hbase0.96与hive0.12整合高可靠文档及问题总结
本文链接:http://www.aboutyun.com/thread-7881-1-1.html
问题导读:
1.hive安装是否需要安装mysql?
2.hive是否分为客户端和服务器端?
3.hive的元数据库有哪两种?
4.hive与hbase整合的关键是什么?
5.hive的安装是否必须安装hadoop?
6.hive与hbase整合需要做哪些准备工作?

网上有很多资料,看到大部分都是一致的,看到一篇国外的文章,原来都是翻译的,并没有经过实践。这里记录一下实践的过程。
本篇是在:
hadoop2.2完全分布式最新高可靠安装文档
http://www.aboutyun.com/thread-7684-1-1.html
hbase 0.96整合到hadoop2.2三个节点全分布式安装高可靠文档
http://www.aboutyun.com/thread-7746-1-1.html
基础上的一个继续:
因为derby数据库使用的局限性,我们采用mysql作为元数据库。
derby存在什么缺陷
1.derby不能多个客户端登录
2.derby登录必须在相同目录下,否则可能会找不到所创建的表。
比如在/hive目录下启动hive程序,那么所创建的表就会存储在/hive下面保存。如果在/home下面,所创建的表就会在/home下面保存。这样导致初学者摸不着头脑。如果还不是不太明白可以,可以参考
-----------
hive使用derby作为元数据库找达到所创建表的原因
http://www.aboutyun.com/thread-7803-1-1.html
-----------
下面我们开始安装:
1.下载hivehive
链接: http://pan.baidu.com/s/1eQw0o50 密码: mgy6
2. 安装:
tar zxvf hive-0.12.0.tar.gz
重命令名为:hive文件夹
达到如下效果:
<ignore_js_op>
3. 替换jar包,与hbase0.96和hadoop2.2版本一致
由于我们下载的hive是基于hadoop1.3和hbase0.94的,所以必须进行替换,因为我们的hbse0.96是基于hadoop2.2的,所以我们必须先解决hive的hadoop版本问题,目前我们从官网下载的hive都是用1.几的版本编译的,因此我们需要自己下载源码来用hadoop2.X的版本重新编译hive,这个过程也很简单,只需要如下步骤:
(1)进入/usr/hive/lib
<ignore_js_op>
上面只是截取了一部分:
(2)同步hbase的版本
先cd到hive0.12.0/lib下,将hive-0.12.0/lib下hbase-0.94开头的那两个jar包删掉,然后从/home/hadoop/hbase-0.96.0-hadoop2/lib下hbase开头的包都拷贝过来
find /usr/hbase/hbas/lib -name "hbase*.jar"|xargs -i cp {} ./
<ignore_js_op>![]()
(3)基本的同步完成了
重点检查下zookeeper和protobuf的jar包是否和hbase保持一致,如果不一致,
拷贝protobuf.**.jar和zookeeper-3.4.5.jar到hive/lib下。
(4)用mysql当原数据库,
找一个mysql的jdbcjar包mysql-connector-java-5.1.10-bin.jar也拷贝到hive-0.12.0/lib下
可以通过下面命令来查找是否存在
<ignore_js_op>
如果不存在则下载:
链接: http://pan.baidu.com/s/1gdCDoGj 密码: 80yl
--------------------------------------------------------------------------
注意 mysql-connector-java-5.1.10-bin.jar
修改权限为777 (chmod 777 mysql-connector-java-5.1.10-bin.jar)
--------------------------------------------------------------------------
还有,看一下hbase与hive的通信包是否存在:
<ignore_js_op>
可以通过下面命令:
aboutyun@master:/usr/hive/lib$ find -name hive-hbase-handler*
./hive-hbase-handler-0.13.0-SNAPSHOT.jar
不存在则下载:
链接: http://pan.baidu.com/s/1gd9p0Fh 密码: 94g1
4. 安装mysql
• Ubuntu 采用apt-get安装
• sudo apt-get install mysql-server
• 建立数据库hive
• create database hivemeta
• 创建hive用户,并授权
• grant all on hive.* to hive@'%' identified by 'hive';
• flush privileges;
对于musql的安装不熟悉,可以参考:
Ubuntu下面卸载以及安装mysql
http://www.aboutyun.com/thread-7788-1-1.html
-------------------------------------------
上面命令解释一下:
• sudo apt-get install mysql-server安装数据服务器,如果想尝试通过其他客户端远程连接,则还需要安装mysql-client
• create database hivemeta
这个使用来存储hive元数据,所创建的数据库
• grant all on hive.* to hive@'%' identified by 'hive'; 这个是授权,还是比较重要的,否则hive客户端远程连接会失败
里面的内容不要照抄:需要根据自己的情况来修改。上面的用户名和密码都为hive。
如果连接不成功尝试使用root用户
- grant all on hive.* to 'root'@'%'identified by '123';
- flush privileges;
复制代码
------------------------------------------
4. 修改hive-site文件配置:
<ignore_js_op>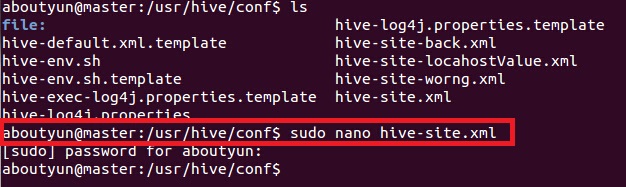
下面配置需要注意的是:
(1)使用的是mysql的root用户,密码为123,如果你是用的hive,把用户名和密码该为hive即可:
<ignore_js_op>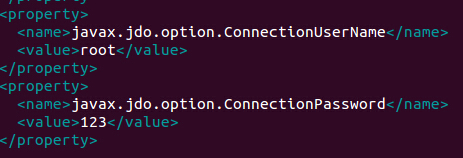
(2)hdfs新建文件并授予权限
<ignore_js_op>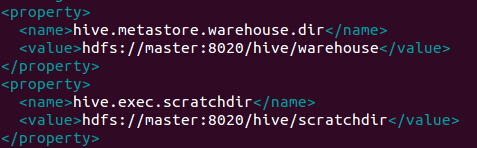
对于上面注意
bin/hadoop fs -mkdir /hive/warehouse
bin/hadoop fs -mkdir /hive/scratchdir
bin/hadoop fs -chmod g+w /hive/warehouse
bin/hadoop fs -chmod g+w /hive/scratchdir
(3)hive.aux.jars.path切忌配置正确
不能有换行或则空格。特别是换行,看到很多文章都把他们给分开了,这对很多新手是一个很容易掉进去的陷阱。
- <property>
- <name>hive.aux.jars.path</name>
- <value>file:///usr/hive/lib/hive-hbase-handler-0.13.0-SNAPSHOT.jar,file:///usr/hive/lib/protobuf-java-2.5.0.jar,file:///usr/hive/lib/hbase-client-0.96.0-hadoop2.jar,file:///usr/hive/lib/hbase-common-0.96.0-hadoop2.jar,file:///usr/hive/lib/zookeeper-3.4.5.jar,file:///usr/hive/lib/guava-11.0.2.jar</value>
- </property>
复制代码
<ignore_js_op>
上面问题解决,把下面内容放到hive-site文件即可
--------------------------------
这里介绍两种配置方式,一种是远程配置,一种是本地配置。最好选择远程配置
远程配置
- <configuration>
- <property>
- <name>hive.metastore.warehouse.dir</name>
- <value>hdfs://master:8020/hive/warehouse</value>
- </property>
- <property>
- <name>hive.exec.scratchdir</name>
- <value>hdfs://master:8020/hive/scratchdir</value>
- </property>
- <property>
- <name>hive.querylog.location</name>
- <value>/usr/hive/logs</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionURL</name>
- <value>jdbc:mysql://172.16.77.15:3306/hiveMeta?createDatabaseIfNotExist=true</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionDriverName</name>
- <value>com.mysql.jdbc.Driver</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionUserName</name>
- <value>hive</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionPassword</name>
- <value>hive</value>
- </property>
- <property>
- <name>hive.aux.jars.path</name>
- <value>file:///usr/hive/lib/hive-hbase-handler-0.13.0-SNAPSHOT.jar,file:///usr/hive/lib/protobuf-java-2.5.0.jar,file:///usr/hive/lib/hbase-client-0.96.0-hadoop2.jar,file:///usr/hive/lib/hbase-common-0.96.0-hadoop2.jar,file:///usr/hive/lib/zookeeper-3.4.5.jar,file:///usr/hive/lib/guava-11.0.2.jar</value>
- </property>
- <property>
- <name>hive.metastore.uris</name>
- <value>thrift://172.16.77.15:9083</value>
- </property>
- </configuration>
复制代码
本地配置:
- <configuration>
- <property>
- <name>hive.metastore.warehouse.dir</name>
- <value>/user/hive_remote/warehouse</value>
- </property>
- <property>
- <name>hive.metastore.local</name>
- <value>true</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionURL</name>
- <value>jdbc:mysql://localhost/hive_remote?createDatabaseIfNotExist=true</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionDriverName</name>
- <value>com.mysql.jdbc.Driver</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionUserName</name>
- <value>root</value>
- </property>
- <property>
- <name>javax.jdo.option.ConnectionPassword</name>
- <value>123</value>
- </property>
- </configuration>
复制代码
-------------------------------------------------------------------------------------
5. 修改其它配置:
1.修改hadoop的hadoop-env.sh(否则启动hive汇报找不到类的错误)
<ignore_js_op>
2.修改$HIVE_HOME/bin的hive-config.sh,增加以下三行
<ignore_js_op>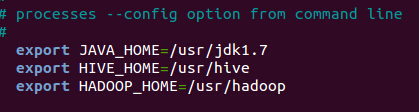

首先说一些遇到的各种问题
1.遇到的问题
问题1:元数据库未启动
这里首先概括一下,会遇到的问题。首先需要启动元数据库,通过下面命令:
(1)hive --service metastore
(2)hive --service metastore -hiveconf hive.root.logger=DEBUG,console
注释:
-hiveconf hive.root.logger=DEBUG,console命令的含义是进入debug模式,便于寻找错误
如果不启用元数据库,而是使用下面命令
- hive
复制代码
你会遇到下面错误
- Exception in thread "main" java.lang.RuntimeException: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
- at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:295)
- at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:679)
- at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:623)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
- Caused by: java.lang.RuntimeException: Unable to instantiate org.apache.hadoop.hive.metastore.HiveMetaStoreClient
- at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1345)
- at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:62)
- at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:72)
- at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:2420)
- at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:2432)
- at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:289)
- ... 7 more
- Caused by: java.lang.reflect.InvocationTargetException
- at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
- at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
- at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
- at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1343)
- ... 12 more
- Caused by: MetaException(message:Could not connect to meta store using any of the URIs provided. Most recent failure: org.apache.thrift.transport.TTransportException:
- java.net.ConnectException: Connection refused
- at org.apache.thrift.transport.TSocket.open(TSocket.java:185)
- at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.open(HiveMetaStoreClient.java:288)
- at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:169)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance0(Native Method)
- at sun.reflect.NativeConstructorAccessorImpl.newInstance(NativeConstructorAccessorImpl.java:57)
- at sun.reflect.DelegatingConstructorAccessorImpl.newInstance(DelegatingConstructorAccessorImpl.java:45)
- at java.lang.reflect.Constructor.newInstance(Constructor.java:526)
- at org.apache.hadoop.hive.metastore.MetaStoreUtils.newInstance(MetaStoreUtils.java:1343)
- at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.<init>(RetryingMetaStoreClient.java:62)
- at org.apache.hadoop.hive.metastore.RetryingMetaStoreClient.getProxy(RetryingMetaStoreClient.java:72)
- at org.apache.hadoop.hive.ql.metadata.Hive.createMetaStoreClient(Hive.java:2420)
- at org.apache.hadoop.hive.ql.metadata.Hive.getMSC(Hive.java:2432)
- at org.apache.hadoop.hive.ql.session.SessionState.start(SessionState.java:289)
- at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:679)
- at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:623)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
- Caused by: java.net.ConnectException: Connection refused
- at java.net.PlainSocketImpl.socketConnect(Native Method)
- at java.net.AbstractPlainSocketImpl.doConnect(AbstractPlainSocketImpl.java:339)
- at java.net.AbstractPlainSocketImpl.connectToAddress(AbstractPlainSocketImpl.java:200)
- at java.net.AbstractPlainSocketImpl.connect(AbstractPlainSocketImpl.java:182)
- at java.net.SocksSocketImpl.connect(SocksSocketImpl.java:392)
- at java.net.Socket.connect(Socket.java:579)
- at org.apache.thrift.transport.TSocket.open(TSocket.java:180)
- ... 19 more
- )
- at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.open(HiveMetaStoreClient.java:334)
- at org.apache.hadoop.hive.metastore.HiveMetaStoreClient.<init>(HiveMetaStoreClient.java:169)
- ... 17 more
复制代码
问题2:元数据库启动状态是什么样子的
<ignore_js_op>
- hive --service metastore
- Starting Hive Metastore Server
- 14/05/27 20:14:51 INFO Configuration.deprecation: mapred.input.dir.recursive is deprecated. Instead, use mapreduce.input.fileinputformat.input.dir.recursive
- 14/05/27 20:14:51 INFO Configuration.deprecation: mapred.max.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.maxsize
- 14/05/27 20:14:51 INFO Configuration.deprecation: mapred.min.split.size is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize
- 14/05/27 20:14:51 INFO Configuration.deprecation: mapred.min.split.size.per.rack is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.rack
- 14/05/27 20:14:51 INFO Configuration.deprecation: mapred.min.split.size.per.node is deprecated. Instead, use mapreduce.input.fileinputformat.split.minsize.per.node
- 14/05/27 20:14:51 INFO Configuration.deprecation: mapred.reduce.tasks is deprecated. Instead, use mapreduce.job.reduces
- 14/05/27 20:14:51 INFO Configuration.deprecation: mapred.reduce.tasks.speculative.execution is deprecated. Instead, use mapreduce.reduce.speculative
复制代码
刚开始遇到这种情况,我知道是因为可能没有配置正确,这个耗费了很长时间,一直没有找到正确的解决方案。当再次执行
hive --service metastore
命令的时候报4083端口被暂用: 报错如下红字部分。表示9083端口已经被暂用,也就是说客户端已经和主机进行了通信,当我在进行输入hive命令的时候,进入下面图1界面
<ignore_js_op>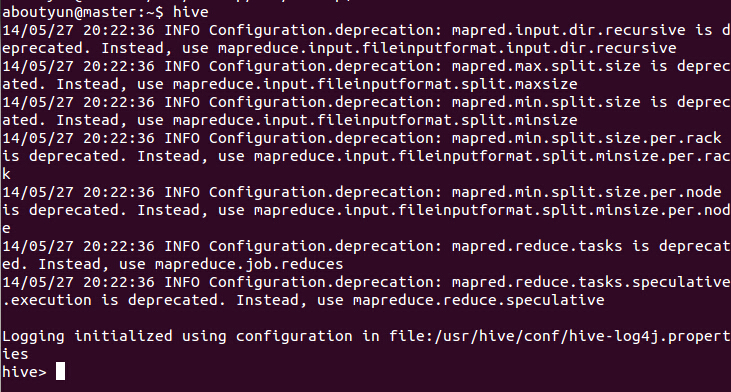
图1
- Could not create ServerSocket on address 0.0.0.0/0.0.0.0:9083.
- at org.apache.thrift.transport.TServerSocket.<init>(TServerSocket.java:93)
- at org.apache.thrift.transport.TServerSocket.<init>(TServerSocket.java:75)
- at org.apache.hadoop.hive.metastore.TServerSocketKeepAlive.<init>(TServerSocketKeepAlive.java:34)
- at org.apache.hadoop.hive.metastore.HiveMetaStore.startMetaStore(HiveMetaStore.java:4291)
- at org.apache.hadoop.hive.metastore.HiveMetaStore.main(HiveMetaStore.java:4248)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
- Exception in thread "main" org.apache.thrift.transport.TTransportException: Could not create ServerSocket on address 0.0.0.0/0.0.0.0:9083.
- at org.apache.thrift.transport.TServerSocket.<init>(TServerSocket.java:93)
- at org.apache.thrift.transport.TServerSocket.<init>(TServerSocket.java:75)
- at org.apache.hadoop.hive.metastore.TServerSocketKeepAlive.<init>(TServerSocketKeepAlive.java:34)
- at org.apache.hadoop.hive.metastore.HiveMetaStore.startMetaStore(HiveMetaStore.java:4291)
- at org.apache.hadoop.hive.metastore.HiveMetaStore.main(HiveMetaStore.java:4248)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
复制代码
对于端口的暂用,可以采用下面命令杀掉进程
- netstat -ap|grep 4083
复制代码
上面主要的作用是查出暂用端口的进程id,然后使用下面命令杀掉进程即可
- kill -9 进程号
复制代码
详细可以查看下面内容:
使用配置hadoop中常用的Linux命令
问题3:hive.aux.jars.path配置中含有看换行或则空格,报错如下
错误表现1:/usr/hive/lib/hbase-client-0.96.0-
hadoop2.jar
整个路径错位,导致系统不能识别,这个错位,其实就是换行。
- FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
- java.io.FileNotFoundException: File does not exist: hdfs://hydra0001/opt/module/hive-0.10.0-cdh4.3.0/lib/hive-builtins-0.10.0-cdh4.3.0.jar
- 2014-05-24 19:32:06,563 ERROR exec.Task (SessionState.java:printError(440)) - Job Submission failed with exception 'java.io.FileNotFoundException(File file:/usr/hive/lib/hbase-client-0.96.0-
- hadoop2.jar does not exist)'
- java.io.FileNotFoundException: File file:/usr/hive/lib/hbase-client-0.96.0-
- hadoop2.jar does not exist
- at org.apache.hadoop.fs.RawLocalFileSystem.getFileStatus(RawLocalFileSystem.java:520)
- at org.apache.hadoop.fs.FilterFileSystem.getFileStatus(FilterFileSystem.java:398)
- at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:337)
- at org.apache.hadoop.fs.FileUtil.copy(FileUtil.java:289)
- at org.apache.hadoop.mapreduce.JobSubmitter.copyRemoteFiles(JobSubmitter.java:139)
- at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:212)
- at org.apache.hadoop.mapreduce.JobSubmitter.copyAndConfigureFiles(JobSubmitter.java:300)
- at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:387)
- at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1268)
- at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1265)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
- at org.apache.hadoop.mapreduce.Job.submit(Job.java:1265)
- at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:562)
- at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:557)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
- at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:557)
- at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:548)
- at org.apache.hadoop.hive.ql.exec.mr.ExecDriver.execute(ExecDriver.java:424)
- at org.apache.hadoop.hive.ql.exec.mr.MapRedTask.execute(MapRedTask.java:136)
- at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:152)
- at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:65)
- at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1481)
- at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1258)
- at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1092)
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:932)
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:922)
- at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:268)
- at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:220)
- at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:422)
- at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:790)
- at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:684)
- at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:623)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
- 2014-05-24 19:32:06,571 ERROR ql.Driver (SessionState.java:printError(440)) - FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
复制代码
错误表现2:
- <property>
- <name>hive.aux.jars.path</name>
- <value>
- file:///usr/hive/lib/hive-hbase-handler-0.13.0-SNAPSHOT.jar,
- file:///usr/hive/lib/protobuf-java-2.5.0.jar,
- file:///usr/hive/lib/hbase-client-0.96.0-hadoop2.jar,
- file:///usr/hive/lib/hbase-common-0.96.0-hadoop2.jar,
- file:///usr/hive/lib/zookeeper-3.4.5.jar,
- file:///usr/hive/lib/guava-11.0.2.jar</value>
- </property>
- <property>
复制代码
上面看那上去很整洁,但是如果直接复制到配置文件中,就会产生下面错误。
- Caused by: java.net.URISyntaxException: Illegal character in scheme name at index 0:
- file:///usr/hive/lib/protobuf-java-2.5.0.jar
- at java.net.URI$Parser.fail(URI.java:2829)
- at java.net.URI$Parser.checkChars(URI.java:3002)
- at java.net.URI$Parser.checkChar(URI.java:3012)
- at java.net.URI$Parser.parse(URI.java:3028)
- at java.net.URI.<init>(URI.java:753)
- at org.apache.hadoop.fs.Path.initialize(Path.java:203)
- ... 37 more
- Job Submission failed with exception 'java.lang.IllegalArgumentException(java.net.URISyntaxException: Illegal character in scheme name at index 0:
- file:///usr/hive/lib/protobuf-java-2.5.0.jar)'
- FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
复制代码

验证hive与hbase的整合:
一、启动hbase与hive
启动hbase
- hbase shell
复制代码
<ignore_js_op>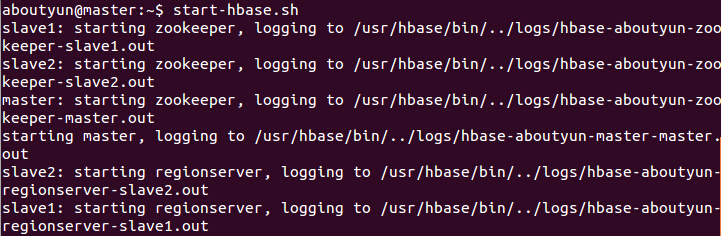
启动hive
(1)启动元数据库
<ignore_js_op>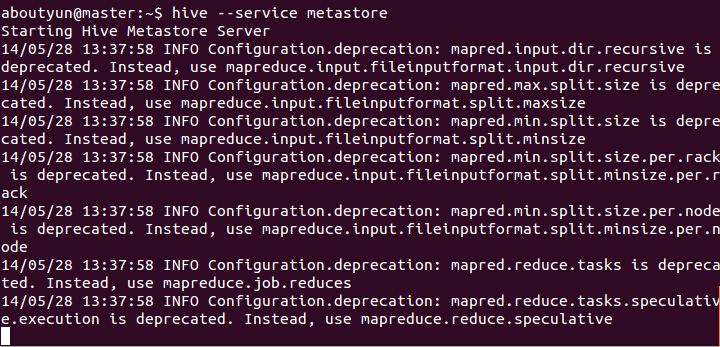
- CREATE TABLE hbase_table_1(key int, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") TBLPROPERTIES ("hbase.table.name" = "xyz");
复制代码
上面的含义是在hive中建表hbase_table_1,通过org.apache.hadoop.hive.hbase.HBaseStorageHandler这个类映射,在hbase建立与之对应的xyz表。
(1)执行这个语句之前:
首先查看hbase与hive:
hbase为空:
<ignore_js_op>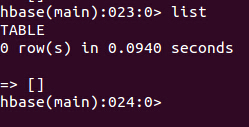
hive为空
<ignore_js_op>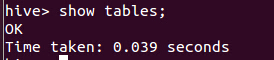
(2)执行
- CREATE TABLE hbase_table_1(key int, value string) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler' WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,cf1:val") TBLPROPERTIES ("hbase.table.name" = "xyz");
复制代码
<ignore_js_op>
(3)对比发生变化
hbase显示新建表xyz
<ignore_js_op>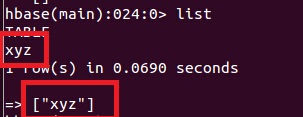
hive显示新建表hbase_table_1
<ignore_js_op>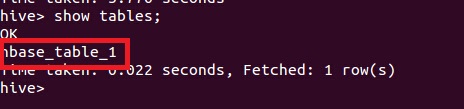
三、验证整合,在hbase插入表
(1)通过hbase添加数据
在hbase中插入一条记录:
- put 'xyz','10001','cf1:val','www.aboutyun.com'
复制代码
<ignore_js_op>
分别查看hbase与hive表发生的变化:
(1)hbase变化
<ignore_js_op>
(2)hive变化
<ignore_js_op>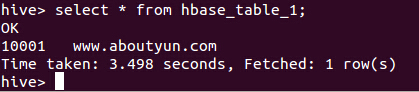
(2)通过hive添加数据
对于网上流行的通过pokes表,插入这里没有执行成功,通过网上查询,可能是hive0.12的一个bug.详细可以查看:
- INSERT OVERWRITE TABLE hbase_table_1 SELECT * FROM pokes;
- Total MapReduce jobs = 1
- Launching Job 1 out of 1
- Number of reduce tasks is set to 0 since there's no reduce operator
- java.lang.IllegalArgumentException: Property value must not be null
- at com.google.common.base.Preconditions.checkArgument(Preconditions.java:88)
- at org.apache.hadoop.conf.Configuration.set(Configuration.java:810)
- at org.apache.hadoop.conf.Configuration.set(Configuration.java:792)
- at org.apache.hadoop.hive.ql.exec.Utilities.copyTableJobPropertiesToConf(Utilities.java:1996)
- at org.apache.hadoop.hive.ql.exec.FileSinkOperator.checkOutputSpecs(FileSinkOperator.java:864)
- at org.apache.hadoop.hive.ql.io.HiveOutputFormatImpl.checkOutputSpecs(HiveOutputFormatImpl.java:67)
- at org.apache.hadoop.mapreduce.JobSubmitter.checkSpecs(JobSubmitter.java:458)
- at org.apache.hadoop.mapreduce.JobSubmitter.submitJobInternal(JobSubmitter.java:342)
- at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1268)
- at org.apache.hadoop.mapreduce.Job$10.run(Job.java:1265)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
- at org.apache.hadoop.mapreduce.Job.submit(Job.java:1265)
- at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:562)
- at org.apache.hadoop.mapred.JobClient$1.run(JobClient.java:557)
- at java.security.AccessController.doPrivileged(Native Method)
- at javax.security.auth.Subject.doAs(Subject.java:415)
- at org.apache.hadoop.security.UserGroupInformation.doAs(UserGroupInformation.java:1491)
- at org.apache.hadoop.mapred.JobClient.submitJobInternal(JobClient.java:557)
- at org.apache.hadoop.mapred.JobClient.submitJob(JobClient.java:548)
- at org.apache.hadoop.hive.ql.exec.mr.ExecDriver.execute(ExecDriver.java:424)
- at org.apache.hadoop.hive.ql.exec.mr.MapRedTask.execute(MapRedTask.java:136)
- at org.apache.hadoop.hive.ql.exec.Task.executeTask(Task.java:152)
- at org.apache.hadoop.hive.ql.exec.TaskRunner.runSequential(TaskRunner.java:65)
- at org.apache.hadoop.hive.ql.Driver.launchTask(Driver.java:1481)
- at org.apache.hadoop.hive.ql.Driver.execute(Driver.java:1258)
- at org.apache.hadoop.hive.ql.Driver.runInternal(Driver.java:1092)
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:932)
- at org.apache.hadoop.hive.ql.Driver.run(Driver.java:922)
- at org.apache.hadoop.hive.cli.CliDriver.processLocalCmd(CliDriver.java:268)
- at org.apache.hadoop.hive.cli.CliDriver.processCmd(CliDriver.java:220)
- at org.apache.hadoop.hive.cli.CliDriver.processLine(CliDriver.java:422)
- at org.apache.hadoop.hive.cli.CliDriver.executeDriver(CliDriver.java:790)
- at org.apache.hadoop.hive.cli.CliDriver.run(CliDriver.java:684)
- at org.apache.hadoop.hive.cli.CliDriver.main(CliDriver.java:623)
- at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
- at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:57)
- at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
- at java.lang.reflect.Method.invoke(Method.java:606)
- at org.apache.hadoop.util.RunJar.main(RunJar.java:212)
- Job Submission failed with exception 'java.lang.IllegalArgumentException(Property value must not be null)'
- FAILED: Execution Error, return code 1 from org.apache.hadoop.hive.ql.exec.mr.MapRedTask
复制代码
网上找了很多资料,这个可能是一个bug,在hive0.13.0已经修复。
详细见:
https://issues.apache.org/jira/browse/HIVE-5515
hbase0.96与hive0.12整合高可靠文档及问题总结的更多相关文章
- _00018 Hadoop-2.2.0 + Hbase-0.96.2 + Hive-0.13.1 分布式环境整合,Hadoop-2.X使用HA方式
博文作者:妳那伊抹微笑 itdog8 地址链接 : http://www.itdog8.com(个人链接) 博客地址:http://blog.csdn.net/u012185296 个性签名:世界上最 ...
- ubuntu12.04+hadoop2.2.0+zookeeper3.4.5+hbase0.96.2+hive0.13.1伪分布式环境部署
目录: 一.hadoop2.2.0.zookeeper3.4.5.hbase0.96.2.hive0.13.1都是什么? 二.这些软件在哪里下载? 三.如何安装 1.安装JDK 2.用parallel ...
- Hadoop-2.2.0 + Hbase-0.96.2 + Hive-0.13.1(转)
From:http://www.itnose.net/detail/6065872.html # 需要软件 Hadoop-2.2.0(目前Apache官网最新的Stable版本) Hbase-0.96 ...
- ABBYY FineReader 12 能够识别哪些文档语言
ABBYY FineReader可以识别单语言文本和多语言文本(如使用两种及以上语言).对于多语言文本,需要选择多种识别语言. 要为文本指定一种 OCR 语言,请从主工具栏或任务窗口的文档语言下拉列表 ...
- Spark Streaming + Flume整合官网文档阅读及运行示例
1,基于Flume的Push模式(Flume-style Push-based Approach) Flume被用于在Flume agents之间推送数据.在这种方式下,Spark Stre ...
- Springboot中整合knife4j接口文档
在项目开发过程中,web项目的前后端分离开发,APP开发,需要由前端后端工程师共同定义接口,编写接口文档,之后大家都根据这个接口文档进行开发. 什么是knife4j 简单说knife4j就swagge ...
- Cacti+nagios 整合监控部署文档
目录 Cacti+nagios监控部署步骤... 2 一.Cacti安装... 2 1需要安装的依赖软件包:... 2 2安装rrdtool 2 3启动数据库和httpd服务... 3 4将serve ...
- 某站出品2016织梦CMS进阶教程共12课(附文档+工具)
此为广告商内容使用最新版的dede cms建站 V5.7 sp1,经常注意后台的升级信息哦!一.安装DEDE的时候数据库的表前缀,最好改一下,不用dedecms默认的前缀dede_,随便一个名称即可. ...
- 2015.12.14 MDI(多文档窗口结构)设置基本解决,折腾一天,部分解决存在已久的问题。但效果仍不如临时航线的MDI窗体结构。
创建从一个窗口弹出多个子窗口的结构叫MDI窗体结构 如果不按MDI结构管理,最简单的做法是: 在窗体A上添加菜单或按钮,在菜单或按钮事件中添加弹出B窗体代码: B b = new B(); b.sho ...
随机推荐
- Hardwood Species
http://poj.org/problem?id=2418 #include<cstdio> #include<cstring> #include<string> ...
- maven3常用命令\创建Project
转自 http://blog.csdn.net/edward0830ly/article/details/8748986 ------------------------------maven3常用命 ...
- Discuz模版与插件 安装时提示“对不起,您安装的不是正版应用...”解决方法
关于出现“对不起,您安装的不是正版应用..”的解决办法 有些插件和风格在安装时出现不能安装的现象,出现以下提示: 对不起,您安装的不是正版应用,安装程序无法继续执行 点击这里安 ...
- 选择排序的openMP实现
// test.cpp : 定义控制台应用程序的入口点. // #include "stdafx.h" #include <stdio.h> #include < ...
- HeadFirst设计模式之单例模式
一. 1.The Singleton Pattern ensures a class has only one instance, and provides a global point of acc ...
- git删除中文文件
git中出现如下代码时,是因为文件中包含中文.而且我们也无法用 git rm name 命令来删除该文件. deleted: "chrome_plugin/source_file/iHub\ ...
- bzoj1821: [JSOI2010]Group 部落划分 Group
kruskal算法. #include<cstdio> #include<algorithm> #include<cstring> #include<cmat ...
- Dubbo实例
1. Dubbo是什么? Dubbo是一个分布式服务框架,致力于提供高性能和透明化的RPC远程服务调用方案,以及SOA服务治理方案.简单的说,dubbo就是个服务框架,如果没有分布式的需求,其实是不需 ...
- css padding在ie7、ie6、firefox中的兼容问题
padding 简写属性在一个声明中设置所有内边距属性. 说明这个简写属性设置元素所有内边距的宽度,或者设置各边上内边距的宽度.行内非替换元素上设置的内边距不会影响行高计算:因此,如果一个元素既有内边 ...
- JDBC基础教程
本文实例讲述了JDBC基础知识与技巧.分享给大家供大家参考.具体分析如下: 1.什么是JDBC? 通俗来讲JDBC技术就是通过java程序来发送SQL语句到数据库,数据库收到SQL语句后执行,把结果返 ...