Java线程池ThreadPoolExecuter:execute()原理
一、线程池执行任务的流程
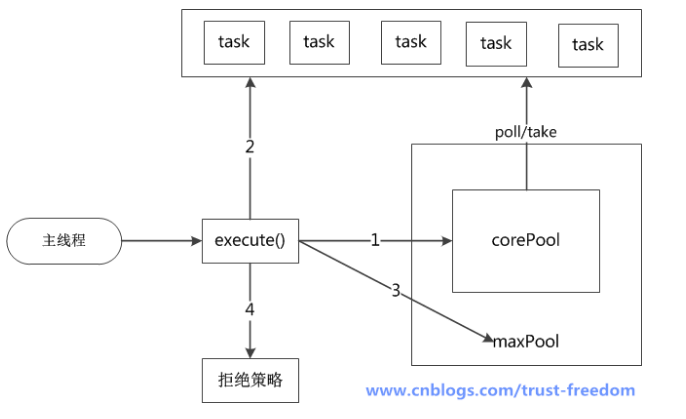
如果线程池工作线程数<corePoolSize,创建新线程执行task,并不断轮训t等待队列处理task。
如果线程池工作线程数>=corePoolSize并且等待队列未满,将task插入等待队列。
如果线程池工作流程数>=corePoolSize并且等待队列已满,且工作线程数<maximumPoolSize,创建新线程执行task。
如果线程池工作流程数>=corePoolSize并且等待队列已满,且工作线程数=maximumPoolSize,执行拒绝策略。
二、execute()原理
public void execute(Runnable command) { if (command == null)
throw new NullPointerException();
/*
* Proceed in 3 steps:
*
* 1. If fewer than corePoolSize threads are running, try to
* start a new thread with the given command as its first
* task. The call to addWorker atomically checks runState and
* workerCount, and so prevents false alarms that would add
* threads when it shouldn't, by returning false.
* 如果运行的线程数小于corePoolSize,尝试创建一个新线程(Worker),并执行它的第一个任务command
* 2. If a task can be successfully queued, then we still need
* to double-check whether we should have added a thread
* (because existing ones died since last checking) or that
* the pool shut down since entry into this method. So we
* recheck state and if necessary roll back the enqueuing if
* stopped, or start a new thread if there are none.
* 如果task成功插入等待队列,我们仍需要进行双重校验是否可以成功添加一个线程
(因为有的线程可能在我们上次检查以后已经死掉了)或者在我们进入这个方法后线程池已经关闭了
* 3. If we cannot queue task, then we try to add a new
* thread. If it fails, we know we are shut down or saturated
* and so reject the task.
如果等待队列已满,我们尝试新创建一个线程。如果创建失败,我们知道线程已关闭或者已饱和,因此我们拒绝改任务。
*/
int c = ctl.get();
//工作线程小于核心线程数,创建新的线程
if (workerCountOf(c) < corePoolSize) {
//创建新的worker立即执行command,并且轮训workQueue处理task
if (addWorker(command, true))
return;
c = ctl.get();
}
//线程池在运行状态且可以将task插入队列
//第一次校验线程池在运行状态
if (isRunning(c) && workQueue.offer(command)) {
int recheck = ctl.get();
//第二次校验,防止在第一次校验通过后线程池关闭。如果线程池关闭,在队列中删除task并拒绝task
if (! isRunning(recheck) && remove(command))
reject(command);
//如果线程数=0(线程都死掉了,比如:corePoolSize=0),新建线程且未指定firstTask,仅仅去轮训workQueue
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//线程队列已满,尝试创建新线程执行task,创建失败后拒绝task
//创建失败原因:1.线程池关闭;2.线程数已经达到maxPoolSize
else if (!addWorker(command, false))
reject(command);
}
1. addWorker(Runnable firstTask, boolean core)
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
//外层循环判断线程池的状态
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);//线程池状态
// Check if queue empty only if necessary.
//线程池状态:RUNNING = -1、SHUTDOWN = 0、STOP = 1、TIDYING = 2、TERMINATED = 3
//线程池至少是shutdown状态
if (rs >= SHUTDOWN &&
//除了线程池正在关闭(shutdown),队列里还有未处理的task的情况,其他都不能添加
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
//内层循环判断是否到达容量上限,worker+1
for (;;) {
int wc = workerCountOf(c);//worker数量
//worker大于Integer最大上限
//或到达边界上限
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//CAS worker+1
if (compareAndIncrementWorkerCount(c))
break retry;//成功了跳出循环
c = ctl.get(); // Re-read ctl
if (runStateOf(c) != rs) //如果线程池状态发生变化,重试外层循环
continue retry;
// else CAS failed due to workerCount change; retry inner loop
// CAS失败workerCount被其他线程改变,重新尝试内层循环CAS对workerCount+1
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
final ReentrantLock mainLock = this.mainLock;
w = new Worker(firstTask); //1.state置为-1,Worker继承了AbstractQueuedSynchronizer
//2.设置firstTask属性
//3.Worker实现了Runable接口,将this作为入参创建线程
final Thread t = w.thread;
if (t != null) {
//addWorker需要加锁
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int c = ctl.get();
int rs = runStateOf(c);
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
workers.add(w);//workers是HashSet<Worker>
//设置最大线程池大小
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}
addWorker(Runnable firstTask, boolean core)
参数:
firstTask: worker线程的初始任务,可以为空
core: true:将corePoolSize作为上限,false:将maximumPoolSize作为上限
addWorker方法有4种传参的方式:
1、addWorker(command, true)
2、addWorker(command, false)
3、addWorker(null, false)
4、addWorker(null, true)
在execute方法中就使用了前3种,结合这个核心方法进行以下分析
1、线程数小于corePoolSize。判断workers(HashSet<Worker>)大小,如果worker数量>=corePoolSize 返回false,否则创建worker添加到workers,并执行worker的run方法(执行firstTask并轮询tworkQueue);
2、线程数大于corePoolSize且workQueue已满。如果worker数量>=maximumPoolSize返回false,否则创建worker添加到workers,并执行worker的run方法(执行firstTask并轮询tworkQueue);
3.、没有worker存活,创建worker去轮询workQueue,长度限制maximumPoolSize。
4、prestartAllCoreThreads()方法调用,启动所有的核心线程去轮询workQueue。因为addWorker是需要上锁的,预启动核心线程可以提高执行效率。
2. ThreadPoolExecutor 内部类Worker
/**
* Class Worker mainly maintains interrupt control state for
* threads running tasks, along with other minor bookkeeping.
* This class opportunistically extends AbstractQueuedSynchronizer
* to simplify acquiring and releasing a lock surrounding each
* task execution. This protects against interrupts that are
* intended to wake up a worker thread waiting for a task from
* instead interrupting a task being run. We implement a simple
* non-reentrant mutual exclusion lock rather than use
* ReentrantLock because we do not want worker tasks to be able to
* reacquire the lock when they invoke pool control methods like
* setCorePoolSize. Additionally, to suppress interrupts until
* the thread actually starts running tasks, we initialize lock
* state to a negative value, and clear it upon start (in
* runWorker).
* 1.Worker类主要负责运行线程状态的控制。
* 2.Worker继承了AQS实现了简单的获取锁和释放所的操作。来避免中断等待执行任务的线程时,中断正在运行中的线程(线程刚启动,还没开始执行任务)。
* 3.自己实现不可重入锁,是为了避免在实现线程池控状态控制的方法,例如:setCorePoolSize的时候中断正在开始运行的线程。
* setCorePoolSize可能会调用interruptIdleWorkers(),该方法中会调用worker的tryLock()方法中断线程,自己实现锁可以确保工作线程启动之前不会被中断
*/
private final class Worker
extends AbstractQueuedSynchronizer
implements Runnable
{
/**
* This class will never be serialized, but we provide a
* serialVersionUID to suppress a javac warning.
*/
private static final long serialVersionUID = 6138294804551838833L; /** Thread this worker is running in. Null if factory fails. */
final Thread thread;
/** Initial task to run. Possibly null. */
Runnable firstTask;
/** Per-thread task counter */
volatile long completedTasks; /**
* Creates with given first task and thread from ThreadFactory.
* @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker //状态置为-1,如果中断线程需要CAS将state 从0->1,以此来保证能只中断从workerQueue getTask的线程
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
} /** Delegates main run loop to outer runWorker */
public void run() {
runWorker(this); //首先执行w.unlock,就是把state置为0,对该线程的中断就可以进行了
} // Lock methods
//
// The value 0 represents the unlocked state.
// The value 1 represents the locked state. protected boolean isHeldExclusively() {
return getState() != 0;
}
//在setCorePoolSize/shutdown等方法中断worker线程时需要调用该方法,确保中断的是从workerQueue getTask的线程
protected boolean tryAcquire(int unused) {
if (compareAndSetState(0, 1)) {
setExclusiveOwnerThread(Thread.currentThread());
return true;
}
return false;
} protected boolean tryRelease(int unused) {
setExclusiveOwnerThread(null);
setState(0);
return true;
} public void lock() { acquire(1); }
public boolean tryLock() { return tryAcquire(1); }
public void unlock() { release(1); } //调用tryRelease修改state=0,LockSupport.unpark(thread)下一个等待锁的线程
public boolean isLocked() { return isHeldExclusively(); } void interruptIfStarted() {
Thread t;
if (getState() >= 0 && (t = thread) != null && !t.isInterrupted()) {
try {
t.interrupt();
} catch (SecurityException ignore) {
}
}
}
}
Java线程池ThreadPoolExecuter:execute()原理的更多相关文章
- 这么说吧,java线程池的实现原理其实很简单
好处 : 线程是稀缺资源,如果被无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,合理的使用线程池对线程进行统一分配.调优和监控,有以下好处: 1.降低资源消耗: 2.提高响应速度: 3.提高线 ...
- 深入分析java线程池的实现原理(转载)
前言 线程是稀缺资源,如果被无限制的创建,不仅会消耗系统资源,还会降低系统的稳定性,合理的使用线程池对线程进行统一分配.调优和监控,有以下好处: 1.降低资源消耗: 2.提高响应速度: 3.提高线程的 ...
- 深入源码分析Java线程池的实现原理
程序的运行,其本质上,是对系统资源(CPU.内存.磁盘.网络等等)的使用.如何高效的使用这些资源是我们编程优化演进的一个方向.今天说的线程池就是一种对CPU利用的优化手段. 通过学习线程池原理,明白所 ...
- 深入源码,深度解析Java 线程池的实现原理
java 系统的运行归根到底是程序的运行,程序的运行归根到底是代码的执行,代码的执行归根到底是虚拟机的执行,虚拟机的执行其实就是操作系统的线程在执行,并且会占用一定的系统资源,如CPU.内存.磁盘.网 ...
- Java线程池应用及原理分析(JDK1.8)
目录 一.线程池优点 二.线程池创建 三.任务处理流程 四.任务缓存队列及排队策略 五.任务拒绝策略 六.线程池关闭 七.线程池实现原理 八.静态方法创建线程池 九.如何确定线程池大小 一.线程池优点 ...
- java并发编程(十七)----(线程池)java线程池架构和原理
前面我们简单介绍了线程池的使用,但是对于其如何运行我们还不清楚,Executors为我们提供了简单的线程工厂类,但是我们知道ThreadPoolExecutor是线程池的具体实现类.我们先从他开始分析 ...
- Java线程池的工作原理与实现
简单介绍 创建线程有两种方式:继承Thread或实现Runnable.Thread实现了Runnable接口,提供了一个空的run()方法,所以不论是继承Thread还是实现Runnable,都要有自 ...
- Java线程池使用和分析(二) - execute()原理
相关文章目录: Java线程池使用和分析(一) Java线程池使用和分析(二) - execute()原理 execute()是 java.util.concurrent.Executor接口中唯一的 ...
- Java线程池ThreadPoolExecutor使用和分析(二) - execute()原理
相关文章目录: Java线程池ThreadPoolExecutor使用和分析(一) Java线程池ThreadPoolExecutor使用和分析(二) - execute()原理 Java线程池Thr ...
随机推荐
- jquery获取html元素的绝对位置和相对位置的方法
绝对位置坐标: 代码如下: $("#elem").offset().top$("#elem").offset().left 相对父元素的位置坐标: 代码如下: ...
- Unity的加载路径
1.Resources 路径 只读 不能动态的修改 存放内容 预制体(prefabs) - 不容易变化的预制体 prefabs打包的时候 会自动过滤不需要的资源 有利于减小资源大小 主线程加载 Res ...
- C#委托和事件定义和使用
委托 定义委托的语法和定义方法比较相似,只是比方法多了一个关键字delegate ,我们都知道方法就是将类型参数化,所谓的类型参数化就是说该方法接受一个参数,而该参数是某种类型的参数,比如int.st ...
- Asp.net 程序优化js,css合并与压缩
访问时将js和css压缩并且缓存在客户端,采用的是Yahoo.Yui.Compressor组件还完成的,从这里可下载 创建一个IHttpHandler来处理文件 ) }; ) ...
- 数据库ADO方式读取图片
void Caccess_test_1Dlg::OnBnClickedButton3()//将偏振图像存入数据库 { // TODO: 在此添加控件通知处理程序代码 if (!PathFileExis ...
- NHibernate之映射文件配置说
1. hibernate-mapping 这个元素包括以下可选的属性.schema属性,指明了这个映射所引用的表所在的schema名称.假若指定了这个属性, 表名会加上所指定的schema的名字扩展为 ...
- EF--CodeFirst
1,增加EntityFramework的引用 2,创建实体类 public class Invoice { public Invoice() { LineItems = new List<Lin ...
- hadoop命令fsck命令
在HDFS中,提供了fsck命令,用于检查HDFS上文件和目录的健康状态.获取文件的block块信息和位置信息等. 具体命令介绍: -move: 移动损坏的文件到/lost+found目录下 -del ...
- 实现Runnable接口和继承Thread类区别
如果一个类继承Thread,则不适合资源共享.但是如果实现了Runable接口的话,则很容易的实现资源共享. 实现Runnable接口比继承Thread类所具有的优势: 1):适合多个相同的程序代码的 ...
- Python 使用正则表达式匹配电子邮箱
如下: In [1]: import re In [2]: email = "1210640219@qq.com" In [3]: regular = re.compile(r'[ ...