方法跟start方法相比,逻辑上并没有很大的区别,除了执行时顺序相反外。
- start方法,先找出这个Bean的所有依赖,然后先启动这个Bean的依赖
- stop方法,先找出哪些Bean依赖了当前的Bean,然后停止这些被依赖的Bean,之后再停止当前的Bean
Aware接口
在整个Bean的生命周期的初始化阶段,有一个很重要的步骤就是执行相关的Aware接口,而整个Aware接口执行又可以分为两个阶段:
- 第一阶段,执行
BeanXXXAware接口 - 执行其它Aware接口
至于为什么需要这样分,我们在进行源码分析的时候就明白了
我们可以发现,所有的Aware接口都是为了能让我们拿到容器中相关的资源,比如BeanNameAware,可以让我们拿到Bean的名称,ApplicationContextAware 可以让我们拿到整个容器。但是使用Aware接口也会相应的带来一些弊病,当我们去实现这些接口时,意味着我们的应用程序跟Spring容器发生了强耦合,违背了IOC的原则。所以一般情况下,并不推荐采用这种方式,除非我们在编写一些整个应用基础的组件。
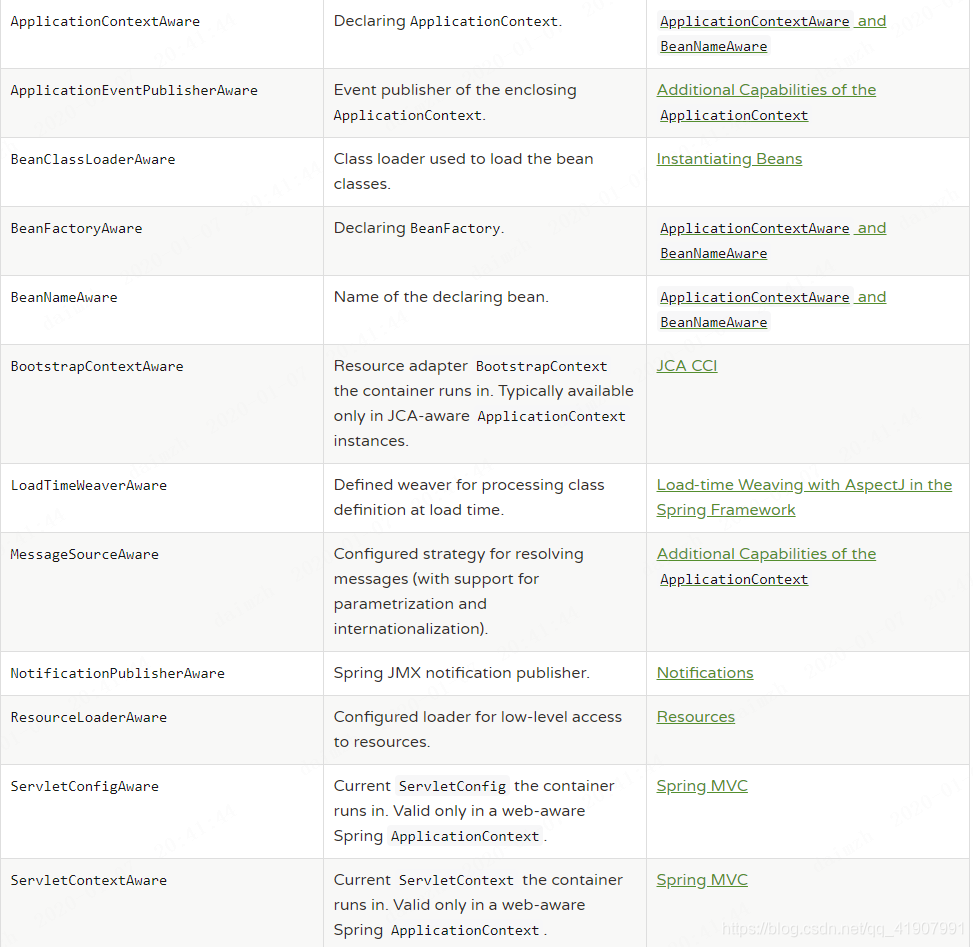
Spring内部提供了如下这些Aware接口
初始化过程源码分析
回顾我们之前的流程图,我们可以看到,创建Bean的动作主要发生在3-11-6-4步骤中,主要分为三步:
createBeanInstance,创建实例populateBean,属性注入initializeBean,初始化
我们今天要分析的代码主要就是第3-11-6-4-3步,其完成的功能主要就是初始化,相对于我们之前分析过的代码来说,这段代码算比较简单的:
protected Object initializeBean(final String beanName, final Object bean, @Nullable RootBeanDefinition mbd) {
if (System.getSecurityManager() != null) {
AccessController.doPrivileged((PrivilegedAction<Object>) () -> {
invokeAwareMethods(beanName, bean);
return null;
}, getAccessControlContext());
}
else {
// 第一步:执行aware接口中的方法,需要主要的是,不是所有的Aware接口都是在这步执行了
invokeAwareMethods(beanName, bean);
}
Object wrappedBean = bean;
if (mbd == null || !mbd.isSynthetic()) {
// 第二步:完成Aware接口方法的执行,以及@PostConstructor,@PreDestroy注解的处理
wrappedBean = applyBeanPostProcessorsBeforeInitialization(wrappedBean, beanName);
}
try {
// 第三步:完成初始化方法执行
invokeInitMethods(beanName, wrappedBean, mbd);
}
catch (Throwable ex) {
throw new BeanCreationException(
(mbd != null ? mbd.getResourceDescription() : null),
beanName, "Invocation of init method failed", ex);
}
if (mbd == null || !mbd.isSynthetic()) {
// 第四步:完成AOP代理
wrappedBean = applyBeanPostProcessorsAfterInitialization(wrappedBean, beanName);
}
return wrappedBean;
}
第一步:执行部分aware接口中的方法
private void invokeAwareMethods(final String beanName, final Object bean) {
if (bean instanceof Aware) {
if (bean instanceof BeanNameAware) {
((BeanNameAware) bean).setBeanName(beanName);
}
if (bean instanceof BeanClassLoaderAware) {
ClassLoader bcl = getBeanClassLoader();
if (bcl != null) {
((BeanClassLoaderAware) bean).setBeanClassLoader(bcl);
}
}
if (bean instanceof BeanFactoryAware) {
((BeanFactoryAware) bean).setBeanFactory(AbstractAutowireCapableBeanFactory.this);
}
}
}
可以看到,在invokeAwareMethods这个方法中,并不是所有的Aware接口都会被执行,只有BeanNameAware,BeanClassLoaderAware,BeanFactoryAware这三个接口会被执行,这也是为什么我单独将BeanXXXAware这一类的接口划分为一组的原因。这三个Aware接口分别实现的功能为:
BeanNameAware:获取Bean的名字
BeanClassLoaderAware:获取加载这个Bean的类加载器
BeanFactoryAware:获取当前的BeanFactory
第二步:完成Aware接口方法的执行,以及@PostConstructor,@PreDestroy注解的处理
- Aware接口执行,出了我们上面介绍的三个Aware接口,其余的接口都会在这个阶段执行,例如我们之前说到的
ApplicationContextAware接口,它会被一个专门的后置处理器ApplicationContextAwareProcessor处理。其余的接口也是类似的操作,这里就不在赘述了 @PostConstructor,@PreDestroy两个注解的处理。这两个注解会被CommonAnnotationBeanPostProcessor这个后置处理器处理,需要注意的是@Resource注解也是被这个后置处理器进行处理的。关于注解的处理逻辑,我们后面的源码阅读相关文章中再做详细分析。
第三步:完成初始化方法执行
protected void invokeInitMethods(String beanName, final Object bean, @Nullable RootBeanDefinition mbd)
throws Throwable {
// 是否实现了 InitializingBean接口
boolean isInitializingBean = (bean instanceof InitializingBean);
if (isInitializingBean && (mbd == null ||
// 这个判断基本恒成立,除非手动改变了BD的属性
!mbd.isExternallyManagedInitMethod("afterPropertiesSet"))) {
if (logger.isTraceEnabled()) {
logger.trace("Invoking afterPropertiesSet() on bean with name '" + beanName + "'");
}
if (System.getSecurityManager() != null) {
try {
AccessController.doPrivileged((PrivilegedExceptionAction<Object>) () -> {
// 调用afterPropertiesSet方法
((InitializingBean) bean).afterPropertiesSet();
return null;
}, getAccessControlContext());
}
catch (PrivilegedActionException pae) {
throw pae.getException();
}
}
else {
// 调用afterPropertiesSet方法
((InitializingBean) bean).afterPropertiesSet();
}
}
if (mbd != null && bean.getClass() != NullBean.class) {
String initMethodName = mbd.getInitMethodName();
if (StringUtils.hasLength(initMethodName) &&
!(isInitializingBean && "afterPropertiesSet".equals(initMethodName)) &&
!mbd.isExternallyManagedInitMethod(initMethodName)) {
invokeCustomInitMethod(beanName, bean, mbd);
}
}
}
整段代码的逻辑还是很简单的,先判断是否实现了对应的生命周期回调的接口(InitializingBean),如果实现了接口,先调用接口中的afterPropertiesSet方法。之后在判断是否提供了initMethod,也就是在XML中的Bean标签中提供了init-method属性。
第四步:完成AOP代理
AOP代理实现的具体过程放到之后的文章中分析,我们暂时只需要知道AOP是在Bean完成了所有初始化方法后完成的即可。这也不难理解,在进行AOP之前必须保证我们的Bean已经被充分的”装配“了。
总结
就目前而言,我们可以将整个Bean的生命周期总结如下:
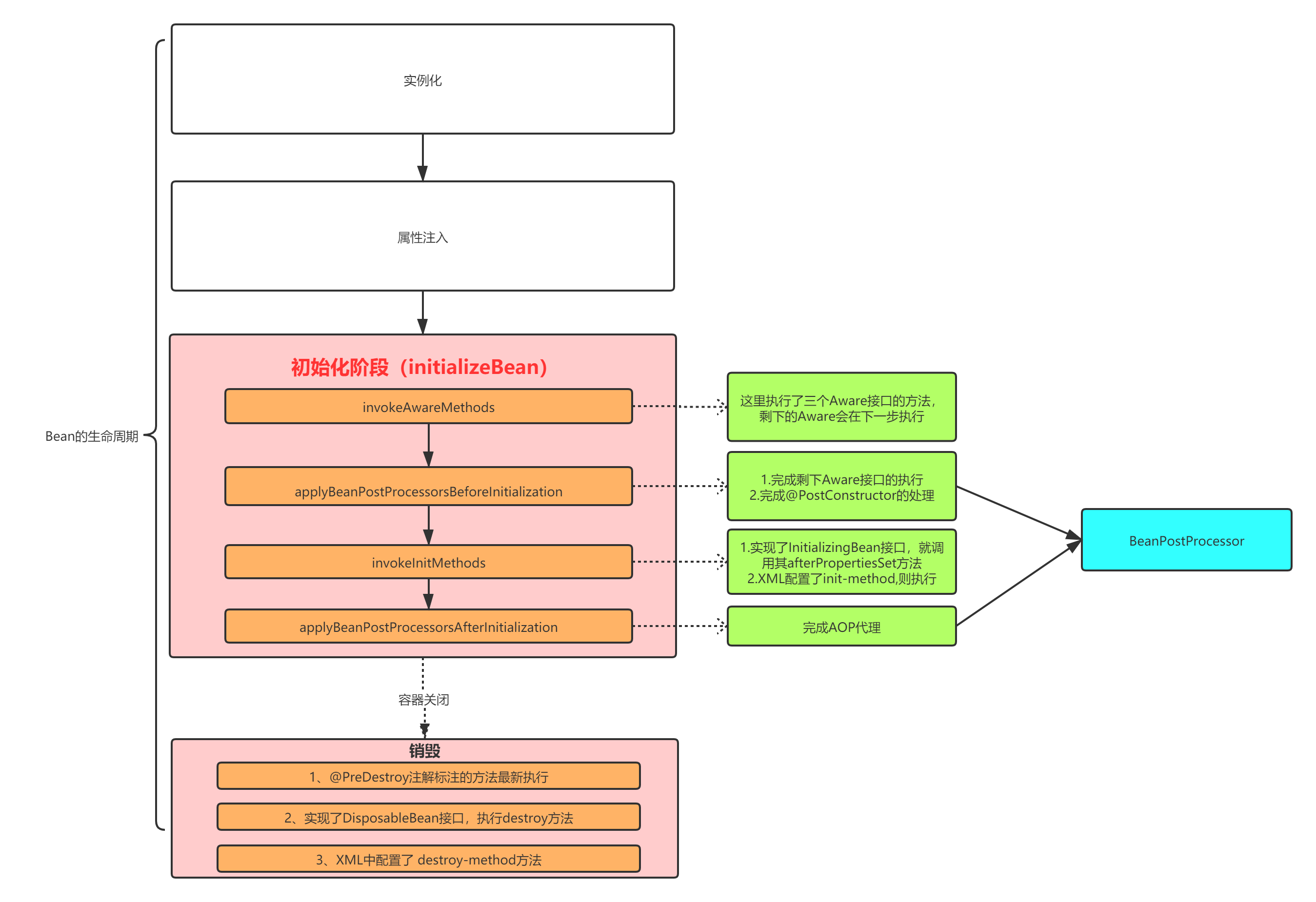
在上图中,实例话跟属性注入的过程我们还没有分析,在后续的文章中,我们将对其进行详细的分析。销毁阶段并不复杂,所以这里也不做分析了,直接给出结论,大概可以自己阅读代码,入口在容器的close方法中。
另外,我这里并没有将实现了LifeCycle接口的Bean中的start方法跟stop方法算入到整个Bean的生命周期中,大家只要知道,如果实现了SmartLifeCyle接口,那么在容器启动时也会默认调用其start方法,并且调用的时机在Bean完成初始化后,而stop方法将在Bean销毁前调用。
Spring官网阅读(九)Spring中Bean的生命周期(上)的更多相关文章
- 7 -- Spring的基本用法 -- 9...容器中Bean的生命周期
7.9 容器中Bean的生命周期 Spring可以管理singleton作用域的Bean的生命周期,Spring可以精确地知道该Bean何时被创建,何时被初始化完成.容器何时准备销毁该Bean实例. ...
- Spring官网阅读(十一)ApplicationContext详细介绍(上)
文章目录 ApplicationContext 1.ApplicationContext的继承关系 2.ApplicationContext的功能 Spring中的国际化(MessageSource) ...
- Spring官网阅读 | 总结篇
接近用了4个多月的时间,完成了整个<Spring官网阅读>系列的文章,本文主要对本系列所有的文章做一个总结,同时也将所有的目录汇总成一篇文章方便各位读者来阅读. 下面这张图是我整个的写作大 ...
- Spring官网阅读(十)Spring中Bean的生命周期(下)
文章目录 生命周期概念补充 实例化 createBean流程分析 doCreateBean流程分析 第一步:factoryBeanInstanceCache什么时候不为空? 第二步:创建对象(crea ...
- Spring官网阅读(十七)Spring中的数据校验
文章目录 Java中的数据校验 Bean Validation(JSR 380) 使用示例 Spring对Bean Validation的支持 Spring中的Validator 接口定义 UML类图 ...
- Spring官网阅读(十六)Spring中的数据绑定
文章目录 DataBinder UML类图 使用示例 源码分析 bind方法 doBind方法 applyPropertyValues方法 获取一个属性访问器 通过属性访问器直接set属性值 1.se ...
- Spring官网阅读(十八)Spring中的AOP
文章目录 什么是AOP AOP中的核心概念 切面 连接点 通知 切点 引入 目标对象 代理对象 织入 Spring中如何使用AOP 1.开启AOP 2.申明切面 3.申明切点 切点表达式 excecu ...
- 你知道Spring是怎么将AOP应用到Bean的生命周期中的吗?
聊一聊Spring是怎么将AOP应用到Bean的生命周期中的? 本系列文章: 听说你还没学Spring就被源码编译劝退了?30+张图带你玩转Spring编译 读源码,我们可以从第一行读起 你知道Spr ...
- Spring中 bean的生命周期
为什么要了解Spring中 bean的生命周期? 有时候我们需要自定义bean的创建过程,因此了解Spring中 bean的生命周期非常重要. 二话不说先上图: 在谈具体流程之前先看看Spring官方 ...
- 如果你每次面试前都要去背一篇Spring中Bean的生命周期,请看完这篇文章
前言 当你准备去复习Spring中Bean的生命周期的时候,这个时候你开始上网找资料,很大概率会看到下面这张图: 先不论这张图上是否全面,但是就说这张图吧,你是不是背了又忘,忘了又背? 究其原因在于, ...
随机推荐
- 数据结构和算法(Golang实现)(9)基础知识-算法复杂度及渐进符号
算法复杂度及渐进符号 一.算法复杂度 首先每个程序运行过程中,都要占用一定的计算机资源,比如内存,磁盘等,这些是空间,计算过程中需要判断,循环执行某些逻辑,周而反复,这些是时间. 那么一个算法有多好, ...
- unity3d的键盘和鼠标输入
一.键盘的输入 •GetKey,GetKeyDown,GetKeyUp三个方法分别获取用户键盘按键的输入 1. GetKey:用户长按按键有效: bool down = Input.GetKeyDow ...
- git以及gitHub的使用说明书
一.使用说明 1.Git与github的功能: Git是世界上最先进的分布式版本控制系统,也就是用来记录你的项目代码历史变更信息的工具:github就是用来存储你的代码以及变更信息的云端平台: 2.优 ...
- E. 数字串
给你一个长度为 n 的数字串,找出其中位数不超过15位的不包含前导0和后导0的数 x ,使得 x+f(x) 是一个回文数,其中 f(x) 表示将 x 反转过来的数. 输入格式 多组输入,处理到文件结束 ...
- calculator.py
代码如下: #计算器类 class Count: def __init__(self, a, b): self.a = int(a) self.b = int(b) #计算器加法 def add(se ...
- Numpy学习-(1)
记录我学习Numpy过程 1. 介绍 (1)NumPy(Numerical Python) 是 Python 语言的一个扩展程序库,支持大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库 ...
- Mysql使用终端操作数据库
使用终端操作数据库 1.如何查看有什么数据库? show databases; 2.如何选择数据库? use databasesName; 3. ...
- 新的知识点来了-ES6 Proxy代理 和 去银行存款有什么关系?
ES给开发者提供了一个新特性:Proxy,就是代理的意思.也就是我们这一节要介绍的知识点. 以前,ATM还没有那么流行的时候(暴露年纪),我们去银行存款或者取款的时候,需要在柜台前排队,等柜台工作人员 ...
- 编程语言千千万,为什么学习Python的占一半?
如果让你从数百种的编程语言中选择一个入门语言?你会选择哪一个? 是应用率最高.长期霸占排行榜的常青藤 Java?是易于上手,难以精通的 C?还是在游戏和工具领域仍占主流地位的 C++?亦或是占据 Wi ...
- 0day学习笔记(3)Windows定位API引起的惨案(原理)
段选择器FS与TEB WinNT内核下内存采用保护模式,段寄存器的意义与实模式汇编下的意义不同.另外,FS存的是段选择子,而不是实模式下的高16位基地址. FS寄存器指向当前活动线程的TEB结构(线程 ...