爬虫Larbin解析(一)——Larbin配置与使用
介绍
功能:网络爬虫
开发语言:c++
开发者:Sébastien Ailleret(法国)
特点:只抓取网页,高效(一个简单的larbin的爬虫可以每天获取500万的网页)
安装
安装平台:Ubuntu 12.10
下载:http://sourceforge.net/projects/larbin/files/larbin/2.6.3/larbin-2.6.3.tar.gz/download
安装:
tar -zxvf larbin-2.6..tar.gz
cd larbin-2.6.
./configure
make
期间会出现错误,解决
1. adns文件夹下internal.h文件569-571行:
adns_status adns__parse_domain(adns_state ads, int serv, adns_queryqu,
vbuf *vb, parsedomain_flags flags,
const byte *dgram, int dglen, int *cbyte_io, int max);
改为
adns_status adns__parse_domain(adns_state ads, int serv, adns_query qu,
vbuf *vb, adns_queryflags flags,
const byte *dgram, int dglen, int *cbyte_io, int max);
2. 输入sudo ./congure 出现错误
make[2]: 正在进入目录 `/home/byd/test/larbin-2.6.3/src/utils'
makedepend -f- -I.. -Y *.cc 2> /dev/null > .depend
make[2]: *** [dep-in] 错误 127
make[2]:正在离开目录 `/home/byd/test/larbin-2.6.3/src/utils'
make[2]: 正在进入目录 `/home/byd/test/larbin-2.6.3/src/interf'
<span style="color: #ff0000;"><strong>makedepend</strong></span> -f- -I.. -Y *.cc 2> /dev/null > .depend
make[2]: *** [dep-in] 错误 127
make[2]:正在离开目录 `/home/byd/test/larbin-2.6.3/src/interf'
make[2]: 正在进入目录 `/home/byd/test/larbin-2.6.3/src/fetch'
makedepend -f- -I.. -Y *.cc 2> /dev/null > .depend
make[2]: *** [dep-in] 错误 127
make[2]:正在离开目录 `/home/byd/test/larbin-2.6.3/src/fetch'
make[1]: *** [dep] 错误 2
make[1]:正在离开目录 `/home/byd/test/larbin-2.6.3/src'
make: *** [dep] 错误 2
上边提示makedepend 有问题,于是输入makedepend,提示
makedepend 没安装,但是可以通过
sudo apt-get install xutils-dev
ok了。
3. 到/usr/include/c++/下CP一份iostream文件到larbin的src目录下。并将其名改为iostream.h,在文件中添加一句
using namespace std;
然后,继续
make
运行
./larbin
可以在浏览器上输入"localhost:8081"看当前爬虫的运行状况
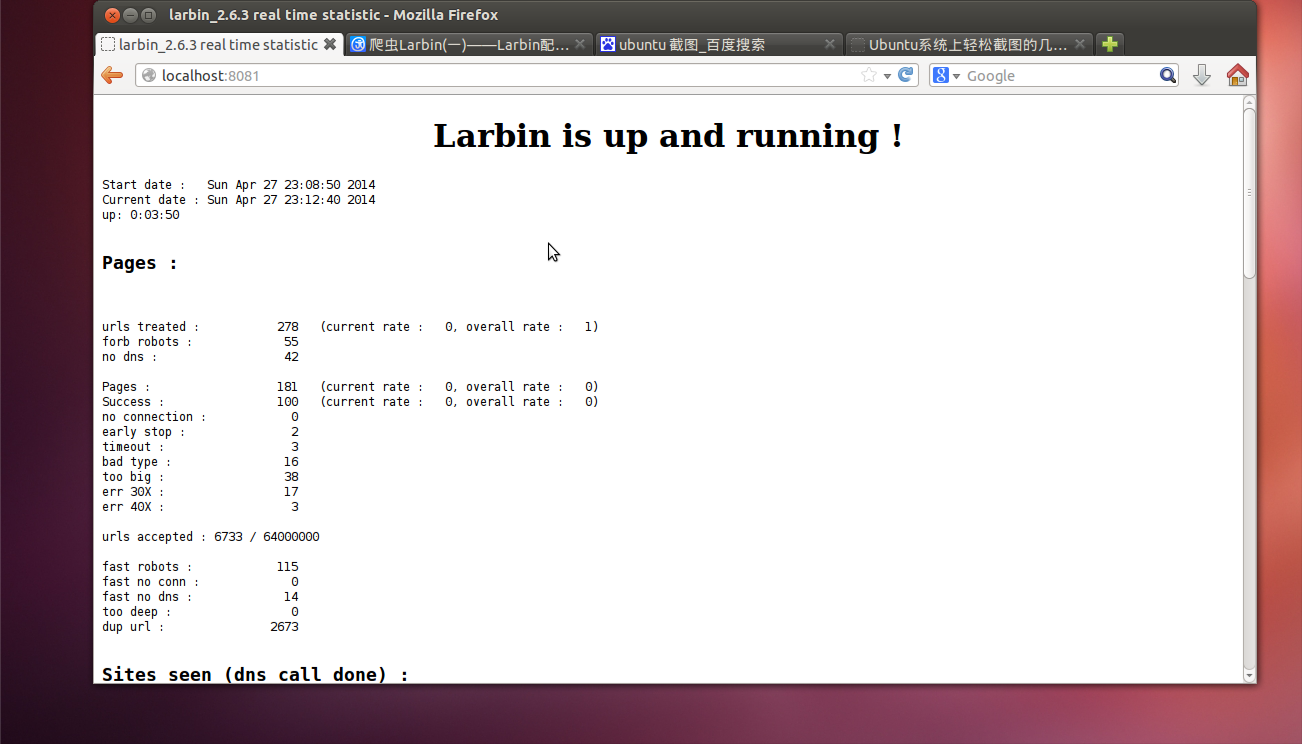
终止
ctrl+c
重启
./larbin -scratch
再次启动larbin时出现错误(只输入命令 ./larbin)
larbin_2.6.3 is starting its search
Unable to get the socket for the webserver () : Address already in use
原因
当客户端保持着与服务器端的连接,这时服务器端断开,再开启服务器时会出现: Address already in use
解决
netstat -anp | more
可以看到(如下图),杀死进程即可
kill -
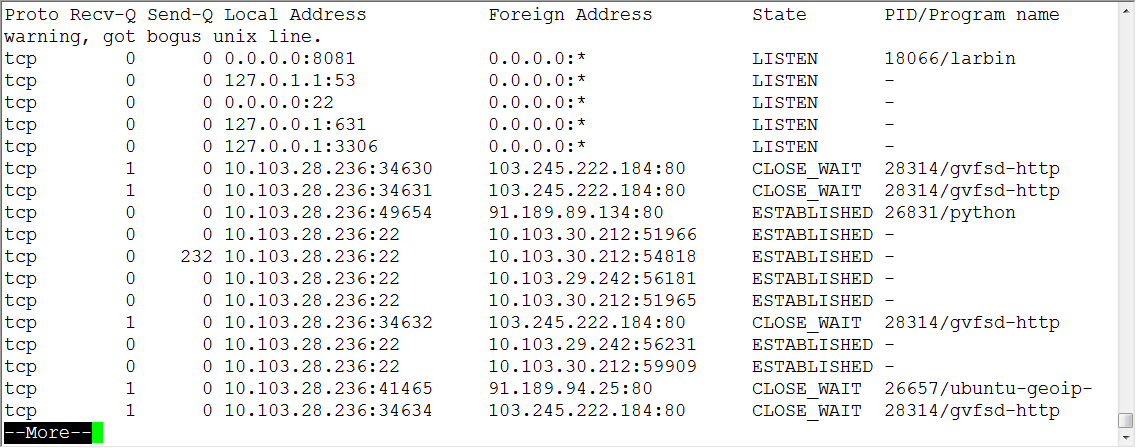
其中
- 在Internet RFC标准中,Netstat的定义是: Netstat是在内核中访问网络及相关信息的程序,它能提供TCP连接,TCP和UDP监听,进程内存管理的相关报告
- kill - 9 表示强制杀死该进程(最好少用,他是强制性的,即使是系统进程也会杀掉的)
配置
1、larbin.conf文件
###############################################
//客户端标记,当对其他网站抓取时,被抓取的网站知道是什么抓取的 UserAgent larbin_2.6.3 ############################################
# What are the inputs and ouputs of larbin
# port on which is launched the http statistic webserver
# if unset or set to , no webserver is launched //用于运行的http web服务器的端口号(larbin运行时访问http://localhost:8081/,设置为http_port 8081).如果将端口设为0,则不会启动web服务器。通过这个可以查看爬行结果 httpPort # port on which you can submit urls to fetch
# no input is possible if you comment this line or use port //你要爬取url的端口。如果注释掉或设为0,则可能没有任何输入。如果通过手动或者程序提交爬取的//urls,则必须练就到计算机的TCP端口1976,即设为:inputPort 1976,可以添加爬行的url。 #inputPort ############################################
# parameters to adapt depending on your network
# Number of connexions in parallel (to adapt depending of your network speed)
//并行爬取网页的数量,根据自己环境的网速调解,如果超时太多,则要降低这个并行数量 pagesConnexions # Number of dns calls in parallel
//并行DNS域名解析的数量。 dnsConnexions # How deep do you want to go in a site
//对一个站点的爬取的深度 depthInSite # do you want to follow external links
//不允许访问外部链接。如果设置则只可访问同一主机的连接
#noExternalLinks # time between calls on the same server (in sec) : NEVER less than
//访问同一服务器的时间间隔。不可低于30s,建议60s
waitDuration # Make requests through a proxy (use with care)
//是否用代理连接,如果用,则要设置、可以不用尽量不要用,这个选项要谨慎
#proxy www ##############################################
# now, let's customize the search # first page to fetch (you can specify several urls)
//开始爬取的URL
startUrl http://slashdot.org/ # Do you want to limit your search to a specific domain ?
# if yes, uncomment the following line
//这个选项设置了,则不可以爬行指定的特殊域名
#limitToDomain .fr .dk .uk end # What are the extensions you surely don't want
# never forbid .html, .htm and so on : larbin needs them
//不想要的扩展名文件。一定不要禁止.html、.htm.larbin爬取的就是它们。禁止也是无效的
forbiddenExtensions
.tar .gz .tgz .zip .Z .rpm .deb
.ps .dvi .pdf
.png .jpg .jpeg .bmp .smi .tiff .gif
.mov .avi .mpeg .mpg .mp3 .qt .wav .ram .rm
.jar .java .class .diff
.doc .xls .ppt .mdb .rtf .exe .pps .so .psd
end
2、options.h
2.1 输出模式
// Select the output module you want to use //默认模式。什么也不输出,不要选择这个
#define DEFAULT_OUTPUT // do nothing... //简单保存,存在save/dxxxxx/fyyyyy文件中,每个目录下2000个文件
//#define SIMPLE_SAVE // save in files named save/dxxxxxx/fyyyyyy
//镜像方式存储。按网页的层次存储,可以作为网页的字典。
//#define MIRROR_SAVE // save in files (respect sites hierarchy)
//状态输出。在网页上进行状态输出,可以查看http://localhost:8081/output.html查看结果
//#define STATS_OUTPUT // do some stats on pages
// Set up a specific search
//设置特定的查询
//#define SPECIFICSEARCH
//内容类型
//#define contentTypes ((char *[]) { "audio/mpeg", NULL })
//文件扩展。用于查询速度,不涉及类型,类型由上一个决定
//#define privilegedExts ((char *[]) { ".mp3", NULL })
2.3 设置完要设置特定文件的管理
#define DEFAULT_SPECIFIC //默认管理方式。 作为html有限制除了被解析。 //存储特定文件。 允许将文件存储在硬盘上 文件可以很大在src/types.h 可以具体设置。
#define SAVE_SPECIFIC //动态存储模式。对于较大的文件动态的分配buffer。
#define DYNAMIC_SPECIFIC
可以通过"src/fetch/specbuf.cc" and "src/fetch/specbuf.h" 定义特定文件的管理方式。
2.4 你要爬虫做什么
//不继续子链接。不设置此项则html页不被解析链接也不会爬子链接。通过输入系统添加url时很有用
#define FOLLOW_LINKS //每个网页中包含的子链接的列表。在"useroutput.cc" 用page->getLinks() 访问此信息。
#define LINKS_INFO //url标签。设置此项url有一个int(默认为0)。使用输入系统统时应该给定一个int。可以通过其获取u//rl。可以重定向。
#define URL_TAGS //不允许重复。如果设置则遇到相同网页但已遇到过时则不管。
#define NO_DUP //结束退出。没有url可爬取时是否退出。设置则退出。
#define EXIT_AT_END //抓取网页中的图片。设置了此项则要更新larbin.conf中禁止项。
#define IMAGES //抓取任何类型网页不管其的类型。设置要更新larbin.conf。
#define ANYTYPE //要larbin管理cookies。只简单实现但很有用。
#define COOKIES
2.5 其他选项说明
#define CGILEVEL 1 //定于选项及其参数。用于对爬行的url的限制。 #define MAXBANDWIDTH 200000 //larbin使用的带宽大小。不设置则不限带宽。 #define DEPTHBYSITE //当url链接到其他站点时新rul的深度是已被初始化的。
2.6 效率和特征
//是否为输入制定一个专用线程。当你在useroutput.cc定义自己的代码时必须设置此项。
#define THREAD_OUTPUT //重启位置记录表。设置此项时可以从上次终止处继续爬取。使用-scratch 选项从上次结束处重启。
#define RELOAD
2.7 Larbin怎么工作
#define NOWEBSERVER //不启动服务器。不运行线程时很有用 #define GRAPH //是否在状态也使用柱状图。 #define NDEBUG //不启动调试信息。 #define NOSTATS //不启动状态输出。 #define STATS //启动状态输出。运行时每个一段时间就会输出抓取的状态。 #define BIGSTATS //在标准输出上显示每个被抓去的网页名字。会降低larbin速度 #define CRASH //用于报告严重的bugs用。以gmake debug模式编译时使用。
参考
爬虫Larbin解析(一)——Larbin配置与使用的更多相关文章
- springmvc 项目完整示例06 日志–log4j 参数详细解析 log4j如何配置
Log4j由三个重要的组件构成: 日志信息的优先级 日志信息的输出目的地 日志信息的输出格式 日志信息的优先级从高到低有ERROR.WARN. INFO.DEBUG,分别用来指定这条日志信息的重要程度 ...
- fedora环境安装webkit支持作爬虫下载解析JS
环境: 我使用的fedora19.1-xfce版本,属于redhat系的桌面环境. 1.安装 webkit源码安装webkit失败,这里提供的是yum安装方式. a.查看当前yum库中的webkit资 ...
- python爬虫数据解析之BeautifulSoup
BeautifulSoup是一个可以从HTML或者XML文件中提取数据的python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式. BeautfulSoup是python爬虫三 ...
- Mybatis 系列7-结合源码解析核心CRUD 配置及用法
[Mybatis 系列10-结合源码解析mybatis 执行流程] [Mybatis 系列9-强大的动态sql 语句] [Mybatis 系列8-结合源码解析select.resultMap的用法] ...
- linux 学习第十八天学习(DNS分离解析、DHCP配置、邮件服务配置)
DNS分离解析技术 yum install bind-chroot systemctl restart named systemctl enable named vim /etc/named.conf ...
- nginx解析漏洞,配置不当,目录遍历漏洞环境搭建、漏洞复现
nginx解析漏洞,配置不当,目录遍历漏洞复现 1.Ubuntu14.04安装nginx-php5-fpm 安装了nginx,需要安装以下依赖 sudo apt-get install libpcre ...
- 【XPath Helper:chrome爬虫网页解析工具 Chrome插件】XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插件网
[XPath Helper:chrome爬虫网页解析工具 Chrome插件]XPath Helper:chrome爬虫网页解析工具 Chrome插件下载_教程_安装 - 开发者插件 - Chrome插 ...
- Nginx防盗链、访问控制、解析PHP相关配置及Nginx代理
6月11日任务 12.13 Nginx防盗链12.14 Nginx访问控制12.15 Nginx解析php相关配置12.16 Nginx代理 扩展502问题汇总 http://ask.apelearn ...
- python爬虫--数据解析
数据解析 什么是数据解析及作用 概念:就是将一组数据中的局部数据进行提取 作用:来实现聚焦爬虫 数据解析的通用原理 标签定位 取文本或者属性 正则解析 正则回顾 单字符: . : 除换行以外所有字符 ...
随机推荐
- mysql导入的时候提示“1046-No Database selected”的解决办法
进入phpmyadmin后,先点击左边的要导入的数据库,进入后再点击右上角的“导入‘按钮即可 详细说明 http://www.xmxwl.net/help/member/20160325/13653. ...
- Struts 2简单配置分析
要配置Struts 2,首先先要有Struts 2的Jar包,可以去Struts的官网下载(http://struts.apache.org/),这里有3个GA版本可以选择下载,我选择的是最新的2.2 ...
- 关于qt5在win7下发布 & 打包
QT5 发布时,莫过于依赖动态链接库(dll) , 但是,QT5的动态链接库貌似都有2套 ,例如 Qt5Core (针对realese) , Qt5Cored (针对debug) ,凡事末尾带d的都是 ...
- axure7.0 汉化包下载
下载地址:http://files.cnblogs.com/files/feijian/axure7.0%E4%B8%AD%E6%96%87%E8%AF%AD%E8%A8%80%E6%B1%89%E5 ...
- ADO.NET- 基础总结及实例介绍
最近闲暇时间写的一些小程序中,访问数据库比较多:下面主要介绍下ADO.NET方面知识,有不足之处,希望大神们不吝赐教: 提到ADO.NET,经常会和ASP.NET进行混淆,两者的区别很大,没有可比性, ...
- bitmap缩放时抗锯齿
bitmap在进行放大缩小的时候经常会出现边缘锯齿的情况,通常的解决办法是在Paint中加入抗锯齿, paint.setAntiAlias(true); 但是有时候发现这并没有起到抗锯齿的作用,这是可 ...
- MyEclipse2015破解版_MyEclipse 2015 stable 2.0 稳定版 破解日志
前言:在MyEclipse 2015 Stable 1.0下载安装破解日志(http://www.cnblogs.com/wql025/p/5161979.html)一文中,笔者主要讲述了该版本的破解 ...
- css文件都写在一个里面还是每个页面都引用单独的css样式好?
因为网站比较小,外加网站页面有很多重复构件,决定采用“构件复用”搭建网页,但是遇到了一个问题.因为虽然有共同的css,但是每个页面或多或少都有独立的样式控制,到底是写在同一个css还是分离看上去清楚一 ...
- 奇异值分解(We Recommend a Singular Value Decomposition)
奇异值分解(We Recommend a Singular Value Decomposition) 原文作者:David Austin原文链接: http://www.ams.org/samplin ...
- uva 434
贪心 ~ #include <cstdio> #include <cstdlib> #include <cmath> #include <map> #i ...