新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署
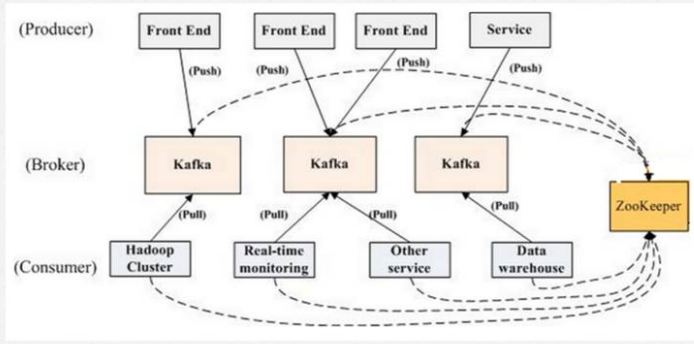
Kafka是由LinkedIn开发的一个分布式的消息系统,使用Scala编写,它以可水平扩展和高吞吐率而被广泛使用。目前越来越多的开源分布式处理系统如Cloudera、Apache Storm、Spark都支持与Kafka集成。
1.下载Kafka并安装
1)下载Apache版本的Kafka。
2)下载Cloudera版本的Kafka。
3)这里选择下载Apache版本的kafka_2.11-0.8.2.1.tgz ,然后上传至bigdata-pro01.kfk.com节点/opt/softwares/目录下
4)解压Kafka
tar -zxf kafka_2.11-0.8.2.1.tgz -C /opt/modules/
2.Kafka集群配置
1)配置server.properties文件
vi kafka_2.11-0.8.2.1
#节点唯一标识
broker.id=0
#默认端口号
port=9092
#主机名绑定
host.name=bigdata-pro01.kfk.com
#Kafka数据目录
log.dirs=/opt/modules/kafka_2.11-0.8.2.1/tmp/kafka-logs
#配置Zookeeper
zookeeper.connect=bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,bigdata-pro03.kfk.com:2181
2)配置zookeeper.properties文件
vi zookeeper.properties
#Zookeeper的数据存储路径与Zookeeper集群配置保持一致
dataDir=/opt/modules/zookeeper-3.4.5-cdh5.10.0/zkData
3)配置consumer.properties文件
#配置Zookeeper地址
zookeeper.connect=bigdata-pro01.kfk.com:2181,bigdata-pro02.kfk.com:2181,bigdata-pro03.kfk.com:2181
4)配置producer.properties文件
#配置Kafka集群地址
metadata.broker.list=bigdata-pro01.kfk.com:9092,bigdata-pro02.kfk.com:9092,bigdata-pro03.kfk.com:9092
5)Kafka分发到其他节点
scp -r kafka_2.11-0.8.2.1 bigdata-pro02.kfk.com:/opt/modules/
scp -r kafka_2.11-0.8.2.1 bigdata-pro03.kfk.com:/opt/modules/
6)修改另外两个节点的server.properties
#bigdata-pro02.kfk.com节点
broker.id=1
host.name=bigdata-pro02.kfk.com
#bigdata-pro03.kfk.com节点
broker.id=2
host.name=bigdata-pro03.kfk.com
3.启动Kafka集群并进行测试
1)各个节点启动Zookeeper集群
bin/zkServer.sh start
2)各个节点启动Kafka集群
bin/kafka-server-start.sh config/server.properties &
3)创建topic
bin/kafka-topics.sh --zookeeper localhost:2181 --create --topic test --replication-factor 1 --partitions 1
4)查看topic列表
bin/kafka-topics.sh --zookeeper localhost:2181 --list
5)生产者生成数据
bin/kafka-console-producer.sh --broker-list localhost:9092 --topic test
6)消费者消费数据
bin/kafka-console-consumer.sh --zookeeper localhost:2181 --topic test --from-beginning
新闻网大数据实时分析可视化系统项目——7、Kafka分布式集群部署的更多相关文章
- 新闻网大数据实时分析可视化系统项目——2、linux环境准备与设置
1.Linux系统常规设置 1)设置ip地址 使用界面修改ip比较方便,如果Linux没有安装操作界面,需要使用命令:vi /etc/sysconfig/network-scripts/ifcfg-e ...
- 新闻网大数据实时分析可视化系统项目——6、HBase分布式集群部署与设计
HBase是一个高可靠.高性能.面向列.可伸缩的分布式存储系统,利用Hbase技术可在廉价PC Server上搭建 大规模结构化存储集群. HBase 是Google Bigtable 的开源实现,与 ...
- 新闻网大数据实时分析可视化系统项目——18、Spark SQL快速离线数据分析
1.Spark SQL概述 1)Spark SQL是Spark核心功能的一部分,是在2014年4月份Spark1.0版本时发布的. 2)Spark SQL可以直接运行SQL或者HiveQL语句 3)B ...
- 新闻网大数据实时分析可视化系统项目——13、Cloudera HUE大数据可视化分析
1.Hue 概述及版本下载 1)概述 Hue是一个开源的Apache Hadoop UI系统,最早是由Cloudera Desktop演化而来,由Cloudera贡献给开源社区,它是基于Python ...
- 新闻网大数据实时分析可视化系统项目——4、Zookeeper分布式集群部署
ZooKeeper 是一个针对大型分布式系统的可靠协调系统:它提供的功能包括:配置维护.名字服务.分布式同步.组服务等: 它的目标就是封装好复杂易出错的关键服务,将简单易用的接口和性能高效.功能稳定的 ...
- 新闻网大数据实时分析可视化系统项目——19、Spark Streaming实时数据分析
1.Spark Streaming功能介绍 1)定义 Spark Streaming is an extension of the core Spark API that enables scalab ...
- 新闻网大数据实时分析可视化系统项目——14、Spark2.X环境准备、编译部署及运行
1.Spark概述 Spark 是一个用来实现快速而通用的集群计算的平台. 在速度方面, Spark 扩展了广泛使用的 MapReduce 计算模型,而且高效地支持更多计算模式,包括交互式查询和流处理 ...
- 新闻网大数据实时分析可视化系统项目——12、Hive与HBase集成进行数据分析
(一)Hive 概述 (二)Hive在Hadoop生态圈中的位置 (三)Hive 架构设计 (四)Hive 的优点及应用场景 (五)Hive 的下载和安装部署 1.Hive 下载 Apache版本的H ...
- 新闻网大数据实时分析可视化系统项目——5、Hadoop2.X HA架构与部署
1.HDFS-HA架构原理介绍 hadoop2.x之后,Clouera提出了QJM/Qurom Journal Manager,这是一个基于Paxos算法实现的HDFS HA方案,它给出了一种较好的解 ...
随机推荐
- 容器远程访问vnc--CentOS 6.8安装和配置VNC
对于用惯了WIN系统的朋友来说,没有图形化操作界面的Linux用起来实在太难受了.实际上,Linux也是有图形化操作界面的,这就是VNC.接下来本文将告诉大家如何在CentOS 6.8下安装和配置 V ...
- 给博客页面添加 live2d 小萝莉
添加依赖 在页脚HTML代码的地方添加下面的代码: <script src="https://eqcn.ajz.miesnfu.com/wp-content/plugins/wp-3d ...
- numpy.eye() 生成对角矩阵
numpy.eye(N,M=None, k=0, dtype=<type 'float'>) 关注第一个第三个参数就行了 第一个参数:输出方阵(行数=列数)的规模,即行数或列数 第三个参数 ...
- sql 中u.*什么意思
i.* i是一个表的别名,i.*是这个表的所有列,比如 select i.* from customer i; 相当于 select id,name,password from customer;
- Cisco Umbrella WLAN
Cisco Umbrella WLAN在域名系统(DNS)级别提供云交付网络安全服务,可自动检测已知和紧急威胁. 此功能允许您在实际恶意攻击之前阻止托管恶意软件,僵尸网络和网络钓鱼的站点. Cisco ...
- 杭电 2136 Largest prime factor(最大素数因子的位置)
Largest prime factor Time Limit: 5000/1000 MS (Java/Others) Memory Limit: 32768/32768 K (Java/Oth ...
- Update(stage3):第1节 redis组件:1 - 3、web发展历史以及redis简介
Redis课程教案 1. NoSQL数据库的发展历史简介 1.web系统的变迁历史 web1.0时代简介 基本上就是一些简单的静态页面的渲染,不会涉及到太多的复杂业务逻辑,功能简单单一,基本上服务器性 ...
- 【Fine学习笔记】python 文件l操作方法整理
python脚本可以对excel进行创建.读.写.保存成指定文件名,保存到指定路径的操作.整理了以下处理方法: 首先区别几个操作方式: "r" 以读方式打开,只能读文件 , 如 ...
- Nginx安装部署!
安装Nginx方法一:利用u盘导入Nginx软件包 二nginx -t 用于检测配置文件语法 如下报错1:配置文件43行出现错误 [root@www ~]# nginx -tnginx: [emerg ...
- Jquery 动态交换两个div位置并添加Css动画效果
前端网页开发中我们经常会遇到需要动态置换两个DIV元素的位置,常见的思路大多是不考虑原始位置,直接采用append或者appendTo方式将两元素进行添加,该法未考虑原始位置,仅会添加为元素的最后一子 ...