李洪强iOS开发之【零基础学习iOS开发】【02-C语言】07-基本数据类型
C语言有丰富的数据类型,因此它很适合用来编写数据库,如DB2、Oracle等大型数据库都是C语言写的。其中,提供了4种最常用的基本数据类型:char、int、float、double,使用这些数据类型,我们就可以定义相应的变量来存储数据。这讲就来深入研究一下基本数据类型的一些使用细节。
一、取值范围
我们已经知道,不同数据类型所占的存储空间是不一样的。比如在64bit编译器环境下,char类型占用1个字节,int类型占用4个字节。字节长度不一样,包含的二进制位数就不一样,能表示的数据范围也就不一样。因此,int类型能表示的数据范围肯定比char类型大。下面来简单算算64bit编译器环境下int类型的取值范围。
1.推算int类型的取值范围
int类型占用4个字节,所以一共32位,那么按理来说,取值范围应该是:0000 0000 0000 0000 0000 0000 0000 0000~1111 1111 1111 1111 1111 1111 1111 1111,也就是10进制的0 ~ 232 - 1。但是int类型是有正负之分的,包括了正数和负数,那怎么表示负数呢?就是拿最高位来当符号位,当最高位为0就是正数,最高位为1则是负数。即:1000 0000 1001 1011 1000 0000 1001 1011就是一个负数,0000 1001 0000 1101 0000 1001 0000 1101是一个正数。由于最高位是0才代表正数,因此最大的正数是0111 1111 1111 1111 1111 1111 1111 1111,也就是231 - 1。而最小的负数就是1000 0000 0000 0000 0000 0000 0000 0000,也就是-231(为什么是这个值呢?可以根据前面章节提到的负数的二进制形式,自己去换算一下,看看1000 0000 0000 0000 0000 0000 0000 0000是不是-231。算不出也不用去纠结,不影响写代码,知道有这么一回事就完了)。因此,int类型的取值范围是-231 ~ 231 - 1。
注意:这个推算过程是不用掌握的,大致知道过程就行了,而且这个结论也不用去记,大致知道范围就行了。
2.各种数据类型的取值范围
int类型的取值范围已经会算了,那么其他数据类型的取值范围就能够以此类推。

(注:float和double由于是小数,它们的存储方式是特别不一样的,所以它们取值范围的算法也很不一样,这里不做介绍,也不用去掌握。e38表示乘以10的38次方,e-38表示乘以10的负38次方。)
上面表格中列出的只是64bit编译器环境下的情况。如果你的编译器是16bit或者32bit,这些数据类型的取值范围肯定是不一样的。比如int类型,在16bit编译器环境下是占用2个字节的,共16bit,所以int类型的取值范围是:-215 ~ 215 - 1。
3.数值越界
1> 例子演示
前面已经看到,每种数据类型都有自己的取值范围。如果给一个变量赋值了一个超出取值范围的数值,那后果会不堪设想。

1 #include <stdio.h>
2
3 int main()
4 {
5 int c = 1024 * 1024 * 1024 * 4;
6
7 printf("%d\n", c);
8 return 0;
9 }
我们都知道,int类型能保存的最大值是231-1。在第5行给int类型的变量c赋值一个比231-1大的数值:232 (1024是210)
先看看在终端中的输出结果: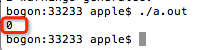 ,可以看出输出的值是0。
,可以看出输出的值是0。
2> 结果分析
我们可以简单分析一下为什么将232赋值给变量c之后输出的是0。232的 二进制形式是:1 0000 0000 0000 0000 0000 0000 0000 0000,一共有33位二进制数。变量c占用了4个字节,只能容纳32位二进制数,而且内存寻址是从大到小的,因此,变量c在内存中的存储形式是0000 0000 0000 0000 0000 0000 0000 0000,也就是0,最前面的那个1就不属于变量c的了。

3> 结论
可以发现,如果超出了变量的取值范围,那么将损失精度,得到“垃圾数据”(“垃圾数据”就是指并非我们想要的数据)。可是,有时候我们确实要存储一个很大很大的整数,比231-1还大的整数,这该怎么办呢?这个就要用到类型说明符,这这讲的后面会讨论。
二、char
1.简单使用
char是C语言中比较灵活的一种数据类型,称为“字符型”。既然叫“字符型”,那肯定是用来存储字符的,因此我们可以将一个字符常量赋值给一个字符型变量。
1 #include <stdio.h>
2
3 int main()
4 {
5 char c = 'A';
6
7 printf("%c\n", c);
8 return 0;
9 }
在第5行定义了一个char类型变量c,并将字符常量'A'赋值给了c。在第7行将字符变量c输出到屏幕,%c的意思是以字符的格式输出。
输出结果:
2.字符常量一定要用单引号括住
1> 下面的写法是错误的:
1 int main()
2 {
3 char c = A;
4 return 0;
5 }
编译器会直接报第3行的错,错误原因是:标识符A找不到。你直接写个大写A,编译器会认为这个A是一个变量。因此写成'A'才是正确的,或者在第3行代码的前面再定义1个变量名叫做A的char类型变量。
2> 下面的写法也是错误的:
1 int main()
2 {
3 char c = "A";
4 return 0;
5 }
第3行中的"A"并不是字符常量,而是字符串常量,将字符串"A"赋值给字符变量c是错误的做法。字符串和字符的存储机制不一样,因此"A"和'A'是有本质区别的。
3.字符型变量还可以当做整型变量使用
1个字符型变量占用1个字节,共8位,因此取值范围是-27~27-1。在这个范围内,你完全可以将字符型变量当做整型变量来使用。
1 #include <stdio.h>
2
3 int main()
4 {
5 char c1 = -10;
6
7 char c2 = 120;
8
9 printf("c1=%d c2=%d \n", c1, c2);
10 return 0;
11 }
由于第9行用的是%d,表示以十进制整数格式输出,输出结果: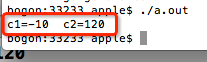 。因此,如果使用的整数不是很大的话,可以使用char代替int,这样的话,更节省内存开销。
。因此,如果使用的整数不是很大的话,可以使用char代替int,这样的话,更节省内存开销。
4.字符型变量只能存储单字节字符
其实字符有2种类型:单字节字符和双字节字符。
- 单字节字符:在内存中占用1个字节的字符。包括了26个英文字母的大小写、10个阿拉伯数字等字符;
- 双字节字符:在内存中占用2个字节的字符。包括了中国、日本和韩国等国家的文字,比如汉字。
1个字符型变量只占用1个字节,所以1个字符型变量只能存储1个单字节字符。
下面的写法是错误的:
1 #include <stdio.h>
2
3 int main()
4 {
5 char c = 'ABCD';
6
7 printf("%c\n", c);
8 return 0;
9 }
编译器会对上面的代码发出警告,并不会报错,因此程序还是能够运行。由于变量c只能存储1个单字节字符,最终变量c只存储了'ABCD'中的'D'。
输出结果:
5.字符型变量不能存储汉字
在内存中,1个汉字需要用2个字节来存储,而1个字符型变量只占用1个字节的存储空间,所以字符型变量不能用来存储汉字。
下面的写法是错误的:
1 int main()
2 {
3 char c = '男';
4 return 0;
5 }
编译器会直接报第3行的错误。记住一个原则:单引号括住的必须是单字节字符。
6.ASCII
说到字符,就不得不提ASCII这个概念
1> ASCII是基于拉丁字母的一套电脑编码系统,是现今最通用的单字节编码系统,全称是“American Standard Code for Information Interchange”。编码系统,看起来好像很高级,其实就是一个字符集---字符的集合。
2> ASCII字符集包括了:所有的大写和小写英文字母,数字0到9,标点符号,以及一些特殊控制字符:如退格、删除、制表、回车,一共128个字符,全部都是“单字节字符”。
3> 在计算机中的任何数据都是以二进制形式存储的,因此每个ASCII字符在内存中是以二进制形式存储的,而且只占用1个字节,二进制数的值就称为这个ASCII字符的ASCII值。比如大写字母A在内存中的二进制形式是:0100 0001,那么它的ASCII值就是65。
4> 下面是一张ASCII码字符表,ASCII码值的范围是0~127
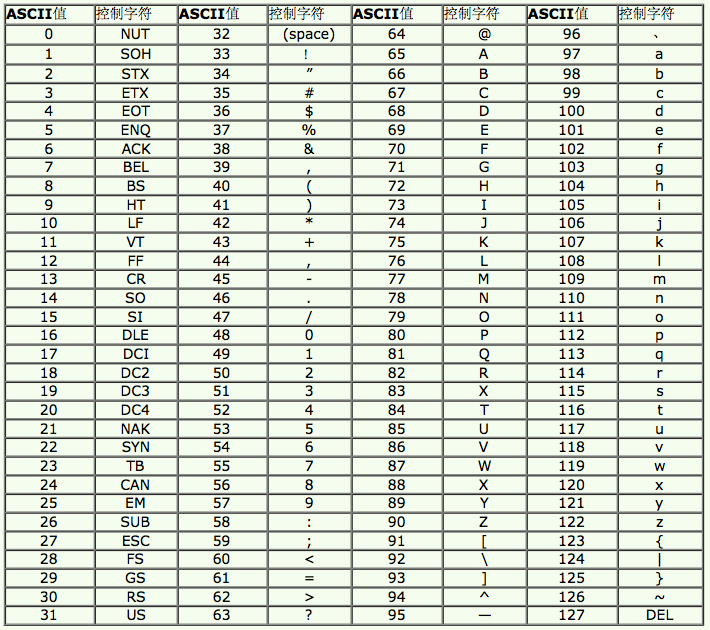
5> 我们都知道1个char型变量只占用1个字节的存储空间,而所有的ASCII字符都是单字节字符,因此char型变量能存储任何ASCII字符。而且在使用char型变量存储ASCII字符时,可以直接用ASCII字符,也可以用ASCII值。
1 #include <stdio.h>
2
3 int main()
4 {
5 char c1 = 65;
6
7 char c2 = 'A';
8
9 printf("c1=%c c2=%c \n", c1, c2);
10 return 0;
11 }
在第5、7行分别定义了字符型变量c1、c2。很明显,变量c2存储的是ACII字符'A';变量c1存储的是65,而ASCII值65对应的ASCII字符就是'A',因此变量c1存储的也是'A'。
由于第9行用的是%c,表示以字符格式输出,输出结果:
5> 经过上面的例子后,应该知道6和'6'的区别了吧
1 #include <stdio.h>
2
3 int main()
4 {
5 char c1 = 6;
6
7 char c2 = '6';
8
9 printf("c1=%d c2=%d \n", c1, c2);
10 return 0;
11 }
第5行给变量c1赋值了整数6,第7行给变量c2赋值了字符'6','6'的ASCII值是54。
由于第9行用的是%d,表示以十进制整数格式输出,输出结果:
三、说明符
1.什么是说明符
1> 我们已经知道,在64bit编译器环境下,1个int类型变量取值范围是-231 ~ 231 - 1,最大值是231-1。有时候,我们要使用的整数可能比231-1还大,比如234这个整数,如果还坚持用int类型变量来存储这个值的话,就会损失精度,得到的是垃圾数据。为了解决这个问题,C语言允许我们给int类型的变量加一些说明符,某些说明符可以增大int类型变量的长度,这样的话,int类型变量能存储的数据范围就变大了。
2> C语言提供了以下4种说明符,4个都属于关键字:
- short 短型
- long 长型
- signed 有符号型
- unsigned 无符号型
按照用途进行分类,short和long是一类,signed和unsigned是一类。
2.用法演示
这些说明符一般就是用来修饰int类型的,所以在使用时可以省略int
1 // 下面两种写法是等价的
2 short int s1 = 1;
3 short s2 = 1;
4
5 // 下面两种写法是等价的
6 long int l1 = 2;
7 long l2 = 2;
8
9 // 可以连续使用2个long
10 long long ll = 10;
11
12 // 下面两种写法是等价的
13 signed int si1 = 3;
14 signed si2 = 3;
15
16 // 下面两种写法是等价的
17 unsigned int us1 = 4;
18 unsigned us2 = 4;
19
20 // 也可以同时使用2种修饰符
21 signed short int ss = 5;
22 unsigned long int ul = 5;
1> 第2行中的short int和第3行中的short是等价的。
2> 看第10行,可以连续使用两个long。long的作用会在后面解释。
3> 注意第21和22行,可以同时使用两种不同的说明符。但是不能同时使用相同类型的修饰符,也就是说不能同时使用short和long 或者 不能同时使用signed和unsigned。
3.short和long
1> short和long可以提供不同长度的整型数,也就是可以改变整型数的取值范围。在64bit编译器环境下,int占用4个字节(32bit),取值范围是-231~231-1;short占用2个字节(16bit),取值范围是-215~215-1;long占用8个字节(64bit),取值范围是-263~263-1
2> 总结一下:在64位编译器环境下,short占2个字节(16位),int占4个字节(32位),long占8个字节(64位)。因此,如果使用的整数不是很大的话,可以使用short代替int,这样的话,更节省内存开销。
3> 世界上的编译器林林总总,不同编译器环境下,int、short、long的取值范围和占用的长度又是不一样的。比如在16bit编译器环境下,long只占用4个字节。不过幸运的是,ANSI \ ISO制定了以下规则:
- short跟int至少为16位(2字节)
- long至少为32位(4字节)
- short的长度不能大于int,int的长度不能大于long
- char一定为为8位(1字节),毕竟char是我们编程能用的最小数据类型
4> 可以连续使用2个long,也就是long long。一般来说,long long的范围是不小于long的,比如在32bit编译器环境下,long long占用8个字节,long占用4个字节。不过在64bit编译器环境下,long long跟long是一样的,都占用8个字节。
5> 还有一点要明确的是:short int等价于short,long int等价于long,long long int等价于long long
4.long的使用注意
1> 常量
long和int都能够存储整型常量,为了区分long和int,一般会在整型常量后面加个小写字母l,比如100l,表示long类型的常量。如果是long long类型呢,就加2个l,比如100ll。如果什么都不加,就是int类型的常量。因此,100是int类型的常量,100l是long类型的常量,100ll是long long类型的常量。
1 int main()
2 {
3 int a = 100;
4
5 long b = 100l;
6
7 long long c = 100ll;
8
9 return 0;
10 }
变量a、b、c最终存储的值其实都是100,只不过占用的字节不相同,变量a用4个字节来存储100,变量b、c则用8个字节来存储100。
其实,你直接将100赋值给long类型的变量也是没问题的,照样使用。因为100是个int类型的常量,只要有4个字节,就能存储它,而long类型的变量b有8个字节,那肯定可以装下100啦。
1 int main()
2 {
3 long b = 100;
4
5 return 0;
6 }
2> 输出
1 #include <stdio.h>
2
3 int main()
4 {
5 long a = 100000000000l;
6
7 printf("%d\n", a);
8 return 0;
9 }
在第5行定义了long类型变量a,在第7行尝试输出a的值。注意了,这里用的是%d,表示以十进制整数格式输出,%d会把a当做int类型来输出,它认为a是4个字节的。由于a是long类型的,占用8个字节,但是输出a的时候,只会取其中4个字节的内容进行输出,所以输出结果是:
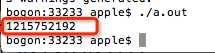 又是传说的垃圾数据
又是传说的垃圾数据
那怎样才能完整地输出long类型呢?应该用格式符%ld
1 #include <stdio.h>
2
3 int main()
4 {
5 long a = 100000000000l;
6
7 printf("%ld\n", a);
8 return 0;
9 }
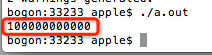
注意第7行,双引号里面的是%ld,表示输出1个long类型的整数,这时候的输出结果是:
如果是long long类型,应该用%lld
1 #include <stdio.h>
2
3 int main()
4 {
5 long long a = 100000000000ll;
6
7 printf("%lld\n", a);
8 return 0;
9 }
5.signed和unsigned
1> 首先要明确的:signed int等价于signed,unsigned int等价于unsigned
2> signed和unsigned的区别就是它们的最高位是否要当做符号位,并不会像short和long那样改变数据的长度,即所占的字节数。
- signed:表示有符号,也就是说最高位要当做符号位,所以包括正数、负数和0。其实int的最高位本来就是符号位,已经包括了正负数和0了,因此signed和int是一样的,signed等价于signed int,也等价于int。signed的取值范围是-231 ~ 231 - 1
- unsigned:表示无符号,也就是说最高位并不当做符号位,所以不包括负数。在64bit编译器环境下面,int占用4个字节(32bit),因此unsigned的取值范围是:0000 0000 0000 0000 0000 0000 0000 0000 ~ 1111 1111 1111 1111 1111 1111 1111 1111,也就是0 ~ 232 - 1
6.signed、unsigned也可以修饰char,long还可以修饰double
知道有这么一回事就行了。
1 unsigned char c1 = 10;
2 signed char c2 = -10;
3
4 long double d1 = 12.0;
7.不同数据类型所占用的存储空间

四、自动类型提升
1.什么是自动类型提升
先来看看下面的一则运算
1 #include <stdio.h>
2
3 int main()
4 {
5 int a = 10;
6
7 double d = a + 9.5;
8
9 printf("%f \n", d);
10
11 return 0;
12 }
1> 在第5行定义了一个int类型的变量a,赋值了一个整数10。
2> 接着在第7行取出a的值10,加上浮点数9.5,这里做了一个“加法运算”,并且将“和”赋值给d。所以d的值应该是19.5。
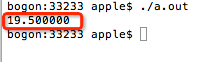
3> 在第9行使用格式符%f输出浮点型变量d,默认是保留6位小数的。输出结果为:
4> 看似这么简单的运算,其实包含了一些语法细节在里面。严格来说,相同数据类型的值才能进行运算(比如加法运算),而且运算结果依然是同一种数据类型。第7行的情况是:变量a的值10是int类型(4字节),9.5是double类型(8字节)。很明显,10和9.5并不是相同数据类型。按理来说,10和9.5是不允许进行加法运算的。但是,系统会自动对占用内存较少的类型做一个“自动类型提升”的操作,也就把10提升为double类型。也就是说,本来是用4个字节来存放10的,现在改为用8个字节来存放10。因此,10和9.5现在都是用8个字节来存放的,都是double类型,然后就可以进行运算了。并且把运算结果赋值给double类型的变量d。
5> 需要注意的是:经过第7行代码后,变量a一直都还是int类型的,并没有变成double类型。1个变量在它定义的时候是什么类型,那么就一直都是什么类型。“自动类型提升”只是在运算过程中进行的。
2.常见的自动类型提升
1 int main()
2 {
3 float a = 10 + 3.45f;// int 提升为 float
4
5 int b = 'A' + 32; // char 提升为 int
6
7 double c = 10.3f + 5.7; // float 提升为 double
8
9 return 0;
10 }
1> 注意第5行,系统会将字符'A'提升为int类型数据,也就是转为'A'的ASCII值后再跟32进行加法运算。'A'的ASCII值是65,因此变量b的值为65+32=97。
2> 这个自动类型提升,知道有这么一回事就行了,不用死记这规则,因为系统会自动执行这个操作。
五、强制类型转换
1.什么是强制类型转换
先来看看下面的代码
1 #include <stdio.h>
2
3 int main()
4 {
5 int i = 10.7;
6
7 printf("%d \n", i);
8 return 0;
9 }
1> 注意第5行,我们将一个8个字节的浮点数10.7赋值给了只有4个字节存储空间的整型变量i。可以想象得到,把8个字节的内容塞给4个字节,肯定会损失精度。在第7行将变量i的值输出,输出结果是:
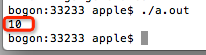 输出值为10,这是必然的。
输出值为10,这是必然的。
2> 这里面也有一点语法细节,其实第5行做了一个“强制类型转换”的操作:由于左边是int类型的变量i,那么就会强制把double类型的10.7转换为int类型的10,并且把转换后的值赋值给了整型变量i。由于C语言是语法限制不严格,所以系统会自动强制转换,如果换做是其他语法严格的语言,比如Java,第5行代码早就报错了。
3> 如果写得严格一点,明显地进行“强制类型转换”,应该这样写:
1 #include <stdio.h>
2
3 int main()
4 {
5 int i = (int) 10.7;
6
7 printf("%d \n", i);
8 return 0;
9 }
注意第5行,在10.7的前面加了个(int),表示强制转换为int类型的数据。这样就绝对不会有语法问题了。总之你将一个浮点型数据转换为整型数据,就会丢失小数部分的值。
2.常见的强制类型转换
1 int main()
2 {
3 int a = 198l; // long 转换为 int
4
5 char b = 65; // int 转换为 char
6
7 int c = 19.5f; // float 转换为 int
8
9 return 0;
10 }
这个强制类型转换,知道有这么一回事就行了,不用死记这规则,因为很多时候系统会自动执行这个操作。
3.其他用法
前面看到的强制转换好像都是“大类型”转为“小类型”,其实这是不一样的,也可以由“小类型”转为“大类型”
1 int main()
2 {
3 int a = 10;
4
5 double b = (double)a + 9.6;
6
7 return 0;
8 }
注意第5行,先将a的值强制转换为double类型后,再跟9.6进行加法运算。这样的话,系统就不用执行“自动类型提升”的操作了。其实你不强转也可以的,因为系统会做一个“自动类型提升”的操作,将变量a的值10提升为double类型。知道有这用法就行了,以后某些地方会用得上。
李洪强iOS开发之【零基础学习iOS开发】【02-C语言】07-基本数据类型的更多相关文章
- 李洪强iOS开发之零基础学习iOS开发】【02-C语言】01-概述
前面已经给大家介绍了iOS开发相关的一些基础知识,其实iOS开发就是开发iPhone\iPad上的软件,而要想开发一款软件,首先要学习程序设计语言.iOS开发需要学习的主要程序设计语言有:C语言.C+ ...
- 李洪强iOS开发之零基础学习iOS开发【02-C语言】03-关键字、标识符、注释
上一讲中已经创建了第一个C语言程序,知道了C程序是由函数构成的,这讲继续学习C语言的一些基本语法.C语言属于一门高级语言,其实,所有的高级语言的基本语法组成部分都是一样的,只是表现形式不太一样.就好像 ...
- 李洪强iOS开发之【零基础学习iOS开发】【01-前言】01-开篇
从今天开始,我就开始更新[零基础学习iOS开发]这个专题.不管你是否涉足过IT领域,也不管你是理科生还是文科生,只要你对iOS开发感兴趣,都可以来阅读此专题.我尽量以通俗易懂的语言,让每个人都能够看懂 ...
- 【零基础学习iOS开发】【转载】
原文地址:http://www.cnblogs.com/mjios/archive/2013/04/24/3039357.html 本文目录 一.什么是iOS 二.主流手机操作系统 三.什么是iOS开 ...
- 【零基础学习iOS开发】【01-前言】01-开篇
本文目录 一.什么是iOS 二.主流手机操作系统 三.什么是iOS开发 四.学习iOS开发的目的 五.学习iOS开发的前提 从今天开始,我就开始更新[零基础学习iOS开发]这个专题.不管你是否涉足过I ...
- 零基础学习iOS开发
零基础学习iOS开发不管你是否涉足过IT领域,只要你对iOS开发感兴趣,都可以阅读此专题. [零基础学习iOS开发][02-C语言]11-函数的声明和定义 摘要: 在上一讲中,简单介绍了函数的定义和使 ...
- [iOS]关于零基础学习iOS开发的学习方法总结
关于零基础学习iOS开发的学习方法总结 最近很多零基础来参加蓝鸥培训的学生经常会问到一些学习方法的问题,就如下我自己见过的好的学习方法一起讨论一下. 蓝鸥iOS开发技术的学习路线图 程序员的主要工作是 ...
- MongoDB实战开发 【零基础学习,附完整Asp.net示例】
MongoDB实战开发 [零基础学习,附完整Asp.net示例] 阅读目录 开始 下载MongoDB,并启动它 在C#使用MongoDB 重构(简化)代码 使用MongoDB的客户端查看数据 使用Mo ...
- 零基础学习hadoop开发所必须具体的三个基础知识
大数据hadoop无疑是当前互联网领域受关注热度最高的词之一,大数据技术的应用正在潜移默化中对我们的生活和工作产生巨大的改变.这种改变给我们的感觉是“水到渠成”,更为让人惊叹的是大数据已经仅仅是互联网 ...
- 李洪强iOS开发之【零基础学习iOS开发】【01-前言】02-准备
在上一讲中,介绍了什么是iOS开发.说简单一点,iOS开发,就是开发运行在iPhone或者iPad上的软件.这么一说完,应该有很多人就会产生一些疑惑,比如学习iOS开发是不是一定要买iPhone?需不 ...
随机推荐
- Linux学习三部曲(之二)
新建Linux分区以及文件系统 今天,我们来聊聊在linux上建立分区和文件系统.windows系统建立分区可以借助分区工具,那么在linux分区以及文件系统又该如何操作呢? 打开secureCRT, ...
- spring读取加密配置信息
描述&背景Spring框架配置数据库等连接等属性时,都是交由 PopertyPlaceholderConfigurer进行读取.properties文件的,但如果项目不允许在配置文件中明文保存 ...
- FKCL-OS——自主的操作系统
我想搞一个操作系统,这是因为我对windows非常不满意,对linux非常讨厌,我想要开发一个真正自己的OS,然后让自己和别人使用它.得到方便.我将在这篇文章中写下我对操作系统的不满,然后构思出我的操 ...
- 利用Echarts设计一个图表平台(一)
Echarts是一款百度的开源图表库,里面提供了非常多的图表样式,我们今天要讲的内容是利用这一款开源js图表,制作一个能够动态定制的图表平台. 1)Echarts API介绍 首先我们先来看一下Ech ...
- L001-oldboy-mysql-dba-lesson01
L001-oldboy-mysql-dba-lesson01 <sql应用重构>经典的书 ,思想,封顶境界! mysql下载页面: http://www.filewatcher ...
- margin折叠
什么是margin折叠:当两个或更多个垂直边距相遇时,它们将形成一个外边距.这个外边距的高度等于两个发生叠加的外边距的高度中的较大者. 注意: (1 ...
- XML美化工具及其他各种美化工具
在线工具 http://www.ostools.net/codeformat/xml 3464网页常用工具 http://www.3464.com/Tools/CodeFormat/ 在线工具大全 h ...
- Unity学习笔记(3):获取对象
在上一篇文章中(Unity映射注册)中概要介绍了Unity中的映射机制,本节主要介绍对象获取,包括默认获取,通过名称获取,获取全部对象,同时通过加载配置文件,然后再获取对象. 通过代码获取对象 方式1 ...
- C# 获取中文星期的两种方法
//方法一 public string Week() { string[] weekdays = { "星期日", "星期一", "星期二" ...
- 打破常规——大胆尝试在路由器上搭建SVN服务器
注册博客园挺久了,一直比较懒,虽然有几次想写点文章,但是一直没有行动,今天给大家带来一篇比较有意思的文章,不涉及技术上的,希望大家轻拍.本文的文字和图片全部为原创,尊重作者转载请注明出处! 说起路由器 ...