(数据科学学习手札49)Scala中的模式匹配
一、简介
Scala中的模式匹配类似Java中的switch语句,且更加稳健,本文就将针对Scala中模式匹配的一些基本实例进行介绍:
二、Scala中的模式匹配
2.1 基本格式
Scala中模式匹配的基本格式如下:
data match {
case ... => 执行语句
case ... => 执行语句
case _ => 执行语句
}
其中,data表示将要进行模式匹配的对象,match是模式匹配的关键字,后面紧跟的{}中包含若干条匹配的方向,且只会匹配其中满足条件的第一条;对于每一条条件,都是以case关键字开头,紧跟匹配的模式,且_表示匹配任何模式,接着是=>,指向对应的执行语句,下面是一个简单的示例:
object main{
def main(args: Array[String]): Unit = {
var data:String = "Hadoop"
//模式匹配语句
data match {
case "Spark" => println("No!")
case "Hadoop" => println("Yes")
}
var demo = 1 match {
//通配符_表示匹配任何对象
case _ => println("Anything!")
}
}
}

可以看出,在第一个模式匹配语句中,匹配到对应的"Hadoop"字符串对象之后,执行了对应的语句;在第二个模式匹配语句中,_指定了匹配任意对象,并执行了对应的输出;
2.2 结合条件语句
在我们的模式匹配语句中,可以添加条件语句,在Scala中这叫做守卫,下面是一个简单的例子:
object main{
def main(args: Array[String]): Unit = {
def isMale(Gender:Int)={
Gender match {
case 1 => println("Yes!Male!")
case 0 => println("No!Female!")
//添加守卫的模式匹配语句
case _ if Gender != 0 & Gender != 1 => println("Unknown!")
}
}
//调用函数
isMale(0)
isMale(1)
isMale(2)
}
}

2.3 结合变量
在Scala的模式匹配中,我们还可以在模式语句内直接赋以新变量,来与传入的变量结合起来,对上面的例子稍加改造得到下面这个例子:
object main{
def main(args: Array[String]): Unit = {
def isMale(Gender:Int)={
Gender match {
case 1 => println("Yes!Male!")
case 0 => println("No!Female!")
//添加守卫的模式匹配语句
case gender if gender != 0 & gender != 1 => {
println("Unknown!")
//在match语句中调用新变量
println("gender = " + gender)
}
}
}
//调用函数
isMale(2)
}
}
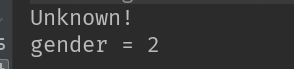
可以看出,将match语句下的模式匹配内容由常量改成新变量,会直接将传入的待匹配对象传递给该新变量,但该新变量的作用域只限于match语句内,在外无法调用;
2.4 匹配数组与元组
数组:
在对数组进行模式匹配时,可以配合通配符完成一些模糊匹配的功能:
import scala.collection.mutable.ArrayBuffer
object main{
def main(args: Array[String]): Unit = {
val Demo = ArrayBuffer("Spark","Scala","Python")
Demo match {
case ArrayBuffer("Scala") => println("No!")
case ArrayBuffer("Spark",_*) => println("Yes!")
case _ => println("Warning!")
}
}
}
通过在匹配内容中添加_*,来表示匹配任意多的数组元素,这这里表示匹配第一个元素时"Spark",之后任意多其他元素的可变长数组;
元组:
在匹配元组时,同样可以使用对应的语法来实现模糊匹配:
object main{
def main(args: Array[String]): Unit = {
def fitTuple(tuple:Tuple2[Any,Any]): Unit ={
tuple match {
case (1,"Spark") => println("1")
//匹配第二个元素为Scala的长度为2的元组
case (x,"Scala") => println(x)
case _ => println("Nothing!")
}
}
val t = (3,"Scala")
fitTuple(t)
}
}

2.5 异常处理与模式匹配
在前面的(数据科学学习手札45)Scala基础知识中提到过Scala中的错误处理机制,其实catch{}语句中的各条执行语句就是一条条的模式匹配语句,这里便不再赘述。
以上就是Scala中关于模式匹配的一些基础内容的简单介绍,如有笔误,望指出。
(数据科学学习手札49)Scala中的模式匹配的更多相关文章
- (数据科学学习手札32)Python中re模块的详细介绍
一.简介 关于正则表达式,我在前一篇(数据科学学习手札31)中已经做了详细介绍,本篇将对Python中自带模块re的常用功能进行总结: re作为Python中专为正则表达式相关功能做出支持的模块,提供 ...
- (数据科学学习手札42)folium进阶内容介绍
一.简介 在上一篇(数据科学学习手札41)中我们了解了folium的基础内容,实际上folium在地理信息可视化上的真正过人之处在于其绘制图像的高度可定制化上,本文就将基于folium官方文档中的一些 ...
- (数据科学学习手札44)在Keras中训练多层感知机
一.简介 Keras是有着自主的一套前端控制语法,后端基于tensorflow和theano的深度学习框架,因为其搭建神经网络简单快捷明了的语法风格,可以帮助使用者更快捷的搭建自己的神经网络,堪称深度 ...
- (数据科学学习手札69)详解pandas中的map、apply、applymap、groupby、agg
*从本篇开始所有文章的数据和代码都已上传至我的github仓库:https://github.com/CNFeffery/DataScienceStudyNotes 一.简介 pandas提供了很多方 ...
- (数据科学学习手札55)利用ggthemr来美化ggplot2图像
一.简介 R中的ggplot2是一个非常强大灵活的数据可视化包,熟悉其绘图规则后便可以自由地生成各种可视化图像,但其默认的色彩和样式在很多时候难免有些过于朴素,本文将要介绍的ggthemr包专门针对原 ...
- (数据科学学习手札50)基于Python的网络数据采集-selenium篇(上)
一.简介 接着几个月之前的(数据科学学习手札31)基于Python的网络数据采集(初级篇),在那篇文章中,我们介绍了关于网络爬虫的基础知识(基本的请求库,基本的解析库,CSS,正则表达式等),在那篇文 ...
- (数据科学学习手札47)基于Python的网络数据采集实战(2)
一.简介 马上大四了,最近在暑期实习,在数据挖掘的主业之外,也帮助同事做了很多网络数据采集的内容,接下来的数篇文章就将一一罗列出来,来续写几个月前开的这个网络数据采集实战的坑. 二.马蜂窝评论数据采集 ...
- (数据科学学习手札40)tensorflow实现LSTM时间序列预测
一.简介 上一篇中我们较为详细地铺垫了关于RNN及其变种LSTM的一些基本知识,也提到了LSTM在时间序列预测上优越的性能,本篇就将对如何利用tensorflow,在实际时间序列预测任务中搭建模型来完 ...
- (数据科学学习手札36)tensorflow实现MLP
一.简介 我们在前面的数据科学学习手札34中也介绍过,作为最典型的神经网络,多层感知机(MLP)结构简单且规则,并且在隐层设计的足够完善时,可以拟合任意连续函数,而除了利用前面介绍的sklearn.n ...
随机推荐
- VS2017配置cuda9.1编译不过问题。
#if defined(_WIN32) #if _MSC_VER < 1600 || _MSC_VER > 1920 #error -- unsupported Microsoft Vis ...
- My personal website:http://47.94.240.229:8080/yjh/project/
My personal website: http://47.94.240.229:8080/yjh/project/
- 10个值得深思的PHP面试题
第一个问题关于弱类型 $str1 = 'yabadabadoo'; $str2 = 'yaba'; if (strpos($str1,$str2)) { echo "/"" ...
- [BZOJ 2186][SDOI 2008] 莎拉公主的困惑
2186: [Sdoi2008]沙拉公主的困惑 Time Limit: 10 Sec Memory Limit: 259 MBSubmit: 4519 Solved: 1560[Submit][S ...
- 认识 Java(配置环境变量)
1. Java 简介 Java由Sun Microsystems公司于1995年5月推出,是一种面向对象的编程语言.在2009年4月20号,ORACLE (甲骨文)收购了 Sun 公司,也就是说 Ja ...
- Linux中从oracle官网下载jdk文件不是标准的gzip格式文件问题
首先你要知道,在linux系统中,文件类型跟后缀名无关,后缀名只是为了方便识别,所以你下载的压缩包可能是tar.gz格式的,也有可能是tar.bz2或tar.xz格式,因为可能别人压缩之后不小心改错了 ...
- psql: FATAL: role “postgres” does not exist
I'm a postgres novice. I installed the postgres.app for mac. I was playing around with the psql comm ...
- ZooKeeper学习之路 (六)ZooKeeper API的简单使用(二)级联删除与创建
编程思维训练 1.级联查看某节点下所有节点及节点值 2.删除一个节点,不管有有没有任何子节点 3.级联创建任意节点 4.清空子节点 ZKTest.java public class ZKTest { ...
- 【JavaScript】particle
这是js实现的粒子动画,有两种模式,分别是zoom和line,它们对应的效果不同,但是原理都相同,具体分析如下: 部分程序如下: var p = this; p.originParams = orig ...
- 如何异步的处理restful服务(基础)
1.使用Runnable 2.使用DeferredResult 3.异步处理的一些配置 正常请求方式 package com.nxz.controller; import lombok.extern. ...