强化学习之QLearning
注:以下第一段代码是 文章 提供的代码,但是简书的代码粘贴下来不换行,所以我在这里贴了一遍。其原理在原文中也说得很明白了。
算个旅行商问题
基本介绍
戳 代码解释与来源
代码整个计算过程使用的以下公式-QLearning
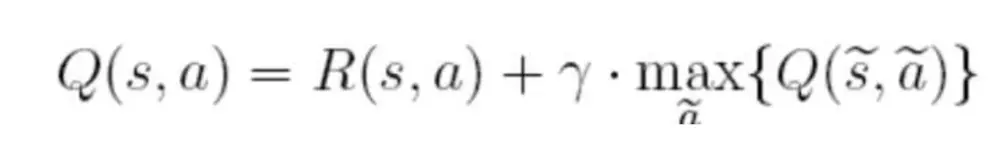
在上面的公式中,S表示当前的状态,a表示当前的动作,s表示下一个状态,a表示下一个动作,γ为贪婪因子,0<γ<1,一般设置为0.8。Q表示的是,在状态s下采取动作a能够获得的期望最大收益,R是立即获得的收益,而未来一期的收益则取决于下一阶段的动作
算法过程

面对问题
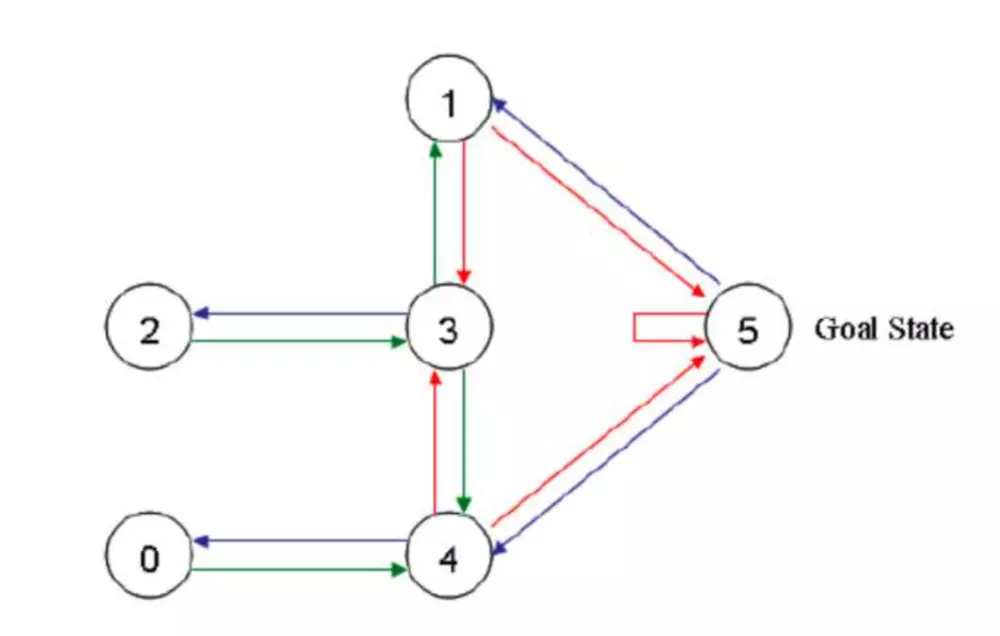
这是一个把一个代理(玩家)随机丢入一个房间,代理如何能最快速到达指定房间(在这里是5号房间) 的问题。
代码全文
import numpy as np
import random
r = np.array([[-1, -1, -1, -1, 0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1, -1, 0, -1, -1], [-1, 0, 0, -1, 0, -1], [0, -1, -1, 0, -1, 100], [-1, 0, -1, -1, 0, 100]])
q = np.zeros([6,6],dtype=np.float32)
gamma = 0.8
step = 0
for step in range(100):
print("step:", step)
state = random.randint(0,5)
if state != 5:
next_state_list=[]
for i in range(6):
if r[state,i] != -1:
next_state_list.append(i)
next_state = next_state_list[random.randint(0,len(next_state_list)-1)]
qval = r[state,next_state] + gamma * max(q[next_state])
q[state,next_state] = qval
print(q)
for i in range(10):
print("第{}次验证".format(i + 1))
state = random.randint(0, 5)
print('机器人处于{}'.format(state))
count = 0
while state != 5:
if count > 20:
print('fail')
break
q_max = q[state].max()
q_max_action = []
for action in range(6):
if q[state, action] == q_max:
q_max_action.append(action)
next_state = q_max_action[random.randint(0, len(q_max_action) - 1)]
print("the robot goes to " + str(next_state) + '.')
state = next_state
count += 1
关于视频教程
视频教程中的demo实现没有看懂,然后我就按照上述文章的思路实现了视频中demo的基本功能。还不算完善,完善之后再追加。
简述:视频中demo的功能是实现一个单项运动,从1走到6就算成功。但是机器本身不知道应该按照什么样的方式走,应该加或者减,通过多次强化学习之后,可以通过回报表(Q表)知道自己应该一路加上去,从1加到6.
代码
import numpy as np
import random
r = np.array([[-1, 0, -1, -1, -1, -1], [0, -1, 0, -1, -1, -1], [-1, 0, -1,0, -1, -1], [-1, -1, 0, -1,0, -1], [-1, -1, -1, 0, -1, 100], [-1, -1,-1, -1, 0, 100 ]])
#能走的标记为0,不能走的方向标记为-1,到达终点标记为100
#因为是从1走到6一字排开,所以1能到2,2能到1,1不能到3酱紫
q = np.zeros([6,6],dtype=np.float32)
gamma = 0.8
#贪婪因子
step = 0
for step in range(10):
state = 0
time = 0
while state != 5:
time =time + 1
next_state_list=[]
for i in range(6):
if r[state,i] != -1:
next_state_list.append(i)
next_state = next_state_list[random.randint(0,len(next_state_list)-1)]
qval = r[state,next_state] + gamma * max(q[next_state])
q[state,next_state] = qval
state = next_state
############################我是分割线##########################
print(q)#打印Q表
state = 0
while state != 5:
next_state = q[state].argmax(axis = 0)#取得Q表当前行最大值的索引
print(next_state)
state = next_state
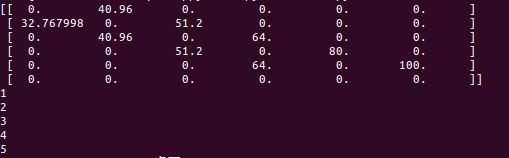
打印结果
解释
分割线之上通过强化学习(QLearning)得到Q表
分割线之下是通过Q表得到路线图(即一路上加)
打印结果表示下一步到哪 。初始在位置0,然后依次顺序打印应该到哪个位置。
总结
神经网络适合拟合、图像视频识别与分类能,强化学习适合做类似于阿尔法狗/走迷宫酱紫的智能活动
参考
文章:
https://www.itcodemonkey.com/article/3646.html
https://www.jianshu.com/p/29db50000e3f?utm_medium=hao.caibaojian.com&utm_source=hao.caibaojian.com
视频:
https://www.bilibili.com/video/av16921335/?p=6 对应代码
强化学习之QLearning的更多相关文章
- 强化学习之Q-learning ^_^
许久没有更新重新拾起,献于小白 这次介绍的是强化学习 Q-learning,Q-learning也是离线学习的一种 关于Q-learning的算法详情看 传送门 下文中我们会用openai gym来做 ...
- 强化学习之Q-learning简介
https://blog.csdn.net/Young_Gy/article/details/73485518 强化学习在alphago中大放异彩,本文将简要介绍强化学习的一种q-learning.先 ...
- 强化学习Q-Learning算法详解
python风控评分卡建模和风控常识(博客主亲自录制视频教程) https://study.163.com/course/introduction.htm?courseId=1005214003&am ...
- 基于Keras的OpenAI-gym强化学习的车杆/FlappyBird游戏
强化学习 课程:Q-Learning强化学习(李宏毅).深度强化学习 强化学习是一种允许你创造能从环境中交互学习的AI Agent的机器学习算法,其通过试错来学习.如上图所示,大脑代表AI Agent ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- (译) 强化学习 第一部分:Q-Learning 以及相关探索
(译) 强化学习 第一部分:Q-Learning 以及相关探索 Q-Learning review: Q-Learning 的基础要点是:有一个关于环境状态S的表达式,这些状态中可能的动作 a,然后你 ...
- 强化学习 - Q-learning Sarsa 和 DQN 的理解
本文用于基本入门理解. 强化学习的基本理论 : R, S, A 这些就不说了. 先设想两个场景: 一. 1个 5x5 的 格子图, 里面有一个目标点, 2个死亡点二. 一个迷宫, 一个出发点, ...
- 强化学习(九)Deep Q-Learning进阶之Nature DQN
在强化学习(八)价值函数的近似表示与Deep Q-Learning中,我们讲到了Deep Q-Learning(NIPS 2013)的算法和代码,在这个算法基础上,有很多Deep Q-Learning ...
随机推荐
- 阿里云CentOS7部署MySql8.0
本文主要介绍了阿里云CentOS7如何安装MySql8.0,并对所踩的坑加以记录; 环境.工具.准备工作 服务器:阿里云CentOS 7.4.1708版本; 客户端:Windows 10; SFTP客 ...
- Django学习笔记6(iframe、外键插入)
1.{%include 'index.html'%i} 平时很好用的iframe在django里面的不是很好用 django里面提供了{%include 'index.html'%i}的方式来取代了i ...
- windows 使用npm安装webpack 4.0以及配置问题的解决办法
输入cmd点击打开 输入node -v 出现nodejs版本号 输入npm -v 出现npm版本号则安装npm安装成功, 2.安装webpack 桌面新建一个webpack-test文件夹,点击进入文 ...
- urllib库使用方法 3 get html
import urllib.requestimport urllib.parse #https://www.baidu.com/s?ie=UTF-8&wd=中国#将上面的中国部分内容,可以动态 ...
- 20155203 实验四《 Android程序设计》实验报告
一.实验内容 实验项目一:Android Stuidio的安装测试: 参考<Java和Android开发学习指南(第二版)(EPUBIT,Java for Android 2nd)>第二十 ...
- 20155204第4次实验《Android程序设计》实验报告
20155204第四次实验报告 一.实验内容及步骤 1.Android Stuidio的安装测试: 安装 Android Stuidio 完成Hello World, 要求修改res目录中的内容,He ...
- 20145226夏艺华 《Java程序设计》实验报告三
实验三 敏捷开发与XP实践 实验内容 XP基础 XP核心实践 相关工具 实验步骤 (一)敏捷开发与XP 软件工程是把系统的.有序的.可量化的方法应用到软件的开发.运营和维护上的过程.软件工程包括下列领 ...
- c++静态变量
静态变量 一.静态变量 static关键字 static int i; 二.静态变量的运用 .计算函数被调用次数 .返回指针 第45课中有这么一段 int* square3(int *x) { int ...
- MySQL入门篇(五)之高可用架构MHA
一.MHA原理 1.简介: MHA(Master High Availability)目前在MySQL高可用方面是一个相对成熟的解决方案,它由日本DeNA公司youshimaton(现就职于Faceb ...
- 一个奇怪的JS函数
今天在分析一个jQuery插件源码的时候,发现了一个奇怪的函数. 这个函数的目的是为数字补零,如传入7,输出07,传入12输出12.由于是对时间补零,只截取后两位. // add leading ze ...